无监督领域迁移及文本表示学习的相关进展


摘要
随着基于 transformer 的预训练语言模型的广泛应用,多种自然语言处理任务在近一两年来都取得了显著突破。然而,高质量的模型仍然很大程度上依赖于充足的下游任务训练数据,当面对新的领域、问题场景时,预训练模型的效果仍然有待提高。
在现实应用场景中,很多领域及语言的高质量标注数据十分稀缺且昂贵,因此,如何让模型在低资源的场景下更高效地学习是一个 NLP 社群非常关注的问题。
本文总结了我们最近在低资源 NLP 上的三个工作,分别被 IJCAI 2020 和 EMNLP 2020 高分录用。这三个工作重点探索了两个方向, 第一个方向是文本粒度的无监督领域迁移(下文介绍的第一个和第二个工作), 我们提出了两种从不同角度出发的领域迁移模型。第二个方向是无监督文本表示,我们提出了一种基于 BERT 的无监督方式来学习句子向量,使之不受数据标注和领域的限制。
本文介绍的工作来自于阿里巴巴达摩院新加坡 NLP 团队,其中前两篇是同新加坡国立大学 Prof Ng Hwee Tou(ACL Fellow)的 AIR 合作项目产出。本文由达摩院邴立东、何瑞丹、张琰,苏州大学李俊涛,新加坡国立大学叶海共同整理而成。由 PaperWeekly 编辑进行了校对和格式调整。

无监督领域迁移
2.1 IJCAI 2020

2.1.1 问题设置
本篇论文考虑跨语言跨领域迁移,其设置是利用源语言和源领域的有标签训练数据集 来训练一个有监督模型,在源语言的无标签数据集 的帮助下迁移到目标语言和目标领域,并在测试数据集 上进行效果验证。鉴于我们没有使用目标语言和目标领域的有标签数据集,该设置可以被认为是一种无监督的领域迁移形式。
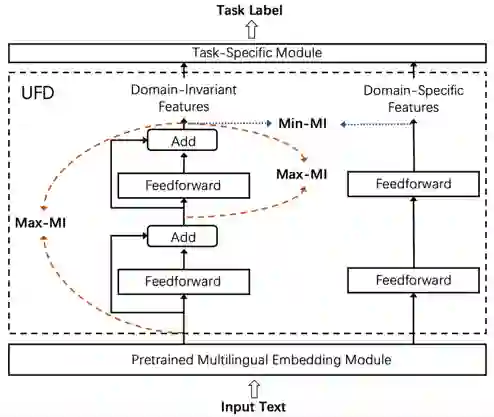
2.1.2 模型架构
本论文的总体思路是将预训练模型输出的特征进行分解,分别得到领域共享 (domain-invariant)特征和领域特有(domain-specific)特征。我们发现,相较于直接使用预训练模型输出的特征,在分解后的特征上训练的文本分类器具有更强的领域迁移能力。
为了不破坏预训练模型的泛化能力,我们采用了无监督的设置和轻量级的迁移模块设计。如上图所示,我们提出的模型包括三个组成部分:
-
一个预训练好的多语言编码模块(XLMR),主要用于将输入的文本编码成多语言共享空间(language-invariant)的表示; -
一个非监督的特征分解模块 – unsupervised feature decomposition (UFD),用于从多语言共享表示空间(language-invariant)抽取领域共享(domain-invariant)和领域特有(domain-specific)的特征; -
任务特有的分类器, 在这里我们使用简单的 softmax 分类器。
2.1.3 特征分解
