超越Alpha Zero!DeepMind升级版MuZero:无需告知规则,观察学习时即可掌握游戏

新智元报道
新智元报道
来源:DeepMind
编辑:Q
【新智元导读】看过美剧《后翼弃兵》的观众,都会惊叹于女主的象棋天赋,不知道规则看几遍即可掌握,而且可在脑中复盘棋局,反复训练。而今AI也可以做到了!
DeepMind的使命是证明AI不仅可以精通游戏,甚至可以在不知道规则的情况下做到这一点,最新的MuZero就实现了这一目标。
在象棋和围棋比赛中,都是为AI提供了一组不变的、已知的游戏规则,但MuZero完全不需要提供规则手册,通过自己试验,就学会了象棋围棋游戏和各种Atari游戏,其通过考虑游戏环境的各个方面来评估是否重要,并可通过复盘游戏在自身错误中学习。
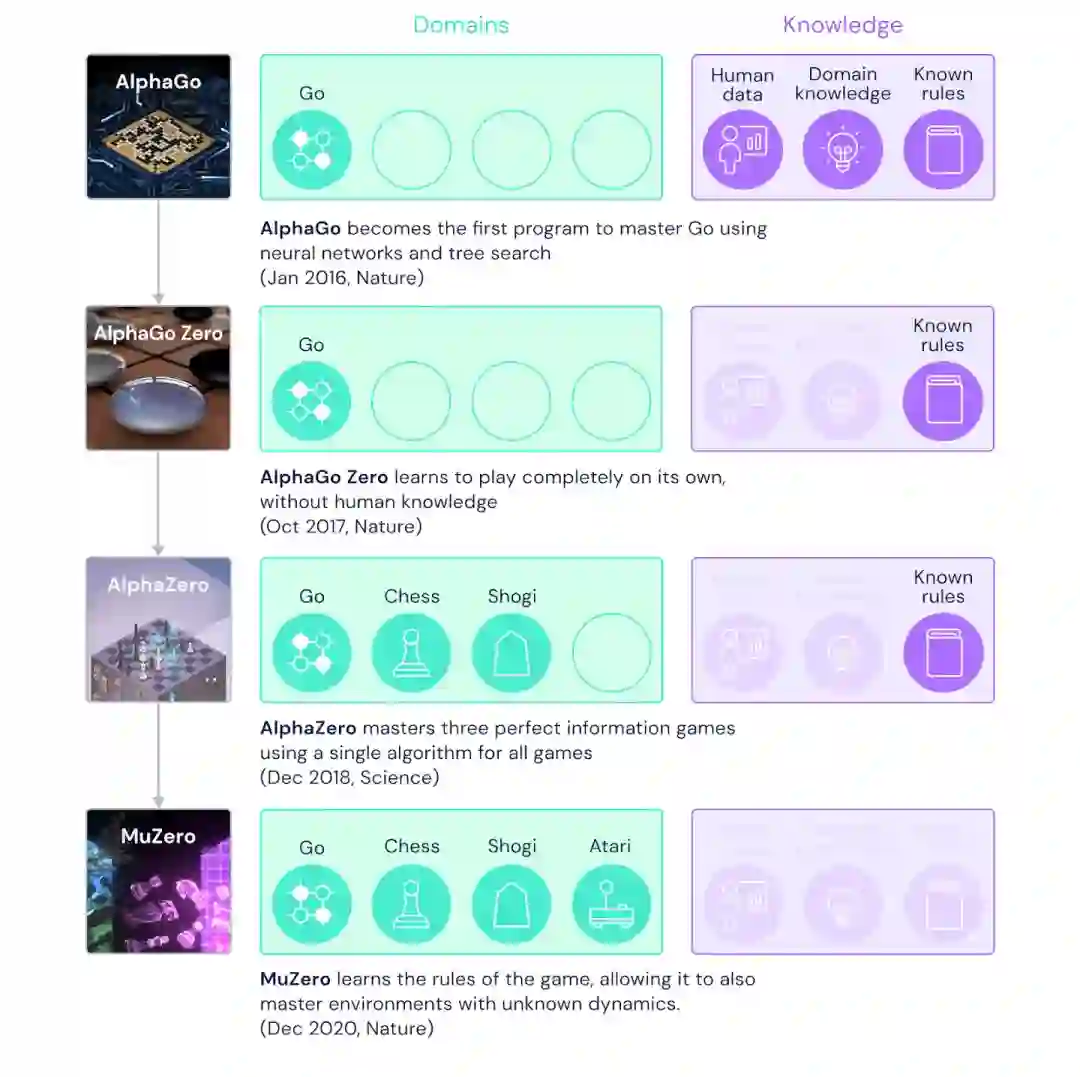
2016年,DeepMind 推出了第一个人工智能程序 AlphaGo,在围棋游戏中击败人类。两年后,它的继任者AlphaZero从零开始学习围棋、国际象棋和将棋。

现在,在《自然》杂志的一篇论文中,DeepMind又带来了 MuZero,这是在寻求通用人工智能算法方面迈出的重要一步。

由于它能够在未知环境中计划胜利的策略,MuZero 掌握围棋、国际象棋、shogi 和 Atari ,而不需要被告知游戏规则。
多年来,研究人员一直在寻找方法,既可以学习一个模型,解释他们的环境,然后可以使用该模型来规划最佳的行动方案。到目前为止,大多数方法都难以有效地在不同domain之间规划,比如 Atari,其中的规则或动态通常是未知的和复杂的。
