在线推理和在线学习,从两大层级看实时机器学习的应用现状
选自huyenchip.com
作者:Chip Huyen
机器之心编译
编辑:Panda
实时机器学习正得到越来越广泛的应用和部署。近日,计算机科学家和 AI 领域科技作家 Chip Huyen 在其博客中总结了实时机器学习的概念及其应用现状,并对比了实时机器学习在中美两国的不同发展现状。
与美国、欧洲和中国一些大型互联网公司的机器学习和基础设施工程师聊过之后,我发现这些公司可以分为两大类。一类公司重视实时机器学习的基础设施投资(数亿美元),并且已经看到了投资回报。另一类公司则还在考虑实时机器学习是否有价值。
对于实时机器学习的含义,现在似乎还没有明确的共识,而且也还没有人深入探讨过产业界该如何做实时机器学习。我与数十家在做实时机器学习的公司聊过之后,总结整理了这篇文章。
本文将实时机器学习分为两个层级:
层级 1:机器学习系统能实时给出预测结果(在线预测)
层级 2:机器学习系统能实时整合新数据并更新模型(在线学习)
本文中的「模型」指机器学习模型,「系统」指围绕模型的基础设施,包括数据管道和监测系统。
层级 1:在线预测
这里「实时」的定义是指毫秒到秒级。
用例
延迟很重要,对于面向用户的应用而言尤其重要。2009 年,谷歌的实验表明:如果将网络搜索的延迟从 100 ms 延长至 400 ms,则平均每用户的日搜索量会降低 0.2%-0.6%。2019 年,Booking.com 发现延迟增加 30%,转化率就会降低 0.5% 左右——该公司称这是「对业务有重大影响的成本」。
不管你的机器学习模型有多好,如果它们给出预测结果的时间太长,就算只是毫秒级,用户也会转而点击其它东西。
批量预测的问题
一个称不上解决方案的措施是不使用在线预测。你可以用离线方法批量生成预测结果,然后将它们保存起来(比如保存到 SQL 表格中),最后在需要时拉取已有的预测结果。
当输入空间有限时,这种方法是有效的——毕竟你完全知道有多少可能的输入。举个例子,如果你需要为你的用户推荐电影。你已经知道有多少用户,那么你可以每隔一段时间(比如每几个小时)为每个用户生成一组推荐。
为了让用户输入空间有限,很多应用采取的方法是让用户从已有类别中选择,而不是让用户输入查询。例如,如果你进入旅游出行推荐网站 TripAdvisor,你必须首先选择一个预定义的都会区,而无法直接输入任何位置。
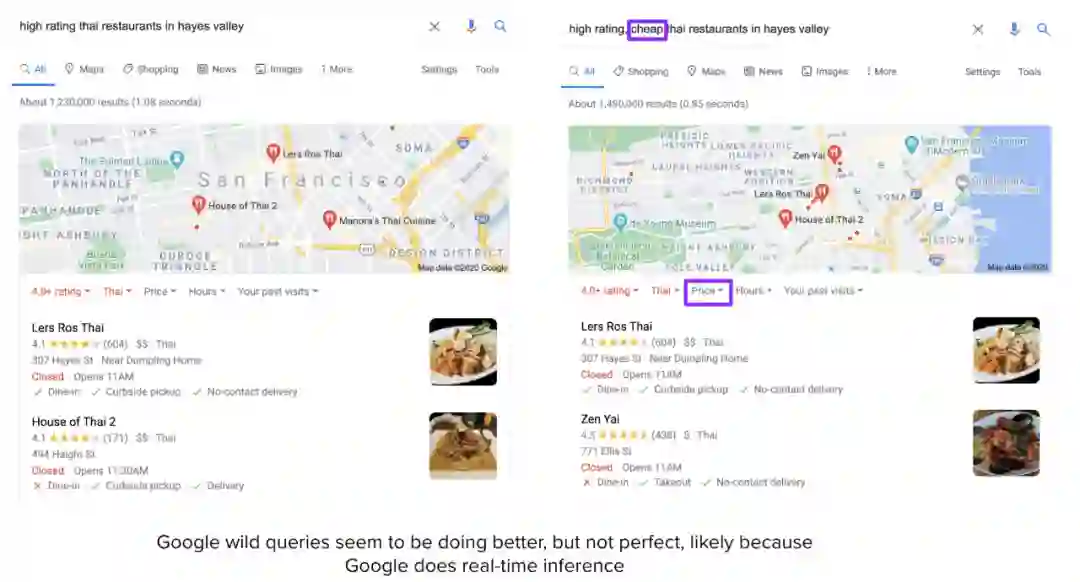
