一文讲透 Git 底层数据结构和原理

阿里妹导读:本文将系统分享 Git 底层知识:对象生命周期变化,底层数据结构,数据包文件结构,数据包文件索引,以及详细分析对象查询流程和算法。
文末福利:程序员需要哪些软技能?

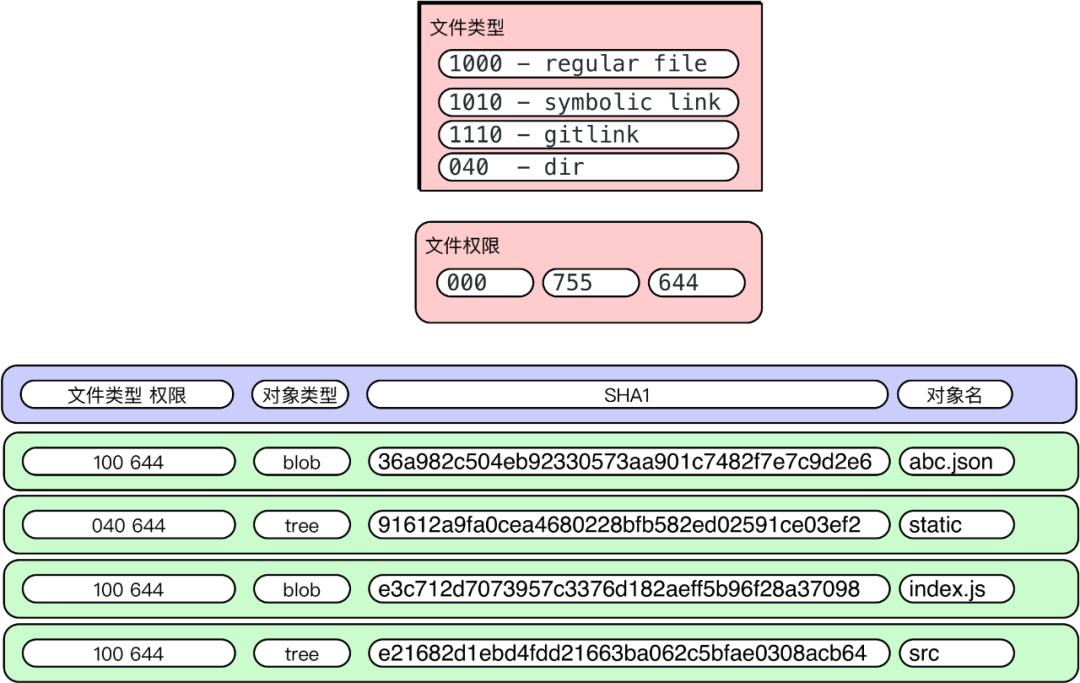
git cat-file -t ed807a4d010a06ca83d448bc74c6cc79121c07c3treegit cat-file -p ed807a4d010a06ca83d448bc74c6cc79121c07c3100644 blob 36a982c504eb92330573aa901c7482f7e7c9d2e6 .cise.yml100644 blob c439a8da9e9cca4e7b29ee260aea008964a00e9a .eslintignore100644 blob 245b35b9162bec4ef798eb05b533e6c98633af5c .eslintrc100644 blob 10123778ec5206edcd6e8500cc78b77e79285f6d .gitignore100644 blob 1a48aa945106d7591b6342585b1c29998e486bf6 README.md100644 blob 514f7cb2645f44dd9b66a87f869d42902174fe40 abc.json040000 tree 8955f46834e3e35d74766639d740af922dcaccd3 cli_list100644 blob f7758d0600f6b9951cf67f75cf0e2fabcea55771 dep.json040000 