PPLcnet和YOLO的碰撞,真的能在cpu上快到起飞?

极市导读
这是一篇论证博客,前几天,baidu发布了PPLcnet,这是一款专门为cpu设计的网络,在看完论文后,果断进行了PPLcnet-yolo的复现,一来是想验证下这个网络在cpu上的性能,二来如果验证效果work,这套实验可以合并到自己的仓库。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一、PPLcnet性能:
在看论文时,对我诱惑最大的是下面这张benckmark的比较。
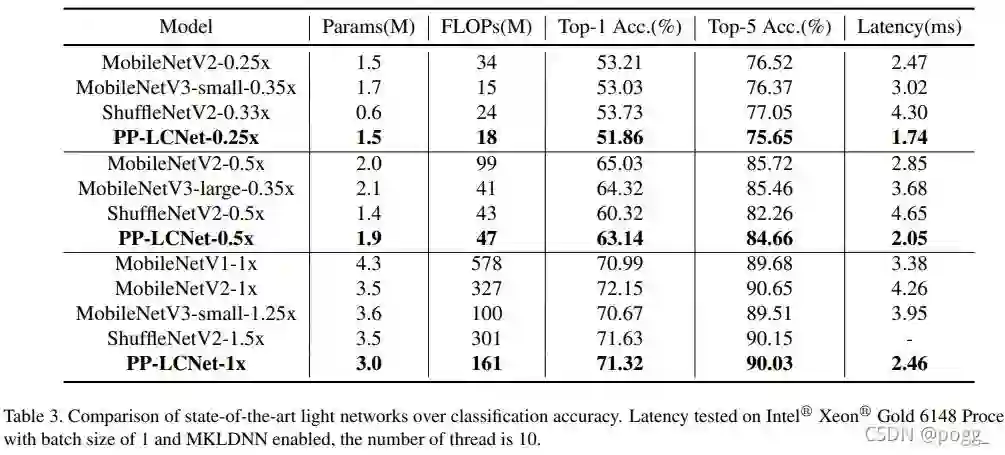
其实在之前,有尝试过使用mobilenetv2、mobilenetv3进行实验,但是效果并没有让我感到理想,原因也简单,在arm架构上,mb系列被shuffle系列一骑绝尘,这种优势并不是体现在精度上,事实上,它们的精度两两比较不会超过3个百分点。但是我认为侧端落地,速度和内存占用才是最关键的两个因素(前提是精度在可接受范围内),因此毫不犹豫使用shufflenetv2来做主干。
当然,并不能拿来主义,需要分析一些利弊后做取舍,比如对于yolov5s的head,如果直接嫁接,会造成部分通道冗余,这不仅仅体现在模型参数上,在多个方面都可以看到。
使用模型剪枝的方式去逼近channel最大的承载量,开展实验去验证效果,这种也算是一种半暴力解法,可以节省很多无效时间。
另一方面,shufflenetv2-yolov5模型的两个branch分支使用了大量了bn层,在部署时进行fuse,速度可以再提升15%(这个代码会在学位论文答辩后合并上去)。
在GPU架构上,Repvgg-yolov5也是如此,头变得更厚更窄,主要还是为了缩小参数和产生的计算量(C3结构的功劳),主干换成了repvgg,在训练时采取多分支特征提取,部署时又重参化成直筒网络,可以加速20%。参数和计算量分别减少了35%和10%,在精度上,Repvgg-yolov5的map@0.5提升了1.1,map@.5:0.95提升了2.2,但代价是向前推理比原先的yolov5s要多耗费1ms(测试显卡为2080Ti)。
综上,大家请叫我为调参调包外加debug狂魔,毫无创新点,但都是对于工业部署很实用的模型。
在cpu架构上,之前以及做过mbv2、mbv3的实验,精度其实和shufflev2相差不大,但结果相对于yolov5s,input size=352*352,yolov5s的精度还略高于魔改后的模型,在速度上也并没有很大的优势。
