「中文电子病历命名实体识别」的研究与进展

海量电子病历(Electronic Medical Record,EMR)数据是支撑医疗智能化研究的重要原料,其结构化的 不完全性给有用信息抽取带来了较大困难. 自命名实体识别(Named Entity Recognition,NER)成为对电子病历进行自 动化信息抽取的核心技术后,近年来受到越来越多的关注 . 鉴于中文电子病历(Chinese Electronic Medical Record, CEMR)独特的文本特征给该研究带来了诸多挑战,本文综述了中文电子病历命名实体识别的概念、相关理论模型以 及制约中文电子病历命名实体识别准确率和识别效率的主要原因,详细分析了中文电子病历命名实体识别近年来的 主要研究进展. 通过对主流模型的实验验证与深入分析,指出了现有模型的不足与改进方向。
https://www.ejournal.org.cn/CN/10.12263/DZXB.20220485
1. 引言
电子病历(Electronic Medical Record,EMR)是指医 务人员在医疗活动过程中,使用信息系统生成的文字、 符号、图表、图形、数字、影像等数字化信息,并能实现 存储、管理、传输和重现的医疗记录,是病历的一种记 录形式,包括门(急)诊病历和住院病历[1] ,是临床辅助 决策[2] 、专病科研数据提取[3] 、医疗知识图谱构建[4] 和 智能预问诊[5] 等应用的重要数据支撑. 然而,电子病历 通常由自然语言书写而成,大多为医疗信息系统无法 直接利用的半结构化甚至无结构化数据[6] ,如何利用自 然语言处理技术对电子病历文本进行智能分析和信息 抽取,将其组织为结构化的内容,是当前研究的重点[4] .
如图1所示,命名实体识别是电子病历分析利用过 程中介于数据预处理与数据应用之间的关键技术 . 基 于对电子病历结构化和标准化的目的,针对电子病历 的命名实体识别(Named Entity Recognition,NER)是从海量电子病历数据中识别出有独立或特定意义的医疗 信息实体[7] ,如目前公认的疾病和诊断、检查、检验、手 术、药物与解剖部位在内的六类实体[8] ,对其进行序列 标注和标准化,为进一步进行信息抽取和文本挖掘做 准备,该技术具有重要的应用前景 . 截至目前,电子病 历的命名实体识别方法主要经历了基于词典、规则和 机器学习的三个发展阶段 . 相较基于词典的方法兼容 性较差和基于规则的方法可迁移性较差,基于机器学 习的方法在电子病历命名实体识别上表现出较好的实 用性和可移植性. 特别在深度学习技术提出后,面向电 子病历命名实体识别的深度学习模型井喷式增长,各 个模型不断优化命名实体识别的准确性.

国际上,早在1996年由NCCOSC(前NOSC)海军研 究与发展小组(NRaD)的 Beth Sundheim 组织的 MUC-6 会议[10] 提出命名实体识别概念就开始推动相关方面研 究,2002 年自然语言处理领域影响力最大的国际学术 组织 ACL 下属的 SIGNLL 主办的计算自然语言学会议 (Conference on Natural Language Learning,CoNLL)①将 跨国语言的命名实体识别作为共享任务,2010 年美国 国立卫生研究院(NIH)赞助的国家生物医学计算项目 Informatics for Integrating Biology and the Bedside(I2B2) 测评任务给出电子病历命名实体识别的具体要求,聚 焦推进英文电子病历命名实体识别方面的研究. 除应用人工规则和建立词典的识别方法之外,早 期主要的识别方法的训练模型几乎都基于监督学习, 包括采用贝叶斯模型、支持向量机[11] 、条件随机场[12] 等. 后续的研究中发现,半监督学习方法有别于有监督 学习,只需要少量语料标注,因此也成为一段时间的研 究热点,包括采用半监督协同训练[13] 和多任务学习的 半监督学习方法[14] 等.
随着深度学习技术的发展,鉴于其在命名实体识 别 上 表 现 优 异 ,迅 速 成 为 了 研 究 热 点 . 从 最 初 以 LSTM[15] 为代表的单向RNN网络到以BiLSTM[16] 为代表 的双向RNN网络,从基本的CNN网络[17] 到其变种迭代 膨胀卷积 IDCNN[18],从类似 CRF 的单一模型到诸如 BiLSTM+CRF[19] 的多模型融合……人工参与工作量不 断减少,识别精度也不断提高. 特别在将预训练模型和迁移学习方法引入后,模型对语义的理解更进一步,具体是通过自监督学习从 大规模语料中获得与后续任务无关的预训练模型,并 迁移到实体识别这样的下游语言任务上 . 比如从 Word2vec[20]到 GLOVE[21],再 到 BiLSTM,BERT[22],以 RoBERTa[23] 为代表的 BERTology 系列……这些预训练 模型依次出现,在优化升级过程中不断提高了命名实 体识别的精度.