整个模型的核心单元是特征分解模块(UFD),用于分别抽取领域共享和领域特有特征。具体地,该模块包含一个领域共享特征提取器 (上图左)和一个领域特有特征提取器 (上图右)。
的作用是从预训练模型输出的特征中提取到领域共享(domain-invariant)的特征。我们提出通过最大化 输入和输出的互信息(mutual information (MI))这一自学习方式来训练 的参数,其损失函数 如下,这里我们用到了 Jensen-Shannon MI estimator 来估算互信息 [1] :
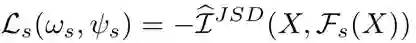
当 在多个领域数据上训练时,最大化其输入输出的互信息可以使 提取到这些领域上共有的特征。为了促进领域共享特征的学习,我们还额外引入了另一个互信息极大化的训练损失信号 – 最大化 中间层和输出层的互信息,其损失函数 如下:
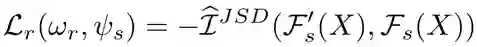
的作用是从预训练模型输出的特征中提取到领域特有(domain-specific)的特征。我们提出通过极小化 和 输出之间的互信息这一自学习方式来训练 ,通过极小化互信息, 抽取到的是完全独立于 的特征。由于 抽取的是领域共享特征, 抽取的可以被视为领域特有的特征。其损失函数如下:
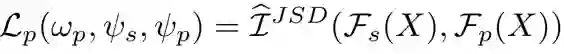
因此整个 UDF 模块的训练目标为:
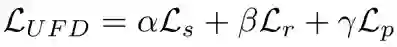
2.1.4 模型训练
整个训练过程分为两步。我们首先用源语言多个领域上的无标注数据训练 UDF。待 UDF 训练完毕后,我们固定其参数,在源语言源领域标注样本上训练最上层的分类器(注:预训练模型 XLMR 的参数在整个过程中是冻结的)。
2.1.5 主要实验结果
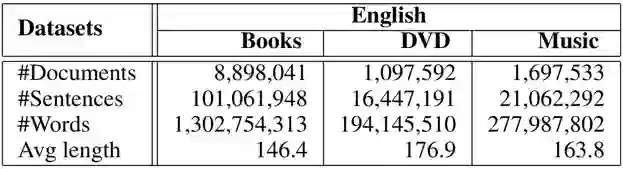
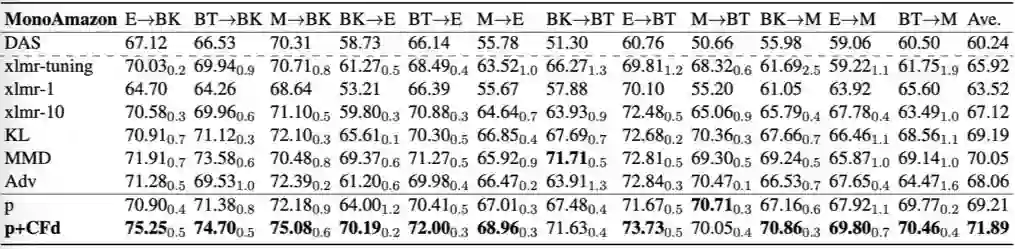
我们在文本情感分类任务上进行了实验。在实验中,我们首先使用了源语言(英语)的无标注数据(unlabeled data)[3],包括三个不同的目标领域,即 Book、Dvd、Music。该数据集用来训练 UDF,其具体的统计信息如上表所示。
除了无标注数据以外,我们还引入了标注数据集。该数据集 [2] 涉及到 4 个不同的语言,其中英语作为高资源的源语言,法语,德语,日语作为目标语言。每个语言包含三个不同的领域,即 Book、Dvd、Music。在每个源语言和源领域有 2000 条带标签的训练样本,每个目标语言和目标领域有 2000 条带标签的测试样本。
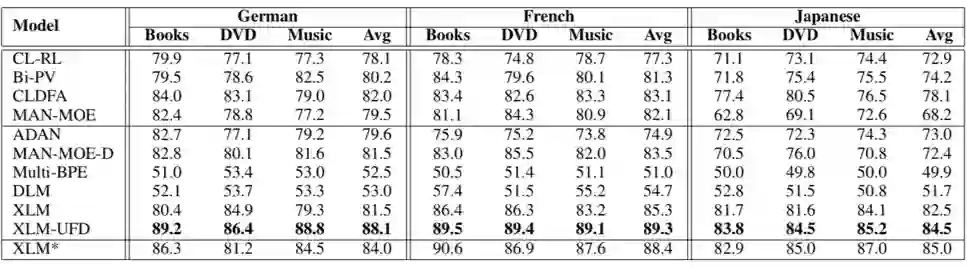
上表给出了各个模型的对比实验结果(accuracy),从中我们可以看到 XLM 是一个非常强的基础模型,在最近提出的非预训练模型 MAN-MOE-D 上取得了明显的效果提升(法语和日语)。我们还观察到预训练的领域语言模型 DLM 远远弱于 XLM,这说明以语言模型为基础的表示学习手段对训练数据量级的要求很高。
