KDD最佳论文奖首次独立颁给中国内地机构!达摩院开源工作获奖,面向联邦图学习
明敏 衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
刚刚,KDD 2022所有奖项正式对外公布!
作为数据挖掘、知识发现领域的最高学术会议,每年KDD奖项花落谁家都会引发学界热烈讨论。
今年,中国团队的表现依旧令人瞩目。
清华裘捷中获得博士论文奖亚军,成为亚洲高校首位获得者。
阿里巴巴达摩院智能计算实验室,获得应用数据科学方向最佳论文奖,是中国工业界研究团队首次独立获得这一奖项。

论文提出了一个面向联邦图学习的库FederatedScope-GNN。

主办方SIGKDD评价其“推动了联邦图学习的发展”。
在此,量子位找到论文一作王桢、通讯作者李雅亮,一起聊了聊他们关于论文研究及背后的更多事儿~
在图数据上发挥联邦学习能力
本次获奖论文的核心,聚焦在联邦图学习方面。
简单来说,它就是将图学习和联邦学习的优势合璧。
近年来,随着越来越多应用场景对隐私保护的需求增高,联邦学习愈发火热。
它能让用户在数据始终都停留在本地的基础上,通过交换模型参数或中间结果的方式,在云端联合训练,最终让多方用户都能完成模型训练。
也就是常说的让“数据可用不可见”,从而避免“数据孤岛”问题。
目前,如谷歌的Tensorflow Federated(TFF)、微众银行的FATE等,都是目前大热的开源联邦学习框架。
不过,现有的联邦学习工作,更多关注视觉和自然语言领域,对图的支持相对有限。
要知道,图(graph)在表示复杂关系方面,具有很大优势。
它是由节点(node)和边(edge)两部分组成的一种数据结构,用来描述对象间关系。

日常生活中,你可以把每个社交账户看作一个节点。预测两个账户是不是有好友关系,就是预测这俩节点之间是否存在连边,从而给你推荐“可能认识的人”。
但是传统神经网络,都是接受几何空间的数据作为输入,无法处理图这种数据结构。
针对这种情况,图神经网络被提出。它能利用神经网络来图进行深度特征抽取等操作,从而实现更好的推理预测效果。
常用的场景有电子商务、药物研发、金融、互联网社交等。而这些场景,对数据保护的需求往往也会很大。
比如银行反洗钱场景下,需要预测每个账户是否为风险账户,但各个银行的账户信息不能相互公开。
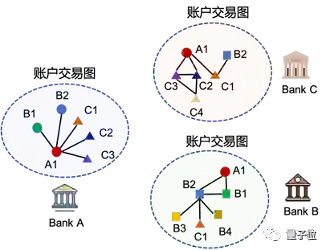
△银行反洗钱场景
还有药物研发过程中,不同厂商只掌握了分子图中的一部分,大家需要共享信息以完成研发任务,但各自的数据还要相互保密。
上述种种,让大家对联邦图学习算法非常渴望。

这样的背景下,达摩院在本次研究中,把图学习用在联邦学习上。
FederatedScope-GNN(以下简称FS-G)基于达摩院已开源的联邦学习框架FederatedScope(以下简称FS)提出。
首先,FS-G提供了一个统一视图,灵活支持异构数据的交换。
得益于底层框架FS事件驱动(event-driven)的编程范式,多种多样的消息交换和参与者的丰富行为得以模块化进行拆分实现——FS-G允许灵活丰富的模块化行为。
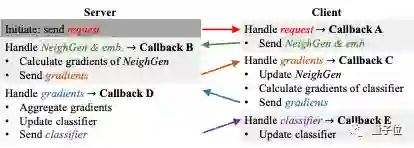
其次,FS-G针对图学习提供了DataZoo和ModelZoo。
前者为用户提供丰富多样的联邦图数据集,后者提供相应的模型与算法。
此外,DataZoo还实现了大量不同类型的splitters,即便在单机场景里,通过FS-G提供的注册机制,开发者也能轻松把单机代码搬到联邦场景复用。
再者,针对联邦图学习对超参数敏感的现象,FS-G还实现了高效的模型调优(model tuning)组件。
其中包括多保真度的Successive Halving Algorithm和新近提出的联邦超参优化算法FedEx,以及针对联邦异质任务的个性化。
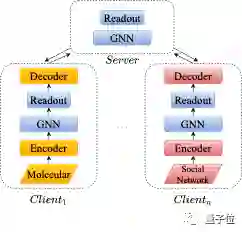
△一个个性化图神经网络示例
因为各个参与者被允许使用独立的特有神经架构,只聚合共享部分,FS-G允许开发者根据实际情况,采用不同的异步训练策略。
最后,FS-G还提供了丰富的隐私评估算法,对算法在隐私保护方面的能力进行检验。
春节加班提交论文
对于这次拿下大奖,论文一作王桢说道,“开心是肯定的,感觉自己的工作得到了认可”。
通讯作者李雅亮则表示,因为看到了团队为此付出了多少努力,所以觉得这一切更像是一种水到渠成。
实际上,这项工作的筹备时间要从一年多以前算起。
当时,团队洞察到了隐私保护计算行业的发展趋势。作为技术人员,自然而然想到从工具入手,推动这股研究浪潮更快前进。
所以,FederatedScope被提上了日程,FS-G则是其中非常重要的部分之一。
前面也有提到,联邦图学习的工作可以满足应用场景中更为广泛的需求,但是复杂程度也更高。
刚好,王桢博士非常擅长图学习方面的研究。
引用量超过2500次的知识图谱补全算法TransH,正是他以一作身份完成的工作。
当时,他还正在中山大学数据科学与计算机学院攻读博士学位,通过微软亚研院联合培养项目,完成了这篇论文。
博士毕业后,王桢就加入了阿里巴巴,曾任阿里云高级算法工程师。
作为主要开发者,王桢参与了阿里机器学习平台PAI中A3gent强化学习组件的研发,并将其开源为EasyRL项目。
同期还参与了伯克利大学Ray RLLib项目共建,并被社区认可为项目committer。
之后,王桢加入达摩院,开始专注联邦图领域的研究。多次在KDD Cup比赛中取得高排名成绩,在ICLR、WWW等国际顶会发表多篇论文。