这种方法存在很多局限性。TripAdvisor 在其预定义的类别内表现还算可以,比如「旧金山」的「餐厅」,但如果你想自己输入「Hayes Valley 的高分泰式餐厅」这样的查询,那么结果会相当差。
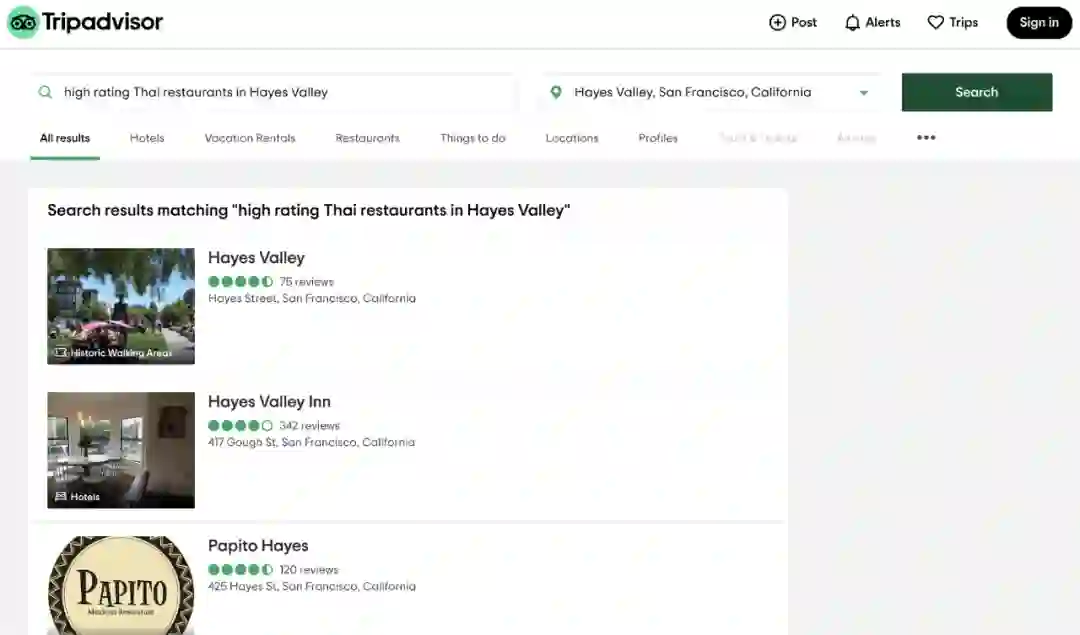
甚至很多技术较为激进的公司也会使用批量预测,并由此显现出其局限性,比如 Netflix。如果你最近看了很多恐怖片,那么当你再次登录 Netflix 时,推荐电影中大部分会是恐怖片。但如果你今天心情愉悦,搜索了「喜剧」开始浏览喜剧类别,那么 Netflix 应该学习并在推荐列表中展示更多喜剧吧?然而,它在生成下一个批量推荐列表之前并不会更新当前列表。
在上面的两个例子中,批量预测会降低用户体验(这与用户参与和用户留存紧密相关),但不会导致灾难性的后果。其它这类例子还有广告排序、Twitter 的热门趋势标签排序、Facebook 的新闻订阅排序、到达时间估计等等。
还有一些应用,如果没有在线预测会出现灾难性的后果,甚至变得毫无作用,比如高频交易、自动驾驶汽车、语音助手、手机的人脸 / 指纹解锁、老年人跌倒检测、欺诈检测等。虽然在欺诈交易发生 3 小时后检测到比检测不到要好一些,但如果能实时检测到欺诈,就可以直接防止其发生了。
如果将批量预测换成实时预测,我们就可以使用动态特征来得到更相关的预测结果。静态特征是变化缓慢或不变化的信息,比如年龄、性别、工作、邻居等。动态特征是基于当前状况的特征,比如你正在看什么节目、刚刚给什么内容点了赞等。如果能知晓用户现在对什么感兴趣,那么系统就能给出更加相关的推荐。
解决方案
要让系统具备在线预测能力,它必须要用两个组件:
快速推理:模型要能在毫秒级时间内给出预测结果;
实时数据管道:能够实时处理数据、将其输入模型和返回预测结果的流程管道。
1. 快速推理
当模型太大或预测时间太长时,可采用的方法有三种:
让模型更快(推理优化)
比如聚合运算、分散运算、内存占用优化、针对具体硬件编写高性能核等。
让模型更小(模型压缩)
起初,这类技术是为了让模型适用于边缘设备,让模型更小通常能使其运行速度更快。最常见的模型压缩技术是量化(quantization),比如在表示模型的权重时,使用 16 位浮点数(半精度)或 8 位整型数(定点数),而不是使用 32 位浮点数(全精度)。在极端情况下,一些人还尝试了 1 位表征(二元加权神经网络),如 BinaryConnect 和 Xnor-net。Xnor-net 的作者创立了一家专注模型压缩的创业公司 Xnor.ai,并已被苹果公司以 2 亿美元收购。
