华人教授史弋宇团队与Kneron合作应用神经网络与硬件协同搜索框架,并获Facebook研究大奖

新智元报道
新智元报道
来源:arxiv
编辑:雅新、白峰
【新智元导读】神经网络搜索的研究极大地推动了AI全民化的进程。在这个进程中,如何将神经网络最优地实现硬件系统成为AI全民化的最后一英里。华人教授史弋宇团队与 Facebook 合作,提出了首个针对许多应用场景的神经网络与ASIC协同设计方案 ASICNAS。
神经网络搜索(NAS)的研究极大地推动了人工智能全民化的进程,即让各行各业的应用都具有智能。
在人工智能全民化进程中,在获得优化的神经网络结构之后,在智能集成于各行应用之前,如何将神经网络最优地实现到硬件系统成为人工智能全民化的最后一英里。

然而,跨过人工智能全民化的最后一英里并不容易。
圣母大学团队开展了一些列关于全自动化生成神经网络结构与量身定制加速器的研究工作,旨在帮助缺乏硬件设计经验的公司与个人,快速并有效地为其应用自动设计出神经网络结构与相对应的硬件实现。
该团队与 Kneron 合作,搜索并设计了神经网络加速器,Kneron KL520 芯片。与 Facebook 合作,提出了针对多应用场景的首个神经网络与 ASIC 协同设计方案–ASICNAS。
KL520,智能物联网专用AI芯片
圣母大学的研究团队与 Kneron 合作,利用神经网络搜索与硬件协同搜索方法,为 Kneron KL520 芯片设计出了神经网络加速器 (NPU)–KDP 520。
深度神经网络以其优异的性能被广泛应用于各种计算机视觉任务中,该加速器的设计,旨在为将这些应用程序部署到边缘设备和边缘服务器上。
KL520 针对最新的卷积神经网络 (CNN) 模型,不仅优化了其功耗和效率,并且能够支持由卷积和密集层构成的 RNN、LSTM 等神经网络。

Kneron KL520 芯片已商用在对功耗要求严苛的 3D 人脸门锁上,以 8 节 AA 干电池每天识别 20 次为例,可以实现 360 天续航,大幅领先其他方案。
而今年量产的 KL720 芯片在业内率先实现 NPU 同时支持图像识别和语音识别,将使其在 AIoT 的应用更为广泛。
KL520 包括了两个 ARM Cortex M4 核心, KDP520 NPU 加速器,以及 DDR 存储器,提供 USB,DVP 等 I/O 接口。

其中 KDP 520 加速器的结构如下,NPU 加速器在保留顶级的架构和独特的过滤分解技术的基础上,使用滤波器分解 (filter decomposition) 技术,MAC 和 Adder 树经过优化为 3x3 内核,能够以有限的效率损失以支持而 其他内核大小的设计。通过对卷积流水线、批处理规范化、激活和池操作等优化,避免了不必要的数据移动,最小化系统延迟。
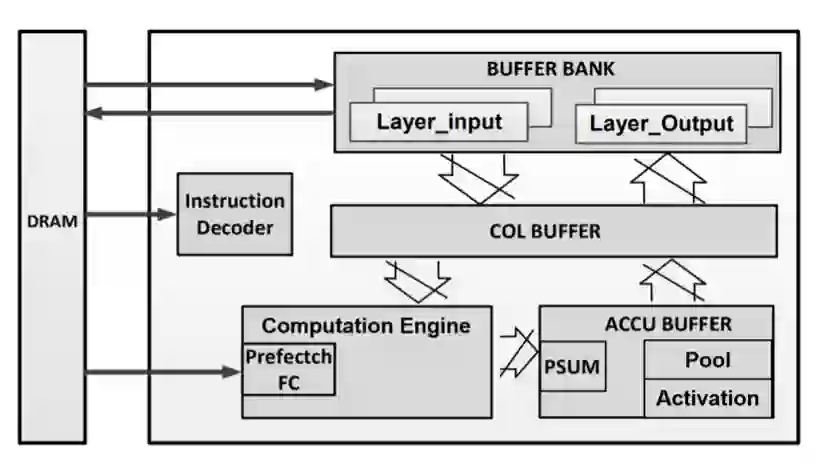
NPU 加速器的设计是可重新配置和可扩展的,包括了低功率版本 (<100GOPS) 到高性能版本 (达到 4TOPS)。该加速器还集成了一个数字信号处理器,不仅仅能加速神经网络,还可以加速先进的激活 功能和计算机视觉算法。
多个芯片也可以通过级联来构建更大的神经计算网络。当制造工艺达到 28nm 时,能效可达到 0.9TOPS/W,使之成为人工智能设备 (AIoT) 和边缘服务器的理想硬件加速器。
ASICNAS,首个神经网络与专用集成芯片搜索框架
神经架构搜索 (NAS) 已经在各种人工智能加速平台上展示了其独有的能力,比如对现场可编程门阵列 (FPGAs) 和图形处理单元 (GPU)。
然而,针对当下能效最高的硬件——专用集成电路 (ASIC),还没有一个协同设计解决方案。
其主要的瓶颈来自于 ASIC 较大的设计自由度,即需要搜索较大的设计空间。此外,在实际应用中,通常需要同时支持多 AI 任务(如 Facebook AI 眼镜)。