MuZero 最初在2019年的一篇初步论文中被首次提出,通过学习一个只关注规划environment最重要方面的模型来解决这个问题。通过将这个模型与 AlphaZero 强大的lookahead tree search相结合,MuZero 在 Atari benchmark上达到了SOTA,同时在围棋、国际象棋和将棋的经典规划挑战中与 AlphaZero 的表现相匹敌。通过这样做,MuZero 展示了强化学习算法能力上的一个重大飞跃。
对未知模型的泛化
对未知模型的泛化
做计划的能力是人类智力的重要组成部分,它使我们能够解决问题并对未来做出决定。例如,如果我们看到乌云正在形成,我们可能会预测会下雨,并决定在出门之前带上一把雨伞。人类学习这种能力很快,可以泛化到新的场景当中,这是DeepMind一直希望算法拥有的特征。
研究人员试图通过两种主要方法来解决人工智能中的这一主要挑战: lookahead search 和 model-based planning。
使用lookahead search的系统,如AlphaZero,在跳棋、国际象棋和扑克等经典游戏中取得了显著的成功,但问题在于需要依赖对环境动态的了解,如游戏规则或精确的模拟器。这使得它们很难应用于混乱的现实世界问题,而这些问题通常是复杂的,难以提炼成简单的规则。
基于模型的系统旨在通过学习环境动态的精确模型来解决这个问题,然后使用它来进行规划。然而,建模环境的每一个方面的复杂性之高,使得这类算法无法使用在一些视觉丰富的领域,如Atari。到目前为止,Atari 上最好的结果来自无模型(model-free)系统,如 DQN、 R2D2和 Agent57。顾名思义,无模型算法不使用已知模型,而是估计下一步采取的最佳行动。

MuZero 使用一种不同的方法来克服以前方法的局限性。MuZero 没有尝试为整个环境建模,而是只建模对Agent的决策过程重要的方面。毕竟,知道一把雨伞能让你保持干爽比模拟空气中雨滴的形状更有用。
