推荐系统中的"忘不了"

今天聊聊一个优秀的推荐系统应具备的重要能力--记忆力。
你是否有过这样的经历:上午搜索了夏威夷果,下午刷虎扑就刷到坚果大礼包的广告;昨天点击了火影忍者十大忍术的帖子,今天首页就推荐了四代火影和宇智波鼬谁厉害的分析贴。。。仿佛有人偷窥你的生活,记住了你的一言一行,只能感慨下互联网时代真是毫无隐私啊。
其实一个推荐系统要做到记忆用户行为,根据其历史行为做出更好的推荐,是有很多环节或者说方法要考虑的。比如 session、id mapping、模型等等多个方面。模型而言,大家熟知的 RNN,LSTM,GRU等等都是比较流行的基础算法。上述模型的缺点也很明显,就是对输入数据要求高、计算复杂度高、在线性能开销大。阿里和百度都有一些工作来解决这个问题,从而能够在线上使用具有记忆能力的模型。今天介绍的是阿里工作:Click-Through Rate Prediction with the User Memory Network。文章的主角就是 memory augmented DNN (MA-DNN)。
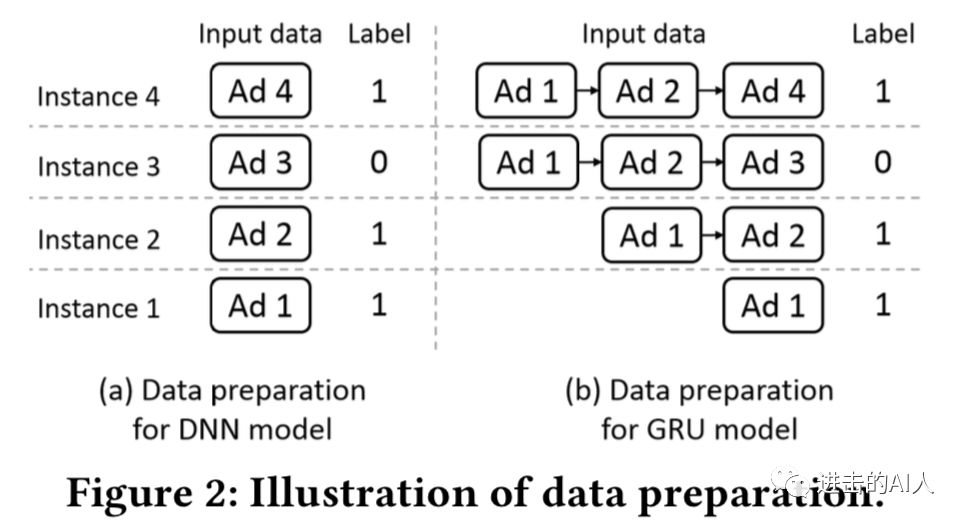
以点击预估模型为例,MA-DNN出发点很简单,就是为了解决传统 DNN 没有记忆能力、而 GRU等模型性能又不行的问题。我们简单回顾下几个模型的对比情况。图1-a 中的结构是传统的 DNN 结构,其训练数据如图2-a 所示,只要把每一条 ins 依次(shuffle 后往往更好)输入即可,模型没有记忆能力。
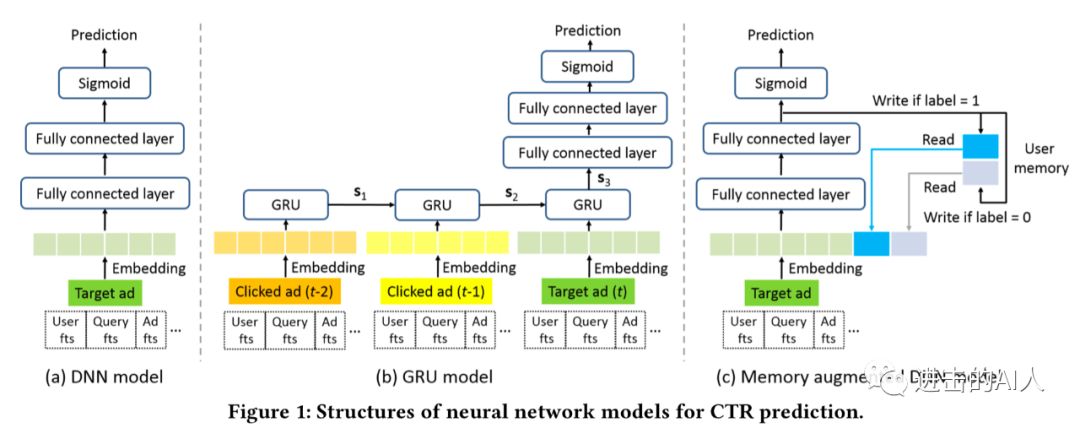
图1-b 中则是一个典型的 GRU 时序模型,具有记忆能力,但是对训练数据的要求很高如图2-b 所示。需要将用户的点击序列提前处理好后再输入给模型。
并且该模型过于复杂,需要存储计算多个 时刻GRU 模块,基本无法用于线上。MA-DNN 提出在 DNN 的基础上增加一个记忆存储向量,从而使得 DNN 具有记忆能力。
MA-DNN 的结构如下图所示,左边是我添加变量注释的模型结构,右边是模型核心的计算步骤。模型结构很简单,左半边是 DNN ,右半边是2个记忆模块mu1和 mu0, 分别代表着用户的点击(喜欢)记忆特征和不点击(不喜欢)记忆特征。预测的时候,对于一个 userid,查询其 mu1/mu0值,然后拼接到原来的 embedding X 上得到最终的底层特征向量输入给 DNN 预估即可。

模型训练的时候,和预估类似,也是查询 userid 的mu1/mu0后进行前向计算得到 loss1和 loss2。然后 loss1 和 loss2分别进行反向传播更新各自的参数。这里要注意,loss1不影响 mu1/mu0的更新,loss2也不影响左侧 FC layer 的参数更新。loss1就是点击率模型常用的 cross-entropy,loss2则是 mu1/mu0分别拟合 ZL 的结果。当 ins 的 label 是0时,则只和 mu0有关,ins 的 label 是1时,则只和 mu1有关。所以mu1/mu0两个向量特征分别刻画着 click/non-click 或者说 like/dislike 的语义。MA-DNN 就是利用这样一个简单的结构来实现对 userid 维度进行历史行为的记忆。
虽然文章脉络写的很好,想要营造一种" MA-DNN 只在 DNN 基础上稍加改进便实现了 GRU 的能力"。但是实际上,MA-DNN 和 GRU 并无太大关系,也不可能完全实现其记忆能力。MA-DNN 更像是 在传统的 embedding 大法上增加了一个长期的有时间顺序的 feature embedding。不过模型的设计确实简洁高效,用起来工作量也不大,值得在广告和推荐场景下尝试一下。下面是一些实际场景应用时需要考虑的点,应具体问题具体分析,不可盲目套用。
用户漂移是否严重,历史行为是否多,历史窗口时长选择
能否应用到user以外的历史行为类id
扩展到其他含义 label,不仅仅点击和不点击
运用到双塔模型结构中效果是否鲁棒
以上是今天的分享笔记~
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。




