53年来国内唯三,MindSpore加速昇腾芯片论文获国际顶会MICRO最佳论文提名
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
“研究芯片光砸钱不行,要砸数学家、物理学家。”
任正非今年5月在接受《科技日报》专访时如是说。据任正非透露,华为已拥有700多名数学家。
现在,这些数学家的基础研究,让华为在AI和芯片等领域得到了回报。
最近,来自郑州数学工程与先进计算国家重点实验室的赵捷老师与华为MindSpore团队合作,凭借着在基础数学上的能力,解决了一个AI芯片优化的重要问题,获得了顶级学术会议MICRO 2020的最佳论文提名,MICRO是计算机体系结构领域的国际顶级会议,这也是中国团队53年第3次入围该大会的最佳论文提名。

这篇论文主要研究了如何优化在AI芯片上的程序编译,尽可能的“榨干”AI芯片的性能,不仅支持对华为自研的昇腾910芯片,也支持现在主流的NVIDIA A100/V100 GPU,今后还会支持更多硬件。
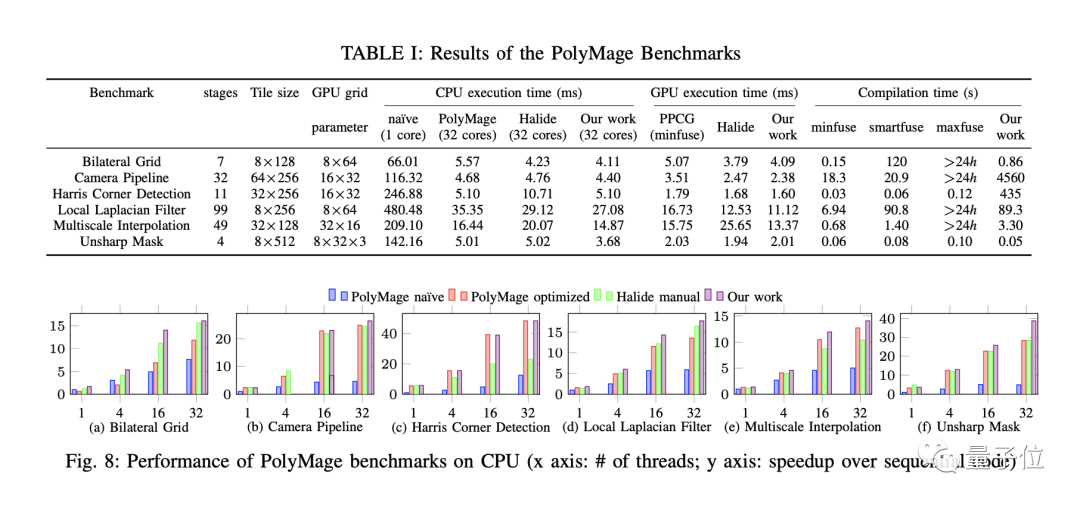
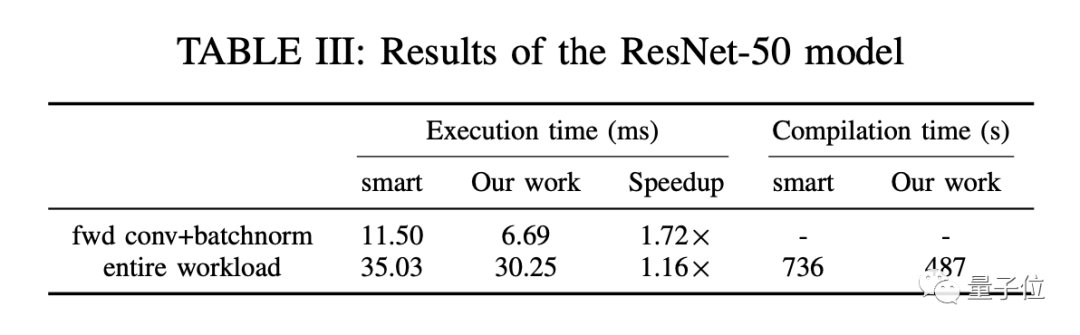
在CPU上,其方法相较PolyMage和Halide分别平均性能提升了20%和33%。在GPU上,其方法比Halide提供了17%的平均性能改进。在AI芯片华为昇腾910上,该论文提出的方法可将ResNet-50模型整个执行时间提升16%。
在论文发表分享理论创新的同时,开源社区也快速推进了这项研究的落地。基于Polyhedral模型的算子自动生成技术MindAKG现已集成到AI框架MindSpore中。
