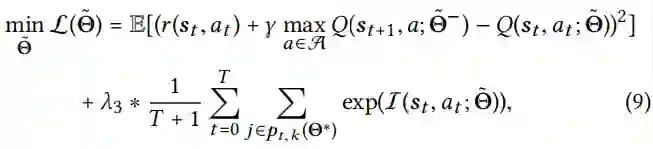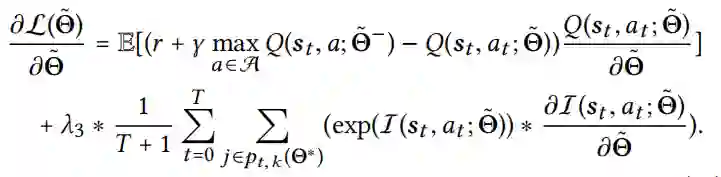作者 | 马尔可夫
近日,第 26 届 ACM SIGKDD 知识发现和数据挖掘会议KDD 2020公布了最佳论文奖、最佳论文亚军奖、最佳学生论文奖等多个奖项。
其中来自弗吉尼亚大学的 Mengdi Huai、Jianhui Sun、Renqin Cai、Aidong Zhang 和来自纽约州立大学布法罗分校的 Liuyi Yao 获得了最佳论文奖的亚军,获奖论文是《Malicious Attacks against Deep Reinforcement Learning Interpretations》。
论文链接:https://dl.acm.org/doi/pdf/10.1145/3394486.3403089
AI科技评论对这篇获得最佳论文亚军奖的论文进行了解读,现与读者分享。
过去几年,深度强化学习(DRL)发展迅速,它是深度学习和强化学习的结合。然而深度神经网络的采用使得DRL的决策过程变得不透明。在此动机下,人们提出了多种解释DRL的方法。然而,这些解释方法都做了一个隐含的假设,即他们是在一个安全可靠的环境下进行网络训练和计算的。在实践中,模型连续与环境的交互使DRL算法及其相对应的下游解释面临额外的对抗性风险。目前还没有针对DRL解释性攻击的可能性和可行性的工作。为了弥补这一空白,了解DRL解释方法在恶意环境下的性能,本文研究了其对攻击的脆弱性。主要有两点贡献:
1、首先,提出了一种针对DRL解释的具有普遍性的对抗攻击框架(UADRLI)
,其目的是制作一个单一的普遍性扰动、并能在每个时间步上被统一的应用。基于提出的方法,攻击者可以通过状态扰动有效的欺骗后续状态的DRL解释方法。
2、设计了一种针对DRL解释的模型中毒攻击框架(MPDRLI)
,基于此,攻击者可以通过向模型提供一个经过策略毒害但同样有效的预训练模型来秘密改变解释结果。
这种类型的攻击发生在DRL的测试阶段,攻击者在目标DRL模型训练后对输入数据进行篡改。与深度监督学习模型不同的是,DRL模型的决策是即时和独立的,对DRL模型的对抗攻击是非常难以定量分析和有效防御的,因为DRL模型涉及到一个时间依赖性的顺序决策过程,不同时间步骤的状态是可扰动的。在每个目标受攻击DRL时间步中,攻击者的目标是通过操纵智能体和环境之间沟通的当前状态观测值来欺骗DRL模型和相应的DRL解释方法。例如在脓毒症患者临床记录的某一时间点,攻击者可以通过添加对抗性的扰动到患者的临床记录上,这不仅导致DRL模型产生错误的医疗决策,而且还会导致所采用的解释方法会给出错误的解释结果。
与测试阶段的对抗攻击不同,模型中毒攻击发生在DRL的训练阶段。在这种类型的攻击中,攻击者的目的是在保持DRL原有性能的前提下,通过操纵学习到的DRL模型参数,大幅度降低DRL解释方法的性能,以保证最大的隐蔽性。这种类型的攻击在很多实际应用场景中很常见。比如由于训练DRL模型需要巨大的计算成本,算法采用从在线模型库中下载预先训练好的DRL模型进行操作,使模型在不知不觉中下载一个被恶意训练好的DRL模型。
在本节中,作者首先介绍了威胁模型,然后开发一个优化框架来形式化针对DRL解释(即UADRLI)的通用对抗性攻击。然后,对提出的通用攻击进行了理论分析。按照对抗性攻击的工作原理,作者在这里假设一个白盒环境,这是一个保守和现实的假设。这种环境下的攻击者试图在测试阶段通过操纵恶意状态来逃避系统的攻击。
攻击者无法改变用于训练模型的DRL算法,也无法改变策略网络的架构。攻击者只能更改模型与环境之间通信的状态观察值。攻击者的目的是欺骗训练好的DRL模型和它所采用的解释方法。
DRL是面向目标的,如果攻击者在每一步都打乱观察到的状态,攻击就很容易被发现。原因是当攻击者干扰每一个观察到的状态时,最终累积的奖励将会很大程度上受到损害。在攻击者这边,他也想最大化他的期望效果。在本文中,我们考虑了攻击者希望攻击的总时间步长最大的情况。另一方面,为了避免被发现,攻击者还应该确保整个DRL任务的最终目标不会受到严重损害。在实践中,模型的最终目标是形式化的长期累积的回报。具体来说,攻击者应该确保攻击前后累积奖励的差异很小,这个差
异的定义是:
现在的问题是攻击者如何找到一个有效的攻击策略{k0,···,kT}与相应的单一普遍的微扰δ,这不仅会使得攻击者的效用最大化,也会对模型的最终目标造成最小的损害。基于上述参数,攻击者的目标是在最大的步骤数中对环境状态添加最小的通用扰动,同时对模型的最终目标造成最小的损害。考虑到这个目标,对于由一系列状态-行动对{(st, at)}Tt=0和威胁模型组成的给定事件,在高层上,我们使用以下优化框架来制定所提议的对抗性攻击:
其中T1 = {t : kt = 1}表示被攻击的时间步数集合,λ1和λ2是两个正则化参数。第一个损失项被利用来强制实际的最终累积奖励不发生重大变化。第二个损失项用于降低被攻击图像区域内的像素的重要性分数。引入第三个损失项则是为了最大化攻击者的效用(即攻击时间步数)。两个超参数(即λ1和λ2)平衡了这三个因素。第三个约束允许攻击者在ϵ预算内操纵模型感知的所有状态,因此确保普遍扰动(即δ)不可感知。最后一个约束条件迫使模型预测是错误的。
在本节中,作者首先描述了中毒攻击中的威胁模型,然后提出了一个算法框架来严格设计一个针对DRL模型解释的中毒攻击。攻击者的目标是操纵预先训练好的DRL模型的参数,从而使解释结果发生重大改变。考虑到前述的例子,由于计算资源有限,模型攻击者会下载第三方提供的预先训练好的DRL模型。在这个过程中,攻击者可能会对系统造成潜在威胁。与传统的数据中毒攻击相比,作者将此攻击称为模型中毒攻击,因为攻击者直接操纵训练阶段生成的预训练模型参数,而不是训练数据集。
在实践中,模型中毒攻击比数据中毒攻击更加普遍,因为攻击者不一定能访问到训练数据库,因为训练数据库通常由专业人员保护,攻击者可以伪装成第三方模型提供者,而普通的模型可能会从攻击者那里获得中毒模型。
如果经过再训练的DRL模型的性能显著下降,通过对验证博弈的评估可以很容易地检测到模型中毒攻击,然后模型会立即拒绝经过再训练的DRL模型。因此,攻击者在操作经过训练的DRL模型时,应该保证能够在不严重损害原始DRL模型性能的情况下显著改变解释结果。为了解决这一挑战,作者建议设计针对DRL解释的“中毒攻击”模型,方法是将预训练的DRL模型与目标函数进行微调,目标函数将原始DRL模型的普通损失与解释结果中的惩罚项结合起来。在不失一般性的情况下,下面使用DQN算法作为DRL的一个典型例子来表示所提出的模型中毒攻击(即MPDRLI)。注意,提议的MPDRLI与模型无关,可以自然地推广到其他DRL算法。
深层Q网络通过正向传递预测出相应的Q值Q(st ,at ; Θ),其中Θ为深层Q网络的参数。Q(st , at ; Θ)值是对未来预期报酬的估计,可以从(st , at )中获得。通过选择每个状态下Q值最大的行动,得到DQN的相应策略。深层Q网络参数(即Θ)可以通过最小化来求出以下是平均平方贝尔曼误差:
其中
![]() 代表目标网络的参数,在线网络的参数Θ是通过对过去过渡元组的mini-batches采样进行梯度更新。上述均方误差衡量的是目标Q值的平方差
代表目标网络的参数,在线网络的参数Θ是通过对过去过渡元组的mini-batches采样进行梯度更新。上述均方误差衡量的是目标Q值的平方差
![]() 和当前Q的输出:
和当前Q的输出:
![]() 。
在这里,我们考虑的是攻击者想要秘密的改变模型参数,这样模型就无法用针对性的解释方法弄清楚什么特征对当前的动作预测真正上最重要。在我们的模型中毒攻击设置中,攻击者对训练数据集
。
在这里,我们考虑的是攻击者想要秘密的改变模型参数,这样模型就无法用针对性的解释方法弄清楚什么特征对当前的动作预测真正上最重要。在我们的模型中毒攻击设置中,攻击者对训练数据集
![]() 一无所知,但他可以通过反复运行目标模型来收集一个替代数据集
一无所知,但他可以通过反复运行目标模型来收集一个替代数据集
![]() 。让
。让
![]() 表示对状态-动作,对(st , at )而言,原始纯净的DQN模型(参数化为
表示对状态-动作,对(st , at )而言,原始纯净的DQN模型(参数化为
![]() )的解释器I具有前k个最高的显著性地图值的像素集。需要注意的是,为了避免被检测到,攻击者应该保持再训练DRL模型的性能,同时只关注攻击解释结果。为了实现攻击目标,根据事先训练好的模型参数
)的解释器I具有前k个最高的显著性地图值的像素集。需要注意的是,为了避免被检测到,攻击者应该保持再训练DRL模型的性能,同时只关注攻击解释结果。为了实现攻击目标,根据事先训练好的模型参数
![]() 和替代数据集
和替代数据集
![]() ,
攻击者可以对原来纯净的DQN 模型进行如下操作。
其中
,
攻击者可以对原来纯净的DQN 模型进行如下操作。
其中
![]() 为原无攻击DQN模型的模型参数,λ3为权衡参数,惩罚项的设计是为了降低原来最高值为k的像素的解释得分。通过对上述损失函数相对于Θ˜进行微分,我们可以得到如下梯度。
然后在此基础上,使用梯
度下降方法对DQN模型进行再训练。
注意,原始参数Θ∗作为初始化参数。
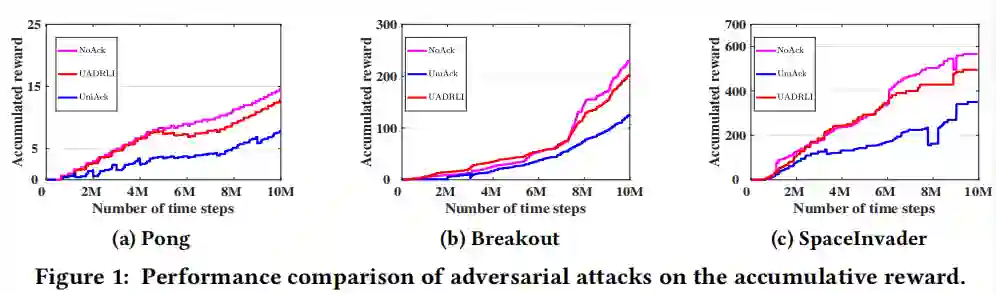
对于所提出的普遍攻击,在实验中,作者首先采用统一对抗攻击作为baseline,称为UniAck,它是传统对抗攻击在DRL上的直接延伸。在UniAck中,作者将生成的普遍扰动应用于每个时间步的观测状态。此外,作者还将模型在提出的对抗性攻击下的性能与无对抗性攻击下的性能进行比较,表示为NoAck。对于所提出的模型中毒攻击,由于目前还没有解决DRL对中毒攻击的脆弱性的工作,作者采用无模型中毒攻击基线(称为NoPAck)。对抗性攻击表现在折现的累计奖励上。接下来,通过对目标模型累计的总奖励进行平均,来比较所提议的UADRLI与两个基线的性能。
图中的参考线为紫色,对应于no attack (NoAck)下的奖励函数。
从图中可以看出,我们提出的UADRLI可以达到与原始未攻击DRL模型相似的效果。
相比之下,采用基线UniAck袭击时间步骤,相应的状态差异很高,它很明显的减少了累积奖励。
综上所述,无论agent玩哪一个博弈,所提出的UADRLI确实会导致策略性能的轻微下降。
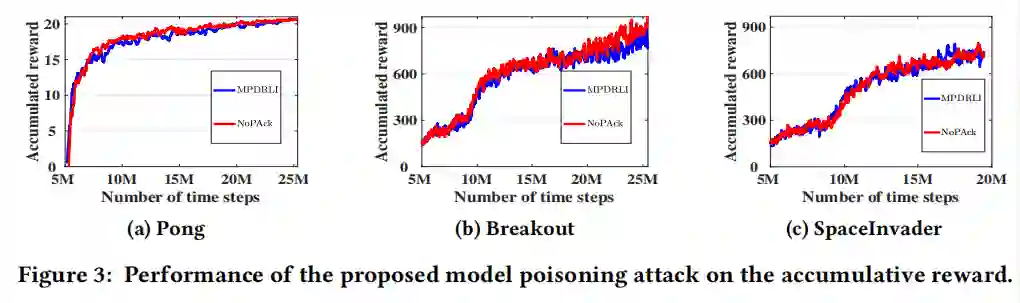
接着作者进行了模型中毒攻击实验,使用的DRL算法为DQN。
实验结果表明,中毒攻击对原DRL模型的性能影响较小。
通过这种方式,中毒攻击可以保持不被发现(也就是说,隐形)。
在实践中,如果中毒的DRL模型的性能显著下降,模型只需检查累积的奖励就可以很容易地检测发起的攻击。
本文是第一个研究DRL解释对恶意攻击的脆弱性的论文。
在本文中,作者首先提出了一种针对DRL解释的通用对抗性攻击框架(即UADRLI),攻击者可以从中以最大的步数将制作好的普遍扰动统一添加到环境状态中,以对模型的最终决策造成最小的损害。然后,设计了一种针对DRL解释的模型中毒攻击框架(即MPDRLI),基于此,攻击者可以显著改变解释结果,同时对原DRL模型的性能造成微小的损害。
本文同时提供了理论分析和大量的实验结果,以证明其有效性。作者提出了针对DRL解释的恶意攻击,并且分析提供了关于针对DRL解释的恶意攻击的有价值的见解,这对研究人员研究如何防御这种恶意攻击大有帮助。
为原无攻击DQN模型的模型参数,λ3为权衡参数,惩罚项的设计是为了降低原来最高值为k的像素的解释得分。通过对上述损失函数相对于Θ˜进行微分,我们可以得到如下梯度。
然后在此基础上,使用梯
度下降方法对DQN模型进行再训练。
注意,原始参数Θ∗作为初始化参数。
对于所提出的普遍攻击,在实验中,作者首先采用统一对抗攻击作为baseline,称为UniAck,它是传统对抗攻击在DRL上的直接延伸。在UniAck中,作者将生成的普遍扰动应用于每个时间步的观测状态。此外,作者还将模型在提出的对抗性攻击下的性能与无对抗性攻击下的性能进行比较,表示为NoAck。对于所提出的模型中毒攻击,由于目前还没有解决DRL对中毒攻击的脆弱性的工作,作者采用无模型中毒攻击基线(称为NoPAck)。对抗性攻击表现在折现的累计奖励上。接下来,通过对目标模型累计的总奖励进行平均,来比较所提议的UADRLI与两个基线的性能。
图中的参考线为紫色,对应于no attack (NoAck)下的奖励函数。
从图中可以看出,我们提出的UADRLI可以达到与原始未攻击DRL模型相似的效果。
相比之下,采用基线UniAck袭击时间步骤,相应的状态差异很高,它很明显的减少了累积奖励。
综上所述,无论agent玩哪一个博弈,所提出的UADRLI确实会导致策略性能的轻微下降。
接着作者进行了模型中毒攻击实验,使用的DRL算法为DQN。
实验结果表明,中毒攻击对原DRL模型的性能影响较小。
通过这种方式,中毒攻击可以保持不被发现(也就是说,隐形)。
在实践中,如果中毒的DRL模型的性能显著下降,模型只需检查累积的奖励就可以很容易地检测发起的攻击。
本文是第一个研究DRL解释对恶意攻击的脆弱性的论文。
在本文中,作者首先提出了一种针对DRL解释的通用对抗性攻击框架(即UADRLI),攻击者可以从中以最大的步数将制作好的普遍扰动统一添加到环境状态中,以对模型的最终决策造成最小的损害。然后,设计了一种针对DRL解释的模型中毒攻击框架(即MPDRLI),基于此,攻击者可以显著改变解释结果,同时对原DRL模型的性能造成微小的损害。
本文同时提供了理论分析和大量的实验结果,以证明其有效性。作者提出了针对DRL解释的恶意攻击,并且分析提供了关于针对DRL解释的恶意攻击的有价值的见解,这对研究人员研究如何防御这种恶意攻击大有帮助。
AI科技评论联合博文视点赠送周志华教授“森林树”十五本,在“周志华教授与他的森林书”一文留言区留言,谈一谈你和集成学习有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,每人送出《集成学习:基础与算法》一本。
活动规则:
1. 在“周志华教授与他的森林书”一文留言区留言,留言点赞最高的前 15 位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年8月23日 - 2020年8月30日(23:00),活动推送内仅允许中奖一次。
阅读原文,直达“ KDD”小组,了解更多会议信息!


