【Paper】AAAI 2020 故事生成模型 之 角色一致性

一、导读
论文:
A Character-Centric Neural Model for Automated Story Generation
任务:
给定title进行故事生成
本期:
在故事生成模型上显式的获取人物信息和情节与人物之间的关系,以提高可解释性和一致性。
机构:
北大 / 上交 / IBM
代码:
https://github.com/liudany/character-centric
发表:
AAAI2020
二、摘要
三、Motivation
本文在借鉴前人的故事生成方法的基础上,结合已有的故事类型知识,我们尝试将深度神经生成网络与角色建模显式结合起来,这被认为是提高角色可信度的有效方法。
我们将每个角色表示为一个分布式嵌入embedding,它编码角色的个性特征以及角色在不同情况下的表现。
在我们的模型中,故事的发展是由角色和当前情况之间的持续交互驱动的。因此我们将故事生成分解为两个步骤:
首先,我们的模型预测了角色在每个时间步上对当前情况的反应动作。即根据S与C预测V。
其次,通过角色embedding、预测动作和情景信息来生成完整的句子。即根据S、C与V进行句子的生成。
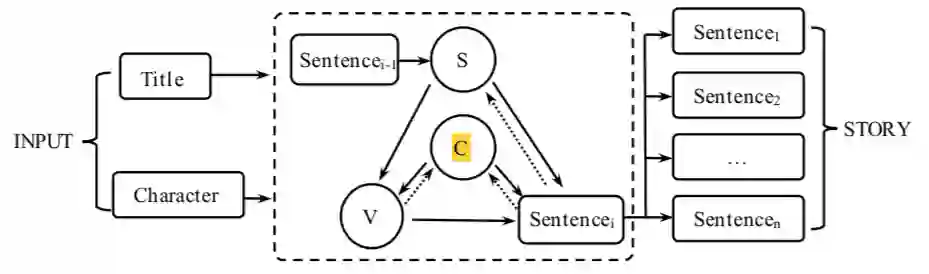
输入:
标题:T = {t1, t2,…, tm}
角色嵌入:C = {c1, c2,…,cp }
其中ti表示第i个单词,m表示标题的长度
其中ci表示故事中的第i个角色嵌入。
输出:
生成的故事:Y = {y1, y2, y3,…, yn}作为我们模型的结果生成
其中yi = {wi,1, wi,2, wi,3,…, wi,l}表示生成的故事中总共n个句子中第i个句子
其中wi,j表示生成的第i个句子中的第j个单词。
注:原本的故事生成模型是给定title,生成story,本文的模型要求给定title的同时给定character(角色)。这一改进提升了模型效果,增进了角色一致性。但角色需要提前给定,且需要角色本身的社会信息。
六、一个直观的例子
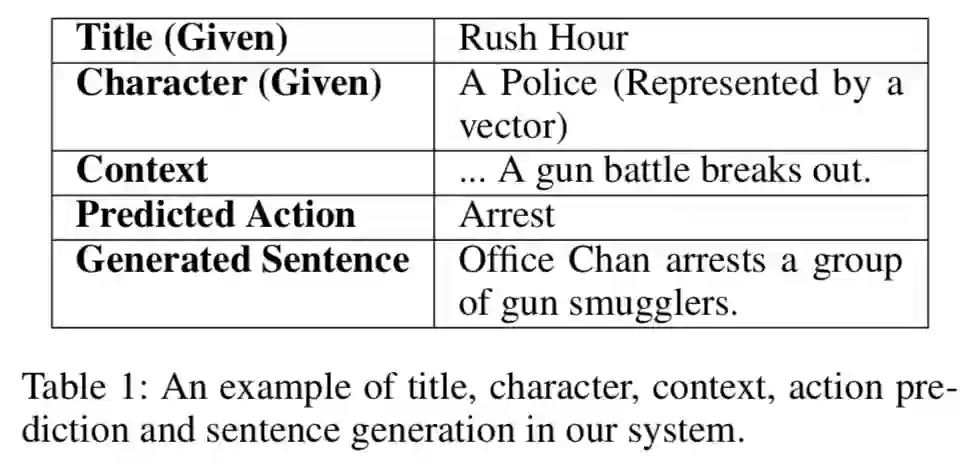
翻译:
标题(给定) |
《尖峰时刻》 |
角色(给定) |
警察(以向量表示) |
上下文内容 |
…一场枪战爆发了。 |
预测的行为 |
逮捕 |
生成的句子 |
陈警官逮捕了一群枪支走私犯。 |
如上表所示,这是一句子的生成过程,根据这个直观的例子,我们可以更好的理解数据集的形式。
七、结合例子看模型
1)动作预测,预测当前角色(警察)对当前语境环境(如图所示Si)作出的反应(逮捕)。
2)句子生成,构成一个完整的句子。
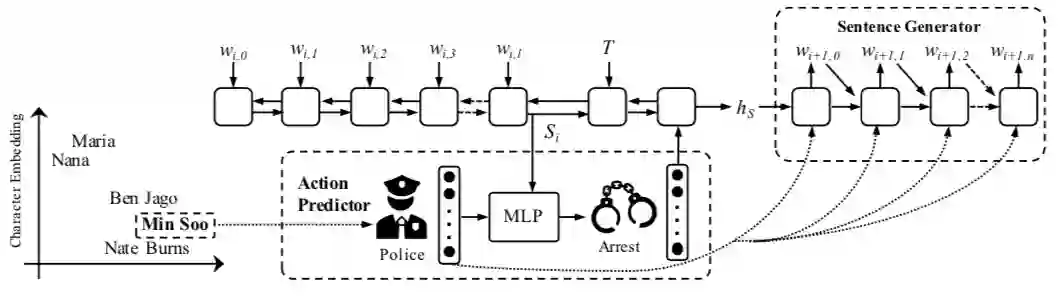
图2:假设上下文内容是根据香港发生的一场激烈的枪战。
给定的角色是警察闵洙。
T表示给定的标题。
结合以上信息,我们的动作预测器计算出动作应该是arrest,输出的句子是警官逮捕一群枪支走私犯。
注意,在句子生成器的每个步骤中都涉及到角色嵌入。
本模型可以分为角色嵌入、动作预测、句子生成和训练策略四个模块细节。
图2左下角展示的是角色嵌入空间。
本文的角色建模(char-embedding)使用每个角色的语言特征(包括相关的动词和属性)的特征求avg作为初始化。
角色嵌入编码角色的属性(例如。(如性格、工作、情感、性别、年龄),这些都会影响角色的行动决定。