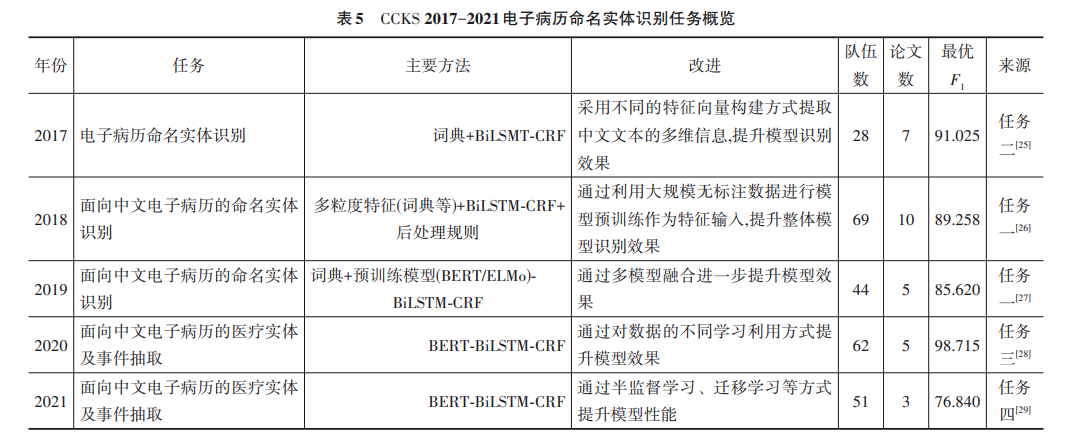
而国内由于医疗信息化建设起步较晚,电子病历 命名实体识别研究相对于英文语料环境落后 . 最早杨 锦锋等人[7] 在2014年对国内外电子病历命名实体识别 工作做了详尽总结,在 2016 年制定了命名实体的详细 标注规范[24] ,此后国内在该领域的研究逐步展开:比如 从2017年至今每年举办的全国知识图谱与语义计算大 会[25~29]均将中文电子病历命名实体识别作为测评任 务,迅速推动了该领域的研究进步. 其中,面向中文电子病历(Chinese Electronic Medi⁃ cal Record,CEMR)命名实体识别的主要技术路线和国 外大致相同,主要在待识别文本的语言特征上两者有 所差异,如英文词语边界明显、词语前后缀较易划分、 词法句法结构相对固定,而中文语句没有明显的分词、 偏旁部首等部分不能直接划分、词法句法结构复杂. 特 别针对医疗领域,中文医学专业词汇多、医学命名实体 长、一词多义、多词一义以及词汇缩写无统一规范等问 题尚未获得有效解决,大多数研究者基于国外提出的 模型技术,融合中文医疗文本特征,在不断摸索提高中 文电子病历命名实体识别准确性的有效方法,具体研 究在 CCKS 历年收录的文章(详见第 4 节)中进行了 说明.
虽然面向中文电子病历的命名实体识别目标明 确,相关技术也取得了长足发展,但有别于英文或者中 文通用领域的命名实体识别,中文电子病历独特的文 本数据特征也给该研究带来了诸多挑战,具体包括以 下几点。
(1)中文电子病历文本的非规范性和专业性. 该特 征带来了三方面挑战:一是中文电子病历文本中存在 大量非规范的语法、拼写错误和不完整的句子结构,如 将“右心室”错误地写为“有心室”;二是中文电子病历 文本包含大量专业术语、受控词汇、缩略语、符号等,如 药物“Aspirin”被译作“阿司匹林”或者“阿斯匹林”其中 哪一种并不确定;三是中文电子病历自身特殊的文法 和句法. 这些挑战均给命名实体识别造成困难.
(2)中文医疗实体的独特性. 中文电子病历文本数 据中不仅有常规的实体,还有很多拥有复杂结构的实 体,主要有两种情况:一是嵌套类实体存在自身复杂的 结构,如“呼吸中枢受累”中存在二级实体嵌套:“呼吸中枢受累”为症状而“呼吸中枢”为身体部位;二是跳跃 类实体在文本中的位置不连续,如“尿道、膀胱、肾绞 痛”中存在三个非连续实体“尿道痛”、“膀胱痛”和“肾 绞痛”.