此外,本文提出的特征抽取模块(UFD)极大地提升原有大规模预训练语言模型的效果。由于该模型和设置只使用了高资源源语言的少量无标注数据,因此不会牺牲大规模预训练模型的泛化能力。
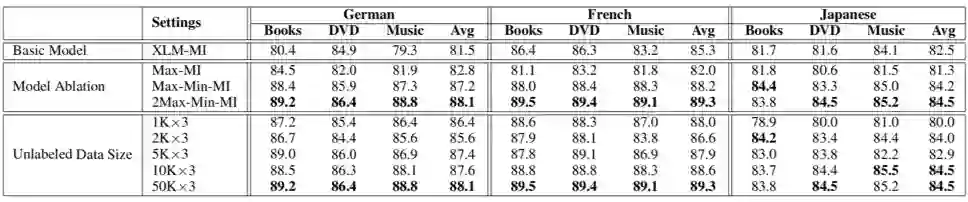
上表进一步给出了模型消融实验的结果和源语言无标注数据的数量对最终模型效果的影响(accuracy)。
比较有意思的结果是,只利用互信息极大化训练目标函数,Max 模型并没有像 CV 领域一样促进预训练模型和下游任务的融合。只有在互信息极大化和互信息极小化损失函数共同作用下,预训练模型的表示才能和具体领域的任务进行更好的结合。
通过分析源语言无标注数据的量级对领域迁移效果的影响,我们发现 3-6K 无监督样本已经可以非常有效地提升预训练模型在特定领域任务上的表现。

2.2.1 问题设置
本篇论文的问题设置是典型的无监督领域迁移。给定源领域的标注数据 和目标领域无标注数据 ,训练一个模型,测试其在目标领域数据集 上的效果。我们依然专注文本分类的问题,而且也同时考虑跨领域和跨语言的设定。为了做到跨语言,同样地,我们采用了多语言预训练模型(XLMR)作为下层的特征编码器。
2.2.2 模型架构
自训练 (self-training) 是领域适应场景中常见的一种方法。这种方法大多以bootstrapping 的方式对目标领域无标注样本进行标注得到伪标签(pseudo labels),然后将高确定性的样本加入训练集用于下一轮模型学习。
虽然自训练在一些情况下很有效,但是此方法极易受到噪声的影响。主要问题是,在源领域标注数据上训练后的编码器由于其参数只针对源领域进行了优化,其对目标领域编码后得到的特征可能变得不可识别(non-discriminative)。分类器在这样的特征上预测的伪标签是非常不准确的,进一步给下一轮的自训练带去了诸多噪音。
我们提出的方法基于自训练,为了减少噪声对算法的影响,提高算法的鲁棒性,我们提出了 CFd (class-aware feature self-distillation) 算法,通过在目标领域学习可识别(discriminative)特征来提高伪标签的准确度,缓解伪标签带来的噪声问题。
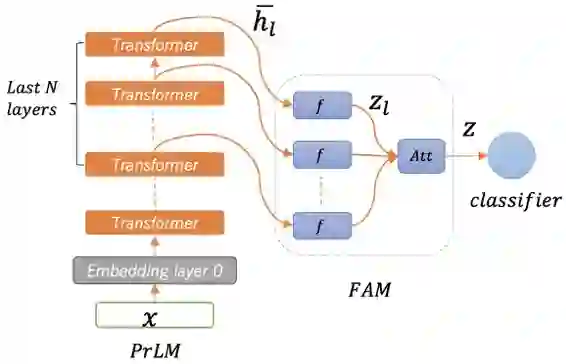
上图展示了我们模型的网络架构,其自下而上分为预训练语言模型(pretrained language model, PrLM for short),用于对输入文本进行初步编码;编码器又叫特征映射器(feature adaptation module, FAM for short),用于将预训练模型输出的特征映射到低维空间;以及分类器(classifier)。