MindAKG的作用就是对深度神经网络中的算子进行优化,利用Polyhedral模型来解决AI应用在不同芯片架构中的性能自动优化难题。
Polyhedral模型则是MindAKG的数学核心。
目前所有MindAKG的源代码早已在Gitee上开源代码,可谓所见即所得的典范。论文合作者赵捷老师目前也是MindSpore社区SIG-AKG的核心成员。业界少见的坚定开源开发如此大规模复杂技术,拥有如此开源雄心的MindSpore无疑将极大的考验其他开源AI框架的“硬核程度”。
基于Polyhedral的编译技术
Polyhedral编译技术历史悠久,最早可追溯到大型机时代研究程序自动并行问题开始。两位图灵奖得主Richard Karp、Leslie Lamport先后为此提出相关理论。
Polyhedral模型需要在编译器中构建一个非常好的数学模型来计算调度。
这种数学模型底层是通过解决整数线性规划问题来得到最优解的,但整数线性规划问题的求解过程是一个NP完全问题,因此只能通过一些近似方法求解。
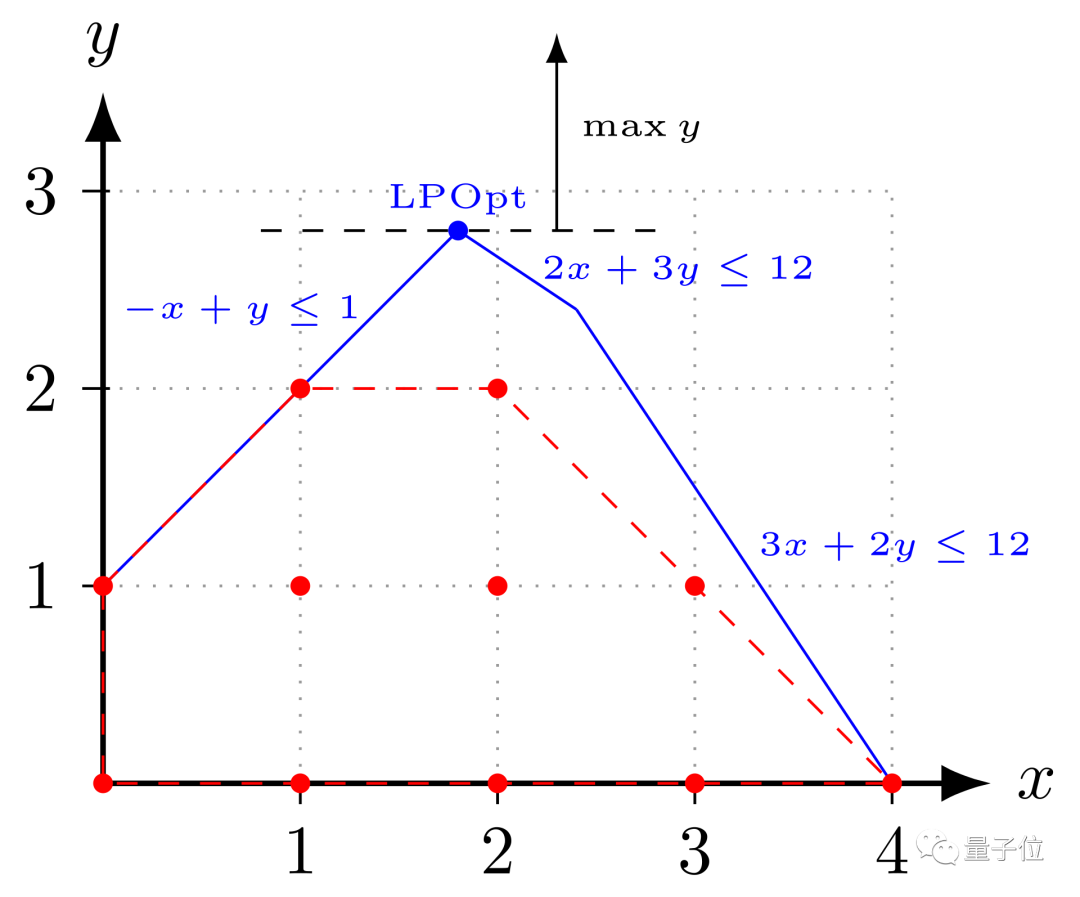
如果这种数学模型的调度不够好,那么可能还不如手工编写调度性能。
如何构建Polyhedral模型的整数线性规划问题,使其能够达到手工编写调度性能相当的结果,是当前研究的核心难点。
既然是NP完全问题,如何降低Polyhedral模型求解的复杂度,也是当前需要解决的问题。
Polyhedral模型涉及大量的基础数学理论,包括但不限于线性代数、空间几何、最优化理论和矩阵论,以及基础计算机理论科学的知识如图论、数理逻辑等,这些知识点本身并不复杂,但是将这些知识点统一地表示在一个模型里,导致该模型的比较复杂,难以理解,入门的“门槛”比较高。