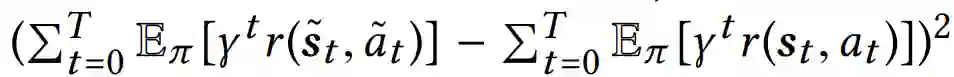
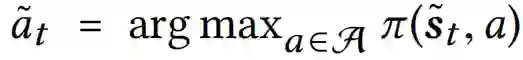
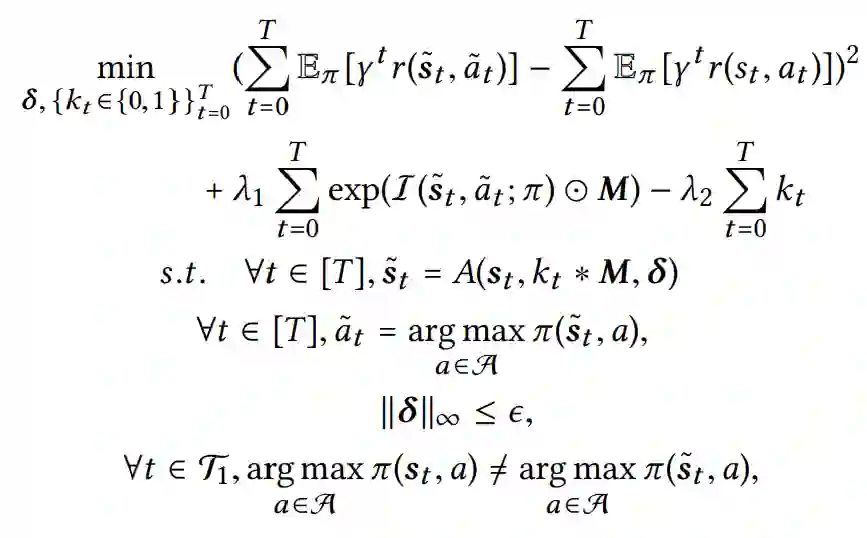
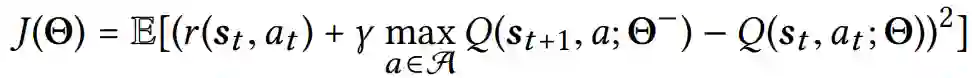
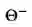 代表目标网络的参数,在线网络的参数Θ是通过对过去过渡元组的mini-batches采样进行梯度更新。上述均方误差衡量的是目标Q值的平方差
代表目标网络的参数,在线网络的参数Θ是通过对过去过渡元组的mini-batches采样进行梯度更新。上述均方误差衡量的是目标Q值的平方差
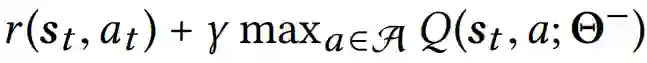 和当前Q的输出:
和当前Q的输出:
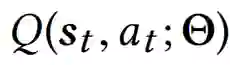 。
。
 一无所知,但他可以通过反复运行目标模型来收集一个替代数据集
一无所知,但他可以通过反复运行目标模型来收集一个替代数据集
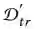 。让
。让
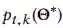 表示对状态-动作,对(st , at )而言,原始纯净的DQN模型(参数化为
表示对状态-动作,对(st , at )而言,原始纯净的DQN模型(参数化为
 )的解释器I具有前k个最高的显著性地图值的像素集。需要注意的是,为了避免被检测到,攻击者应该保持再训练DRL模型的性能,同时只关注攻击解释结果。为了实现攻击目标,根据事先训练好的模型参数
)的解释器I具有前k个最高的显著性地图值的像素集。需要注意的是,为了避免被检测到,攻击者应该保持再训练DRL模型的性能,同时只关注攻击解释结果。为了实现攻击目标,根据事先训练好的模型参数