具体来说,MuZero 模拟了对规划至关重要的三个环境要素:
Value: 目前的位置的好坏程度
Policy: 能采取的最佳程度
Reward: 上一个动作的好坏程度
这些都是通过深层神经网络学习的,这些都是 MuZero 所需要的,以便了解当它采取某种行动时会发生什么,并据此制定计划。

上图展示了蒙特卡罗树搜索如何用 MUZERO 神经网络进行规划。从游戏中的当前位置(顶部的示意图)开始,MUZERO 使用表示函数(H)将观察映射到神经网络(S0)使用的嵌入。使用动态函数(G)和预测函数(F) ,MUZERO 可以考虑未来可能的动作序列(A) ,并选择最佳动作。

MUZERO 使用它在与环境互动时收集的经验来训练它的神经网络。这种经验包括来自环境的观察和奖励,以及在决定最佳行动时所进行的搜索的结果。
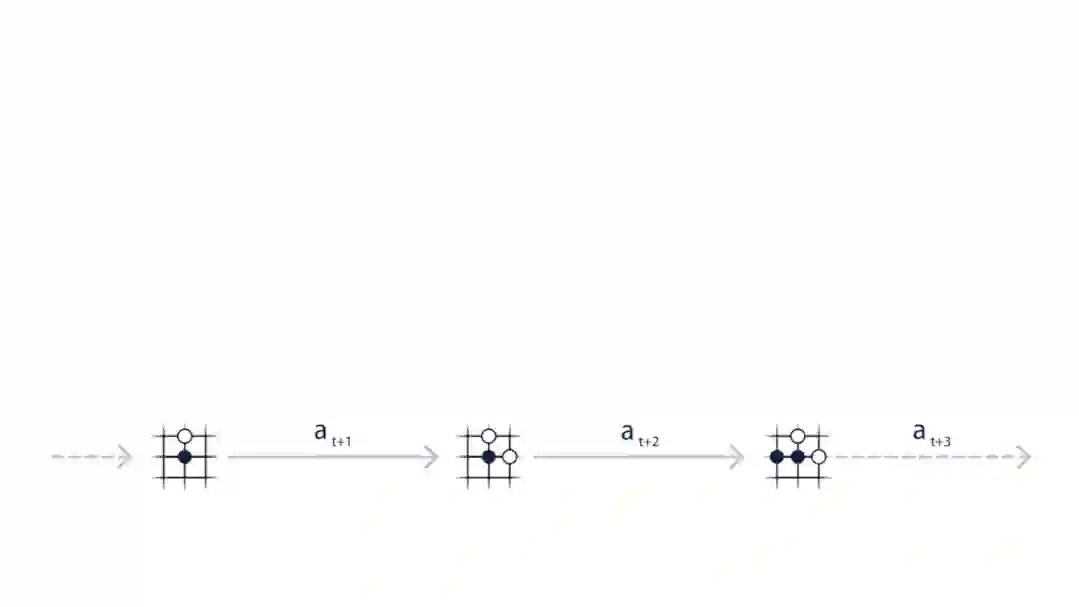
在训练过程中,该模型与收集到的经验一起展开,在每个步骤中预测先前保存的信息: 价值函数 V 预测和观测的奖励之和(U) ,策略估计(P)预测先前的搜索结果(Π) ,奖励估计(R)预测最后的观测奖励(U)。
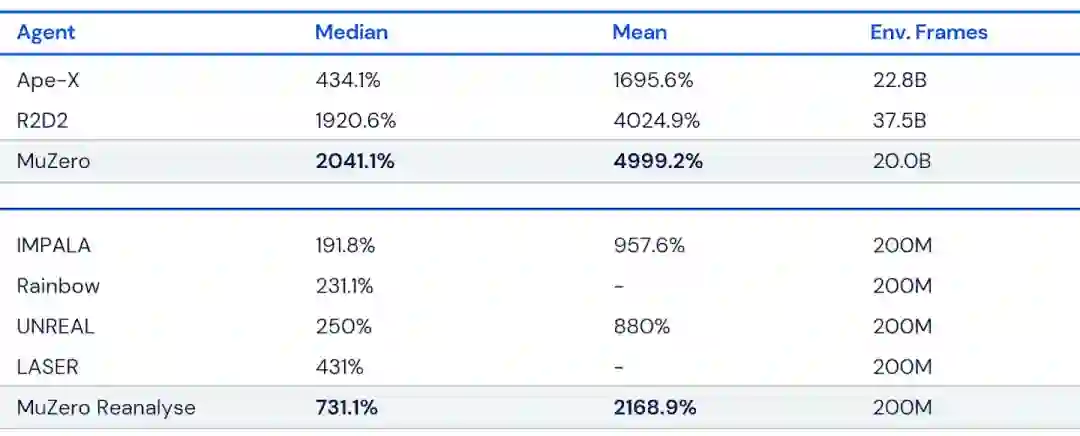
这种方法还有另一个主要的好处: MuZero 可以重复使用它学到的模型来改进它的计划,而不是从环境中收集新的数据。例如,在 Atari 套件的测试中,这个变体被称为 MuZero Reanalyze,它90% 的时间使用模型来重新计划在过去的经验中应该做什么。
性能
性能
DeepMind 选择了四个不同的Domain来测试 MuZeros的能力。围棋、国际象棋和将棋被用来评估它在具有挑战性的规划问题上的表现,而我们使用Atari套件作为更复杂的视觉问题的基准。在所有的情况下,MuZero 的强化学习的算法达到了新的SOTA,在 Atari 套件上的表现优于所有之前的算法,并且匹配了围棋、国际象棋和将棋的 AlphaZero 的超人表现。
DeepMind的研究人员还更详细地测试了 MuZero 如何使用它学到的模型进行规划。
从围棋中经典的精确规划的挑战开始,其中一步棋就能决定输赢。为了证实规划更多应该导致更好的结果的直觉,测量给予更多的时间来计划每一步行动时,一个完全训练过的 MuZero 版本能变得多么强大(见下面的左图)。结果显示,当把每次移动的时间从0.1秒增加到50秒时,游戏力量增加了1000多 Elo(一个玩家的相对技能的度量)。这类似于业余选手和职业选手之间的区别。
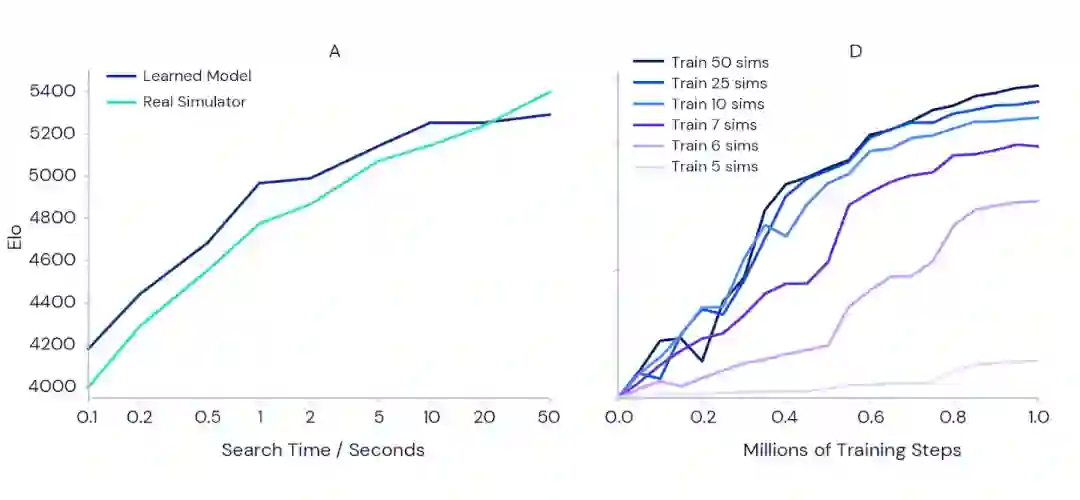
为了测试计划是否在整个训练过程中也带来好处,研究人员在 Atari 游戏 Ms Pac-Man (上面的右图)上进行了一系列实验,使用了单独的训练过的 MuZero 实例。每次行动都允许考虑不同数量的规划模拟,范围从5到50。结果证实,增加每个动作的计划量可以让 MuZero 更快地学习并获得更好的最终性能。
有趣的是,当 MuZero 被允许每次只考虑六到七次模拟时,无法涵盖 Pac-Man 中的所有可用动作,但它仍然取得了良好的性能。这表明,MuZero 能够在行动和情况之间进行概括,而不需要为了有效地学习而竭尽全力地寻找所有可能性。
MuZero 既能够学习环境模型,又能够成功地使用它来进行计划,这证明了在强化学习算法和通用人工智能算法方面的重大进步。
它的前身 AlphaZero 已经应用于化学、量子物理等领域的一系列复杂问题。而 MuZero 强大的学习和规划算法背后的理念,可能为应对机器人技术、工业系统以及其它游戏规则尚不为人知的混乱现实环境中的新挑战铺平了道路。