但即便有优秀学者坐镇,由于联邦图学习是一个十分前沿的领域,领域内一些基础性工作都还没有搭建完整,联邦图学习算法本身也会比普通联邦学习算法难,所以研发FS-G的难度并不小。
王桢提到,最初他们甚至连一个可用的数据集都没有。
加之,图数据相较于其他数据类型,在异质消息交换上会存在更多风险;联邦学习的每个参与者也会有更丰富的行为,去处理这些信息。
因此,研究团队需要在图联邦算法上使用一个与以往不同的编程范式,并设计方案使其在图联邦中发挥最大功效,这是有别于常规开发的。
这背后,都需要更多人力、时间的投入。
论文通讯作者李雅亮回忆,今年KDD论文提交的时间,刚好在大年初十。
当时整个团队都在兴奋地忙碌着论文的提交工作,过年几乎都没有休息。
而这些精力的投入,最终也在论文成果中得以显现。
可以看到,FS-G中包含了丰富的联邦图数据集和相应的模型与算法。并且让没有联邦学习背景的开发者,也能自如使用FS-G。
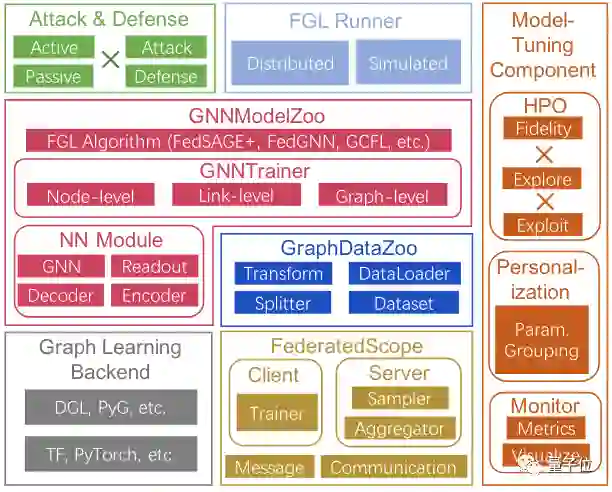
这为后续研究做了大量的基础性工作,可以说是为联邦图学习建立了新基准。
李雅亮在交谈中也表示,基础性工作的完成,能够吸引更多研究人员参与联邦图学习的研究。
我觉得,这是我们工作能够获得组委会认可的一大原因。
值得一提的,李雅亮作为本次成果的通讯作者,还曾负责FederatedScope的开源工作。

他现在是达摩院智能计算实验室的高级算法专家。
2017年从纽约州立大学布法罗分校博士毕业,研究领域覆盖数据融合、因果推断、自动机器学习、隐私保护计算等领域。
曾担任NeurIPS’21、NeurIPS’21、AAAI’22的领域主席,在IJCAI和NeurIPS上三次组织workshop,在CIKM’22上组织了AnalytiCup比赛,并在KDD、AAAI上多次做了Tutorial。
据他透露,FederatedScope现在已经开源0.2.0版本。
新版本可以更好支持大规模下的异步联邦学习,对用户的友好度也更高。
One More Thing
最后是福利时刻~
在聊完获奖论文的相关内容后,我们还找两位大佬问了问AI研究方面的学习经验,大家赶紧来抄作业!
首先,两位学者都表示,想学好AI,数学非常关键。
李雅亮提到,自己观察到这几年很多学生、实习生的数学能力都有些下降,这其实非常值得关注。
现在很多工具变得好用后,大家开始更追求短平快的东西,忽略了更为深入、本质的知识学习。其实数学作为基础能力,和代码这种工程方面的能力,二者缺一不可。

其次,是大家都关心的怎么读论文的问题。
王桢表示,读好的论文才是关键所在。
自己要先学会去甄别什么是好的论文,然后把时间花在刀刃上。
而且相较于读论文,李雅亮更鼓励大家去多读书。因为书会帮助大家更好去建立知识体系。
现在,即便他们都已经毕业很多年了,在达摩院智能计算实验室也经常组织读书活动。
推荐大家读一下《Fundation of Machine Learning》!我相信无论是小白还是行家,都会从这本书中得到更多新的见解。

除了学习经验,我们还问了问大佬们有啥业余爱好。
结果他们都表示,他们做研究就是靠兴趣驱动的,所以平常也很爱钻研。
这点你学废了吗
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