tree e2b3ee59f6b030a45c0bf2770e6b0c1fa5f1d8c7 doc100644 blob e3c712d7073957c3376d182aeff5b96f28a37098 index.js040000 tree b4aadab8fc0228a14060321e3f89af50ba5817ca lib040000 tree 249eafef27d9d8ebe966e35f96b3092d77485a79 mock100644 blob 95913ff73be1cc7dec869485e80072b6abdd7be4 package.json040000 tree e21682d1ebd4fdd21663ba062c5bfae0308acb64 src040000 tree 91612a9fa0cea4680228bfb582ed02591ce03ef2 static040000 tree d0265f130d2c5cb023fe16c990ecd56d1a07b78c task100644 blob ab04ef3bda0e311fc33c0cbc8977dcff898f4594 webpack.config.js100644 blob fb8e6d3a39baf6e339e235de1a9ed7c3f1521d55 webpack.dll.config.js040000 tree 5dd44553be0d7e528b8667ac3c027ddc0909ef36 webpack
git cat-file -t fbf9e415f77008b780b40805a9bb996b37a6ad2ccommitgit cat-file -p fbf9e415f77008b780b40805a9bb996b37a6ad2ctree bd31831c26409eac7a79609592919e9dcd1a76f2parent d62cf8ef977082319d8d8a0cf5150dfa1573c2b7author xxx 1502331401 +0800committer xxx 1502331401 +0800修复增量bug
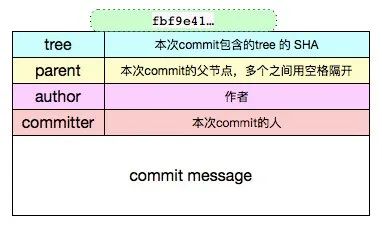
git tag tagNamegit cat-file -t v4commitgit cat-file -p v4tree ceab4f96440655b0ff1a783316c95450fa1fb436parent 7f23c9ca70ce64fc58e8c7507c990c6c6a201d3dauthor 与水 1506224164 +0800committer 与水 1506224164 +0800rawtest2
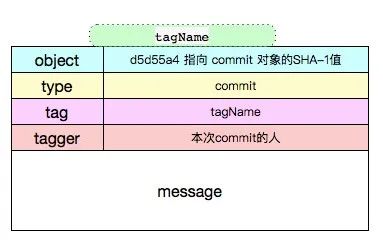
git tag -a tagName -m''git cat-file -t v3taggit cat-file -p v3object d5d55a49c337d36e16dd4b05bfca3816d8bf6de8 //commit 对象SHA-1type committag v3tagger xxx 1506230900 +0800与水测试标注型tag
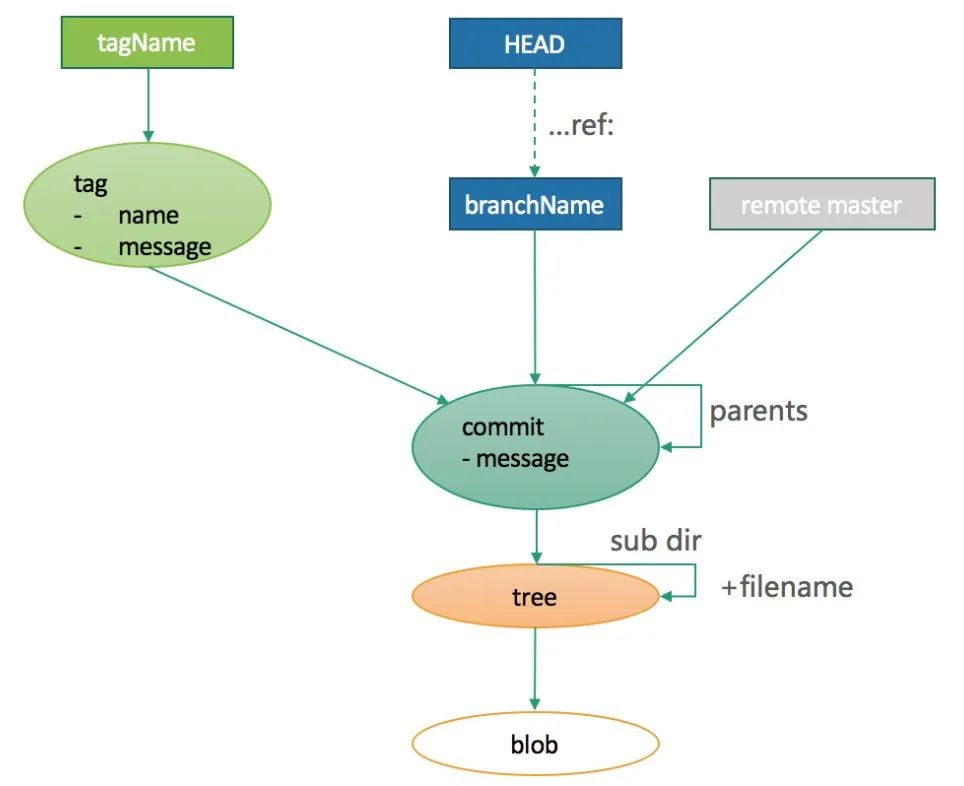
→ cd .git/objects/→ ls03 28 7f ce d0 d5 e6 f9 info pack
→ cd pack→ lspack-efbf3149604d24e6ea427b025da0c59245b2c2ea.idx pack-efbf3149604d24e6ea427b025da0c59245b2c2ea.pack
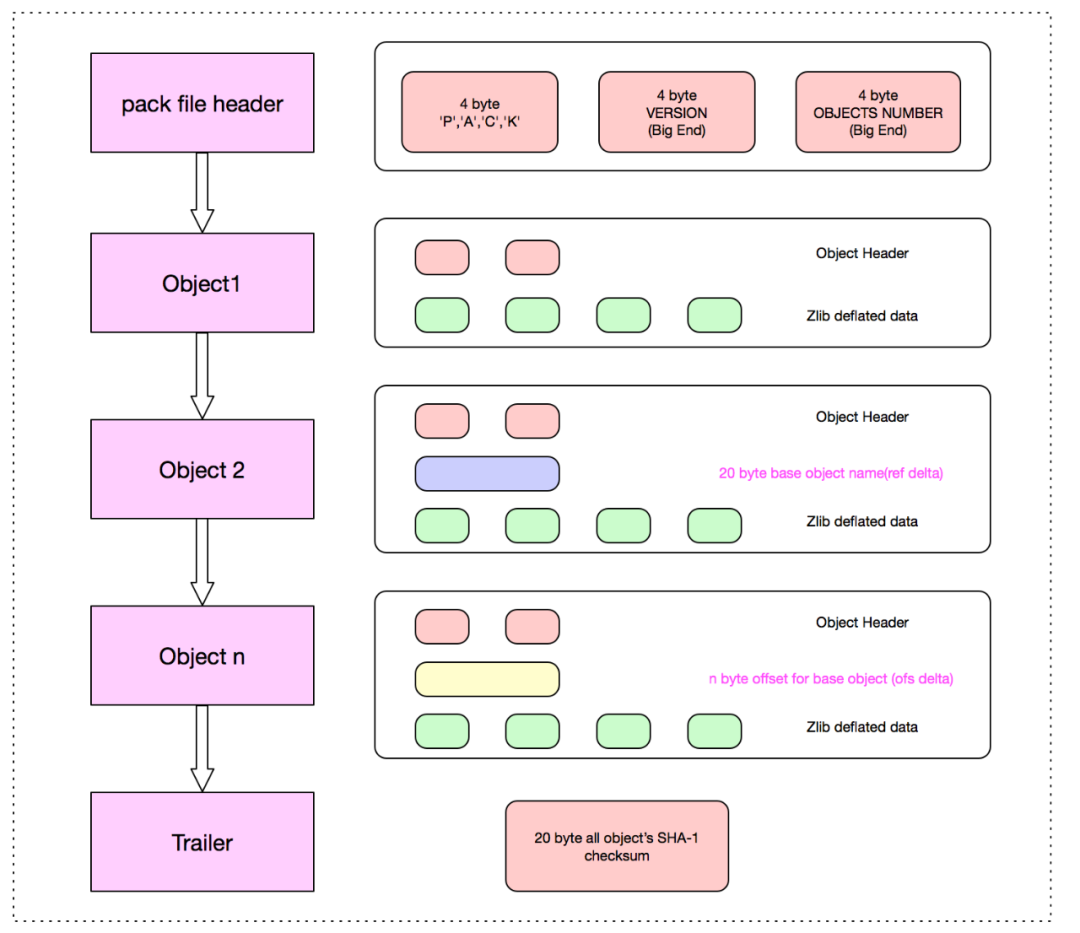
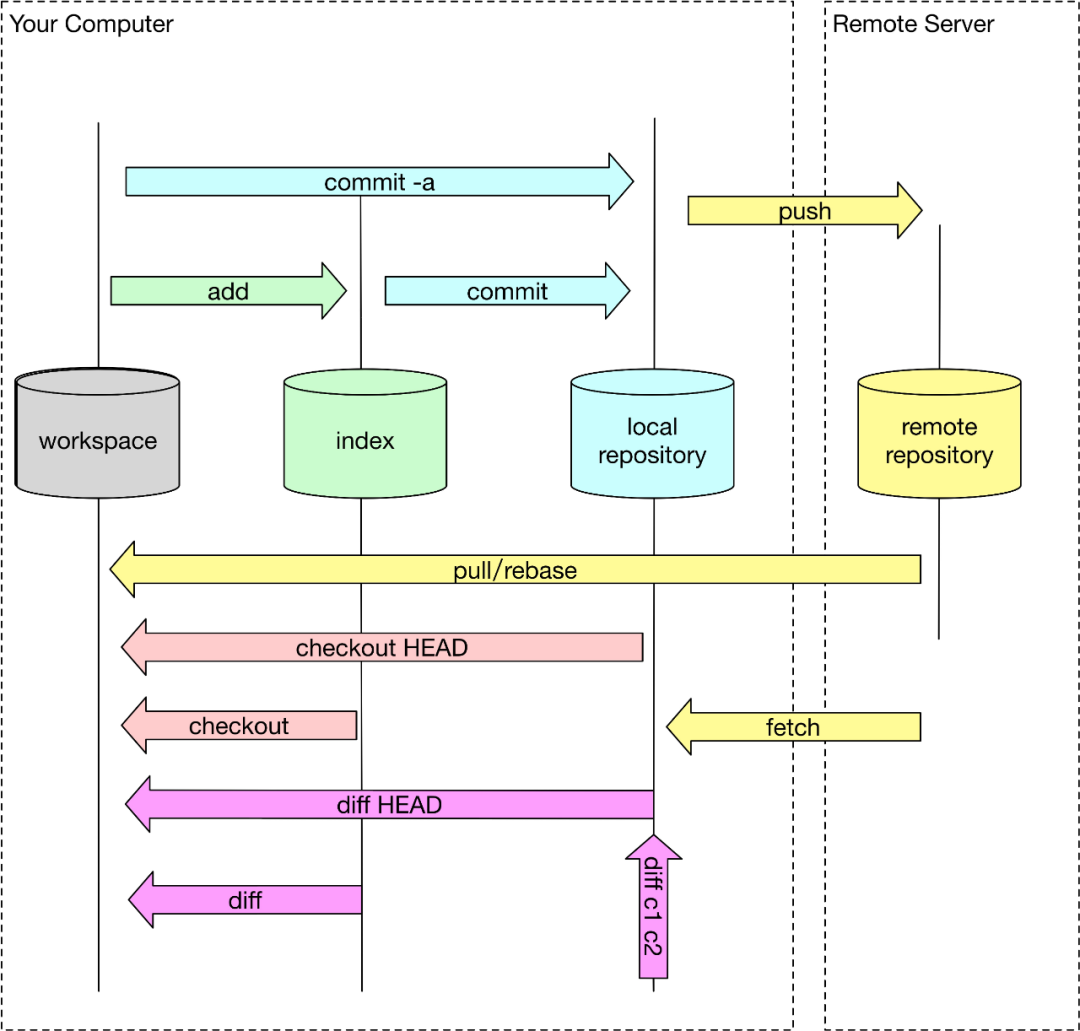
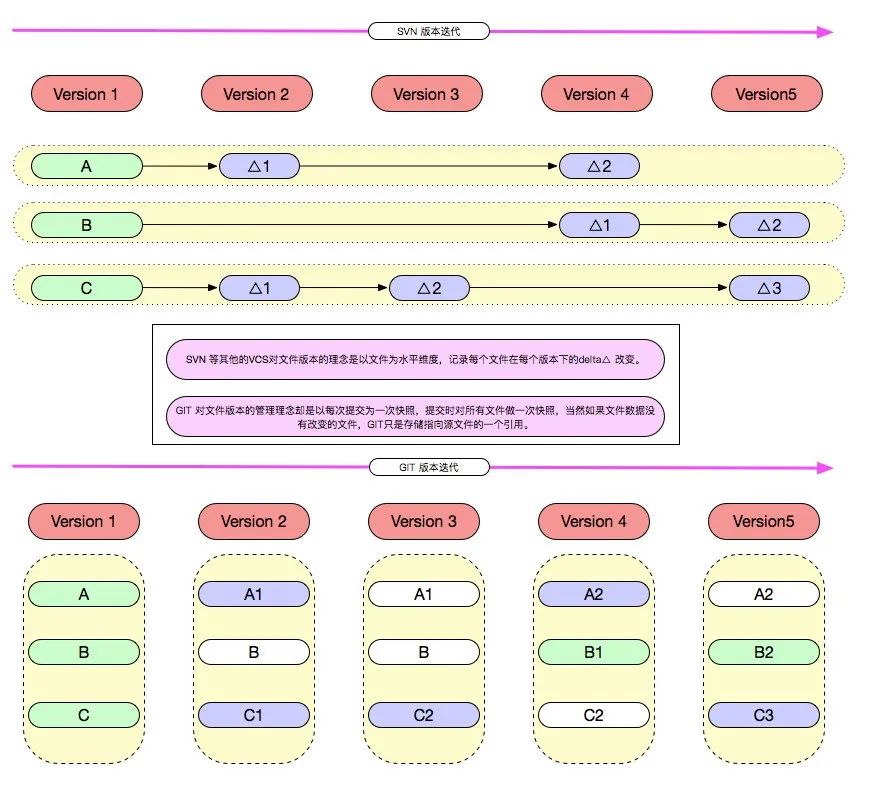
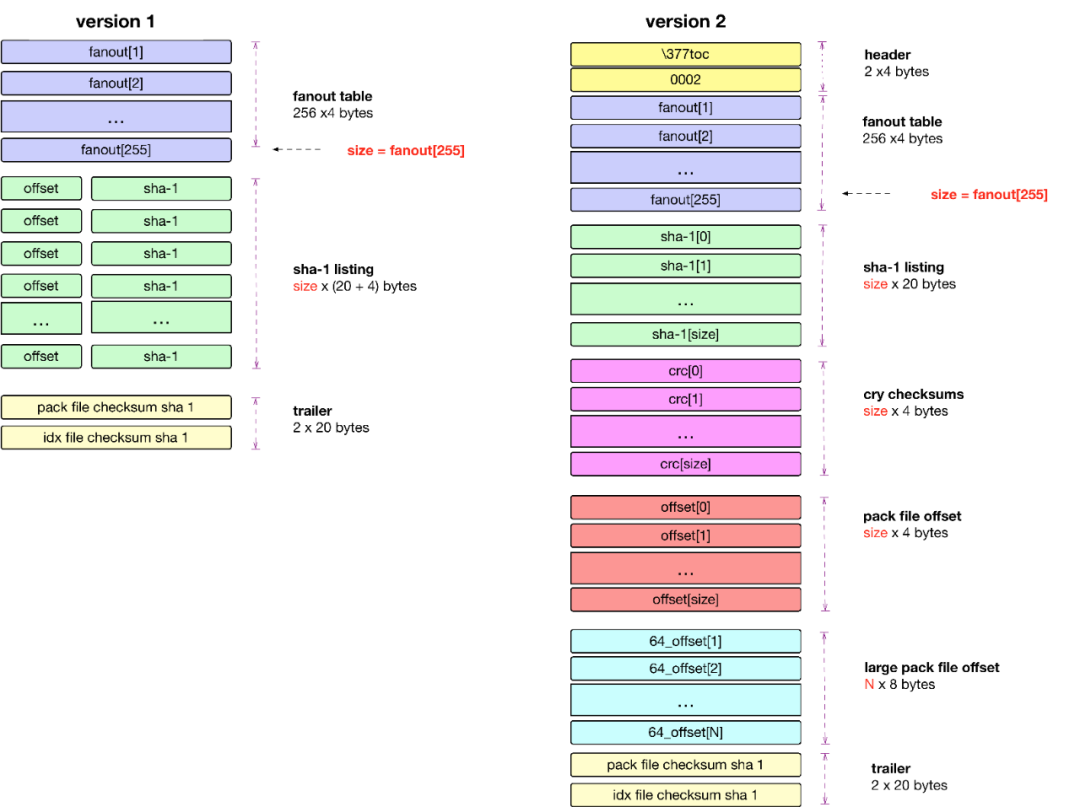
Header 部分主要 4-byte "PACK", 4-byte "版本号", 4-byte "Object 条目数"。
Body 部分主要是一个个 Git 对象依次存储,存储位置在 idx 索引文件中记录改对象在 pack 文件中的偏移量 offset。
Trailer 部分主要是所有 Objects 的名 (SHA-1)的校验和,为了安全可靠的文件传输。
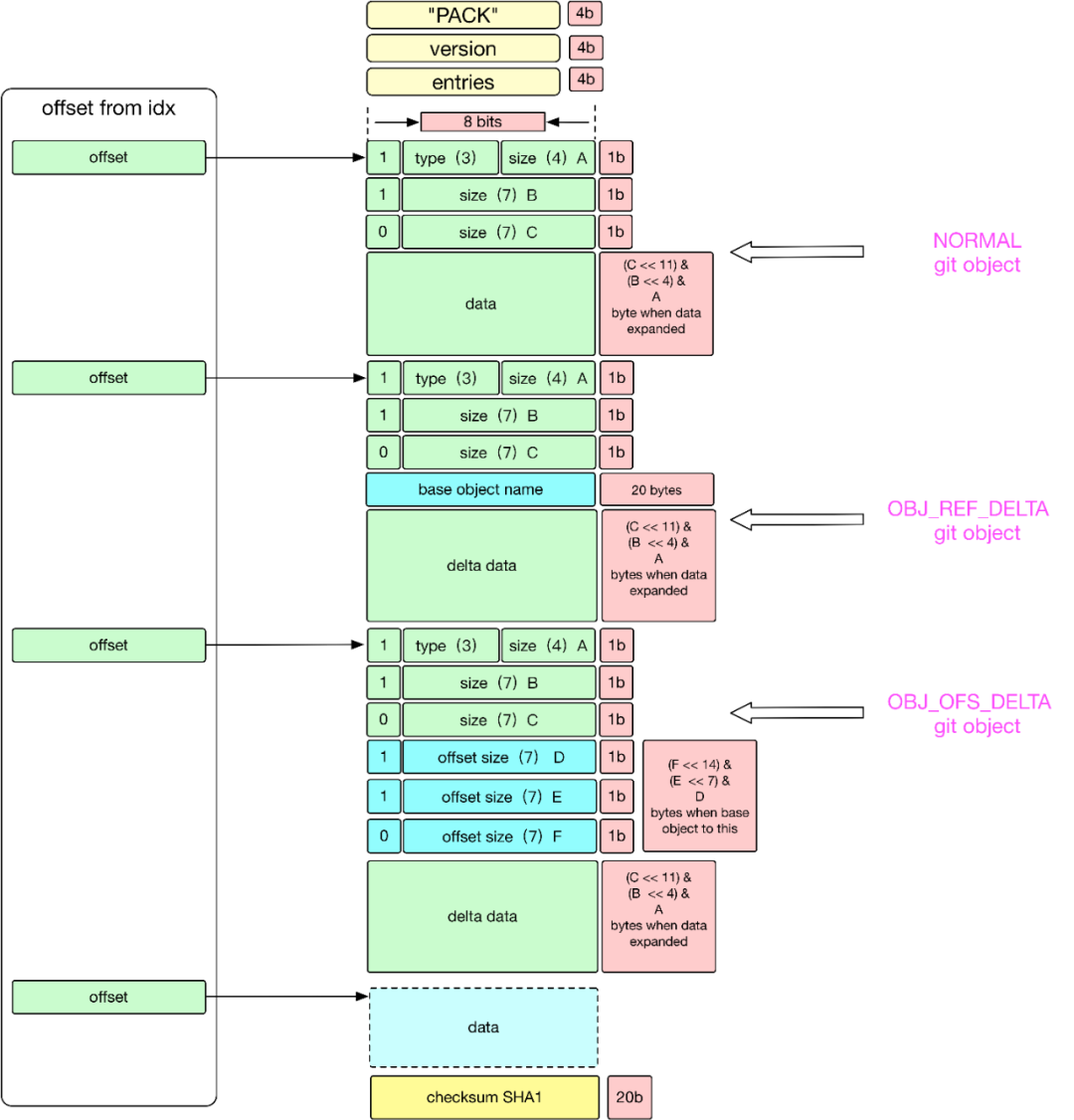
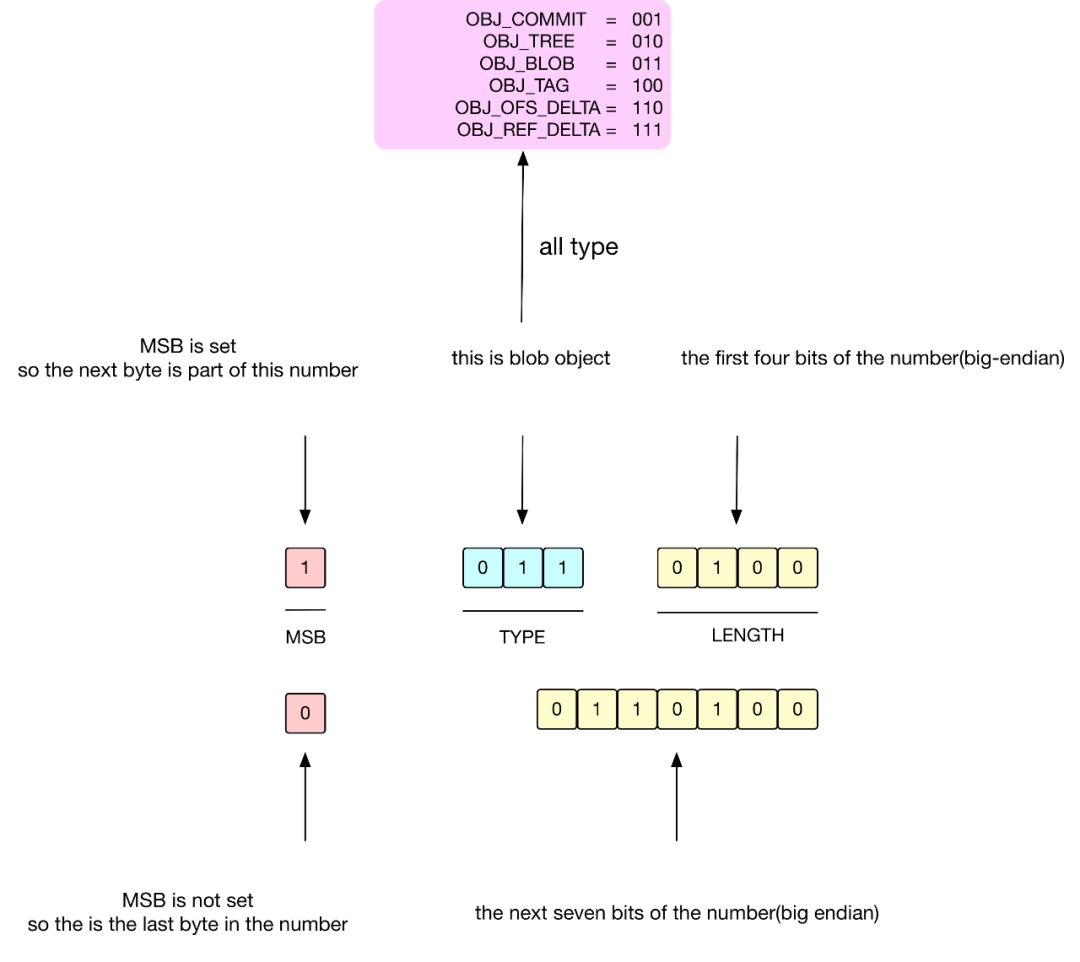
如果 8-bits 中第一位是 1,表示下一个字节还是 header 的一部分,用于表示该对象展开的大小。
如果 8-bits 中第一位是 0,表示从下一个字节开始,将是数据 Data 文件。
如果对象类型是 OBJ_OFS_DELTA 类型, 表示的是 Delta 存储,当前 git 对象只是存储了增量部分,对于基本的部分将由接下来的可变长度的字节数用于表示 base object 的距离当前对象的偏移量,接下来的可变字节也是用 1-bit MSB 表示下一个字节是否是可变长度的组成部分。对偏移量取负数,就可知 base 对象在当前对象的前面多少字节。
如果对象类型是 OBJ_REF_DELTA 类型,表示的是 Delta 存储,当前 git 对象只是存储了增量部分,对于基本的部分,用 20-bytes 存储 Base Object 的 SHA-1 。
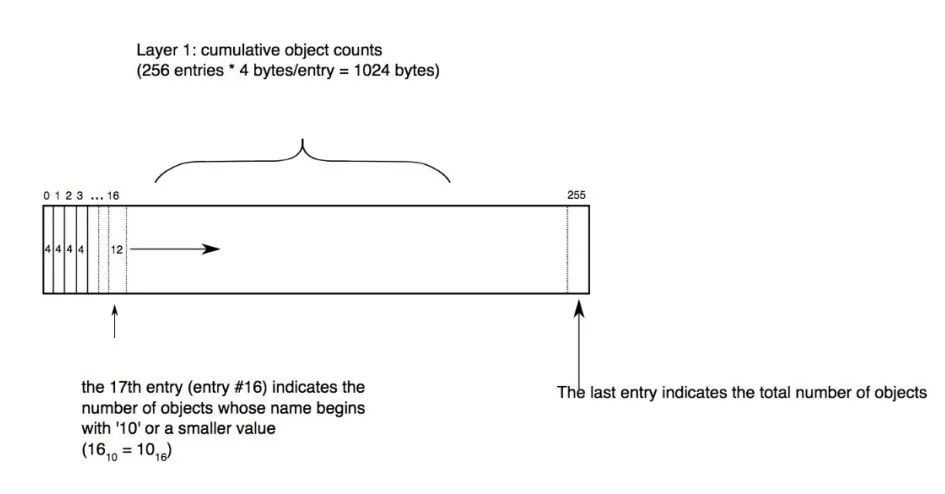
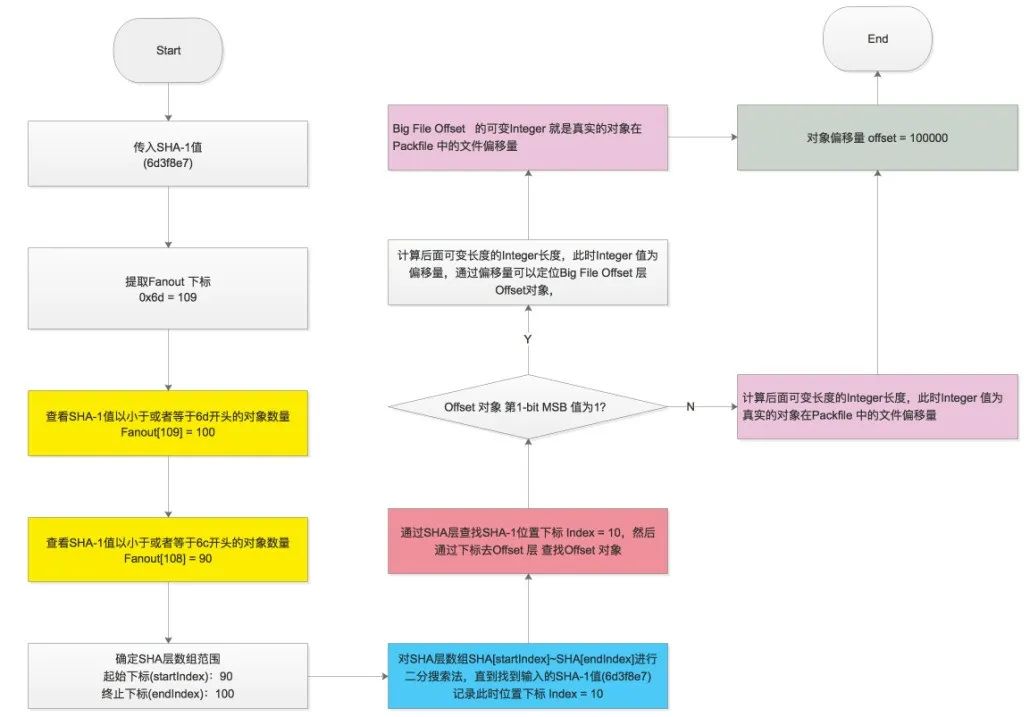
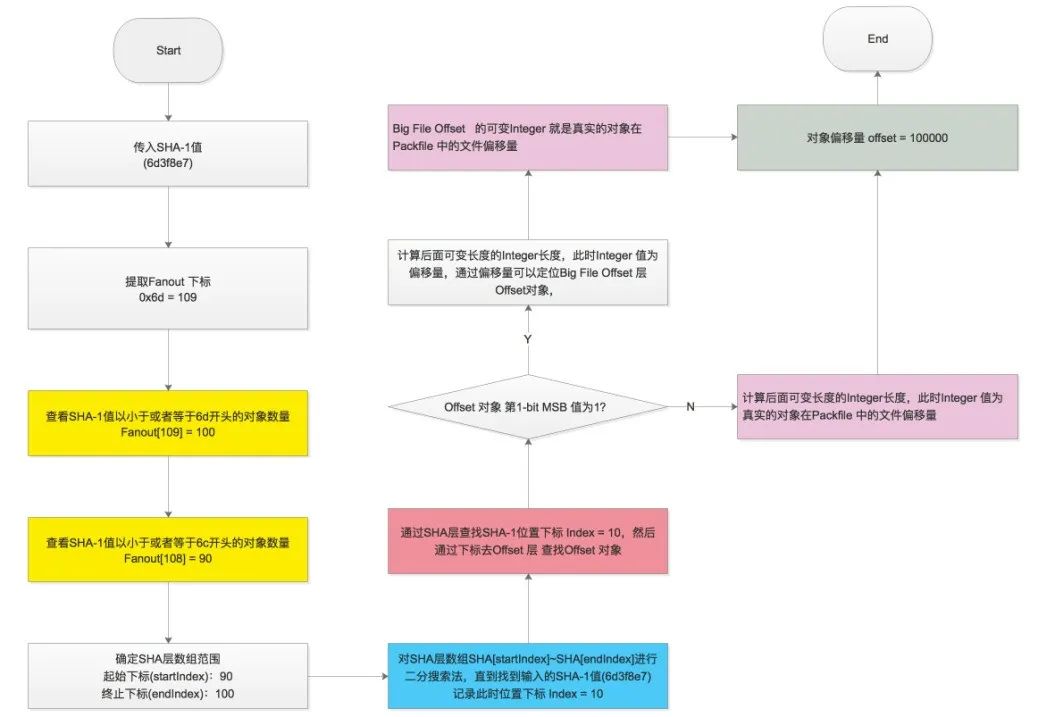
SHA-1 type size size-in-packfile offset-in-packfileSHA-1 type size size-in-packfile offset-in-packfile depth base-SHA-1git verify-pack -v pack-efbf3149604d24e6ea427b025da0c59245b2c2ea.packcb5a93c4cf9c0ee5b7153a3a35a4fac7a7584804 commit 275 189 12399334856af4ca4b49c0008a25b6a9f524e40350 commit 69 81 201 1 cb5a93c4cf9c0ee5b7153a3a35a4fac7a7584804e0efbd5121c31964af1615cf24135a7c6c11cc1d commit 268 187 2827bc9a5e0199bd4a6d4d223ce7e13239631df9635 commit 29 41 469 1 e0efbd5121c31964af1615cf24135a7c6c11cc1d2e43c62f6ff99c88d20329487137f8dbabc8b3ec commit 220 157 510b6f173085f49f109a00b2a3f08a7dc499cc47f1f commit 220 157 6670466b3f1aadde74234f7dd3f4ef7f1505c50fb0c commit 220 157 82476c5e45f8e295226b1bc5c8c7e2bc98d7eae6be1 commit 74 85 981 1 b6f173085f49f109a00b2a3f08a7dc499cc47f1f2729f1fa896d384b49a2f5c53d483eacc0929ebb commit 172 127 10663cc58df83752123644fef39faab2393af643b1d2 blob 2 11 119362189d1a10cc2a544c4e5b9c4aba9493cf5782dc blob 8 15 1204a9a5aecf429fd8a0d81fbd5fd37006bfa498d5c1 blob 4 13 12192b8982f7c281964658d2cd8b6c17b541533dd277 tree 104 105 123292c4aafa39ee387a1f8237f00c78c499aebaf0b2 tree 104 105 1337223b7836fb19fdf64ba2d3cd6173c6a283141f78 blob 2 11 14421756ca64f21724f350fe2cc5cfb218883e314c3d tree 71 80 1453e11ddfa79f01b01a8e1553bbffaa2d6c03ae9f6e tree 71 80 1533f70f10e4db19068f79bc43844b49f3eece45c4e8 blob 2 11 1613e982b6207b10a869164e2c8d19d25ffb059e6a16 tree 66 73 1624f2e9f73f27124916344e0fd03bb449bc6feca59d tree 66 74 1697d09da444f461d7cee3679666a1ded5ab79832ed0 tree 33 44 1771non delta: 18 objectschain length = 1: 3 objects: ok
https://stackoverflow.com/questions/8198105/how-does-git-store-files https://www.npmjs.com/package/git-apply-delta https://git-scm.com/book/en/v2/Git-Internals-Packfiles https://codewords.recurse.com/issues/three/unpacking-git-packfiles http://shafiulazam.com/gitbook/7_the_packfile.html http://wiki.jikexueyuan.com/project/git-community-book/packfile.html http://documentup.com/skwp/git-workflows-book http://www.runoob.com/git/git-workspace-index-repo.html http://shafiulazam.com/gitbook/1_the_git_object_model.html http://eagain.net/articles/git-for-computer-scientists/ https://www.kernel.org/pub/software/scm/git/docs/user-manual.html#object-details https://stackoverflow.com/documentation/git/topics https://stackoverflow.com/search?page=2&tab=Votes&q=user%3a1256452%20%5bgit%5d http://git.oschina.net/progit/9-Git-%E5%86%85%E9%83%A8%E5%8E%9F%E7%90%86.html#9.5-The-Refspec https://codewords.recurse.com/issues/three/unpacking-git-packfiles http://shafiulazam.com/gitbook/7_the_packfile.html https://w.org/pub/software/scm/git/docs/user-manual.html#object-details
程序员需要哪些软技能?
程序员想要不断自我提升,除了持续精进技术之外,还需要哪些必备的软技能?在职业、学习上有没有可行的建议?程序员也需要自我营销吗?识别下方二维码,或点击文末“阅读原文”,了解程序员编程之外的升值之道:

推荐阅读
看完这一篇,再也不用担心 Git 的“黑魔法”
阿里资深技术专家的 10 年感悟
这一团糟的代码,真的是我写的?!