当前国内从事Polyhedral模型研究的人员较少,但在国外,多家科技厂商对该技术的研究十分重视,Google、Facebook、NVIDIA这几家AI领军企业都在研究利用Polyhedral模型来实现算子层的循环优化。
华为MindSpore团队也集结了Polyhedral领域的顶尖专家,全力攻关新的调度算法。
华为自研AI框架MindSpore利用Polyhedral模型,实现了昇腾系列芯片的算子自动生成器MindAKG,采用了可定制化的求解算法,保证程序性能的同时,有效缓解了编译时长的问题。
MindSpore的应用创新
这篇新论文的研究重点是利用Polyhedral模型来解决算子自动生成的问题,与Halide和TVM采用的”compute+schedule”的方式不同。本文研究的算子自动化技术,无需手动编写算子调度算法。
在此基础上,这项研究有以下关键创新点:
首先,这项工作自动化地实现了一种循环分块和合并的新组合。这种组合在已有的基于Polyhedral的自动编译过程中没有被考虑到,因为现有的Polyhedral编译流程限定了这两种循环变换的组合顺序。
同时,这种组合在已有的基于手工编写调度的编译工作中也很难实现,因为在复杂场景下,底层计算和数据之间的映射关系很难用手工编写的方式指定,所以基于手工编写调度的方式很难深入和系统地构建这种组合。
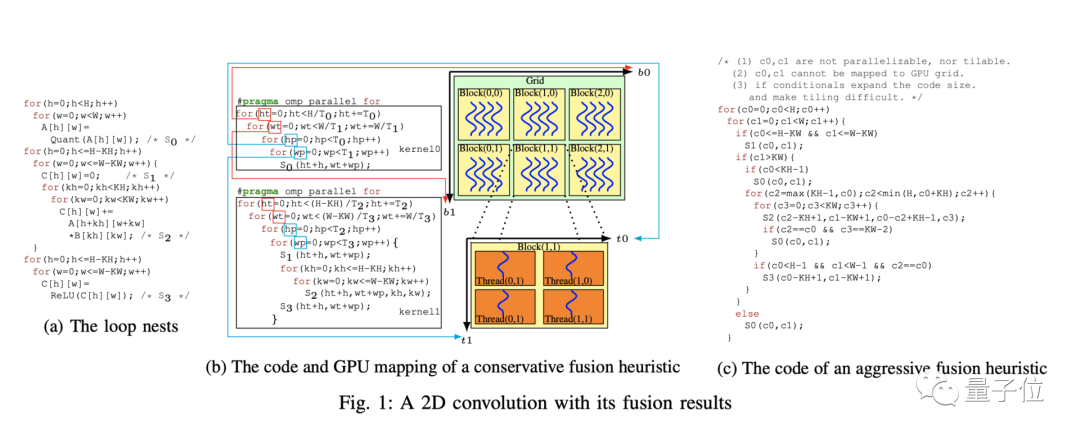
其次,该研究工作在提升程序性能的同时,又有效地缓解了现有Polyhedral编译技术的时间复杂度问题。