再后来PPLcnet出现,有着很强烈的欲望想试一下这个网络是否能帮助yolo在cpu上加速。
模型的结构大致如下:
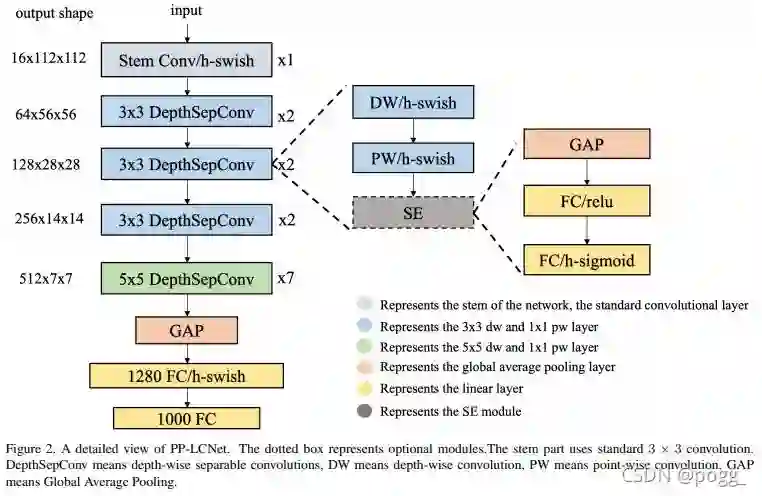
最主要的组成部分时深度可分离卷积,从第一层的CBH开始(conv+bn+hardswish),中间包含了13层dw,而后面的GAP是指7*7的Global Average Pooling,GAP后面再加point conv+FC+hardswish组件,最后是输出为1000的FC层,想要了解更详细的可以查看论文:
https://arxiv.org/pdf/2109.15099.pdf
整篇论文可以归纳关于PPLcnet的四个重要结论:
-
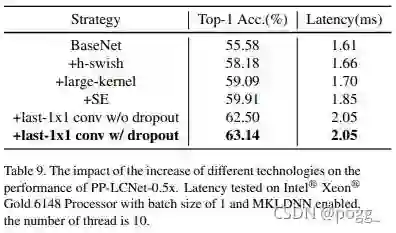
H-Swish与大卷积核可以提升模型性能且不会造成较大的推理损耗(下看Table9); -
在网络的下层添加少量的SE模块可以更进一步提升模型性能且不会产生过多的损耗(实际上Lcnet仅仅这是在最后两层添加注意力,但是提升效果明显);
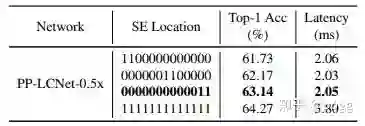
-
GAP后采用更大FC层可以极大提升模型性能(但也会让模型参数和计算量暴涨);
-
dropout技术可以进一步提升了模型的精度
二、PPLcnet-yolo:
下图是融合了PPLcnet的YOLOv5,与原先的Lcnet不同的是,此处的层数有所改变,不仅如此,YOLOv5s head中的3*3卷积也替换成了Lc_Block,并且使用了SE module,我们进行逐层分析:
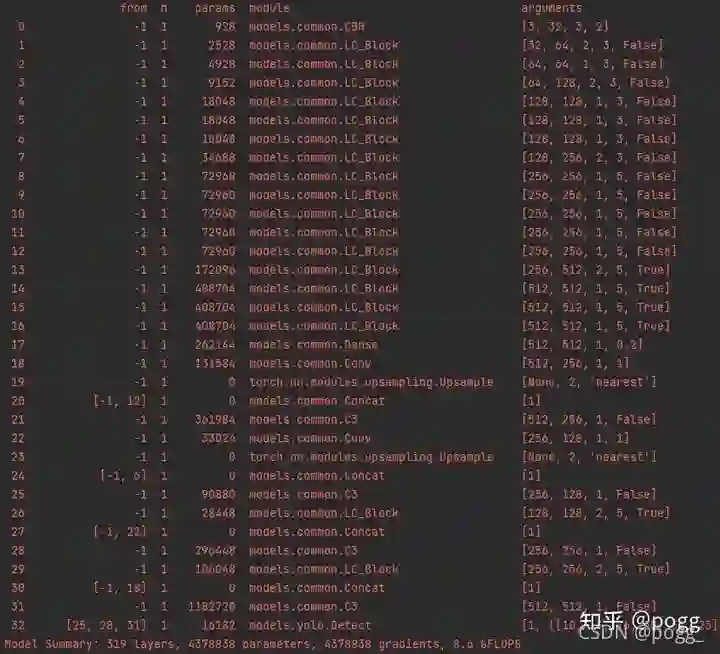
1. 层数改变
如上图,CBH通道数翻倍,抽掉了两个channel为256的DSC 3_3卷积层,替换成两个DSC 5_5层(无SE Module),并且最后的四个DSC层都含有SE模块,总的层数仅增加了3层,SE Module由原来的2层变成了4层(后4层),但是精度提升巨大,这点借鉴shufflev2的【2,4,8,4】偶数倍层数,有兴趣可以看下这篇论文,很有工程意义。

2. Dense Layer
Dense Layer本质还是GAP+FC,实验发现,添加FC层精度能提升4个点左右,但会导致模型参数的暴涨,影响推理速度,故剔除掉了所有的FC层,仅留下point conv和dropout:
class Dense(nn.Module):
