AI 在安全、可靠性方面到底取得了哪些进展?斯坦福 AI 实验室进行了总结


内含大量相关案例分析!
AI 科技评论按:近年来,人工智能尤其是在机器学习领域中,取得了非常巨大的成就,看似其未来更加光明。然而这些系统仍旧不够完美,尤其是被应用到一些因为些许错误就能够导致人命伤害或亿万财产损失的行业中时,这将会存在巨大的风险。
这需要我们人为对这些系统进行保障,其中包括可验证性、可靠性、鲁棒性、可审计性、可解释性和无偏性,对此,斯坦福 AI 实验室对近年来关于 AI 安全、可靠性的研究进展进行了总结,并以文章的形式发布在博客上,AI 科技评论编译如下。

概述
为了能在一些关键应用中使用先进的 AI 系统,比如:商用飞机防撞、金融交易或大规模发电厂、化工厂控制等应用;我们必须保证这些系统具有可验证性(以正确的方式对一系列输入进行验证)、可靠性(即使是新的未见过的输入,表现能够与预期相符)、鲁棒性(在应用时不易受噪音或特定输入干扰)、可审计性(当做出任何给定的决定时,可检查其内部状态)、可解释性(有条理的,可以确保产生决策的数据、场景和假设都是能够被解释清楚的)以及无偏性(不会对某类行为表现出无意识的偏好)。
毫无疑问,这对 AI 系统提出了一系列极为严苛的要求。不过可喜的是,世界上已经有一批来自斯坦福人工智能实验室和斯坦福研究社区的优秀 AI 研究人员(其中包括 Clark Barrett, David Dill, Chelsea Finn, Mykel Kochenderfer, Anshul Kundaje, Percy Liang, Tengyu Ma, Subhasish Mitra, Marco Pavone, Omer Reingold, Dorsa Sadigh 以及 James Zou)正在努力解决这个问题。
本文将介绍一些致力于实现安全可靠的 AI 技术的研究案例。我们将从中看到新技术如何理解神经网络的黑盒子、如何找到和消除偏见,以及如何确保自动化系统的安全性。
理解神经网络的黑盒子:可验证性和可解释性
虽然神经网络在近年来 AI 领域取得的成就中发挥了关键作用,但它们依旧只是有限可解释性的黑盒函数近似器。即便是试图将有限训练数据泛化到未见过的输入,它们在小的干扰下也可能失败,更何况这种做法还会导致难以验证算法的鲁棒性。
让我们看看当前研究工作的两个案例,它们让研究者可以检验神经网络的内部运作。第一个是关于可验证性,第二个则是关于可解释性。
深度神经网络的可验证性
我们希望确保神经网络能够适用于所有可能的情况,但可验证性在实验方面超出了现有工具力所能及的范围。目前,专用工具只能处理非常小的网络,例如具有 10-20 个隐藏节点的单个隐藏层。Katz 等人在论文「Reluplex: An efficient SMT solver for verifying deep neural networks」(论文地址:https://arxiv.org/abs/1702.01135)中提出了 Reluplex,一种用于神经网络错误检测的新算法。Reluplex 将线性编程技术与 SMT(可满足性模块理论)求解技术相结合,其中神经网络被编码为线性算术约束。核心观点就是避免数学逻辑永远不会发生的测试路径,这允许测试比以前更大的数量级的神经网络,例如,每个具有 8 层和 300 个节点的全连接神经网络。
Reluplex 可以在一系列输入上证明神经网络的属性。它可以测量对抗鲁棒性,换言之,即测量可以产生虚假结果的最小或阈值对抗性信号。见 Raghunathan 等人的《针对对抗性实例的认证防御》(https://openreview.net/pdf?id=Bys4ob-Rb),这是另一个评估对抗鲁棒性的案例。
Reluplex 案例研究:无人机防撞
