最新知识图谱论文清单,就算看不懂也会忍不住收藏

精选 6 篇来自 EMNLP 2018、COLING 2018、ISWC 2018 和 IJCAI 2018 的知识图谱相关工作,带你快速了解知识图谱领域最新研究进展。
本期内容选编自微信公众号「开放知识图谱」。


■ 论文解读 | 张良,东南大学博士,研究方向为知识图谱、自然语言处理
本文主要关注 KG embedding 中三元组成立的时间有效性问题,比如三元组(Cristiano Ronaldo, playsFor, Manchester United),其成立的有效时间段是 2003 年到 2009 年,这个使三元组有效成立的时间段被称为 temporal scopes。
这些 temporal scopes 随着时间的推移对许多数据集会产生影响(比如 YAGO,Wikidata),现有的 KG embedding 方法很少考虑到时间这一维度,因为它们假设所有的三元组总是永远正确的,可是现实中很多情况下不是这样。
本文提出了 HyTE 模型,HyTE 不仅能够利用时间导向进行知识图谱图推理,还能够为那些缺失时间注释的事实预测 temporal scopes。实验结果表明该模型与传统模型或者同类模型相比都有着突出的表现。
研究背景
知识图谱嵌入(Knowledge graph embedding)方法是将知识图谱中的实体和关系表示成连续稠密低维实值向量,从而可以通过向量来高效计算实体与关系的语义联系。从 2013 年 TransE 的提出,到后来一系列的衍生模型,比如 TransH,TransD,TransR,DKRL, TKRL, RESCAL, HOLE 等等,都是对 TransE 模型的扩展。
这些模型都没有考虑时间维度,一直将知识图谱当做静态来处理,这显然不符合事实。数据的暴涨与更新表明知识图谱本来就是动态的,所以后来有工作将时间信息考虑进去,但只是将时间序列作为 KG embedding 过程中的约束,没有明显地体现时间的特性。为此,本文提出的 HyTE 模型直接在学习的过程中结合时间信息。
论文模型
本文认为不仅是知识图谱中的实体可能会随着时间改变,实体间的关系也是如此。由于 TransE 模型不能处理多关系的情形,而 TransH 模型能够使实体在不同的关系下拥有不同的表示,所以本文受 TransH 的启发提出了一个基于超平面的时间感知知识图谱嵌入模型。
考虑一个四元组 (h,r,t,[τs, τe]),这里的 τs 和 τe 分别定义了三元组成立时间段的起始与截止。TransE 模型将实体和关系考虑到相同的语义空间,但是在不同的时间段,实体与关系组成的(h,r)可能会对应到不同的尾实体 t。
所以在本文的模型中,希望实体能够随不同的时间点有着不同的表示。为了达到这一目的,文中将时间表示成超平面(hyperplane),模型示意图如下:
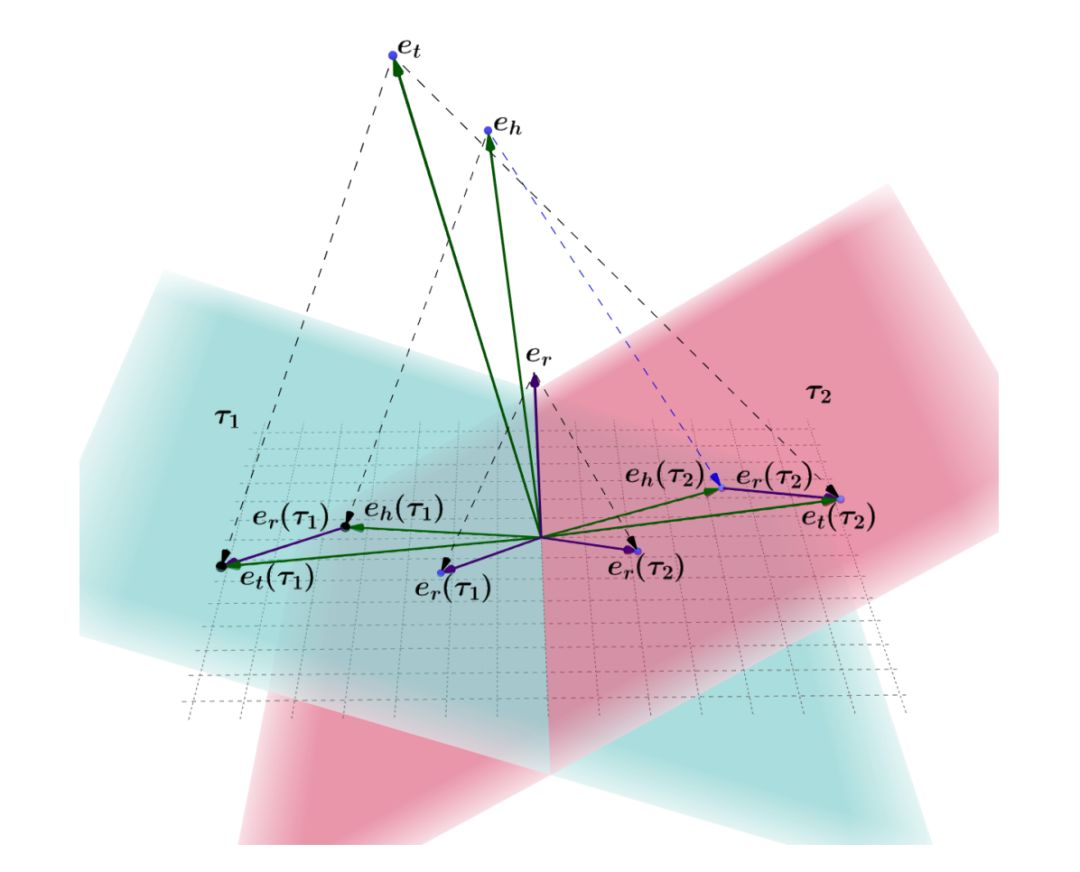
eh,et,er,分别表示三元组中头实体,尾实体以及关系所对应的向量表示,τ1 和 τ2 分别表示此三元组有效成立时间段的起始时间与截止时间。eh(τ1), er(τ1) 以及表示各向量在时间超平面 τ1 上的投影,最终,模型通过最小化翻译距离来完成结合时间的实体与关系 embedding 学习过程。
实验
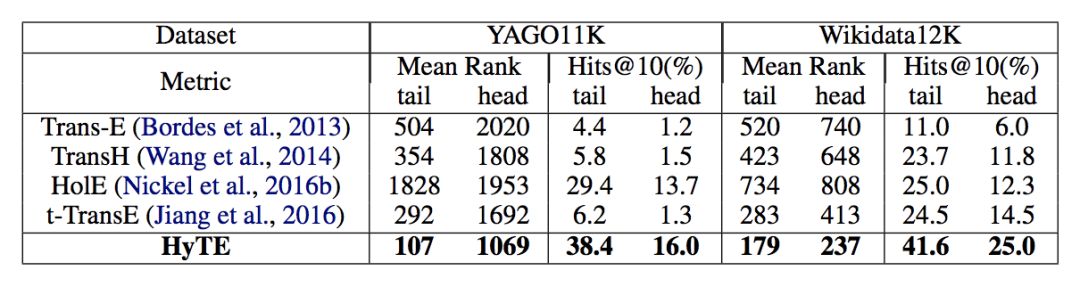
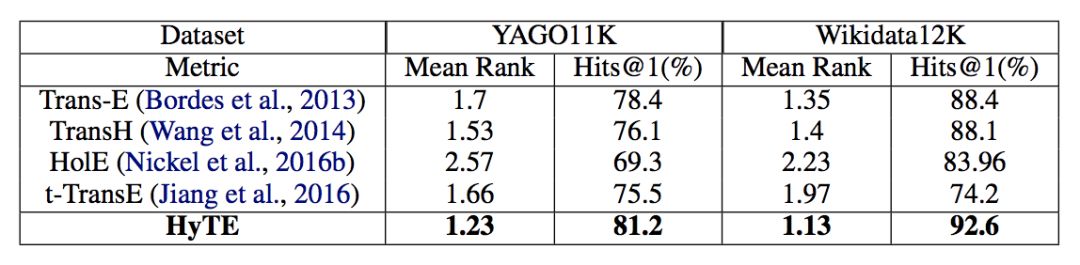
当实验数据包含两部分:YAGO11k 和 Wikidata12k,这两个数据集抽取了 YAGO 以及 Wikidata 中带有时间注释(time annotations)的部分。通过 Link prediction 以及 Temporal scoping 两个实验任务与其它模型比较,实验结果如下:
实体预测结果
关系预测结果
Temporal Scoping预测结果(越小越好)
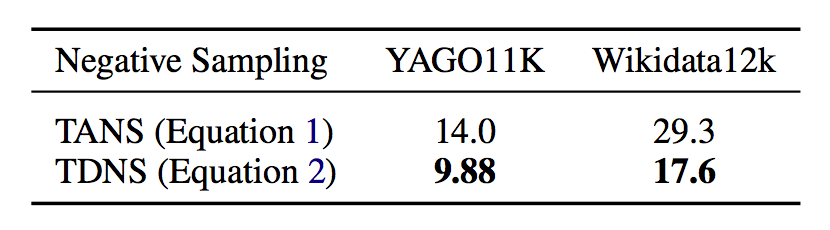