def __init__(self, c1, c2, filter_size, dropout_prob=0.2):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.dense_conv = nn.Conv2d(
in_channels=c1,
out_channels=c2,
kernel_size=filter_size,
stride=1,
padding=0,
bias=False)
self.hardswish = nn.Hardswish()
self.dropout = nn.Dropout(p=dropout_prob)
self.flatten = nn.Flatten(start_dim=1, end_dim=-1)
self.fc = nn.Linear(num_filters, num_filters)
def forward(self, x):
x = self.avg_pool(x)
b, _, w, h = x.shape
x = self.dense_conv(x)
x = self.hardswish(x)
x = self.dropout(x)
x = self.flatten(x)
x = self.fc(x)
x = x.reshape(b, self.c2, w, h)
return x
3. headPPLcnet已经验证了在末端替换少量5_5卷积可以起到涨点的作用,因此也将原yolov5s head的3_3卷积换成Lc Block,但因为Lc Block本质还是深度可分离卷积,即使使用了5_5的卷积核,融合了SE module,参数量依旧比原先的3_3卷积少一半,实验发现可以涨点,产生的参数量也很少,个人觉得性价比特别高
# YOLOv5s head:
Model Summary: 297 layers, 4982390 parameters, 4982390 gradients, 9.4 GFLOPS
# YOLOv5s head with Lc_Block:
Model Summary: 307 layers, 4376531 parameters, 4376531 gradients, 8.6 GFLOPS
# YOLOv5s head with Lc_Block and SE Module:
Model Summary: 319 layers, 4378838 parameters, 4378838 gradients, 8.6 GFLOPS