Reluplex 曾被用来测试 ACAS Xu (https://arxiv.org/abs/1810.04240)早期原型的神经网络,是一种用于无人机的机载防撞系统。如图所示,该系统考虑了两架无人机:一架是由 ACAS Xu 软件控制的你自己的无人机「Ownship」,另一架是我们进行观察的无人机「Intruder」。其目标是引导「Ownship」避免与「Intruder」发生碰撞。
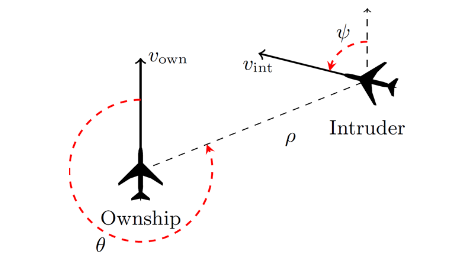
在第一种情况下,要求研究人员展示,如果「Intruder」从左侧接近,那么系统将建议「Ownship」向右急转弯。研究人员使用一定的计算资源在 1.5 小时内证明了该网络在每种情况下都能正常运行。另一个更为复杂的情况是 「Intruder」 和 「Ownship」 处于不同海拔高度的情况,此外 「Ownship」 在这之前还接收到了关于缓慢左转的建议。这说明了在这种系统中可能出现的复杂性。在这种情况下,网络应该建议 COC(没有冲突,即保持当前路线)或缓慢左转。研究人员使用适度的计算资源在 11 个小时内找到了一个反例,后来又在不同的网络中纠正了该反例。
理解模型预测
我们能解释为什么神经网络会做出具体的预测吗?这是 Koh 和 Liang 在论文「 Understanding black-box predictions via influence functions」(https://arxiv.org/pdf/1703.04730.pdf)中提出的问题。当深度学习模型用于决定获得金融贷款或健康保险的对象以及一些其他应用程序时,这一点非常重要。当人工智能系统易于理解时,他们可能会做出更好的决策,从而改进模型的开发,得出更重大的发现,深化我们对 AI 的信任,以及实现更好的发展。因此,研究人员的方法是对给定预测结果最相关训练节点的确定。他们的关键点是使用「影响函数」,通过数学来回答这个问题:「如果我们没有训练节点,模型的预测会如何变化?」

在上图中,如果这只白狗的像素点正是使得该神经网络将其识别为狗,那么系统就非常合理。换句话说,如果海浪的像素点被识别输出为「狗」,则该系统易错率就很高 ——仅具有海浪的其他图像可能被错误地归类为「狗」。通过正确识别白狗的像素影响比海浪像素更高,我们的系统在处理噪声时就会表现得更可靠。
寻找和消除偏差
人工智能系统反映出社会偏差一点都不让人惊讶。Zou 和 Schiebinger 在论文「Design AI so that it’s fair 」(https://www.nature.com/articles/d41586-018-05707-8)中指出偏差可能有两个来源,即训练数据和算法。训练数据中的偏差可能是由于某些群体在数据库中占比过高或过低,解决方案是调查如何策划训练数据。而算法可以放大偏差,因为典型的机器学习程序是试图最大化整个训练数据的整体预测精度,因此解决方案是研究偏差的传播和放大方式。
几何捕获语义
Bolukbasi 等人在论文「Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings」(https://arxiv.org/pdf/1607.06520.pdf)中,使用单词配对来检查偏差。例如,考虑这个问题,男人对应王,那么女人对应什么?任何五岁的孩子都可以回答这个问题,男人是王,那么女人就是女王。研究人员使用 Google 新闻语料库的 Word2Vec 模型回答了单词配对问题。每个单词都映射到高维空间中的一个点。单词之间的关系由连接这些单词的向量表示。
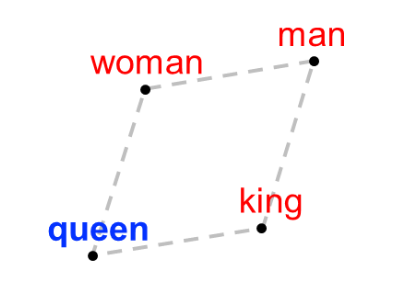
单词嵌入高维空间的二维投影,其中连接女人与女王的向量
与连接男人与王的向量的长度和方向相同