通常性能的提升和时间复杂度的降低是矛盾的,但这项研究由于避开了使用前面提到的整数线性规划问题来求解调度的过程,从而能在降低编译时间复杂度的同时,保证了程序性能的显著提升。
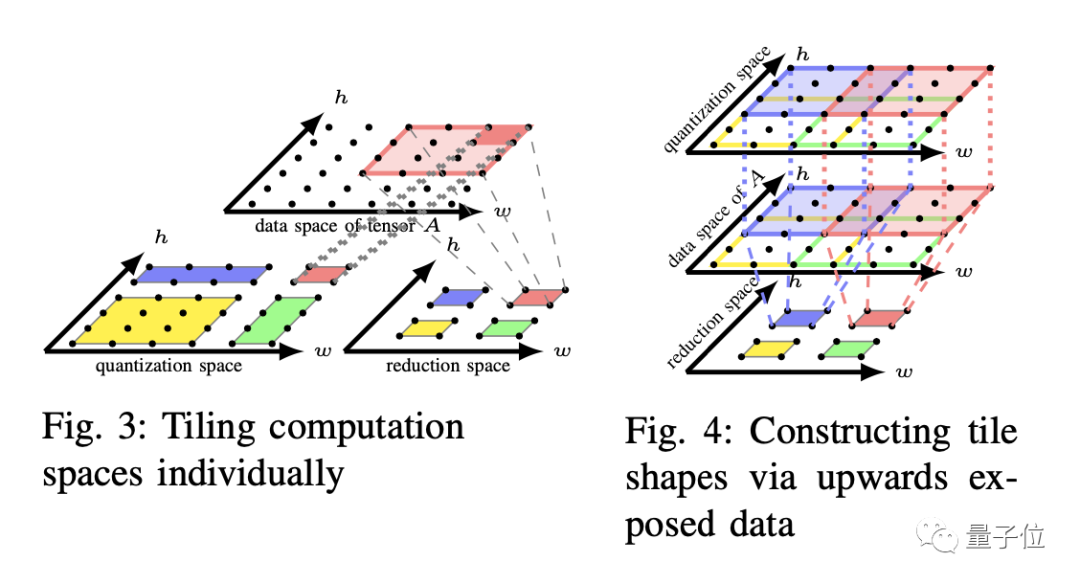
最后,这项研究工作具有很好的可扩展性,可支持多种异构硬件架构的代码自动生成,包括Intel的CPU以及NVDIA的GPU。特别地,这项工作已经在华为自研AI框架MindSpore的算子自动生成器MindAKG中落地,可支持昇腾系列AI芯片上的算子自动生成。
通过对包括神经网络、图像处理、稀疏矩阵计算、线性代数等应用领域在内的11项基准测试实验,该研究证明其方法能在先进的CPU、GPU及AI芯片架构上获得有效的性能改进。
在AI芯片华为昇腾910上,该论文提出的方法可将ResNet-50模型整个执行时间提升16%。
代码已开源
华为MindAKG相关代码已经在Gitee开源,用户既能从MindSpore侧构建,也能独立编译运行。
MindAKG当前已支持华为自研昇腾AI芯片、GPU V100/A100等硬件上的高性能算子自动生成。
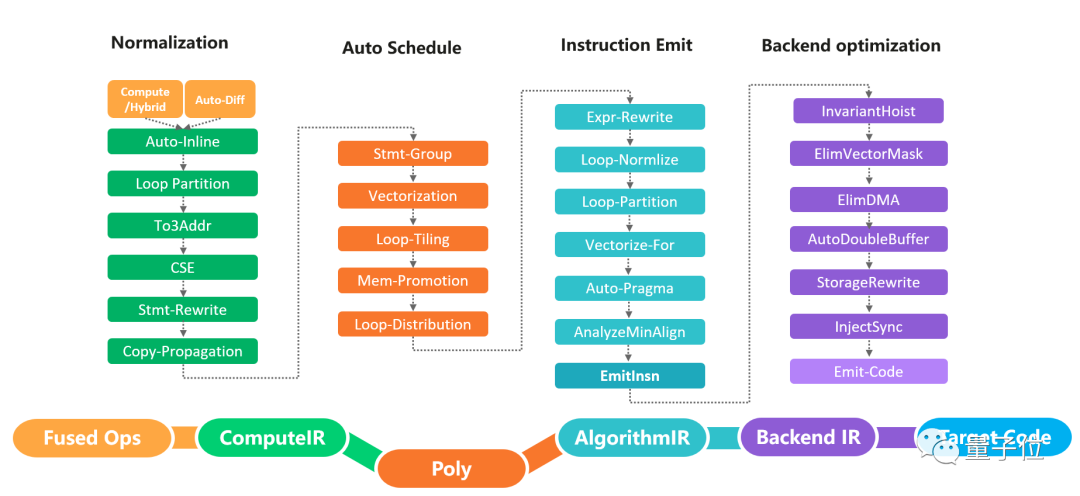
MindAKG主要流程可以分为四个部分:
规范化:为了解决polyhedral表达能力的局限性(只能处理静态的线性程序),需要首先对计算公式IR进行规范化。规范化模块中的优化主要包括自动运算符inline、循环拆分和公共子表达式优化等。
自动调度:自动调度模块基于polyhedral技术,主要包括自动向量化、自动切分、依赖分析和数据搬移等。
指令发射:指令发射模块的优化主要包括循环规范化、标签自动生成和指令发射等。
后端优化:后端优化模块的优化主要包括双缓冲区、存储重写和同步指令插入等。
MindSpore期待开发者加入
今年国产AI框架如雨后春笋一般涌现,华为MindSpore也是其中一员。华为也是少有的具有自研AI框架、AI推理芯片、AI训练芯片的国内厂商。
MindSpore中所应用的Polyhedral技术获得MICRO最佳论文的提名,也说明了华为在AI基础技术上获得了国际认可。让我们看到了任正非口中的数学家在华为AI中起到的最大作用。
华为MindSpore不是国内最早开源的AI框架,却靠着在基础技术上的投入快速得到学界和开发者的认可。
但不可忽视的是,生态才是AI框架最重要的生命力,作为一个正在快速成长的AI社区,MindSpore需要AI开发者积极加入,一起引领AI创新,共同成长。
12月14日至25日,MindSpore社区将在目前已展开过MSG活动的12个城市,开展别开生面的“MindCon极客周”活动,在已渐寒冷的冬日,开发者每天聚集在一个城市,修复社区bug,分享学习心得,还可以参加昇腾模型王者挑战赛的青铜赛段。这次活动还首次通过点亮城市的积分评比(新增star积10分、完成bugfix积100、完成青铜赛段任务积200分)方式,12个城市PK产生明年6月第二届MindCon极客周的主办城市。想要了解像AKG这样黑科技的开发者,快来报名吧!

论文地址:
https://www.microarch.org/micro53/papers/738300a427.pdf
开源地址:
https://gitee.com/mindspore/akg
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~