(3)中文电子病历标注语料的稀缺性. 造成这一现 象的原因主要是考虑到患者隐私和保密性要求,电子 病历数据难以公开;此外可用于电子病历命名实体识 别的数据集标注成本高,需要医疗专家的指导和参与, 费时费力. 鉴于此,本文针对国内外在中文电子病历医疗命 名实体识别上的工作进行了详细分析;综述了近年来 中文电子病历命名实体识别模型上的研究进展;同时 也对当前电子病历命名实体识别的效果进行了对比检 验,进而深入分析了各模型的优势与不足;在此基础上 对该领域的后续研究方向进行了展望.
2. 中文电子病历命名实体识别
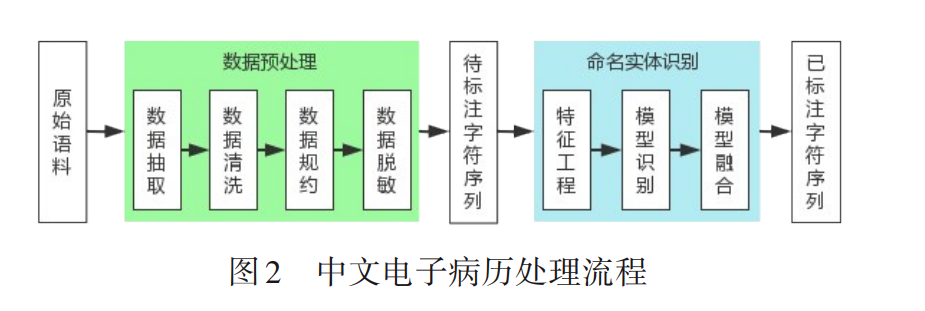
中文电子病历命名实体识别是针对给定的一组电 子病历纯文本文档,通过自然语言处理技术,识别并抽 取出与医学临床相关的实体提及,并将它们归类到预 定义类别[8] . 如全国知识图谱与语义计算大会(CCKS) 于 2021 年发布的中文电子病历命名实体识别评测任 务[8] 中定义了 6 类实体,包括疾病和诊断、检查、检验、 手术、药物和解剖部位. 其一般流程包括先将原始电子 病历语料进行数据抽取、清洗、规约与脱敏四步预处 理,获得待标记的电子病历字符序列. 之后将其输入命 名实体识别模型中进行计算,获得标注好的电子病历 字符序列作为最终结果. 具体到命名实体识别模型,通 常由特征工程、识别方法所对应的模型识别和模型融 合三部分构成,如图2所示.
3 中文电子病历命名实体识别模型
电子病历命名实体识别模型的研究,主要有基于 词典、规则和机器学习三种方法,各方法的优缺点如表 2所示.

近年来,随着机器学习技术的发展,基于深度学习 的命名实体识别也获得较大关注,并取得了很好的识 别效果 . 相较统计机器学习需要依赖研究者手动设计 特征工程,即用一系列工程化的方式从原始语料中筛 选出更好的文本数据特征,以提升模型的训练效果. 深 度学习是端到端的,可以自动找到更深入、更抽象的特 征 . 深度学习的关键在于如何在词向量的基础上设计 并利用各种神经网络模型进行医疗命名实体识别 . 普 遍采用的模型如图5所示。

4. 中文电子病历命名实体识别效果
为实际考察目前中文电子病历命名实体识别前沿 方法及其效果,为下一步研究提供方向 . 本节首先对 CCKS 近年来该领域相关论文中提及的方法进行纵横 比较,分析不同方法的特点和创新之处;再通过对这些 方法中主流模型的深入实验分析,为后续研究提供切 实可行、有借鉴意义的思路.