由于预训练模型不同层的特征具有的迁移能力不同 [6,7],为了能够达到更好的迁移效果,我们把多层的特征融合到一起。在 FAM 中,我们通过注意力机制来学习各层特征的权重,然后将乘上权重后的特征相加,作为 FAM 的输出。
2.2.3 自训练算法
自训练是整体算法的基础。一开始训练集只包含源领域的所有标注数据,在每轮训练后,模型会对所有目标领域的无标签样本进行预测,生成伪标签,然后选择部分目标领域的样本进入训练集用于下一轮模型训练。
我们首先用熵损失(entropy loss)对所有无标签样本排序,熵损失越小,排序越靠前,代表分类器对此样本的伪标签确定性越高。然后将所有样本根据其伪标签分类,平均地从每类选择熵损失最小的 K 个样本。
2.2.4 CFd算法
CFd 是本篇论文的主要贡献。其主要通过两个部分来学习目标领域可识别特征。第一部分是特征自蒸馏算法,第二部分是学习标签的聚类信息。
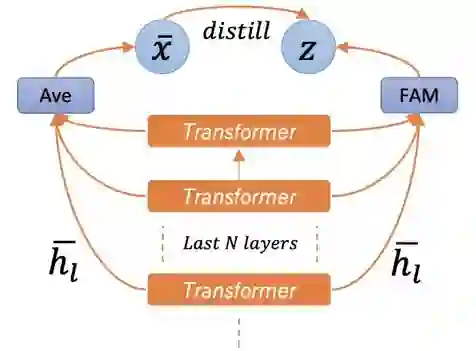
特征自蒸馏:当模型仅通过有监督的方式在源领域数据上学习时,经 FAM 输出的目标领域样本特征可能变得不可识别(non-discriminative)。
由于预训练模型自身就能生成优异的可识别特征(训练过程中预训练模型参数固定),因此在对 FAM 进行有监督训练时,我们可以通过构造自学习 (self-learning)任务的方式同时在目标领域无标注样本上对其进行训练,目的是使其输出特征保留原预训练模型特征的可识别性。
我们把这个过程叫做自蒸馏。上图展示了自蒸馏的过程,这里的目标函数是最大化预训练模型 average pooling 后的特征和 FAM 输出的特征之间的互信息(mutual information)。其损失函数记为 。
聚类信息:对于训练集中来自源领域和目标领域带有伪标签的样本, 我们首先将它们按照标签分组,然后计算每组特征的中心点。接着我们构造一个损失函数 去最小化每个数据点到其所在组中心点的距离,这样能近一步让所有样本的特征变得可以识别(discriminative)。
CFd 损失函数:因此 CFd 的损失函数为 。CFd 部分的损失函数是无监督的,其会被加到源领域上的有监督损失中一起引导模型进行训练。
2.2.5 主要实验结果
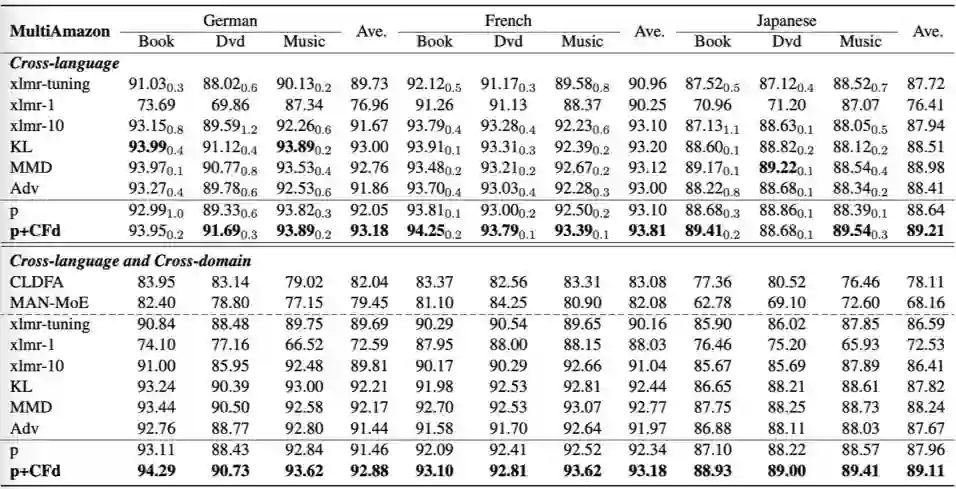
我们在文本情感分类任务上实验了提出的算法,使用到了单语言(MonoAmazon [4])和多语言(MultiAmazon [5])两个数据集。其中,单语言有 4 个 domain,包括 Book, Electronics, Beauty 以及 Music;多语言包括了英语、德语、法语和日语,每个语言包括了 Book, Dvd 和 Music 3 个 domain。
在单语言上,我们只考虑了 cross-domain 的设定,而在多语言上,我们不仅考虑了 cross-domain,而且考虑了 cross-language,cross-domain&cross-language。