另一种常用的技术是知识蒸馏,即训练一个小模型(学生模型)来模仿更大模型或集成模型(教师模型)。即使学生模型通常使用教师模型训练得到,但它们也可能同时训练。在生产环境中使用蒸馏网络的一个例子是 DistilBERT,它将 BERT 模型减小了 40%,同时还保留了 BERT 模型 97% 的语言理解能力,速度却要快 60%。
其它技术还包括剪枝(寻找对预测最无用的参数并将它们设为 0)、低秩分解(用紧凑型模块替代过度参数化的卷积滤波器,从而减少参数数量、提升速度)。详细分析请参阅 Cheng 等人 2017 年的论文《A Survey of Model Compression and Acceleration for Deep Neural Networks》。
模型压缩方面的研究论文数量正在增长,可直接使用的实用程序也在迅速增多。相关的开源项目也不少,这里有一份 40 大模型压缩开源项目列表:https://awesomeopensource.com/projects/model-compression。
让硬件更快
这是另一个蓬勃发展的研究领域。大公司和相关创业公司正竞相开发新型硬件,以使大型机器学习模型能在云端和设备端(尤其是设备)更快地推理乃至训练。据 IDC 预测,到 2020 年,执行推理的边缘和移动设备总数将达 37 亿台,另外还有 1.16 亿台被用于执行训练。
2. 实时数据管道
假设你有一个驾乘共享应用并希望检测出欺诈交易,比如使用被盗信用卡支付。当该信用卡的实际所有者发现未授权支付时,他们会向银行投诉,你就必须退款。为了最大化利润,欺诈者可能会连续多次叫车或使用多个账号叫车。2019 年,商家估计欺诈交易平均占年度网络销售额的 27%。检测出被盗信用卡的时间越长,你损失的钱就会越多。
为了检测一项交易是否为欺诈交易,仅检查交易本身是不够的。你至少需要检查该用户在该交易方面的近期历史记录、他们在应用内的近期行程和活动、该信用卡的近期交易以及在大约同一时间发生的其它交易。
为了快速获得这类信息,你需要尽可能地将这些信息放在内存之中。每当一件你关心的事情发生时,比如用户选择了一个位置、预定了一次行程、联系了一位司机、取消了一次行程、添加了一张信用卡、移除了一张信用卡等,关于该事件的信息都要进入你的内存库。只要这些信息还有用,它们就会一直留在内存里(通常是几天内的事件),然后再被放入永久存储库(比如 S3)或被丢弃。针对该任务,最常用的工具是 Apache Kafka,此外还有 Amazon Kinesis 等替代工具。Kafka 是一种流式存储,可在数据流动时保存数据。