5 结论
海量电子病历数据是支撑医疗智能化研究的重要 原料,然而电子病历文本数据的半结构化甚至无结构 化特点,造成后续对其分析利用的极大困难. 虽然近年 来基于深度学习的命名实体识别技术已经发展到可以 有效完成电子病历的命名实体识别任务,但由于中文 电子病历所具有包括病历文本的非规范性和专业性、 医疗实体的独特性和标注语料的稀缺性在内的独特文 本数据特征,该研究目前仍存在诸多挑战. 本文对中文电子病历命名实体识别的研究与进展 进行了综述,系统梳理了中文电子病历命名实体识别 的相关理论;从技术发展角度详细叙述了中文电子病 历命名实体识别方法的变革历程;并对中文电子病历命名实体识别效果做了实验验证与深入分析,指出了 现有模型的不足与改进方向;鉴于国内近年来与中文 信息学处理相关的测评会议 CCKS 持续关注中文电子 病历命名实体识别,本文特别对CCKS在该领域五年来 的全部代表性测评论文做了纵横对比分析,并通过在 主流模型 BBC 上的深入实验与研究,为后续该领域的 继续推进寻求了思路. 虽然围绕电子病历文本数据处理的医疗命名实体 识别并非新兴研究方向,与其他通用领域文本数据上 的命名实体识别技术差别不大,但中文电子病历自身 所具备的专业性和隐私性等特点,让该领域到目前为 止仍存在极大的研究空间,主要体现在训练语料获取 难度大、现有识别方法仍存在可改进之处等. 基于本文 调研,我们认为以下几个方面是未来中文电子病历命 名实体识别研究中值得重点关注的方向:
(1)针对特殊实体类型研究识别率的提升方法。前文实验结果表明,“实验室检验”类实体的 F1明显较 低. 潜在原因有二:一是该类实体多有中英文混杂的情 况,从而导致模型不能很好地判断实体边界;二是难以 识别出长度为一的短实体以及不能完整识别出较长实 体,该类实体还明显存在实体嵌套的现象,导致严格匹 配指标F1值较低. 针对不同类型实体,特别是针对中文 电子病历中特殊类型的实体,包括嵌套类实体和非连 续类实体,鉴于其自身结构和语义的复杂性至今仍是 制约中文电子病历实体识别效果的要因,有必要对以 往模型的实验结果做进一步分析,统计特殊类实体的 识别情况,并对特定实体类型所存在的问题进行具体 优化.
(2)寻求性能表现更佳的模型结构:综合调研结 果,我们发现基于词典和规则的实体识别方法均因自 身缺陷而不再被独立研究,多结合到基于机器学习的 实体识别方法中,作为提升模型性能的两种手段;而基 于机器学习的实体识别方法目前仅BBC模型被广为采 纳 . 可以预见,在更优的模型架构提出以前,一定阶段 内BBC模型将不被淘汰. 因此,下一步一方面可以考虑 采用 4. 2. 6 小节提出的 12 种方法改良 BBC 模型,另一 方面也可以考虑借鉴图像识别等其他领域思路,在中 文电子病历命名实体识别情景下寻找性能更佳的模型 结构.
(3)采用多元的模型学习方式:深度学习模型大多为数据驱动,足够且高质量的数据才能让模型学到一 定的知识,从而达到相较理想的模型效果. 而短时间内 中文电子病历的命名实体识别仍无法获得足量的数 据,这也是大部分研究者在模型识别效果提升上受到 制约的潜在原因 . 未来可以在模型上尝试采用不同的 学习方式解决这一问题,如主动学习[107] 、自学习[108] 、迁 移学习[109]、多任务学习[79]、元学习[110]和小样本学 习等.
(4)进一步提升模型训练和测试效率:经实际测 验,在一定参数设置下一个主流的中文电子病历命名 实体识别模型 BBC在 CPU 上训练时长超过 24小时,在 GPU上训练时间也长达3小时. 此外,并非可并行计算 模型结构中的各个部分都能采用 GPU 加速计算,如 BERT-LSTM-CRF 模型中,由于单个 LSTM 模型自身结 构无法并行,这一部分就无法使用 GPU 进行加速 . 因 此,在算力资源不紧张的情况下,采用分布式学习如联 邦学习[111] 等思路;在算力资源有限的情况下,寻求合 适的模型训练方案以提升效率,在实际应用场景下都 十分必要.
(5)完善中文医疗领域语料库资源,构建开放高质 量数据集:虽然目前部分研究者如本节第(3)点所述:从小样本学习、领域迁移学习或者对医疗数据进行无 监督学习等方向进行了初步尝试并取得一定进展,如 高冰涛等人[41] 通过构建基于迁移学习的隐马尔可夫模 型 BioTrHMM 仅需要少量的目标领域标注数据即可在 医学命名实体上获得较好性能. 但在大数据浪潮下,建 立统一的标注标准和公共数据集;降低数据集标注的 人工成本和时间成本;利用自动化方式获得较为完善 而高质量的中文医疗领域语料库仍然是较为紧迫的研 究问题,需要政府、医院和相关研究者共同出力.
(6)与其他研究方向做联合研究:自 CCKS2019 以 来,中文电子病历命名实体识别任务就开始和其他任 务做联合测评 . 鉴于中文电子病历命名实体识别最终 为电子病历文本数据结构化和标准化、医疗知识图谱 的构建等服务,联合研究既降低了研究成本、减少了分 开研究潜在的信息丢失和误差传递现象,同时还能通 过研究方向之间的关联性,为彼此提供更丰富的扩展 信息,进一步提升方法的整体性能,目前也吸引了较多 研究者关注.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“EMRE” 就可以获取《「中文电子病历命名实体识别」的研究与进展》专知下载链接