以下是我们的实验结果(accuracy),从实验结果中我们可以发现,对比自训练的基准模型 (p),我们的算法(p+CFd)无论在跨 domain 还是跨 language 的设定上都有稳定且显著的效果提升。
同时我们也发现在固定 XLMR 参数的情况下, 用最上面 10 层特征的融合(xlmr-10)会大幅好于只用最后一层的特征(xlmr-1),甚至好于对 XLMR 进行 finetune (xlmr-tuning)。

无监督文本表示

文本匹配技术如文本相似度、文本相关性计算,是很多应用系统中的核心 NLP 模块,包括搜索引擎、智能问答、知识检索、信息流推荐等。例如, 智能问答系统一般是从大量存储的 Doc 中,选取与用户输入 Query 最匹配的那个 Doc。
尽管 BERT 已经在文本匹配任务如句子对回归(Sentence Pair Regression)等取得了很好的效果,但 BERT 使用了交叉编码器,这需要将两个句子都输入到 transformer 网络对目标值进行预测,从而带来大量计算。
例如,从 1 万个句子中找相似对,就需要用 BERT 进行约 5 千万次计算(单块 v100 GPU 耗时约 65 小时)。为解决这个问题,可以先将所有句子映射到固定大小的向量空间,使得语义相似的句子位置相近,再用余弦距离对句子对回归任务进行评估,这可以极大提高计算效率。
例如,可以将 BERT 的输出层平均化或使用第一个 token([CLS])的 embedding 作为句向量,但这样的句子表征效果很差,之前的研究发现此方法甚至不如用 GloVe 向量取平均来作为句子表示的效果好 [8]。
BERT 的改进版 Sentence-BERT(SBERT)[8] 使用二元和三元网络结构来获得包含语义的句向量。该向量可用于相似度计算,使寻找相似对的工作从 BERT 的 65 小时减少到 SBERT 的 5 秒,同时保证了 BERT 的正确率。
但是,此类改进依赖于高质量的监督学习数据。我们发现,当目标任务的标记数据极为匮乏,或测试集与训练集的数据分布明显不同时,SBERT 的性能会显着下降。为此,我们提出了一种无监督训练方式来学习句向量,使之能不受数据标注和数据领域的限制,并同时保证 BERT 在语义文本匹配等任务上的准确率和效率。
3.1 模型架构
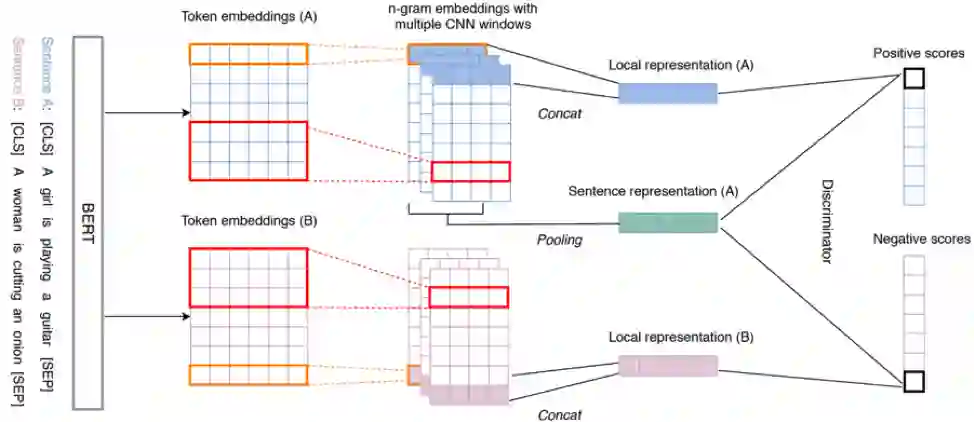
受无监督图片表示学习的启发 [9], 本篇论文提出了一种思路类似的但可用于文本的自学习(self-learning)方法来进行无监督句子表示学习。如上图所示,我们提出的模型主要包括三个组成部分:
1)一个预训练好的编码模块(BERT)模型,主要用于将输入的文本进行编码;
2)多个卷积神经网络 (CNN),用于提取不同的文本局部信息(n-gram)。
3)基于互信息最大化(Mutual Information (MI) maximization)的句向量学习模块。