谷歌新闻语料库很庞大,其中许多文章的作者都是专业记者,因此我们理想的期望是使用这些数据训练的模型没有偏差。然而经过片刻的反思,我们意识到这个模型可能会反映社会的偏差,因为它毕竟是对我们社会产生的数据进行的训练,这正是我们接下来讨论的。
让我们来看看另一个词配对:「他」对应的是「兄弟」,那「她」对应着的是什么?同样,任何五岁的孩子都可以回答说「他」对应「兄弟」,那么「她」对应「姐妹」。我们有一个良好的开端,但正如你在下图中看到的那样,事情开始急速转折。一些单词配对表现出偏差(「他」对应的是「医生」,那「她」则对应「护士」;「他」对应的是「计算机程序员」,那「她」则对应「家庭主妇」),另外有一些更是奇怪得彻头彻尾(「她」对应着「怀孕」,而「他」竟然对应着「肾结石」)。
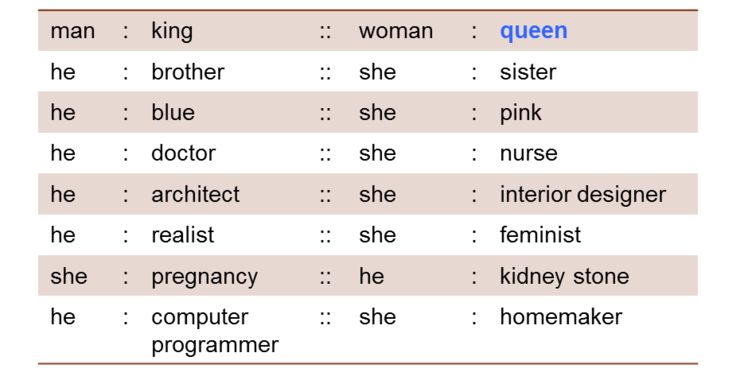
研究人员发现,通过消除性别刻板印象,例如接待员和女性之间的联系,同时保留所期望的联系,比如女王和女性之间的关联,可以减少性别偏差。为了做到这一点,他们根据定义区分了与性别相关的性别特定词,如兄弟,姐妹,商人和女商人,以及其余的性别中性词。在几何学上,他们确定了两个正交维度,即性别特定词与性别中性词间的差别。他们的消除偏差算法通过折叠性别中立的方向去除性别中性词和性别的关联。谷歌,推特,脸书,微软和其他公司都在使用这种消除方式。
在没有人群统计的情况下实现公平
Hashimoto 等人在论文「Fairness without demographics in repeated loss minimization」(https://arxiv.org/pdf/1806.08010.pdf)中想搞清楚是否即使我们没有人群统计信息也有可能开发公平的系统。其主要问题是少数群体在最小化平均训练损失方面的代表性较低。由于成本或隐私原因,分组标签可能不可用,或者受保护的群体可能无法被识别或被知道。当前的方法,即经验风险最小化,会随着时间的推移进一步缩小输入数据中的少数群体,而使问题变得更糟。这些研究人员的目标是即使在没有人口统计标签的情况下,保护所有群体,甚至是少数群体。所以他们的解决方案是一种基于「分布式稳健优化」的方法,可以最大限度地减少所有群体的损失。
分布式稳健优化的目的是控制所有组的最坏情况风险。直观地说,这种方法是加大高损失样本的比重。相对于整个样本而言,加大高损失的样本比重能对具有较少高损失样本的模型做相应的调整,使得某些分组就不再有不成比例的高误差了。即少数群体相关的数据点将默认为遭受高损失的数据点,因此这种方法可以帮助避免这种情况。
确保安全的自治系统
机器人,无人机和自动驾驶车辆需要算法来进行安全学习、规划和操控。当系统探索周围环境时,他们必须处理它们的行为所造成的结果、动态环境和未知人类交互所存在的不确定性。在以下两个例子中,研究人员将自主机器人和人类建模为一个系统。
人机交互的数据驱动概率建模
Marco Pavone 教授的研究(论文:「Multimodal Probabilistic Model-Based Planning for Human-Robot Interaction」,https://arxiv.org/pdf/1710.09483.pdf),旨在开发一个决策和控制堆栈,用于在有多种不同行动方案的环境中进行安全的人机交互。在这案例中,研究人员考虑在进出高速公路的匝道上进行交织区交通流测试。他们的方法是首先从车辆交互样本的数据集中学习未来人类行为的多模态概率分布,然后通过从人类对指定机器人动作序列的回应中进行大规模并行采样来构建实时的机器人策略。该框架不对人类动机做出任何假设,这使得它可以对各种人类驾驶行为进行建模。
值得注意的是,该模型包括高级别随机决策和低级别安全保护控制。考虑到人类有时可能会无视机器人预测,该框架增加了一个低级别的跟踪控制器,当安全受到威胁时,该控制器将随机规划者所需轨迹转化为安全保护控制模式。