实验结果表明,HyTE 模型在相关任务上与其它模型相比有较为显著的提升。


■ 论文解读 | 王梁,浙江大学硕士,研究方向为知识图谱、自然语言处理
研究背景
机器阅读任务按照答案类型的不同,可以大致分为:
分类问题:从所有候选实体选择一个;
Answer Span:答案是输入文本的一个片段;
生成式问题:模型生成一句话回答问题。
不同的数据集文档的差异也较大。如 SQuAD,CNN/DM 数据集来源于百科,新闻等文本,问题类型多为事实型,因而回答问题不需要综合全文多处进行综合推理,只需要包含答案的句子即可。而本文实验所用的数据集如 NarrativeQA 则来源于小说等,回答问题需要综合全文多处不相连片段进行推理,因此难度更大。
本文提出在 NarrativeQA 等需要多跳推理的文本进行生成式问题回答的模型。人工抽样数据集样本分析发现,许多样本答案的推理单凭文本包含的信息是无法完成推理并回答的,需要引入外部知识库中的常识信息。本文提出在常规的机器阅读模型中引入 ConceptNet 中的常识信息。
Baseline模型
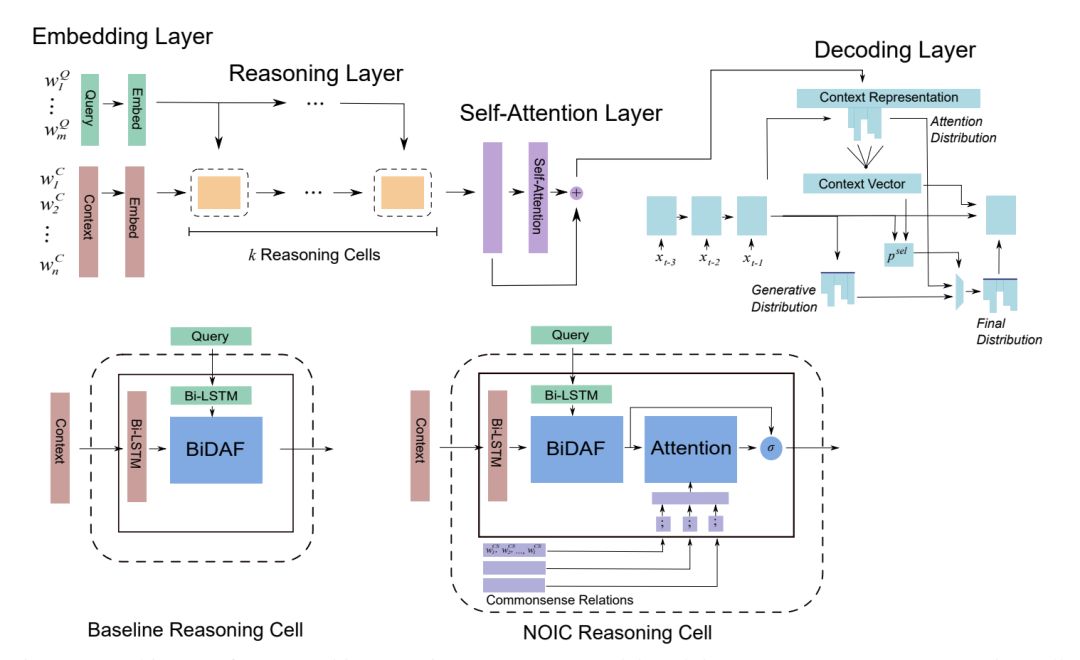
按照机器阅读模型的一般性结构,Baseline 模型可以分为 4 层:
1. Embedding Layer:问题和文档里的每个词用预训练的词向量和 ELMo 向量表示;
2. Reasoning Layer:重复执行 K 次推理单元,推理单元的内部结构是 BiDAF 模型的 attention 层;
3. Model Layer:最后再对文档的表示做 self-attention 和 Bi-LSTM;
4. Answer Layer:pointer-generator decoder,即 RNN 的每一步同时对词表和输入计算输出概率,每个词在当前位置被输出的概率为其在词表中被选中的概率和其在输入中被 copy 的概率之和。
改进模型:引入外部常识
常识挑选
对每一个样本,需要中外部 KG 中选择与之相关的多跳路径,做法如下:
1. 在 KG 中找出多跳路径,其中包含的实体出现在样本的问题或文档中;
2. 对这些路径中的实体节点按照出现次数或 PMI 打分;
3. 类似 beam search,从所有路径生成的输出中挑选出得分最高的一些路径,这些路径是对该样本可能有帮助的外部常识信息。
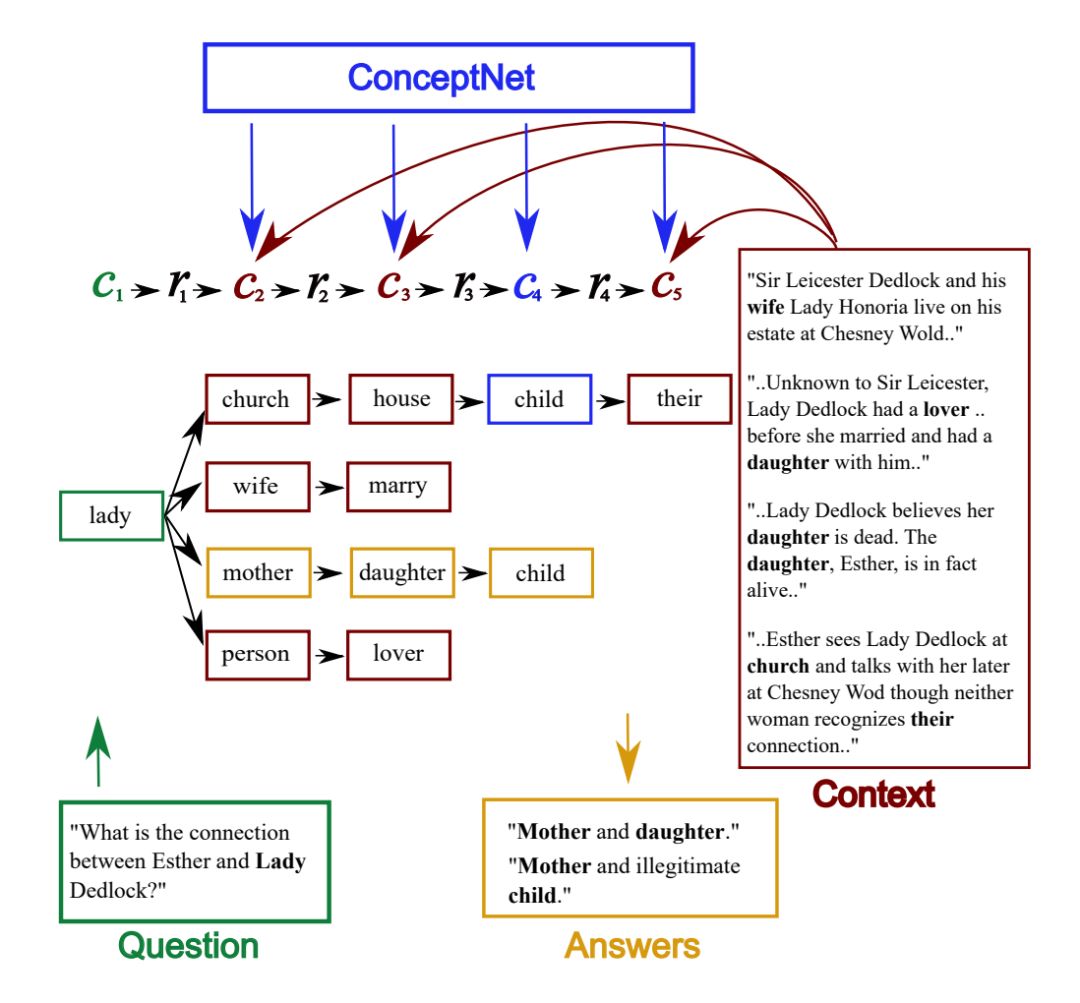
模型引入常识
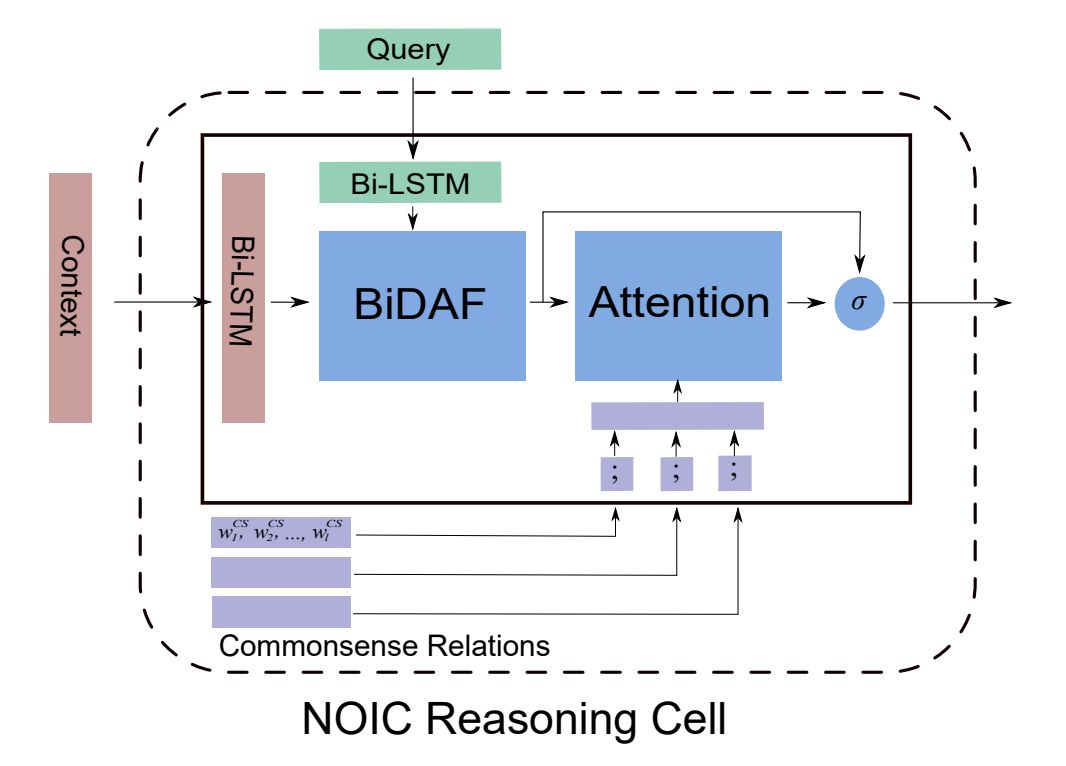
引入外部常识通过修改 Reasoning Layer 中的基本单元。具体做法是,每条路径的 embedding 表示为其每个节点的文本 embedding 的简单拼接,修改后的 Reasoning Cell 在经过 BiDAF 的 attention 结构后,再对该样本的所有外部常识三元组路径做 attention 计算,该 attention 计算再次更改文档和问题中每个词的表示。
实验结果
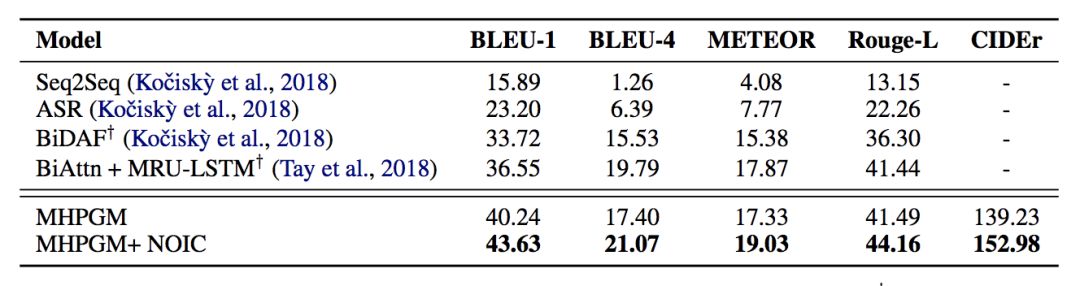
对比 Baseline 模型和引入外部常识的模型可见,引入外部常识能是模型在 BLEU 和 Rouge 等指标上取得不错的提升。
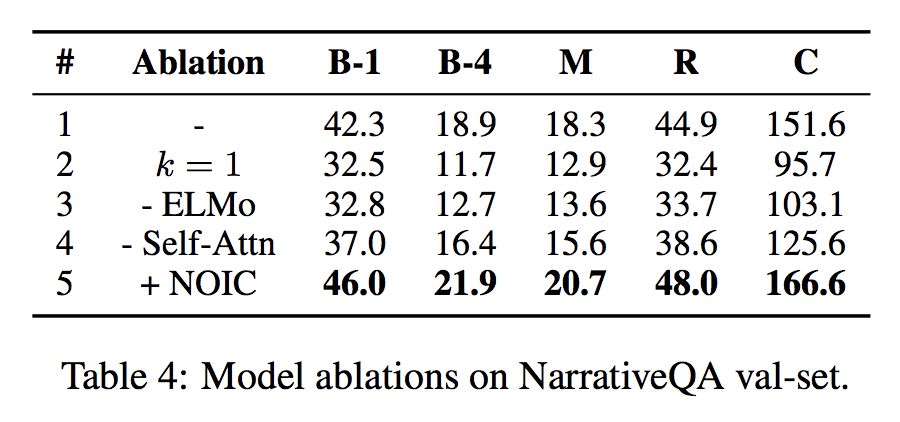
对模型做 ablation test,可以发现推理层的推理次数如果为 1,模型效果下降很多,这表明模型确实在利用多跳的路径信息。另外,ELMo embedding,以及经过 Reasoning 层后的 self-attention,都对模型的效果提升较大。


■ 论文解读 | 丁基伟,南京大学博士生,研究方向为知识图谱、知识库问答
研究背景
面向知识库的语义问答是指将用户的自然语言问句转换为可以在知识库上执行的形式化查询并获取答案,其面临的挑战主要有以下几点:1)实体的识别和链接;2)关系的识别和链接;3)查询意图识别;4)形式化查询生成。
