ACL新政禁止投稿论文在arXiv公开,我们到底需要什么样的双盲评审?

ACL的论文投稿,截稿日期前一个月不允许传arXiv。是直接接受双盲评审的新政,还是与拖延症做对决?
AI 科技评论按:近日 ACL( Association for Computational Linguistics,计算语言学协会)对自己的投稿、评审、引用规则进行了修订,其中最具争议的一项是要求 ACL 下属会议(ACL、EMNLP、NAACL - HLT)的匿名投稿论文, 在会议投稿截止日期前的一个月内不允许上传到非匿名预印本平台(比如 arXiv);直到论文评审结果公布后才可以公开上传(揭开匿名)。

这一要求显然再次引发了对于「双盲评审的必要性」和「如何高效率地执行双盲评审」的讨论,毕竟一段时间之前 ICLR 2018 的匿名论文投稿在评审结果出炉前就大批量暴露了论文作者,已经出现了一些批评的声音。刚好 ACM 通讯近日的一篇文章就研究了论文接受率和匿名的关系,我们先重新认识一下前一个话题。
双盲评审的原因
总的来说,在一场控制性实验中,ACM 网络搜索和数据挖掘国际会议(WSDM)委员会发现当评审者知道论文作者信息时,评审者更倾向于推荐名作者或者顶尖机构的论文。语言演变会议(Evolution of Languages Conference)委员会则发现当评审者知道作者信息时,男性一作的得分会比不知道时高 19%,女性一作则低 4%。
种种研究表明偏见会影响任何人,无论评审者的性别或种族。而双盲评审则可以弱化这种影响,减少歧视。这也使得双盲评审成为评价系统的非常具有建设性的一部分,使得论文评审结果更加的忠于论文质量。但即便是双盲评审中,审稿人猜测论文作者的尝试仍然会影响评审结果。
匿名的效果
就 ASE、OOPSLA、PLDI 这三个会议的数据来看,70%~86% 的评审者在提交评审结果前并不去猜论文作者是谁,这说明他们不知道也不在乎到底是谁写了这些论文。下图显示了每个会议的评价者、论文以及评论的数量。还显示了作者身份猜测结果的分布情况。
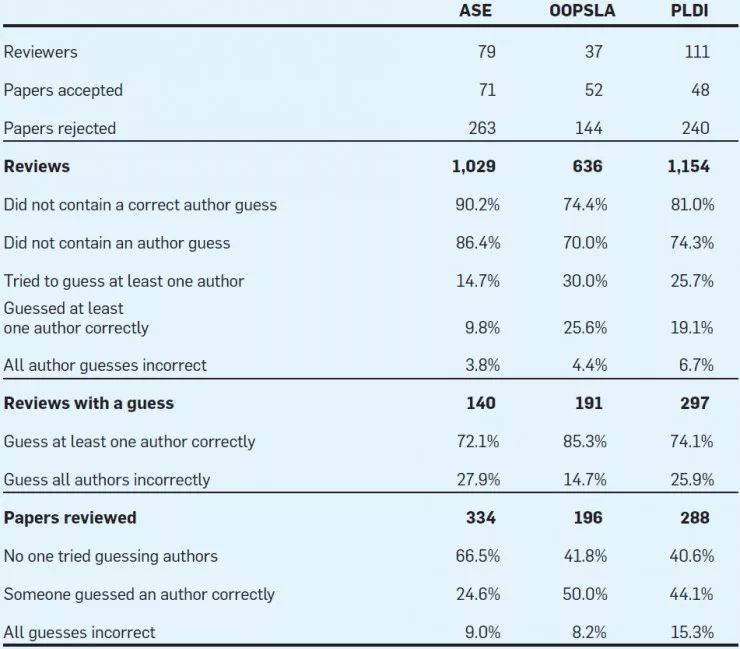
每篇论文至少有三条评论
假如评审者在评论中猜测论文作者,他们大概率会猜对(ASE 72% 的猜测能够猜对,OOPSLA是 85%,PLDI 是74%)。不过实际情况中,绝大多数的评审意见中并没有真的包含正确的猜测结果(ASE 90%,OOPSLA 74%,PLDI 81%)。
相比于普通评审者,专家们是否更喜欢猜作者并且容易猜对呢?下图显示了相关研究得出的结论。
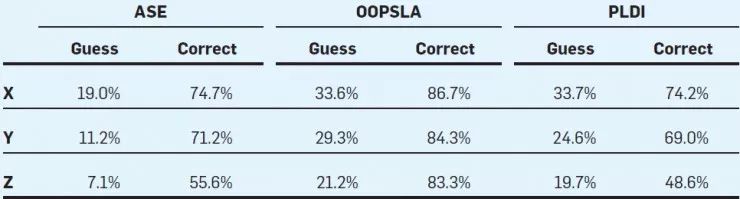
其中 X 代表专家,Y 代表研究学者,Z 代表普通学者(均为自评)。如上图所示,「专家们」显然更喜欢预测,然而预测准确性却没有比另两类人高多少(PLDI 的 Z 类评审除外)。所以结论是那些自认专家的更加喜欢猜测论文作者,正确性却不值一提。
第二个问题,论文「假」匿名频繁吗?有些作者不匿名可能是因为匿名效果太差。这种「假」匿名的论文反而会引来更多猜测。下图显示了相关研究得出的结论。
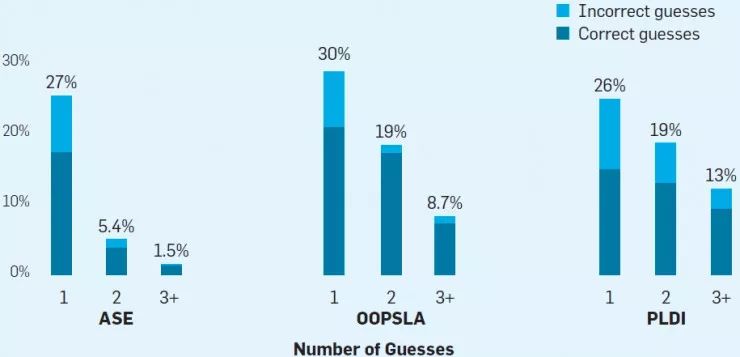
上图显示论文猜测的分布(柱形下部的阴影部分代表着猜测正确率)。其中绝大多数(26%~30%)论文只有一位评审者会猜测它的作者。研究还显示论文作者被猜测的越多那么猜不中的概率就越低。综合了三门会议数据的 χ2分布显示,猜测一次、两次、3+次的论文的作者猜中率在统计学上有显着差异(p≤0.05),这种差异在 OOPSLA 上也表现显著。直接比较各会议的猜测率(均使用单尾 Z 检验)他们还得出了一些结论:对于 OOPSLA 来说,它的一猜正确率与其他两门会议有很大差别;对于 PLDI 来说,它的一猜正确率和 3+猜正确率的也有统计学差异,这表明少数论文可能很容易被猜中作者;对于 ASE 来说,只有 1.5% 的论文被猜测作者的次数超过三次,PLDI 的同类数据是13%。另外,他们还发现,PLDI 中 40% 的猜测只针对 13%的论文,这意味着这要改善这一小部分论文的匿名情况就可减少很多猜测。由于目前这三门会议刚刚采用双盲评审,可能存在匿名程度低的情况,随着作者们的匿名经验越来越丰富,之后的匿名效果会越来越好。
第三个问题,那些被猜中作者的论文更容易被接收吗?他们调查了论文接收率与评审者的猜测的关系以及与猜中率的关系。结果如下图所示。
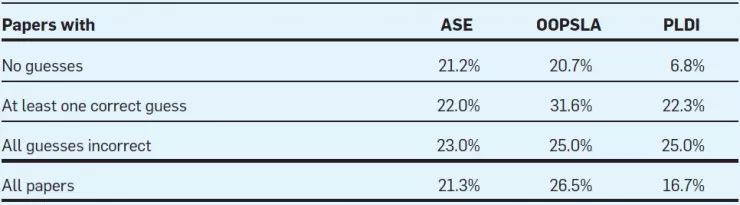
上图显示 ASE 的论文接收率似乎不受猜测行为的影响。而 OOPSLA 和 PLDI 的未被猜测的论文的接受率较低,相较于那些至少猜中一次的则下降更加明显。尤其值得注意的是,PLDI 未被猜测的论文相较于全部猜错的论文更加不容易被接收(OOPSLA也存在这种情况)。这种情况可能是因为 OOPSLA 和 PLDI 的评审者们更加青睐有名的研究员,他们相信高质量的工作更可能来自名研究员,所以也更愿意去猜作者。
最后一个问题,评审者们是怎么「去匿名化」的?曾有人询问 OOPSLA 和 PLDI 的评审者,作者信息是否是从引用中泄露出的。在所有带猜测的评论中,OOPSLA 37%(占全部评论的 11%)和 PLDI 44%(占全部评论的 11%)的评论承认作者信息是根据引用推断的。ASE 的评审者们也被问及是什么指引了他们的猜测,75 人是根据论文主题,31 人是根据之前的工作、数据集和源代码,21 人是因为之前已经见过草稿,3 人是根据先前的谈话。该结果表明有一些匿名曝光是不可避免的。还有一些评审者在搜索相关工作用作评价依据时搜索到了当前论文的 GitHub 库或项目网站。另一种情况就是该篇论文与作者之前的工作联系过于紧密,也难以真正匿名。虽然匿名困难,但现在也有不少改善匿名效果的方法。比如,增加学界对于匿名化的熟悉程度,确立一致的规范和明确的指导原则等。
而在程序委员会的内部会议上,主席就多次听到某成员确信另一个成员就是论文的作者的言论,然而事实证明他猜错了,这也反映了部分评审者过于自信,他们的去匿名推理并不一定正确。
程序委员会主席的观点
针对以上的结果,三个会议的程序委员会主席仍然支持继续使用双盲评审,他们都认为双盲评审减轻了潜在偏见的影响,这也是双盲评审的目的。不过执行的效果以及其中的挑战仍然不能掉以轻心。有一些程序委员会成员也持有同样的观点,这或许表明他们认为引入双盲之后他们认为自己的评审中的偏见变少了。
程序委员会主席们对于揭示论文作者的时间点看法不一,比如在评审后或PC会议前。其他的分歧也有一些,比如 PLDI 的主席强烈建议全部会议都使用双盲评审,这样一篇被拒论文重新匿名投给其他的会议时就能依旧保持匿名。ASE 的主席则发现,在某些情况下,揭示论文作者有助于更好地理解论文的贡献与价值。
总的来说,所有的主席们都不认为双盲评审会增加行政负担,ASE 的程序委员会主席雇佣了两个评审流程主席来协助他的工作,负担并不重。OOPSLA 的程序委员会主席也认同施行双盲评审的负担并不重,他觉得更重要的是指导作者进行匿名。PLDI 则是让作者将论文提交给程序委员会主席,然后由他进行派发,新增行政负担也是微不足道。
双盲评审的额外负担来自于课题冲突,而会议管理软件则可以简化冲突管理,所有的程序委员会主席都认为处理这些冲突并不困难,PLDI 的程序委员会主席认为双盲评审带来的好处完全大于它所产生的负担。
ACL 的新政为何引发争议?
显然双盲评审正如大家一致认为地那样不仅确实有积极的效果,而且不难做,那么 ACL 尝试保护双盲新政为何引起了争议呢?
首先,论文的信息公开和研究内容的快速迭代更新已经是领域内通行的做法,双盲评审带来的各种限制也只能是取得平衡而无法完全在时效性和公开性方面开倒车。有人认为「截稿前一个月限制公开」的做法过于理想化、有效性非常有限。比如它只对首次投稿有用,被拒的论文可以自然地公开上传到 arXiv 然后投下一个会议;以及,作者完全可以在更早的时候完成并上传论文,不仅不受到这一限制的影响,更享有了充分的曝光和修订时间。
新政的支持者、斯坦福大学 NLP 小组(Stanford NLP group)掌门人、2015 年曾任 ACL 主席的 Christopher Manning 也发言针对这一新政的初衷做了详细的解释:
「通过加速研究结果传播速度来加速科学进步是件好事,而过程中使用双盲评审可以弱化偏见,防止一些名学者或者大机构从中获利。ACL 的投稿、评审、引用策略规则就是两者之间的一种折衷方案。
作为折衷方案,它会给非匿名文章的传播带来一些延迟;同时它也无法完美达成双盲评审的各项要求。但它仍然距离双盲的要求更近了,我认为这是一种好的妥协,目前表现也符合预期。当然如果你并不打算为传播速度而妥协,而是专注解决多样性,包容性以及偏见等问题,那么 ACL 的新政可能对你并不重要。
作者的匿名性终究是无法得到绝对保证的,毕竟你要与同事讨论工作,或者外出演讲提到自己的研究课题,总会泄露的,所以 ACL 新政也并不是希望你隔绝与同事的工作交流。事实上,ACL 的新政策是希望通过高效利用预印本来加速科学进步:即在会议截止日期前早早地提交新结果,或者与同事早早交流初步想法以便之后修改。
之所以设计了这样新政,是考虑到了人性的两大弱点:拖延和健忘,每个人都本可以在截止日期前 35 天完成工作,但很少有人这样做。一些预印本或者之前被拒的论文可能经过一段时间以后已经广为传播了,但人们很少记住它们的作者。高匿名性很好的保留了双盲评审的好处,ACL 现在对非匿名预印本的限制只是为了避免匿名性被彻底破坏,当然同时也尽量多地保留加速科学交流的做法。」
结论
结合文中前半段来自 ASE、OOPSLA、PLDI 会议的数据,以及保持匿名性过程中的种种难题,实际上我们都会发现「完全的匿名」是无法达成的。但是既然双盲评审对于减轻偏见能够发挥出效力,我们总还是需要一些措施来提高匿名程度,以及提醒大家,在注重快速自由的沟通交流的同时也不要忘记了我们仍需以为各种方式努力减少人为的偏见。
via ACM.org,Effectiveness of Anonymization in Double-Blind Review,C. Le Goues, Y. Brun, S. Apel, E. Berger, S. Khurshid, Y. Smaragdakis, Communications of the ACM, Vol. 61 No. 6, Pages 30-33, 10.1145/3208157. Christopher Manning ( Twitter @chrmanning)。AI 科技评论编译整理。
对了,我们招人了,了解一下?

BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业

┏(^0^)┛欢迎分享,明天见!