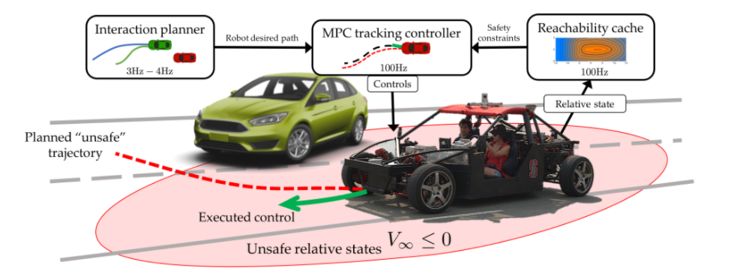
安全学习人的内在状态
Dorsa Sadigh (相关工作论文: 「Planning for cars that coordinate with people: leveraging effects on human actions for planning and active information gathering over human internal state」,http://iliad.stanford.edu/pdfs/publications/sadigh2018planning.pdf)和 Mykel Kochenderfer 正在研究通过训练自动驾驶汽车来了解人类驾驶员的内在状态。他们将自主车辆和人类之间的相互作用建模为动力系统来实现这一点。当然,这项研究中,自动驾驶汽车的动作采用直接控制的方式,但这些动作会影响人类的行为,因此也可以间接控制人类的行为。
想象一下,你正试图在拥挤的高速公路上变道。在观察其他驾驶员的反应时,你可能会从当前车道缓慢进入新车道。如果另一个驾驶员减速并打开一个间隙,那么你继续换道,但如果另一个驾驶员加速并阻挡你,那么你将返回你的车道并稍后再试。曾经常用的方法大体是通过让机器人最大化其自身奖励函数,但现在这个奖励函数可以直接取决于人类做出的响应。由于司机对其他司机的行为做出回应,我们有机会进行积极的信息收集。
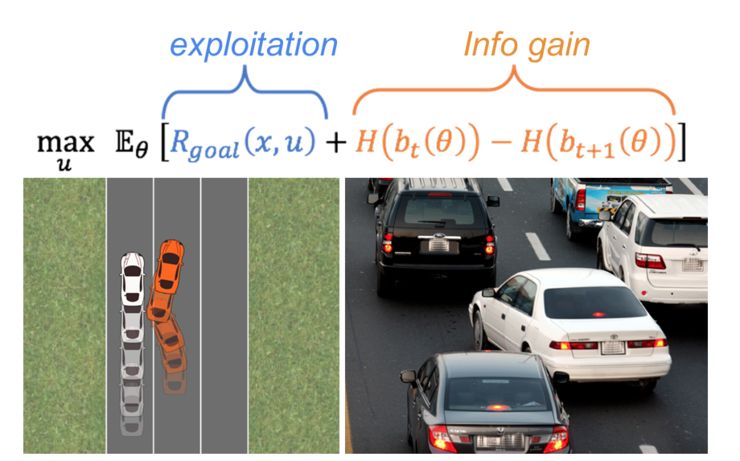
未来
在不久的将来,我们将享受安全可靠的人工智能系统,这些系统具有可验证性、可审计性、可解释性、无偏差性和鲁棒性。正如斯坦福大学人工智能实验室以及其他实验室的研究正在提供创新的技术解决方案,使得这些美好的期愿成为可能。
但光靠技术解决方案还不够,成功还需要对这些解决方案谨慎的实施,并引入社会意识,以确定我们希望在这些系统中加入哪些参数。最近,我们看到以人为本的人工智能方法的兴起,考虑了人为因素和社会影响,这让我们看到:即使对于文化迥异的用户和各种意外情况,这些方法都将赋予人工智能系统以安全、可靠和合理的工作方式!
原文链接:
http://ai.stanford.edu/blog/reliable-ai/
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送7张900元门票优惠码,门票原价1999元,打开以下任一链接即可使用,券后仅1099元,限量7张,先到先得,送完即止。
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e20ce
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e1e17
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e1b53
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e1873
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e1585
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e1289
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e0f24
 点击
阅读原文
,查看:
机器学习如何从上游抑制歧视性行为?
斯坦福 AI 实验室的最新成果给出了答案
点击
阅读原文
,查看:
机器学习如何从上游抑制歧视性行为?
斯坦福 AI 实验室的最新成果给出了答案