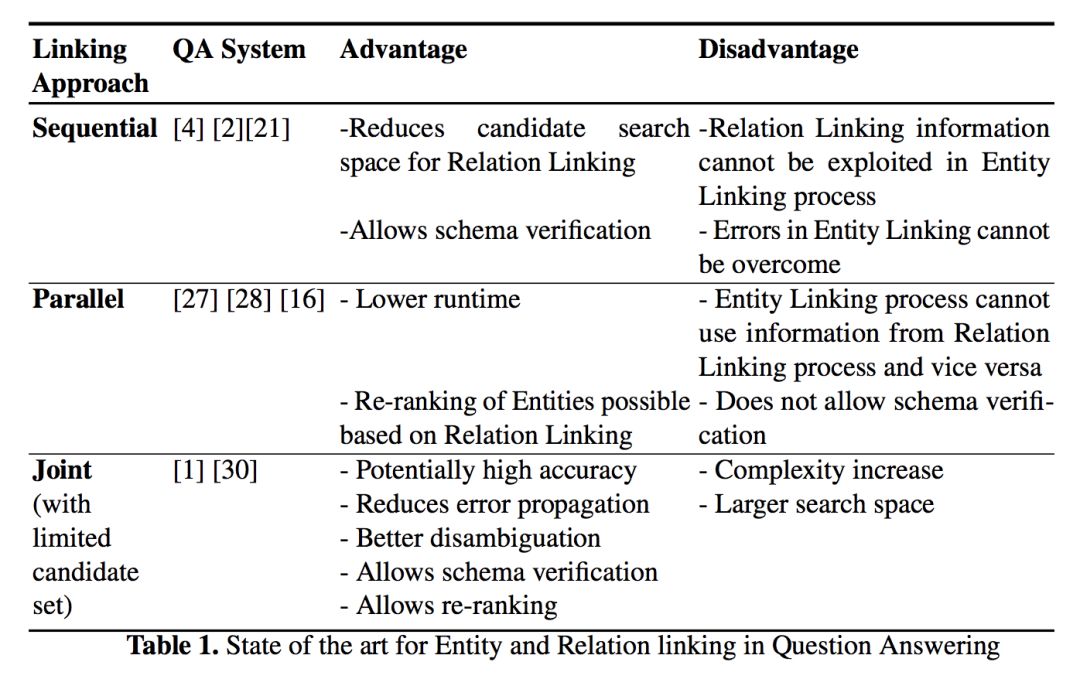
其中实体链接和关系链接是指将自然语言问句中的词汇(或短语)链接到知识库中对应的实体或关系。大多数现有问答系统依次或并行执行实体链接和关系链接步骤,而本工作将这两个步骤合并,提出了基于广义旅行商问题和基于连接密度相关特征进行机器学习的两种联合链接方法。
下表展示了不同种类的链接方法的优缺点:
框架及方法
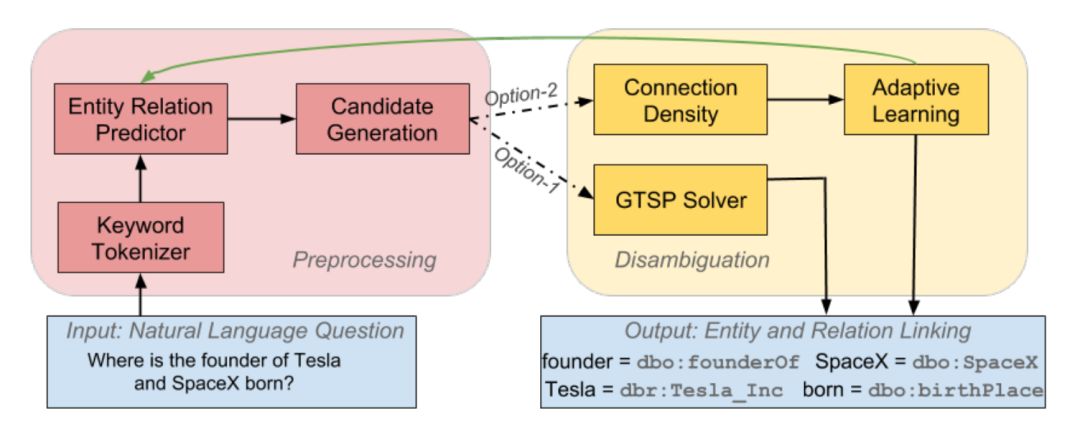
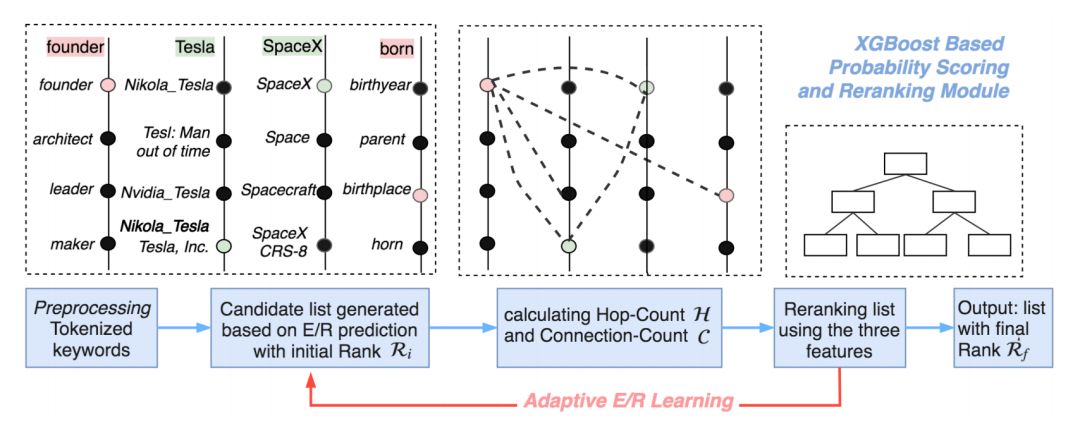
上图展示了本文提出的联合的实体关系链接框架(EARL,Entity and Relation Linking),主要包括如下两个步骤:
预处理步骤(左侧红框),包括如下三个子过程:
1. 利用 SENNA 系统从输入的自然语言问句中抽取出若干关键词短语。对于图中输入的问句,这里抽取到的关键词短语是<founder,Tesla, SpaceX, born>。
2. 对于每个关键词,使用基于字符嵌入(character embedding)的 LSTM 网络判断它是知识库中的关系还是实体。对于上个过程中的关键词短语,这一步将“founder”和“born”识别为关系, 将“Tesla”和“SpaceX”识别为实体。
3. 为每个关键词短语生成候选实体或关系列表。对于问句中的实体名,利用预先收集的 URI-label 词典,以及 Wikidata 中的实体别名、sameas 关系等进行生成。对于关系词,利用 Oxford Dictionary API 和 fastText 扩展知识库上的关系名后进行关联。
联合消歧步骤(右侧黄框),主要包括本文提出的两个核心方法:
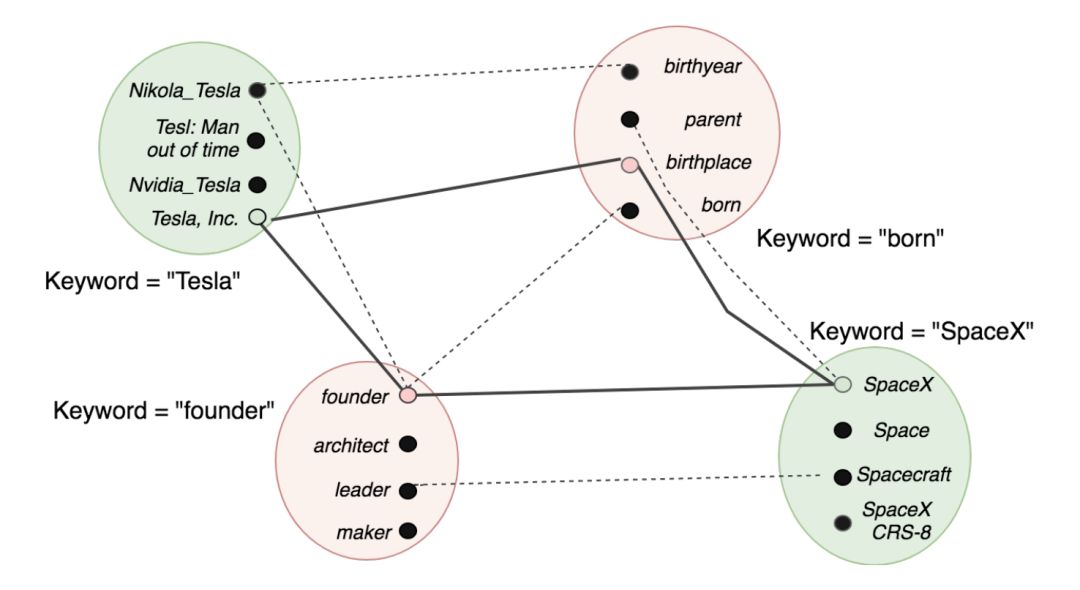
1. 基于广义旅行商问题(GTSP)的消歧方法。如下图所示,该方法将每个关键词的候选 URI 放入同一个簇。边的权重被设置为两个 URI 在知识库上的距离(hop 数),而联合消歧过程被建模为在该图上寻找一条遍历每个簇的边权总和最小的路(头尾结点可以不同)。
对于 GTSP 问题的求解,本工作先将其转换为 TSP 问题,后使用 Lin-Kernighan-Helsgaun 近似算法进行求解。图中加粗的边表示该示例的求解结果。
2. 基于连接密度相关特征进行机器学习的消歧方法。对于每个关键词的所有候选 URI,分别抽取特征 Ri(候选列表中的排序位置),C(2 步以内可达的其他关键词的候选 URI 的数量),H(到其他关键词的候选 URI 的平均步数)三个特征,采用 XGBoost 分类器筛选最合适的候选。
下表总结了上述两个消歧方法的差异:

3. 额外的,本文提出了一种自适应实体/属性预测方法。如果消歧后某个实体/关系和它最终链接到的 URI 的置信度低于阈值,则可能预处理步骤的第二个子过程(实体/关系预测)有错误。在这种情况下,该工作会更改该关键词的实体/关系标签,重新执行候选生成和消歧步骤,从而获得整体精度的提升。
实验
本文选用了 LC-QuAD 问答数据集进行实验,包含 5000 个问句。其标准答案(实体/关系对应的 URI)采用人工标注的方法进行生成。除此以外本文还选用了现有的 QALD-7 问句集进行测试。
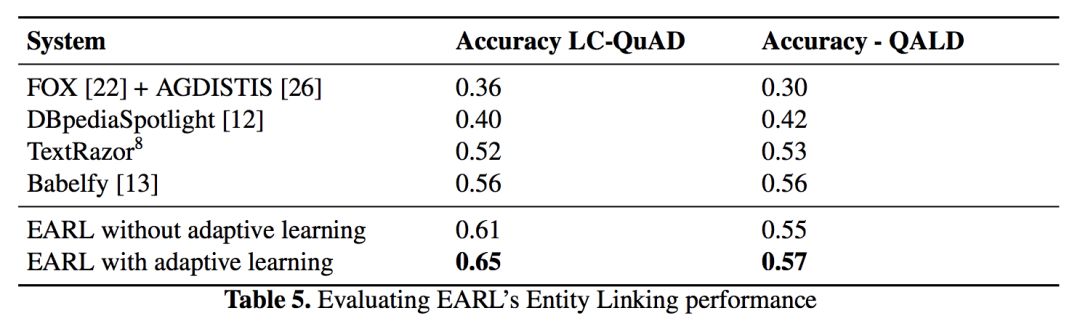
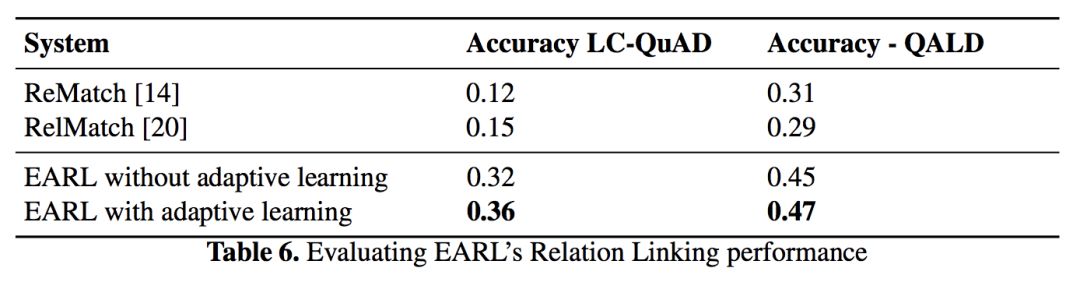
实验结果如下表所示,和对比方法相比,EARL 在 MRR 值上有较大提升。
实体链接结果:
关系链接结果:


■ 解读 | 谭亦鸣,东南大学博士,研究方向为知识图谱问答、自然语言处理
论文动机
近年来,随着多语言知识图谱嵌入(Multilingual KG Embedding)的研究,实体的潜在语义表示以及跨语言知识推理等任务均取得一定成效,因此也推动了许多知识驱动的跨语言工作。然而,受限于各语言知识图谱之间较低的实体对齐(Entity Alignment)程度,跨语言推理的准确性往往不够令人满意。