流式数据不同于静态数据,静态数据是已完全存在于某处的数据,比如 CSV 文件。当从 CSV 文件读取数据时,你知道该任务什么时候结束。而流式数据不会结束。
一旦你有了某种管理流式数据的方法,你需要将其中的特征提取出来,然后输入机器学习模型中。在流式数据的特征之上,你可能还需要来自静态数据的特征(当该账号被创建时,该用户的评分是多少等等)。你需要一种工具来处理流式数据和静态数据,以及将来自多个数据源的数据组合到一起。
流式处理 vs 批处理
人们通常使用「批处理」指代静态数据处理,因为这些数据可以分批处理。这与即到即处理的「流式处理」相反。批处理的效率很高——你可以使用 MapReduce 等工具来处理大量数据。流式处理的速度很快,因为你可以在每一份数据到达时马上就完成处理。Apache Flink 的一位 PMC 成员 Robert Metzger 则有不同意见,他认为流式处理可以做到像批处理一样高效,因为批处理是流式处理的一种特殊形式。
处理流数据的难度更大,因为数据量没有限定,而且数据输入的比率和速度也会变化。比起用批处理器来执行流式处理,使用流式处理器来执行批处理要更容易。
Apache Kafka 有一些流式处理的能力,某些公司将这些能力置于它们的 Kafka 流式存储之上,但 Kafka 流式处理在处理不同数据源方面的能力比较有限。还有一些扩展 SQL 使其支持流数据的努力,SQL 是为静态数据表设计的一种常用查询语言。不过,最常用的流式处理工具还是 Apache Flink,而且它还有原生支持的批处理。
在机器学习生产应用的早期,很多公司都是在已有的 MapReduce/Spark/Hadoop 数据管道上构建自己的机器学习系统。当这些公司想做实时推理时,它们需要为流式数据构建一个单独的数据管道。
使用两个不同的管道来处理数据是机器学习生产过程中常见 bug 的来源,比如如果一个管道没有正确地复制到另一个管道中,那么两个管道可能会提取出两组不同的特征。如果这两个管道由不同的团队维护,那么这会是尤其常见的问题,比如开发团队维护用于训练的批处理管道,而部署团队则维护用于推理的流式处理管道。为了将 Flink 整合进批处理和流式处理流程中,包括 Uber 和微博在内的公司都对它们的基础设施进行了重大检修。
事件驱动型方法 vs 请求驱动型方法
过去十年,软件世界已经进入了微服务时代。微服务的思路是将业务逻辑分解成可独立维护的小组件——每个小组件都是一个可独立运行的服务。每个组件的维护者都可以在不咨询该系统其余部分的情况下快速更新和测试该组件。