注意,初始化之后,我们的模型根据训练过程将角色沿着其中一些属性进行聚类。在动作预测器和句子生成器的训练过程中,通过反向传播学习角色嵌入。
相近的角色往往具有相似的个性特征(例如,工作、年龄、性别)。因此构建了分布式embedding之后在使用时遇到没有见过的角色,可以通过嵌入向量相似而预测出相似的action。
然后char-embedding在decoder的每一个时间步随着target的wordemb一起输入,以此做到角色在故事生成过程的每一步都指导着动作选择操作,以促进角色的一致性。
图2中下方展示的是动作预测。
经过训练,我们的动作预测器将获得推断动作的能力。更具体地说,它是泛化能力,这意味着它有助于推断出一个角色将会执行的动作,即使他/她在训练故事语料库中从未经历过这种情况。
由于训练语料库不能涵盖所有的角色特征,所以这一属性非常重要。
我们的模型基于对特定场景的动作选择来学习角色表征,使得具有相似动作风格的角色在嵌入空间中更倾向于定位在邻近区域。
该特性提高了动作预测器的泛化能力。
例如
考虑角色i和j,他们都是警察,并且在嵌入空间中很邻近。
在训练数据中,当现场显示有一名男子在人群中开枪时,警察进行了逮捕。即使人物j从未经历过相同的情况,但由于其嵌入向量相似,j执行逮捕行动的概率很高。
这就是角色嵌入的泛化能力,它帮助模型在不熟悉角色的情况下执行与其特征一致的动作。
图2中右方展示的是句子生成部分。
在句子生成阶段引入角色嵌入是非常重要的。因为除了动作之外,还有很多与角色相关的信息(例如:形容词、副词、宾语)构成一个完整的句子。
例如
假设角色i是一名篮球运动员,预测的动作是play。考虑角色嵌入C使得我们的模型更倾向于生成篮球而不是计算机作为游戏对象。
同时,角色嵌入增强了角色的可解释性和一致性。
例如
考虑到角色i是一个新生儿,当面对危险时,新生儿所能做的就是哭泣。
但是现有的基于最大似然估计(MLE)的模型更倾向于记住故事语料库的常见模式,这意味着它们更倾向于预测动作逃跑或故事语料库中在危险情况下经常同时出现的其他词汇。
我们的模型明确地引用了每一步的角色嵌入,这使得模型能够选择适当的操作来匹配角色的属性(例如,年龄、性别、个性)。
八、总结
以前的方法缺少故事类型的属性和先验知识,可解释性和一致性差:
一方面,注重生成框架可能会导致生成的故事无法从故事的角度进行解释,比如一个看似可信的故事可能由不相关的情节和不匹配的人物组成。
另一方面,以往的神经模型主要侧重于语义层面的一致性建模,例如,主题的一致性,跨句的连贯性,而角色的一致性则没有得到探索。
本文为一个故事分配了一致的角色,并将故事生成过程重新表述为在上下文环境下选择给定角色的一系列动作。
这样,生成的故事的每个部分都明确地将角色与给定的上下文环境相关联,从故事类型的角度增强了生成故事的可解释性。
此外,给定的角色在故事生成过程的每一步都指导着动作选择操作,以促进角色的一致性。在对话系统(Li et al. 2016)中也验证了这种策略可以提高说话人在神经响应生成中的一致性。
在这篇论文中,我们提出了一个以角色为中心的神经讲故事模型,它在分布式embedding中显式地编码角色以指导故事的生成。
角色char-embedding是由每个角色的语言特征(包括相关的动词和属性)的特征求avg得到,在decoder的每一个时间步随着target的wordemb一起输入。在char-emb上遇到没有见过的角色,可以通过嵌入向量相似而预测出相似的形式。
作者:西柚媛
编辑:西柚媛