考虑到多语言知识图谱中具有对实体的文字性描述,文章提出一种基于嵌入(Embedding)的策略:通过利用图谱中实体的文字描述,对仅包含弱对齐(KG 中的 inter-language links,ILLs)的多语图谱做半监督的跨语言知识推理。
为了有效利用图谱知识以及实体的文字描述,文章提出通过协同训练(Co-train)两个模块从而构建模型 KDCoE:多语言知识嵌入模块和多语言实体描述嵌入模块。
论文贡献
文章贡献如下:
1. 提出了一种半监督学习方法 KDCoE,协同训练了多语知识图谱嵌入和多语实体描述嵌入用于跨语言知识对齐;
2. 证明 KDCoE 在 Zero-shot 实体对齐以及跨语言知识图谱补全(Cross-lingual KG Completion)任务上的有效性;
论文方法
多语言知识图谱嵌入(KGEM)
由知识模型(Knowledge Model)和对齐模型(Alignment Model)两个部分构成,分别从不同角度学习结构化知识。
知识模型:用于保留各语言知识嵌入空间中的实体和关系。文章采用了传统的 TransE 方法构建知识模型,并认为这种方法有利于在跨语言任务重中保持实体表示的统一性,且不会受到不同关系上下文带来的影响。其对应的目标损失函数如下:
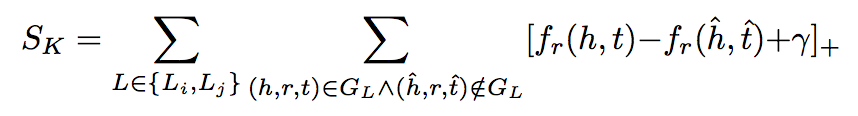
其中,L 表示某种语言,(Li,Lj) 表示一组语言对,GL 表示语言 L 对应的知识图谱,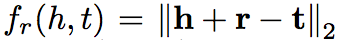
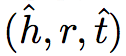
对齐模型:用于在不同语言的嵌入空间中获取跨语言关联。为了将不同语言间的知识关联起来,文章参照 MTransE 中的线性转换策略,其目标函数如下:
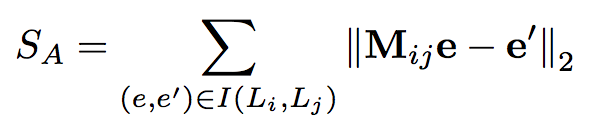
其中 (e, e') 是一组已知的对齐实体,当知识嵌入向量的维度为 k1 时,Mij 是一个
KGEM 的目标函数:
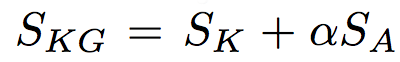
其中,α 是一个正超参数。
多语言实体描述嵌入(DEM)
DEM 过程包含两个部分:编码和跨语言嵌入。
编码:文章使用 Attentive Gated Recurrent Unit encoder, AGRU 对多语言实体描述进行编码,可以理解为带有 self-attention 的 GRU 循环网络编码器。
文章希望利用 self-attention 机制使得编码器能够凸显实体描述句子中的关键信息,AGRU 中的 self-attention 可以定义为以下公式:
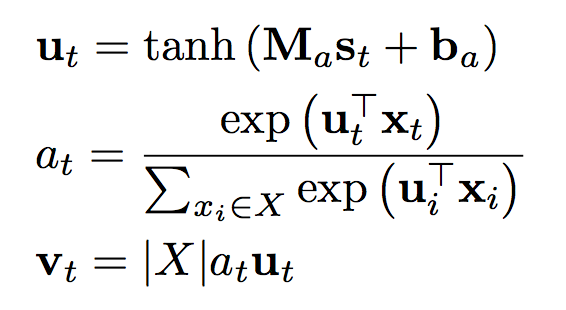
其中,ut 是由 GRU 中 st 产生的隐藏表示,attention 权值 at 则是由一个 softmax 函数计算得到,反映的是单词 xt 对于序列 X 的重要性,而后依据此权重与隐藏表示可以得到 self-attention 的输出 vt,|X|(输入序列的长度)用于防止 vt 失去原有的规模。
在这个部分,作者也尝试了其他的编码框架,包括单层网络,CNN,ALSTM 等等,但 AGRU 取得了最好的性能。
跨语言嵌入部分:为了更好的反映出多语言实体描述的词级别语义信息,文章使用跨语言词嵌入方法用于衡量和找出不同语言间的相似词汇。大致流程可描述如下:
首先,使用跨语言平行语料 Europarl V7 以及 Wikipedia 中的单语语料,对 cross-lingualBilbowa [Gouws et al., 2015] word embeddings 进行预训练。而后使用上述 embeddings 将实体描述文本转换为向量序列,再输入进编码器中。