微服务通常与 REST 紧密结合,这是一套可让微服务互相通信的方法。REST API 是需求驱动型的。客户端(服务)会通过 POST 和 GET 之类的方法向服务器发送明确的请求,然后服务器返回响应结果。为了注册请求,服务器必须监听请求。
因为在请求驱动的世界中,数据是根据向不同服务的请求而处理的,所以没有一项服务了解数据如何流经整个系统的整体情况。我们来看一个包含 3 项服务的简单系统:
A 服务管理可接单的司机
B 服务管理出行需求
C 服务预测每次展示给有需求客户的最佳可能定价
由于价格取决于供需关系,因此服务 C 的输出取决于服务 A 和 B 的输出。首先,该系统需要服务之间的通信:为了执行预测,C 需要查询 A 和 B;而 A 需要查询 B 才能知道是否需要移动更多司机,A 还要查询 C 以了解怎样的定价比较合适。其次,我们没法轻松地监控 A 或 B 的逻辑对 C 性能的影响,也没法在 C 性能突然下降时轻松地对数据流执行映射以进行调试。
才不过三项服务,情况就已经很复杂了。想象一下,如果有成百上千项服务——就像现在的主流互联网公司那样,服务间的通信将多得难以实现。通过 HTTP 以 JSON blob 形式发送数据是 REST 请求的常用模式,但这种方法的速度很慢。服务间的数据传输可能会变成瓶颈,拖慢整个系统的速度。
如果我们不再让 20 项服务向 A 发送请求,而是每当 A 中有事件发生时,该事件都被广播到一个数据流中,这样无论哪个服务需要 A 的数据,都可以订阅该数据流,然后选择其所需的部分?如果有一个所有服务都可以广播事件并且订阅的数据流呢?该模式被称为 pub/sub:发布和订阅。Kafka 等解决方案都支持这样的操作。由于所有数据都会流经一个数据流,因此你可以设置一个仪表盘来监控数据及其在系统中的变化情况。因为这种架构基于服务的事件广播,因此被称为事件驱动型方法。
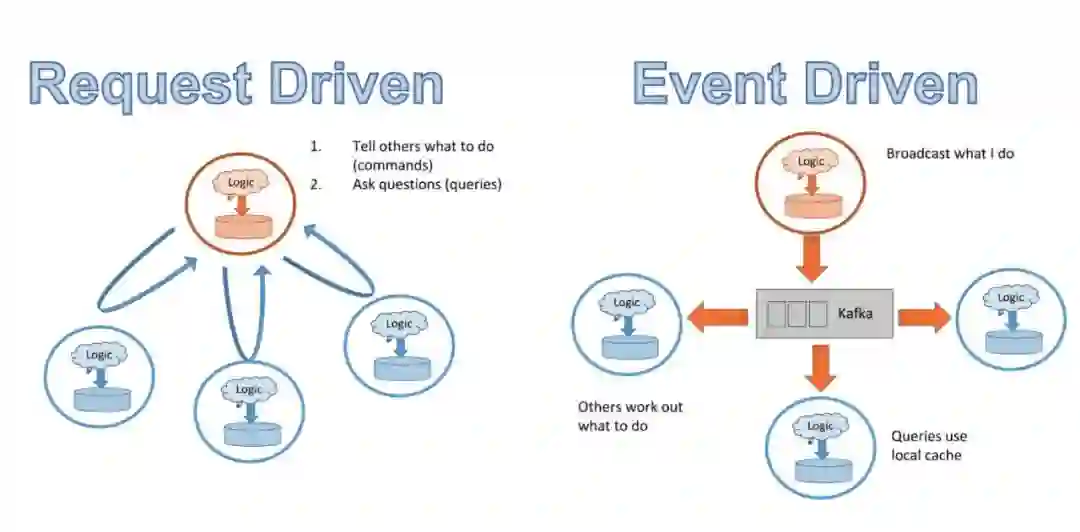
请求驱动型和事件驱动型架构对比。(图源:https://www.infoq.com/presentations/microservices-streams-state-scalability/)
请求驱动型架构适用于更依赖逻辑而非数据的系统,事件驱动型架构则更适合数据量大的系统。
挑战
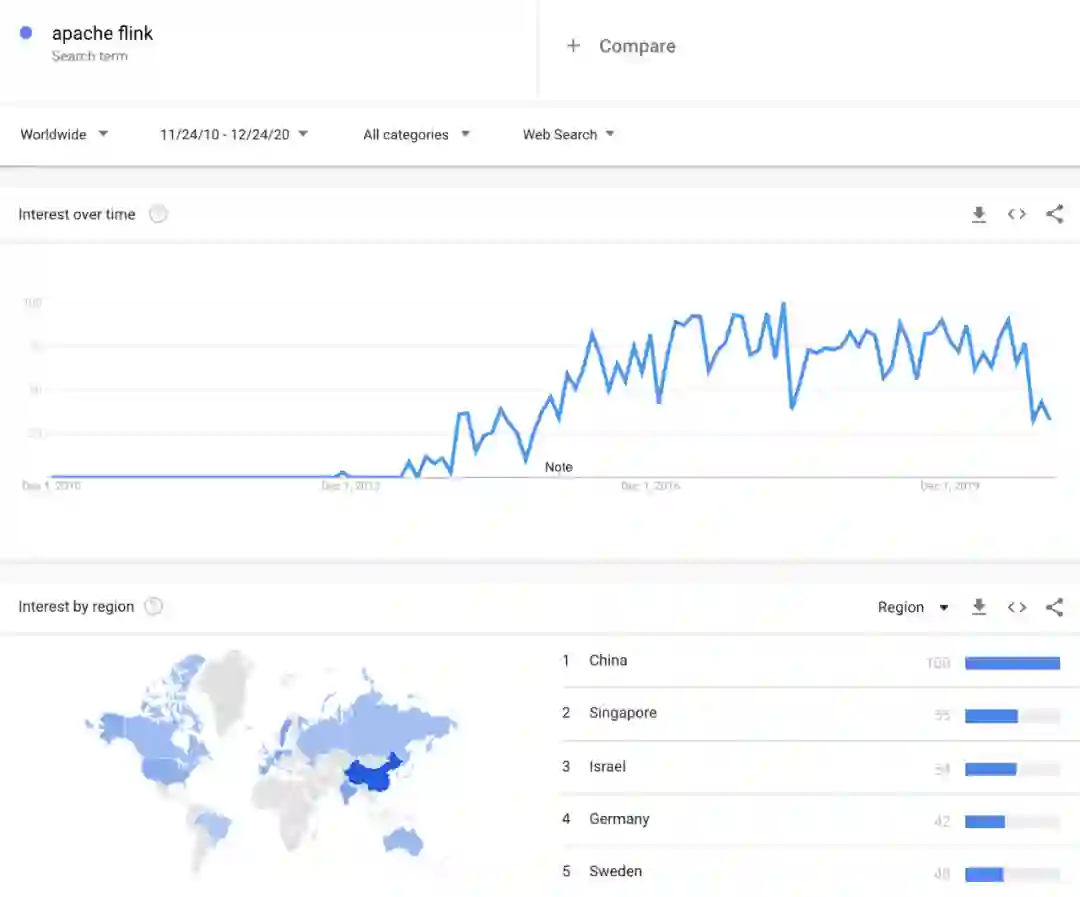
很多公司在从批处理转向流式处理,从请求驱动型架构转向事件驱动型架构。在与美国和中国的主要互联网公司谈过之后,我的感觉是美国这种转变速度要慢一些,而中国的则快得多。流式架构的采用与 Kafka 和 Flink 的流行程度紧密相关。Robert Metzger 告诉我,他观察到亚洲使用 Flink 的机器学习负载比美国的多。「Apache Flink」这个关键词的谷歌搜索趋势与这一观察一致。