模型工作流程如下。句子输入到 BERT 后被编码,其输出的 token embeddings 通过多个不同 kernel size 的一维卷积神经网络 (CNN)得到多个 n-gram 特征。我们把每一个 n-gram 特征当成局部表征(Local representation), 将平均池化(Mean Pooling)后的局部表征称为全局表征(Global representation)。
最后,我们用一个基于互信息的损失函数来学习最终的句向量。该损失函数的出发点是最大化句子的全局表征(句向量)与局部表征之间的平均互信息值,因为对于一个好的全局句向量,它与所对应的局部表征之间的 MI 应该是很高的, 相反,它与其他句子的局部表征间的 MI 应该是很低的。
在实现上,我们用鉴别器(Discriminator)接受所有的特征表示对(局部表征,全局表征),并对每一对输入进行打分。在上图这个例子中,对于句子 A 的句向量,我们将其与句子 A 的局部特征向量配对作为正样本,和 B 的局部特征向量配对作为负样本。
整个自学习任务的优化目标是最大化鉴别器对正样本的打分以及最小化对负样本的打分,以此来训练编码器(BERT+CNN)进行句子表征学习。这样的任务类似 contrastive learning,可以鼓励编码器更好地捕捉句子的局部表征,并且更好地区分不同句子之间的表征。
3.2 主要实验结果
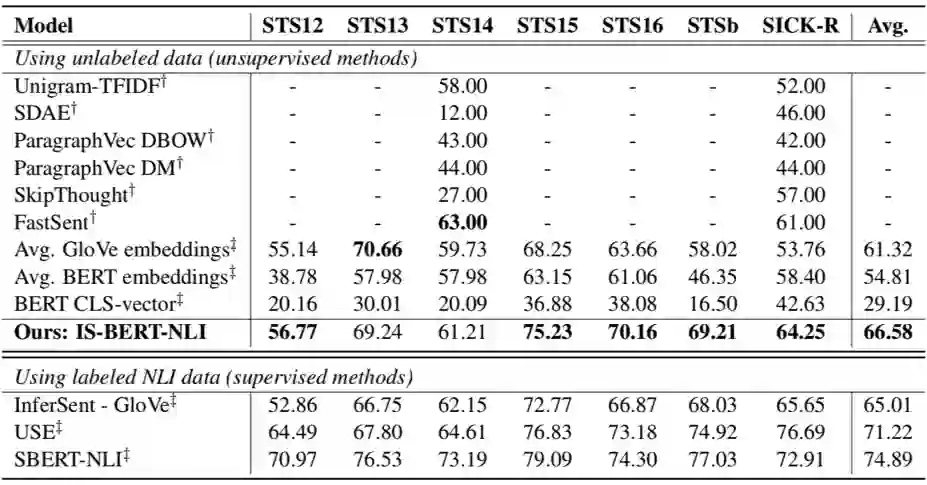
为了方便,我们的模型命名为 IS-BERT。我们在不同的 STS(semantic textual similarity)数据集上进行了实验。上面表 1 展示了 STS 基准数据集上的结果(spearman’s rank correlation)。
这组数据集的文本来自开放领域,所以在实验中我们和 SBERT 一样,在 SNLI 和 MultiNLI 数据集上进行训练。注意 SBERT 学习用到了这两个数据集的标签信息,但 IS-BERT 只用到了文本信息(raw text)进行学习。
从表 1 中我们可以看到所有的有监督方法(SBERT, USE, InferSent)都优于其他的无监督模型。这很大程度上是因为 NLI 数据集和 STS 数据集比较相关,通过在 NLI 数据上进行有监督训练得到句子表征信息比较适用于这组 STS 任务。
但看无监督模型,我们的 IS-BERT 模型远远强于其他的无监督学习方法,甚至在许多任务(5/7)上优于 InferSent 等监督训练的模型。IS-BERT 虽然明显弱于 USE 和 SBERT 这两种有监督训练的方法,但我们的模型不受数据标注的限制并且在部分任务上(STS13 and STS15)与有监督的学习方法效果相当。
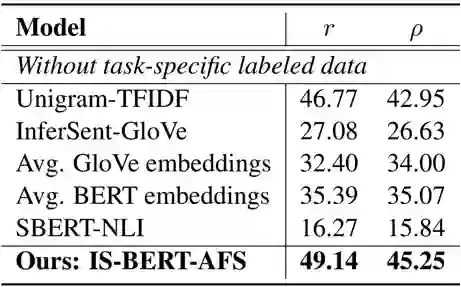