DEM 学习目标:文章建立的编码器由两个堆叠的 AGRU 层构成,用于建模两种语言的实体描述。该编码器将实体描述序列作为输入,而后由第二层输出生成的 embedding。而后,文章引入了一个 affine 层,将上述各种语言的 embedding 结果投影到一个通用空间中,其投影过程由以下公式描述:
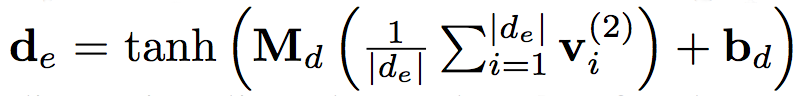
DEM 的目标是最大化各个实体描述 embedding 与对应的其他语言版本之间的 log 相似度,故可以将目标函数描述如下:
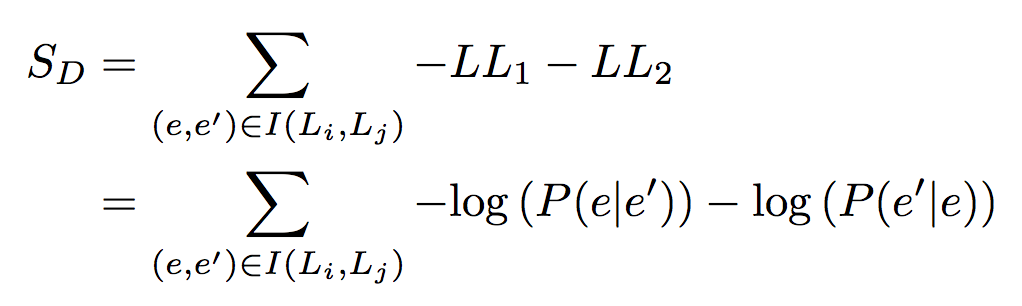
迭代Co-training的KDCoE模型
文章利用 KG 中存在的少量 ILLs 通过迭代的协同过程训练 KGEM 和 DEM 两个模块,过程大致描述如下:
每次迭代中,各模块都进行一系列“训练-生成”的过程:
1)首先利用已有的 ILLs 对模型进行训练;2)之后利用训练得到的模型从 KG 中预测得到以前未出现过的新 ILLs;3)而后将这些结果整合到已有 ILLs 中,作为下一轮迭代的训练数据;4)判断是否满足终止条件:本轮迭代中各模块不再生成新的 ILLs。
其算法细节描述如下图:

实验
实验相关细节
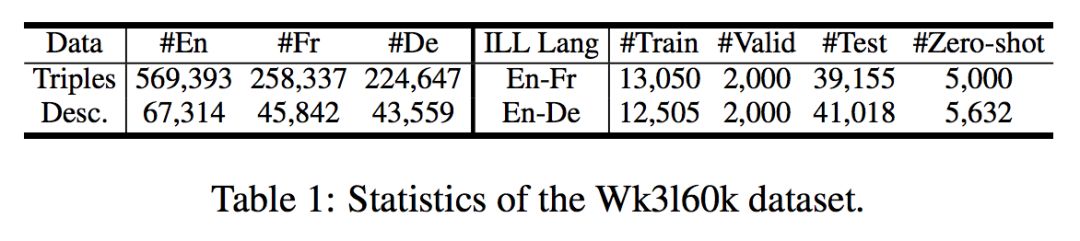
实验数据说明:文章实验数据来自 DBPedia 中抽取的子集 WK3160k,由英法德三语构成,其中每种语言数据中包含了 54k-65k 规模的实体。具体统计信息如下表:
文章分别在跨语言实体对齐,Zero-shot 对齐以及跨语言知识图谱补全等三个任务上进行实验。
其中,跨语言实体对齐选用的基线系统包括:LM,CCA,OT,ITransE 以及 MTransE 的三种策略;Zero-shot 对齐的基线系统为:Single-layer 网络,CNN,GRU,AGRU 的两种策略;知识图谱补全的基线系统为 TransE。
实验结果
跨语言实体对齐:如下图所示,文章设置了三组评价指标,分别为:accuracy Hit@1;proportion of ranks no larger than 10 Hit@10;mean reciprocal rank MRR。
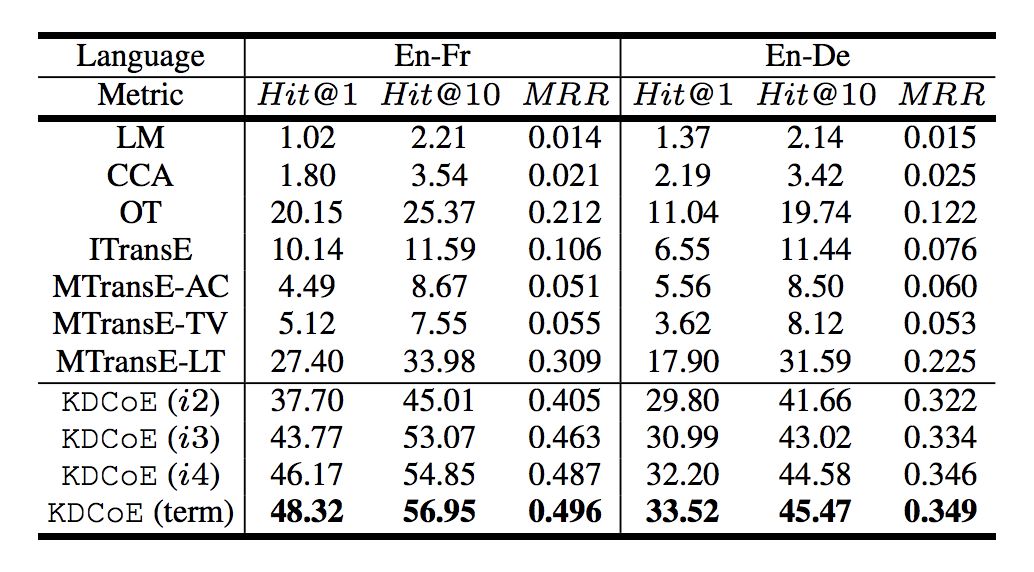
从结果上看,KDCoE 模型的性能远优于其他系统,且随着 Co-train 的迭代次数增加,系统的性能也都有较为明显的提升。
Zero-shot 对齐:Zero-shot 采用的评价指标与跨语言实体对齐相同,下图反映了 KDCoE 在 Zero-shot 对齐任务中的实验结果。
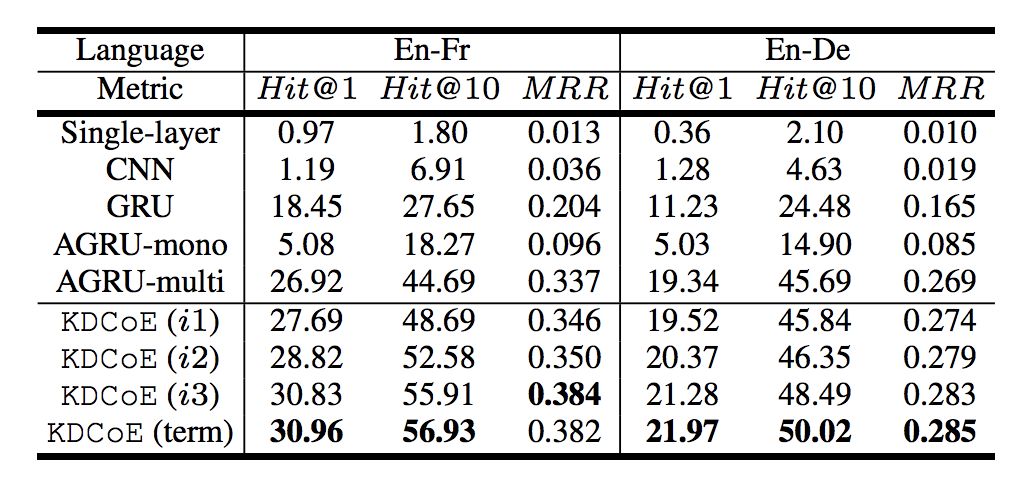
从实验结果上看,KDCoE 的效果依然是随着迭代次数的增加而上升,但从第一次迭代的结果可以发现,其优势的来源基础是 AGRU。这也反映出 AGRU 在编码上相对其他网络模型体现出了更优性能。
跨语言知识补全:在跨语言知识补全任务中,文章采用 proportion of ranks no larger than 10 Hit@10;mean reciprocal rank MRR 等两个评价指标。
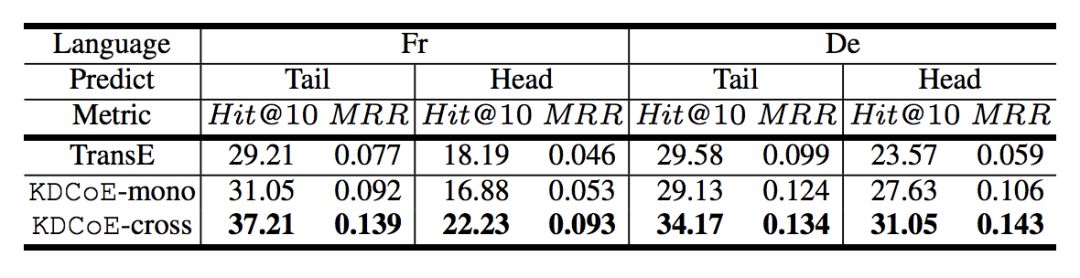
根据 KDCoE-mono 的表现,可以推断,该模型成功继承了 TranE 保持结构化知识中实体和关系的稳定性。而 KDCoE-corss 则反映引入跨语言信息确实对知识补全的效果起到了明显提升。
总结
本文提出了一种基于 embedding 技术的跨语言知识对齐方法,通过引入 Co-train 机制,将 KG 中的关系上下文与实体描述信息有效的利用起来,以现有 KG 中的小规模 ILLs 为基础建立半监督机制,在跨语言实体对齐,知识补全上都起到了明显的效果。


■ 论文解读 | 花云程,东南大学博士,研究方向为知识图谱问答、自然语言处理
论文动机