流式架构没有更受欢迎的原因有很多:
1. 公司没有看到流式架构的优势。
这些公司的系统规模还没有达到服务间通信会造成瓶颈的程度。
它们没有能受益于在线预测的应用。
它们有能受益于在线预测的应用,但还不知道这一点,因为它们之前从未进行过在线预测。
2. 基础设施所需的前期投资较高。
基础设施更新的成本较高并且可能损害已有应用,管理者不愿意投资升级支持在线预测的基础设施。
3. 思维转换
从批处理转向流式处理需要转换思维。使用批处理,你知道任务会在何时完成。使用流式处理,则无法知晓。你可以制定一些规则,比如获得之前 2 分钟内所有数据点的平均,但如果一个发生在 2 分钟之前的事件被延迟了,还没有进入数据流呢?使用批处理,你可以合并处理定义良好的表格,但在流式处理模式下,不存在可以合并的表格,那么合并两个数据流的操作是什么意思呢?
4. Python 不兼容
Python 算得上是机器学习的通用语言,但 Kafka 和 Flink 基于 Java 和 Scala 运行。引入流式处理可能会导致工作流程中的语言不兼容。Apache Beam 在 Flink 之上提供了一个用于与数据流通信的 Python 接口,但你仍然需要能用 Java/Scala 开发的人。
5. 更高的处理成本
批处理意味着你可以更加高效地使用计算资源。如果你的硬件能够一次处理 1000 个数据点,那么使用它来一次处理 1 个数据点就显得有些浪费了。
层级 2:在线学习
这里的「实时」定义在分钟级。
定义「在线学习」
我使用的词语是「在线学习」而非「在线训练」,原因是后者存在争议。根据定义,在线训练的意思是基于每个输入的数据点进行学习。非常少的公司会真正这么做,原因包括:
这种方法存在灾难性遗忘的问题——神经网络在学习到新信息时会突然遗忘之前学习的信息。
基于单个数据点的学习流程比基于批量数据的学习流程成本更高(通过降低硬件的规格,使之降到仅能处理单个数据点的水平,这个问题可以得到一定缓解)。
即使一个模型能使用每个输入的数据点进行学习,这也不意味着在每个数据点之后都会部署新的权重。由于我们目前对机器学习算法学习方式的理解还很有限,因此模型更新后,我们还需要对其进行评估,查看表现如何。
对大多数执行所谓的在线训练的公司而言,它们的模型都是以微批量学习的,并且会在一段时间之后进行评估。在评估之后,只有该模型的表现让人满意时才会得到更广泛的部署。微博从学习到部署的模型更新迭代周期为 10 分钟。