表 2 展示了在模型在另一个 argument 相关的数据集上的效果(pearson correlation and spearman’s rank correlation)。这个数据集更 task-specific 且更有挑战性。我们的实验设置是所有模型都不能用 task-specific 的标注数据进行训练,这是一个非常贴合现实的设置。
在这种情况下 SBERT 只能先在 NLI 上学习句子编码,然后在这个数据集上测试。由于 NLI 和这个 argument 数据集语义差距很大, SBERT 在这种情况下的表现很差。我们提出的 IS-BERT 由于是无监督的,可以直接在 task-specific 的无标签文本上进行训练,固而在这种场景下表现显著优于其他方法。

总结
如何在低资源场景下进行模型训练是自然语言处理中最重要也是最有挑战性的问题之一,其中包含诸多研究方向,本文呈现的工作仅就其中两个方向进行了探索。就文本领域迁移,我们分别从特征分解和强化自训练两个不同角度提出了更高效的方法。
就文本表示,我们提出了基于预训练模型的简单高效的无监督方法。这两个方向都有很大的进一步研究空间。针对领域迁移,我们后续会探索将文本粒度的方法拓展到其它如序列标注,seq2seq 一类的任务上。针对无监督文本表示,进一步探索其在跨语言场景中的潜力将是一个比较有意义的方向。

参考文献
关于作者
邴立东,现任阿里巴巴达摩院 NLP Lab 新加坡团队负责人,香港中文大学博士,卡内基梅隆大学博士后,曾任腾讯人工智能实验室高级研究员。从事自然语言处理领域的研发工作近 10 年,目前研究兴趣集中于低资源NLP问题、情感分析、文本生成、表示学习、论辩挖掘等。近年来在顶级人工智能会议及期刊上,发表论文近 100 篇。以副主编、领域主席、高级程序委员等身份,多次参与顶级自然语言和机器学习期刊、会议的组织和审稿工作。其带领的新加坡 NLP 团队开发的多语言 NLP 技术,全面赋能 Lazada、Daraz 等国际化电商平台,打造云上 NLP 能力的优势项并助力阿里云出海业务拓展;东南亚语言翻译能力赋能钉钉国际化和 Lazada 跨境电商。团队同新加坡高校多名教授开展项目合作,并联合培养近 10 名博士生。
何瑞丹,现任阿里巴巴达摩院 NLP Lab 新加坡团队 Scientist,新加坡国立大学博士。目前研究兴趣包括迁移学习,无监督/半监督学习,低资源 NLP 等。
张琰, 新加坡国立大学博士后,博士毕业于新加坡科技与设计大学, 研究方向为图与文本表示学习。
李俊涛,苏州大学特聘副教授,2020 年从北京大学王选计算机研究所&大数据中心获得博士学位。研究方向为自然语言生成,对话系统,跨语言&领域迁移。截止到 2020 年,在 ACL/EMNLP/AAAI/IJCAI 上发表 10 余篇论文,两次 CCF A 会议 tutorial 报告。担任 ACL/EMNLP/AAAI/IJCAI/CL/TKDE 等会议和期刊审稿人。
叶海,新加坡国立大学研究助理,目前研究兴趣:CQA、低资源 NLP 等。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