在以前的工作中,对话生成的信息源是文本与对话记录。但是这样一来,如果遇到 OOV 的词,模型往往难以生成合适的、有信息量的回复,而会产生一些低质的、模棱两可的回复。
为了解决这个问题,有一些利用常识知识图谱生成对话的模型被陆续提出。当使用常识性知识图谱时,由于具备背景知识,模型更加可能理解用户的输入,这样就能生成更加合适的回复。但是,这些结合了文本、对话记录、常识知识图谱的方法,往往只使用了单一三元组,而忽略了一个子图的整体语义,会导致得到的信息不够丰富。
为了解决这些问题,文章提出了一种基于常识知识图谱的对话模型(commonsense knowledge aware conversational model,CCM)来理解对话,并且产生信息丰富且合适的回复。
本文提出的方法,利用了大规模的常识性知识图谱。首先是理解用户请求,找到可能相关的知识图谱子图;再利用静态图注意力(static graph attention)机制,结合子图来理解用户请求;最后使用动态图注意力(dynamic graph attention)机制来读取子图,并产生合适的回复。
通过这样的方法,本文提出的模型可以生成合适的、有丰富信息的对话,提高对话系统的质量。
论文贡献
本文贡献如下:
1. 首次尝试使用大规模常识性知识图谱来处理对话生成问题;
2. 对知识图谱子图,提出了静态/动态图注意力机制来吸收常识知识,利于理解用户请求与生成对话。
论文方法
Encoder-Decoder模型
经典的 Encoder-Decoder 模型是基于 Seq2Seq 的。Encoder 模型将用户输入(user post)X 用隐状态 H 来表示,而 Decoder 模型使用另一个 GRU 来循环生成每一个阶段的隐状态。
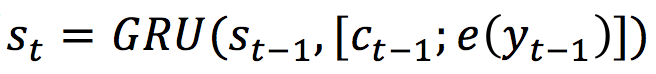
其中 Ct 是上下文向量,通过注意力机制按步生成。最终,Decoder 模型根据概率分布生成了输出状态,并产生每一步的输出 token。
模型框架
如下图 1 所示为本文提出的 CCM 模型框架。
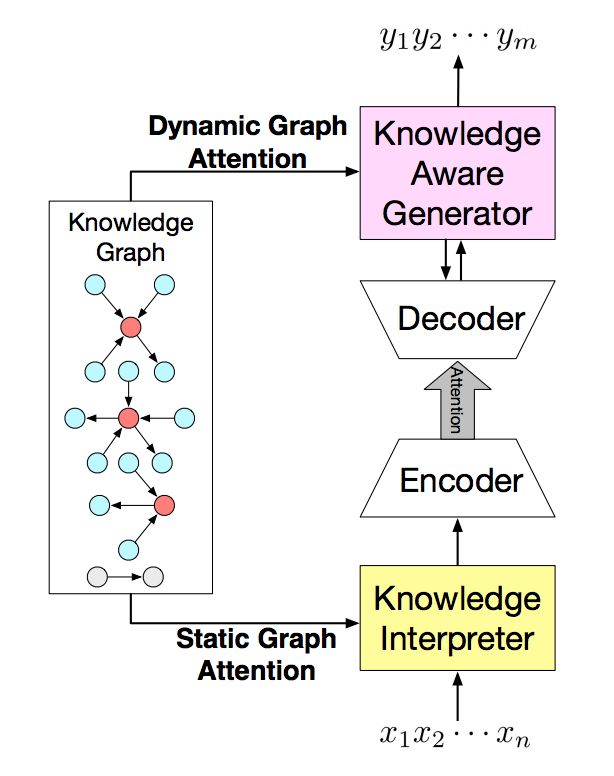
▲ 图1. CCM模型框架
如图 1 所示,基于 n 个词输入,会输出 n 个词作为回复,模型的目的就是预估这么一个概率分布:
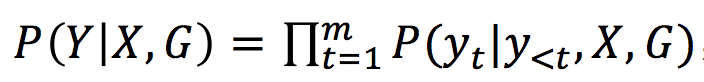
也就是将图信息 G 加入到概率分布的计算中。
在信息读取时,根据每个输入的词 x,找到常识知识图谱中对应的子图(若没有对应的子图,则会生成一个特殊的图 Not_A_Fact),每个子图又包含若干三元组。在信息读取时,词向量与这个词对应的子图向量拼接,而子图向量是由采用静态图注意力机制生成的。
当生成回复时,采用动态图注意力机制来引用图信息,即读取每个字对应的子图和子图中的实体,并且在生成当前回复时,通过概率计算应该是生成通用词还是这个子图中的相关实体。
知识编译模块
如图 2 所示,为如何利用图信息编译 post 的示意图。
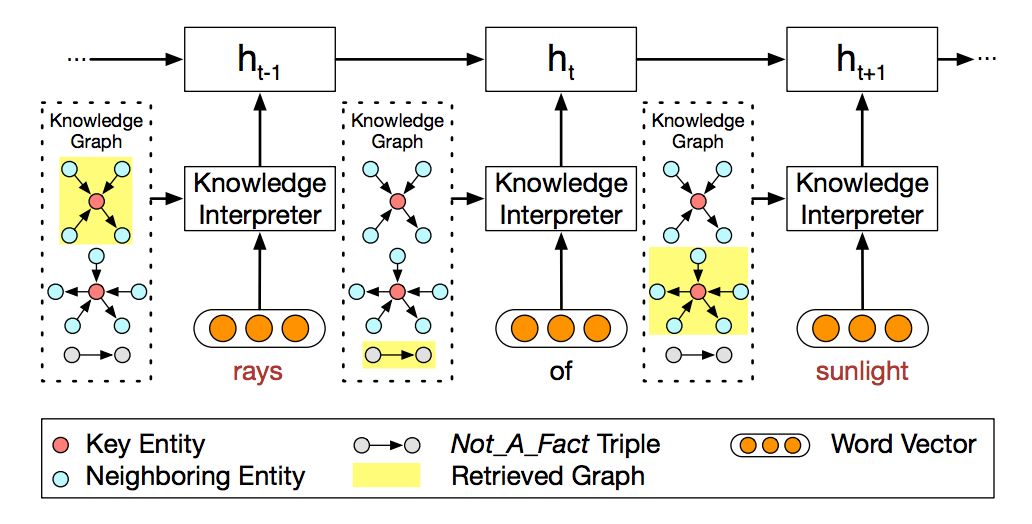
▲ 图2. 知识编译模块
如图所示,当编译到“rays”时,会把这个词在知识图谱中相关的子图得到(图 2 最上的黄色高亮部分),并生成子图的向量。每一个子图都包含了 key entity(即这里的 rays),以及这个“rays”的邻居实体和相连关系。
对于词“of”,由于无法找到对应的子图,所以就采用特殊子图 Not_A_Fact 来编译。之后,采用基于静态注意力机制,CCM 会将子图映射为向量 gi,然后把词向量 w(x_t) 和 gi 拼接为 e(xt)=[w(xt); gi],并将这个 e(xt) 替换传统 encoder-decoder 中的 e(xt) 进行 GRU 计算。
对于静态图注意力机制,CCM 是将子图中所有的三元组都考虑进来,而不是只计算一个三元组,这也是该模型的一个创新点。当得到子图时,且这个子图由三元组 K 表示, K(gi)={k1,k2,…,k(NG)}。在计算时,就是将当前三元组的头实体与尾实体向量通过矩阵变换后相加,再经过正切激活函数后,与经过矩阵变换的关系进行点积,得到一个值。