而对应的多个 DNN 并行运行,具有不同的工作负载和大小不同的层操作。将多个 DNN 部署到异构 ASIC 平台中的实现,能够通过将 DNN 分配到不同的 ASIC 子加速器上以显著提高性能。
但是,整个过程需要对多个 DNN 到由多个子加速其构成的异构 AISC 解空间进行搜索,进一步将设计空间复杂化。
为了解决这些问题,该团队与 Facebook 合作,首次提出 AI 任务网络结构和异构 ASIC 设计协同搜索框架 (ASICNAS)。
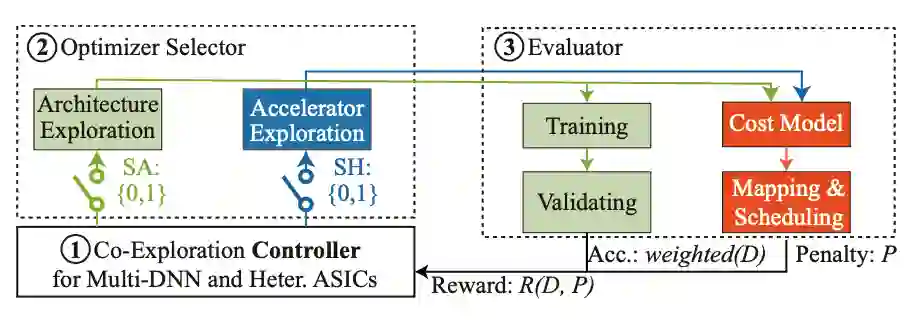
该框架包括三个部分:
1 控制器:基于强化学习的支持多任务与 ASIC 参数搜索的控制器
2 优化搜索器:神经网络结构搜索器 (左) 与加速器搜索器 (右)
3 测评器:神经网络精度 (左) 与加速器性能 (右) 自动化测评
其中,控制器将根据搜索历史,自动地预测神经网络结构与加速器设计参数。优化搜索器将控制对搜索器或加速器的调整。优化后的结果将在测评器中进行测试,以获得网络精度与硬件性能。这两项指标将反馈给控制器,进行下一轮预测。
该框架首次实现了针对应用程序中具有多个 AI 任务,对每个任务搜索到特定的神经网络结构。进而通过对由多个子加速器连接而成的异构 ASIC 平台的设计进行搜索,完成神经网络结构到异构 ASIC 平台的部署,以及资源的分配。
为了解决 ASIC 设计空间过大的问题,在现有设计的基础上,利用其独特的数据流来描述 ASIC 模板集,从而大大减少了设计空间。
进一步地,ASICNAS 可以同时识别多个 DNN 架构和相关联的异构 ASIC 加速器的设计,从而在满足设计规范的同时,将精度最大化。
实验结果表明,ASICNAS 可以保证所有探索到的解决方案均符合 ASIC 平台的设计规范。
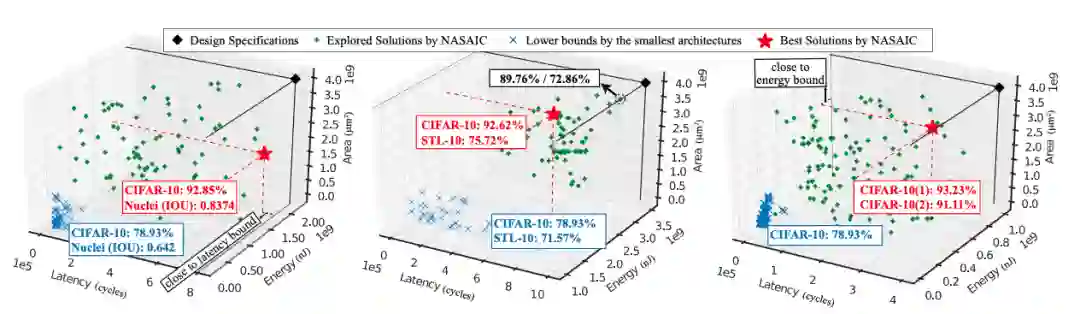
针对三种不同的工作负载,ASICNAS 在三种设计规范下的搜索结果比较:1) CIFAR-10 和 STL-10 数据集;2) CIFAR-10 和 Nuclei 数据集;3) CIFAR-10 数据集
ASICNAS 搜索的解在保证网络结构具有较高的精度的同时 (不到 1.6% 的精度损失),最佳的解方案非常接近硬件平台设计规范所定义的边界,这表明在资源的限制的情况下,能够达到最高的精度。
该成果已经被 DAC 2020 接收,将于 7 月份公开发表。这项研究还获得了Facebook 研究大奖,该奖项收到了111所大学的161个申请,但最终只有8个获奖。
圣母大学博士后姜炜文,圣母大学博士后杨蕾主要参与研究。其一系列工作包括基于FPGA,NoC等硬件和神经网络协同设计的原创性工作发表于 DAC, ICCAD, CODES+ISSS, ASP-DAC, ECAI 等会议,以及 IEEE TCAD, IEEE TC, ACM TECS 期刊。并连续获得 DAC’19,CODES+ISSS’19, ASP-DAC’20 三个自动化设计顶会的最佳论文提名。杨蕾将于今年秋天加入新墨西哥大学(University of New Mexico)担任助理教授。