还要一些小组件的改动,比如SE module的Hard sigmoid替换成Silu,能涨点还能提速(这点跟着v5大神走),另外一个是避免onnx没有h-sigmoid这个算子,需要重构算子(这个重构会造成精度些许下降,所以替换激活函数是最省心的工作)。
4. 性能
模型复现后性能如下:
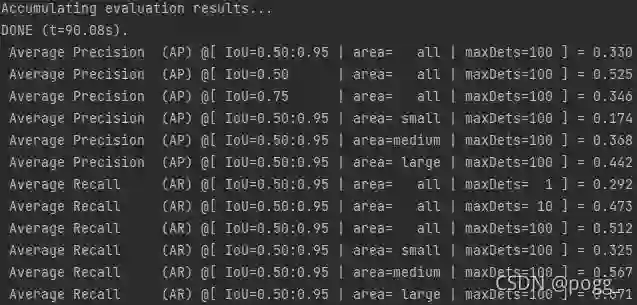
在map@0.5和map@0.5:0.95上都比原yolov5s少三个点左右,参数量和计算量少了一倍左右。

然而,上面的都不是重点,我认为最重要的还是性能,于是使用PPLcnet和yolov5s在openvino进行评测,测试硬件为Inter Core @i5-10210。
首先提取onnx模型:
$ python models/export.py --weights PPLcnet.pt --img 640 --batch 1
$ python -m onnxsim PPLcnet.onnx PPLcnet-sim.onnx
接着将PPLcnet-sim.onnx转化为IR模型:
$ python mo.py --input_model PPLcnet-yolo.onnx -s 255 --data_type FP16 --reverse_input_channels --output Conv_462,Conv_478,Conv_494
同理,yolov5s也是一样
$ python models/export.py --weights yolov5s.pt --img 640 --batch 1
$ python -m onnxsim yolov5s.onnx yolov5s-sim.onnx
$ python mo.py --input_model PPLcnet-yolo.onnx -s 255 --data_type FP16 --reverse_input_channels --output Conv_245,Conv_261,Conv_277
此时,我们可以得到四个模型:
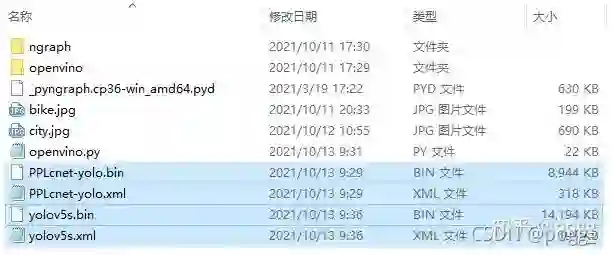
模型对比:

而后进行测试,总50张图片,For循环进行1000次向前推理,计算每张图片平均耗时:

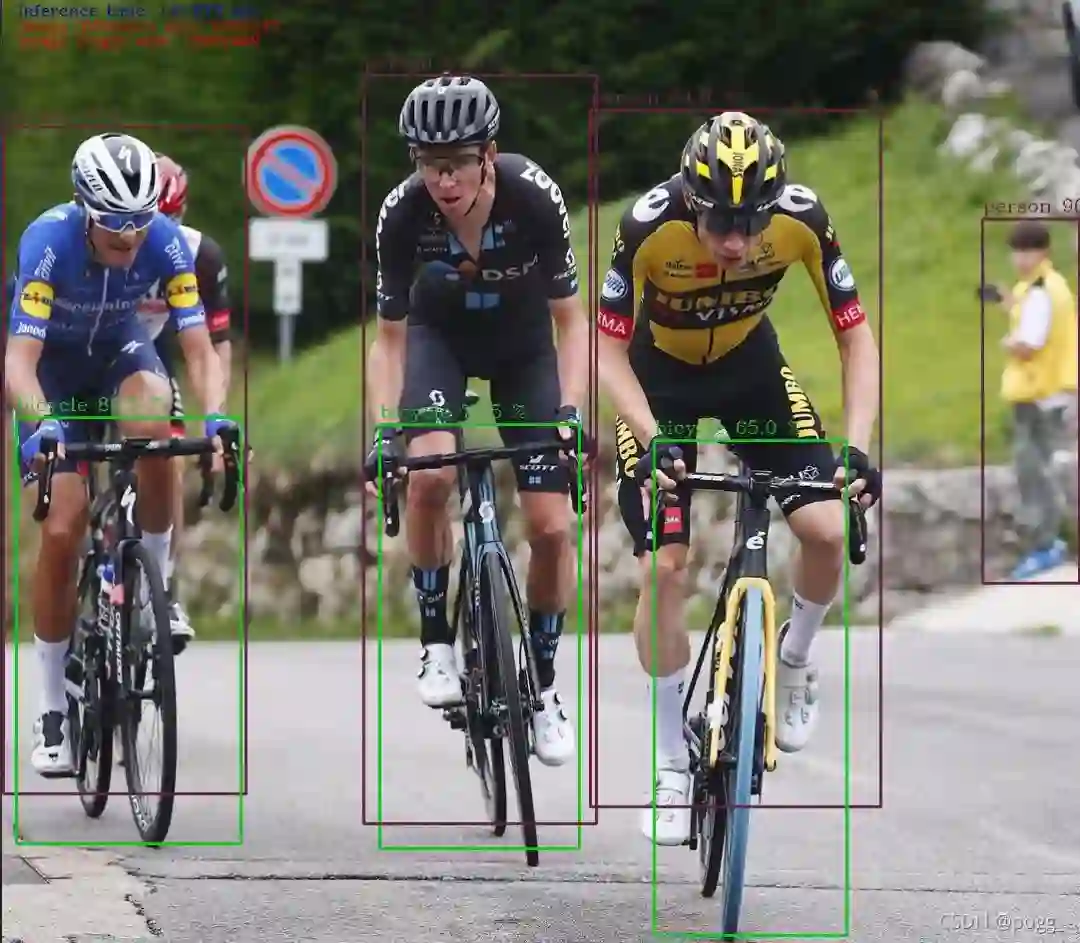
通过测试可以看到,input size=640*640,PPLcnet的一次先前推理比原yolov5s快3倍左右,部分样例视图.
PPLcnet-yolo Forward Example:
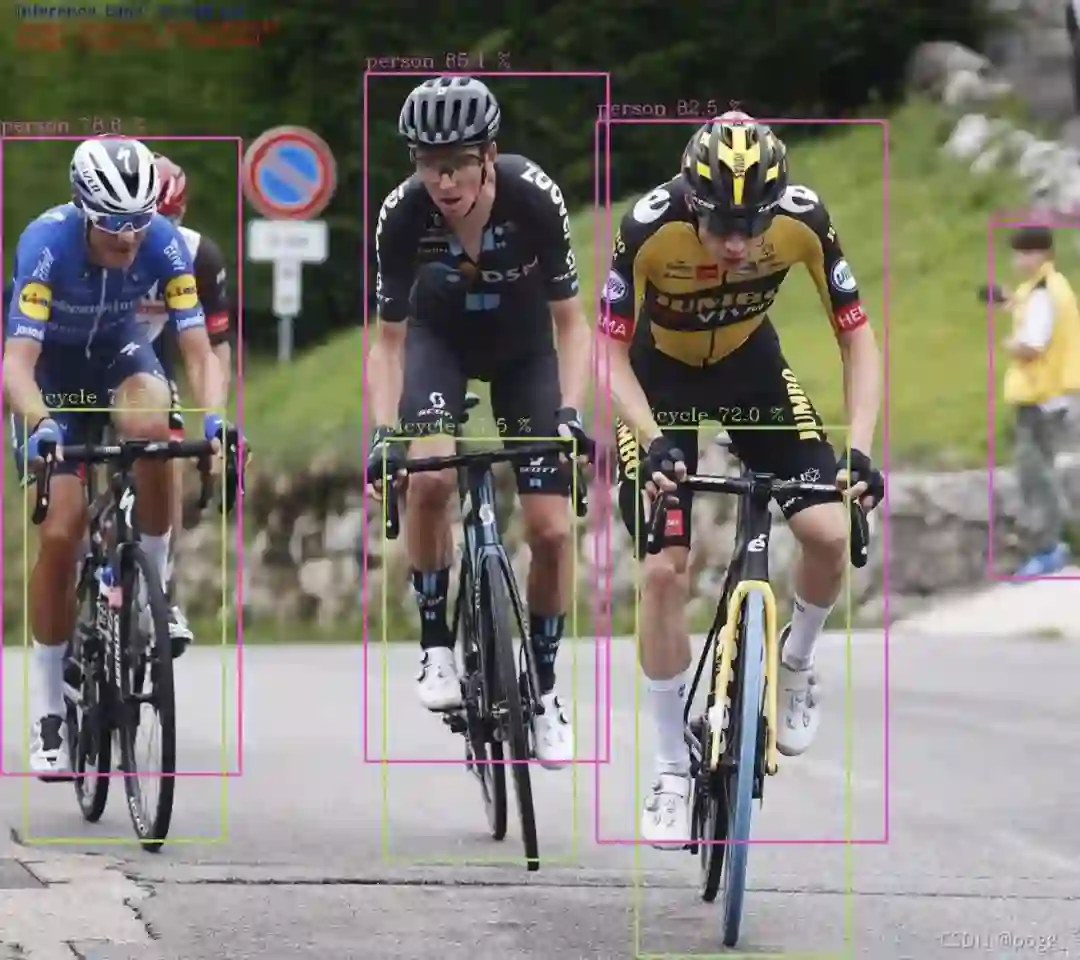
YOLOv5s Forward Example:
留言:
后续会将复现的实验及代码合并到主分支:
https://github.com/ppogg/YOLOv5-Lite
欢迎大家白嫖,有问题可以提issue,会尽快解决。
另外,这个是为cpu设计的模型,请使用openvino或者其他cpu向前推理框架进行部署和评测!!!
YOLOv5 6.0版本来了
重头戏来了,昨天看到YOLOv5发布了第六版:
模型性能有所改观:

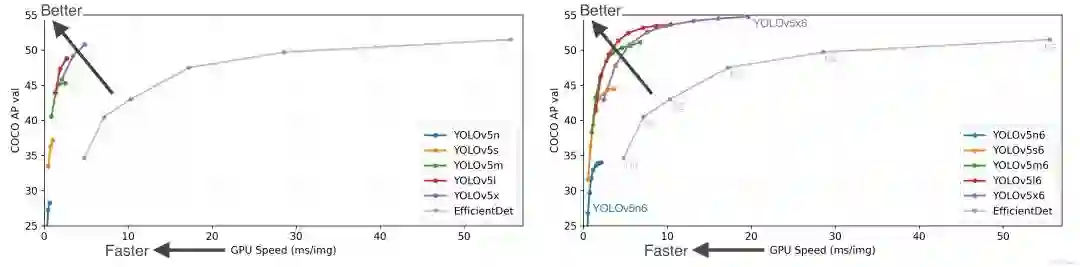
依旧是没有创新点,但是工程价值有突破,体现在计算资源和推理耗时方面。
另外,我觉得最主要的亮点有三个,YOLOv5-Nano对移动设备的适配,Focus层的变化,SPP的改动:
1. YOLOv5-Nano的性能:
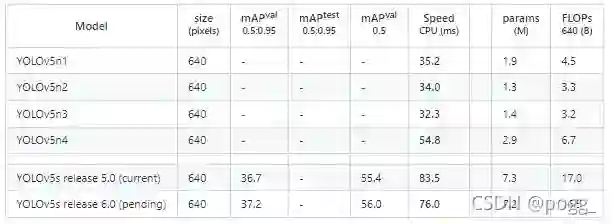
之前在侧端设备上测试了带有focus层的量化版yolov5s模型,发现这玩意很容易崩,对于小模型的话,v5大神是直接替换掉,可能是出于稳定性的考虑,毕竟conv3*3卷积在不同框架上的优化已经非常成熟了,对于大部分小模型,本身模型的参数和运行时产生的计算量并不多,使用focus也很难起到降参降计算量的作用,量化时还能更稳定一些。
2. Focus层的改变:
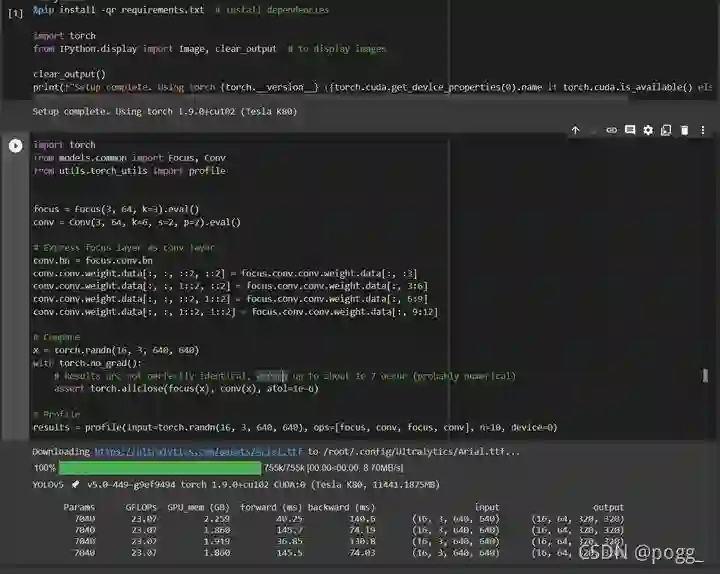
3. SPP→SPPF:

By the way!!!v4大牛,v5大神,还要Scale Yolov4的作者,三人在社区上被称为commit狂魔,有段时间天天看到他们几个在update,这种匠人精神着实令人佩服。。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