而将这个词向量与所有三元组进行计算后,再经过 softmax,就得到了一个权重。把子图中所有头实体、尾实体按对相加,再基于权重计算加权和,就得到了图向量 gi。
知识生成模块
如下图 3 所示,为如何利用图信息生成回复的示意图。
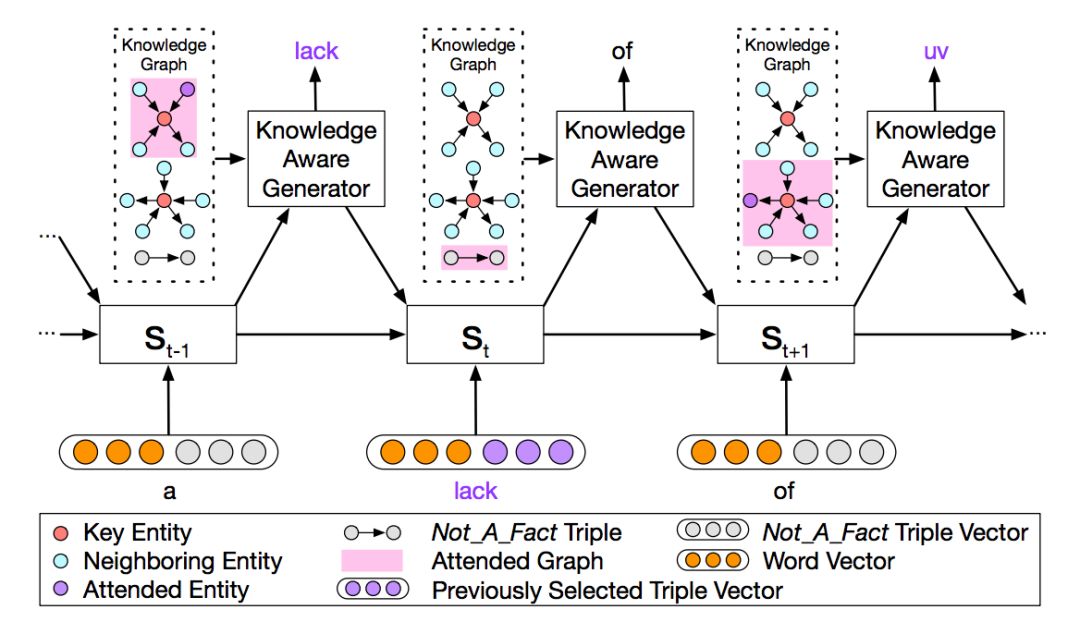
▲ 图3. 知识生成模块
在生成时,不同于静态图注意力机制,模型会读取所有相关的子图,而不是当前词对应的子图,而在读取时,读取注意力最大的就是图中粉色高亮的部分。生成时,会根据计算结果,来选择是生成通用字(generic word)还是子图中的实体。
在进行 decoder 时,公式改为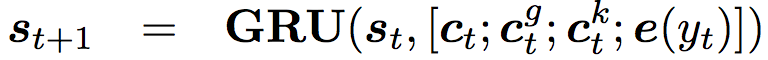
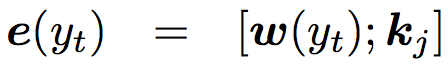
在这里,可以看到 GRU 的输入多了两个向量(来自于表示图信息的向量)和
(表示三元组信息的向量)。
对于动态图注意力机制,是一种层次型的计算,即 CCM 先根据 post 相关的所有知识图谱子图来计算一个向量,再根据子图中的三元组再计算一个向量
。对于上个阶段的隐状态输出 st,最终的
是图向量 gi 的加权和。
然后,对于每个子图中的三元组 kj,CCM 又计算了一次注意力,最终的是 kj 的加权和,权重为对应图 gi 的注意力权重与三元组 kj 的注意力权重之积。
最终,每一个 step 的输出,是根据 st 来选择一个通用词或者子图中的实体。
损失函数
损失函数为预期输出与实际输出的交叉熵,除此之外,为了监控选择通用词还是实体的概率,又增加了一个交叉熵。公式如下:
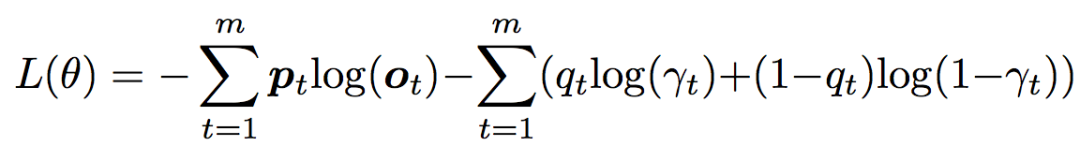
其中 γt 就是选择的概率,而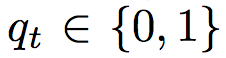
实验
实验相关细节
常识性知识图谱选用了 ConceptNet,对话数据集选用了 reddit 的一千万条数据集,如果一个 post-response 不能以一个三元组表示(一个实体出现于 post,另一个出现于 response),就将这个数据去除。然后对剩下的对话数据,根据 post 的词的出现频数,分为四类。
基线系统选择了如下三个:只从对话数据中生成 response 的 Seq2seq 模型、存储了以 TransE 形式表示知识图谱的 MemNet 模型、从三元组中 copy 一个词或生成通用词的 CopyNet。
在选用 metric 的时候,采用了刻画回复内容是否语法正确且贴近主题的 perplexity,以及有多少个知识图谱实体被生成的 entity score。
实验结果
如下图 4 所示,为根据 perplexity 和 entity score 进行的性能比较,可见 CCM 的 perplexity 最低,且选取 entity 的数量最多。并且,在低频词时,选用的 entity 更多。这表示在训练时比较罕见的词(实体)会需要更多的背景知识来生成答复。

▲ 图4. CCM与基线系统对比结果
另外,作者还采用众包的方式,来人为审核 response 的质量,并采用了两种度量值 appropriateness(内容是否语法正确,是否与主题相关,是否有逻辑)与 informativeness(内容是否提供了 post 之外的新信息)。如下图 5 所示,为基于众包的性能比较结果。

▲ 图5. CCM与基线系统基于众包的对比结果
从图 5 中可见,CCM 对于三个基线系统来说,都有将近 60% 的回复是更优的。并且,在 OOV 的数据集上,CCM 比 seq2seq 高出很多,这是由于 CCM 对于这些低频词或未登录词,可以用知识图谱去补全,而 seq2seq 没有这样的知识来源。