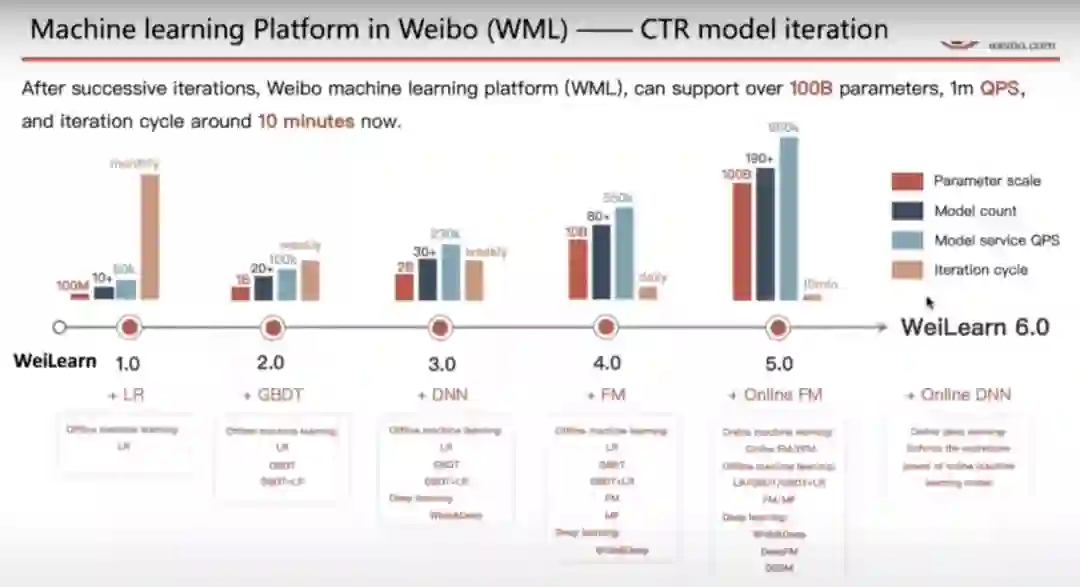
微博使用 Flink 的机器学习(图源:https://www.youtube.com/watch?v=WQ520rWgd9A)
用例
TikTok 让人上瘾。它的秘诀在于推荐系统,其能快速学习你的偏好并推荐你可能会接着看下去的视频,从而为用户提供一个不断刷新视频的体验。TikTok 能做到这一点的原因是其母公司字节跳动建立了一套成熟的基础设施,使其推荐系统能够实时地学习用户偏好。
推荐系统是在线学习的理想应用之一。推荐系统有很自然的标签——如果一位用户点击一个推荐,那么这个预测就是正确的。并非所有推荐系统都需要在线预测。用户对房子、汽车、航班和酒店的偏好不太可能过一分钟就变了,因此对于这样的系统,持续学习并不太合理。但是,用户对在线内容的偏好却会很快改变,比如视频、文章、新闻、推文、帖子和贴图。(比如我刚读到章鱼有时会毫无缘由地击打鱼,现在我想看看相关视频。)由于用户对在线内容的偏好会实时变化,因此广告系统也需要实时更新以展示相关广告。
在线学习对系统适应罕见事件至关重要。以黑色星期五在线购物为例,由于黑色星期五一年仅发生一次,因此亚马逊和其它电商网站不可能有足够多的历史数据来学习用户在那天的行为,因此它们的系统需要持续学习那天的状况以应对变化。
再以 Twitter 的搜索为例,有时候某些名人会发布一些愚蠢的内容。举个例子,当关于「Four Seasons Total Landscaping(直译为:四季完全景观美化)」的新闻上线时,很多人会去搜索「total landscaping」。如果你的系统没有立即学习到这里的「total landscaping」是指特朗普的一场新闻发布会,那么用户就会看到大量关于园艺的推荐。
在线学习还可以帮助解决冷启动(cold start)问题。冷启动是指新用户加入你的应用时,你还没有他们的信息。如果没有任何形式的在线学习,你就只能向新用户推荐一般性内容,直到你下一次以离线方式训练好模型。
解决方案
因为在线学习相对较为新颖,大多数做在线学习的公司也不会公开谈论其细节,因此目前还不存在标准解决方案。
在线学习并不意味着「无批量学习」。在在线学习方面最成功的公司也会同时以离线方式训练其模型,然后再将在线版本与离线版本组合起来。
挑战
无论是理论上还是实践中,在线学习都面临着诸多挑战。
理论挑战
在线学习颠覆了我们对机器学习的许多已有认知。在入门级机器学习课程中,学生学到的东西虽然细节有所不同,但核心都是「使用足够多 epoch 训练你的模型直到收敛」。而在线学习没有 epoch——你的模型只会看见每个数据一次。在线学习也不存在收敛这个说法,基础数据分布会不断变化,没有什么可以收敛到的静态分布。
在线学习的另一大理论挑战是模型评估。在传统的批训练中,你会在静态的留出测试集上评估模型。如果新模型在同一个测试集上优于现有模型,那我们就说新模型更好。但是,在线学习的目标是让模型适应不断变化的数据。如果更新后的模型是在现在的数据上训练的,而且我们知道现在的数据不同于过去的数据,那么再在旧有数据集上测试更新后的模型是不合理的。
那么,我们该怎么知道在前 10 分钟的数据上训练的模型优于使用前 20 分钟的数据训练的模型呢?答案是必须在当前数据上比较两个模型。在线学习需要在线评估,但是向用户提供还未测试的模型听起来简直是灾难。
不过,很多公司都这么做。新模型首先要进行离线测试,以确保它们不会造成灾难性后果,然后再通过复杂的 A/B 测试系统,与现有模型并行地进行在线评估。只有当新模型在该公司关心的某个指标上的表现优于现有模型时,它才能得到更广泛的部署。(本文不再讨论如何选择在线评估的指标。)
实践挑战
在线训练目前还没有标准的基础设施。一些公司选择使用参数服务器的流式架构,但除此之外,我了解过的公司都不得不构建许多自己的基础设施。此处不再详细讨论,因为一些公司要求我对这些信息保密,因为他们构建的方案是为自己服务的——这是他们的竞争优势。
美国和中国的 MLOps 竞赛
我读过许多有关美国和中国 AI 竞赛的文章,但大多数比较关注研究论文、专利、引用和投资。但当我与美国和中国公司聊过实时机器学习的话题之后,我才注意到他们的 MLOps 基础设施有着惊人的差距。
美国很少互联网公司尝试过在线学习,而即使是使用在线学习的公司,也不过是将其用于简单的模型,比如 Logistic 回归。而不管是与中国公司直接谈,还是与曾在两个国家的公司工作过的人谈,给我的印象都是在线学习在中国公司里更常见,而且中国的工程师也更愿意尝试在线学习。下图是一些对话截图。
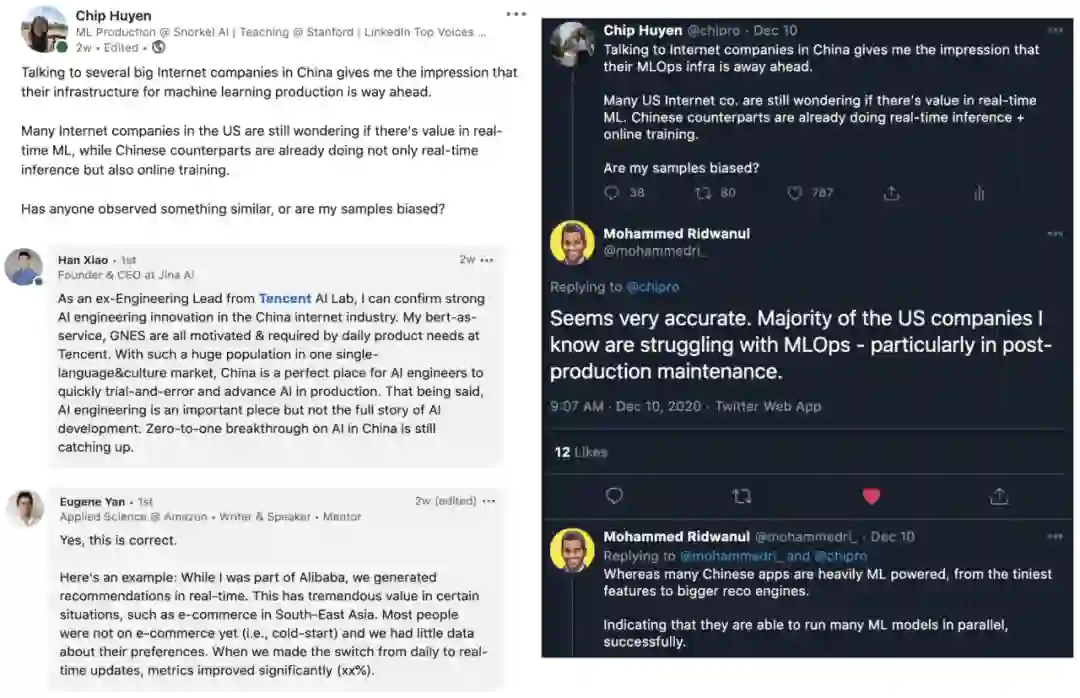
总结
实时机器学习发展正盛,不管你是否已经准备好。尽管大多数公司还在争论在线推理和在线学习是否有价值,但某些正确部署的公司已经看到了投资回报,它们的实时算法可能将成为它们保持竞争优势的重要因素。
原文链接:https://huyenchip.com/2020/12/27/real-time-machine-learning.html
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