在 case study 中,当在 post 中遇到未登录词“breakable”时,seq2seq 和 MemNet 都只能输出一些通用的、模棱两可的、毫无信息量的回复。CopyNet 能够利用知识图谱输出一些东西,但是并不合适。而 CCM 却可以输出一个合理的回复。
总结
本文提出了一种结合知识图谱信息的 encoder-decoder 方法,引入静态/动态图注意力机制有效地改善了对话系统中 response 的质量。通过自动的和基于众包的形式进行性能对比,CCM 模型都是优于基线系统的。


■ 论文解读 | 谭亦鸣,东南大学博士,研究方向为知识图谱问答、自然语言处理
知识库问答研究旨在利用结构化事实回答自然语言问题,在网络中,简单问题占据了相当大的比例。本文提出在完成模式抽取和实体链接后,构建一个模式修正机制,从而缓解错误积累问题。
为了学习对“subject-predicate”(问题的实体-谓词)候选集的排序,本文提出将关系检测机制用于强化联合事实选择,多级别编码和多维信息将被用于强化整个模型过程。实验结果表明,本方法展现出非常强大的性能。
研究背景
简单知识库问答,指的是问答中仅需用到知识库中的一个事实即可给出答案的过程。其流程和可以描述为:从自然语言问句中识别实体,谓词,并与知识库中的内容构成完整三元组的过程。
简单知识库问答目前存在的主要挑战包括:
1. 同一单词(词语)在不同句子中的意义不同;
2. 不同的自然语言表达方式具有相同的含义;
3. 如何利用大规模知识库中的大量事实信息。
论文模型
在简单问答中,首先要做的是实体链接,常规的实体链接方法包括 n-gram 匹配,序列标注等等,但是这两个方法都有可能导致错误积累,从而无法找到准确的“实体-谓词”对。
考虑到这些问题,本文首先使用模式抽取和实体链接,将可能的实体描述和问题模式提取出来,而后减少知识库中的候选实体数量。
在模式抽取过程中,作者发现由于模型性能问题,抽取结果中存在一定比例的较差模式。为了应对这个情况,文章提出添加模式修正机制以提升模式抽取的质量。
下一步工作就是找出最可能生成问题答案的“实体-谓词”对,对于这个问题,前人的工作中主要考虑使用问题模式与候选实体信息来选择合适的谓词。本文则引入了关系检测机制进行改进,其效果体现在限定了知识库中问题表达对应的谓词,从而引导候选实体的重排序。
当问题所问实体在知识库中存在大量不同类型的重名实体时,先做关系推理或者实体链接都有可能引发无召回问题。对此,本文的策略是采用联合事实筛选,通过利用实体的名称信息和类别信息从不同角度描述实体。
在确定谓词方面,作者采用唯一关系名与分散词信息作为限定条件。

▲ 本文问答模型的示意图
同时为了准确保留原始问句的内容,本文将字符级别与词级别的编码结果进行合并,用于表达原始问句。
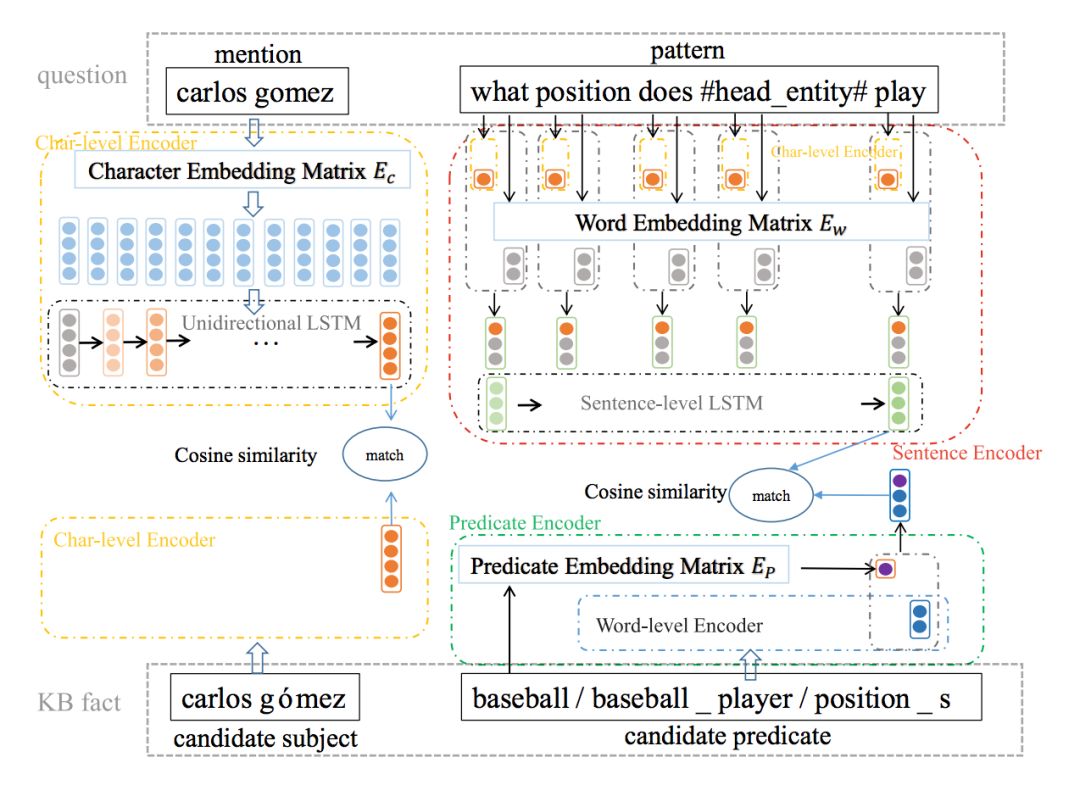
▲ 本文编码策略的示意图
实验
本文实验使用的数据集为 SimpleQuestions benchmark 提供的问答数据集,其中的每个问题都可以由 freebase 中的一个三元组回答。
数据集分为三个部分:训练集规模为75910,验证集为10845,测试集为21687。
知识库则是从 freebase 中抽取的子集 FB2M (2,150,604entities, 6,701 predicates, 14,180,937 atomic fact triples,FB5M (4,904,397entities, 7,523 predicates, 22,441,880 atomic fact triples)。
实验评价指标为准确率,仅当问题对应的事实与模型得到的实体和谓词两者都匹配时,才算准确匹配。
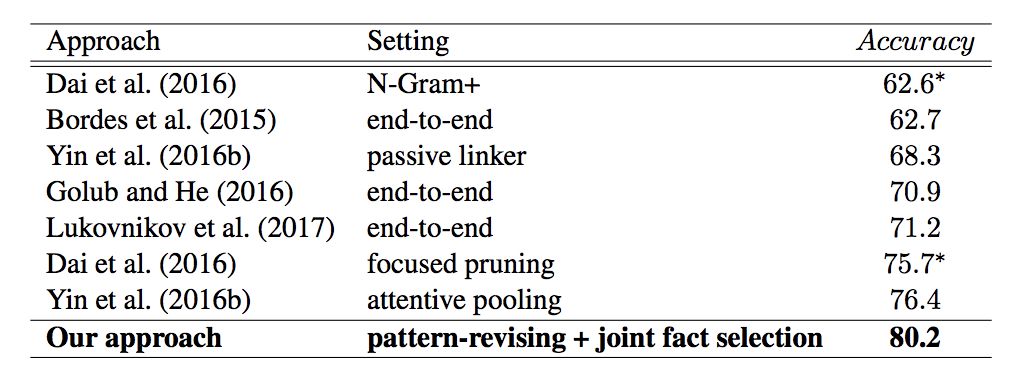
从实验结果上看,本文方法相对过去的工作,取得了非常明显的提升。

点击以下标题查看更多相关文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐



