腾讯AI单挑王者荣耀职业玩家,“绝悟”技术细节首次披露!
新智元报道
新智元报道
来源:腾讯 AI Lab
【新智元导读】腾讯王者荣耀AI“绝悟”的论文终于发表了!“绝悟”制霸王者荣耀世界冠军杯、在2100多场和顶级业余玩家体验测试中胜率达到99.8%。腾讯AI Lab提出一种深度强化学习框架,并探索了一些算法层面的创新,对MOBA 1v1 游戏这样的多智能体竞争环境进行了大规模的高效探索。戳右边链接上 新智元小程序 了解更多!
围棋被攻克之后,多人在线战术竞技游戏(MOBA)已经成为测试检验前沿人工智能的动作决策和预测能力的重要平台。基于腾讯天美工作室开发的热门 MOBA 类手游《王者荣耀》,腾讯 AI Lab 正努力探索强化学习技术在复杂环境中的应用潜力。本文即是其中的一项成果,研究用深度强化学习来为智能体预测游戏动作的方法,论文已被AAAI-2020接收。
此技术支持了腾讯此前推出的策略协作型 AI 「绝悟」1v1版本,该版本曾在今年8月上海举办的国际数码互动娱乐展览会China Joy首次亮相,在2100多场和顶级业余玩家体验测试中胜率达到99.8%。
除了研究,腾讯AI Lab与王者荣耀还将联合推出“开悟”AI+游戏开放平台,打造产学研生态。王者荣耀会开放游戏数据、游戏核心集群(GameCore)和工具,腾讯AI Lab会开放强化学习、模仿学习的计算平台和算力,邀请高校与研究机构共同推进相关AI研究,并通过平台定期测评,让“开悟”成为展示多智能体决策研究实力的平台。目前“开悟”平台已启动高校内测,预计在2020年5月全面开放高校测试,并且在测试环境上,支持1v1,5v5等多种模式;2020年12月,我们计划举办第一届的AI在王者荣耀应用的水平测试。
以下是本次入选论文的详细解读:

解决复杂动作决策难题:创新的系统设计&算法设计
在竞争环境中学习具备复杂动作决策能力的智能体这一任务上,深度强化学习(DRL)已经得到了广泛的应用。在竞争环境中,很多已有的 DRL 研究都采用了两智能体游戏作为测试平台,即一个智能体对抗另一个智能体(1v1)。其中 Atari 游戏和棋盘游戏已经得到了广泛的研究,比如 2015 年 Mnih et al. 使用深度 Q 网络训练了一个在 Atari 游戏上媲美人类水平的智能体;2016 年 Silver et al. 通过将监督学习与自博弈整合进训练流程中而将智能体的围棋棋力提升到了足以击败职业棋手的水平;2017 年 Silver et al. 又更进一步将更通用的 DRL 方法应用到了国际象棋和日本将棋上。
本文研究的是一种复杂度更高一筹的MOBA 1v1 游戏。即时战略游戏(RTS)被视为 AI 研究的一个重大挑战。而MOBA 1v1 游戏就是一种需要高度复杂的动作决策的 RTS 游戏。相比于棋盘游戏和 Atari 系列等 1v1 游戏,MOBA的游戏环境要复杂得多,AI的动作预测与决策难度也因此显著提升。以 MOBA 手游《王者荣耀》中的 1v1 游戏为例,其状态和所涉动作的数量级分别可达10^600 和 10^18000,而围棋中相应的数字则为 10^170 和 10^360,参见下表1。
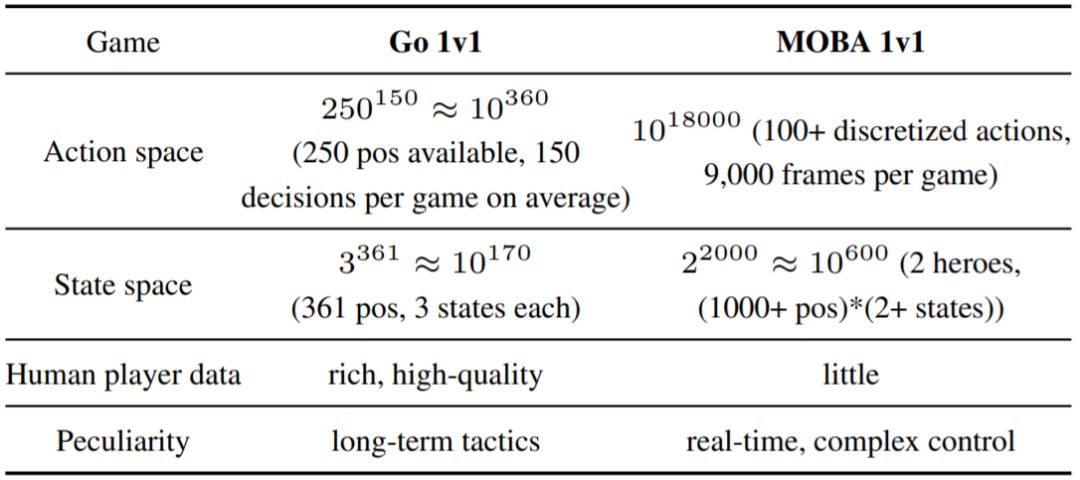
表1:围棋与 MOBA 1v1 游戏的比较
此外,MOBA 1v1 的游戏机制也很复杂。要在游戏中获胜,智能体必须在部分可观察的环境中学会规划、攻击、防御、控制技能组合以及诱导和欺骗对手。除了玩家与对手的智能体,游戏中还有其它很多游戏单位,比如小兵和炮塔。这会给目标选择带来困难,因为这需要精细的决策序列和相应的动作执行。
此外,MOBA 游戏中不同英雄的玩法也不一样,因此就需要一个稳健而统一的建模方式。还有一点也很重要:MOBA 1v1游戏缺乏高质量人类游戏数据以便进行监督学习,因为玩家在玩 1v1 模式时通常只是为了练习英雄,而主流 MOBA 游戏的正式比赛通常都采用 5v5 模式。
需要强调,本论文关注的是 MOBA 1v1 游戏而非 MOBA 5v5 游戏,因为后者更注重所有智能体的团队合作策略而不是单个智能体的动作决策。考虑到这一点,MOBA 1v1游戏更适合用来研究游戏中的复杂动作决策问题。
为了解决这些难题,本文设计了一种深度强化学习框架,并探索了一些算法层面的创新,对MOBA 1v1 游戏这样的多智能体竞争环境进行了大规模的高效探索。文中设计的神经网络架构包含了对多模态输入的编码、对动作中相关性的解耦、探索剪枝机制以及攻击注意机制,以考虑 MOBA 1v1 游戏中游戏情况的不断变化。为了全面评估训练得到的 AI 智能体的能力上限和策略稳健性,新设计的方法与职业玩家、顶级业务玩家以及其它在 MOBA 1v1 游戏上的先进方法进行了比较。
本文有以下贡献:
-
对需要高度复杂的动作决策的 MOBA 1v1 游戏 AI 智能体的构建进行了全面而系统的研究。在系统设计方面,本文提出了一种深度强化学习框架,能提供可扩展的和异步策略的训练。在算法设计方面,本文开发了一种用于建模 MOBA 动作决策的 actor-critic 神经网络。网络的优化使用了一种多标签近端策略优化(PPO)目标,并提出了对动作依赖关系的解耦方法、用于目标选取的注意机制、用于高效探索的动作掩码、用于学习技能组合 LSTM 以及一个用于确保训练收敛的改进版 PPO——dual-clip PPO。
-
在《王者荣耀》1v1 模式上的大量实验表明,训练得到的 AI 智能体能在多种不同类型的英雄上击败顶级职业玩家。
系统设计
考虑到复杂智能体的动作决策问题可能引入高方差的随机梯度,所以有必要采用较大的批大小以加快训练速度。因此,本文设计了一种高可扩展低耦合的系统架构来构建数据并行化。具体来说,这个架构包含四个模块:强化学习学习器(RL Learner)、人工智能服务器(AIServer)、分发模块(Dispatch Module)和记忆池(Memory Pool)。如图 1 所示。
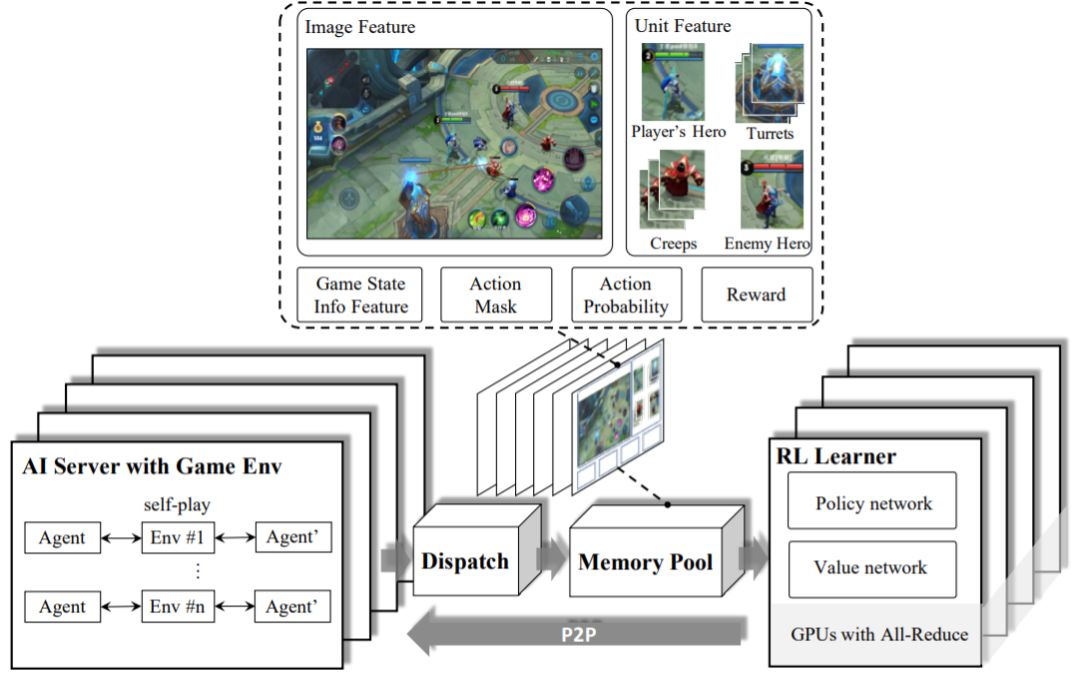
图1:系统设计概况
AI 服务器实现的是 AI 模型与环境的交互方式。分发模块是用于样本收集、压缩和传输的工作站。记忆池是数据存储模块,能为RL 学习器提供训练实例。这些模块是分离的,可灵活配置,从而让研究者可将重心放在算法设计和环境逻辑上。这样的系统设计也可用于其它的多智能体竞争问题。
算法设计
RL 学习器中实现了一个 actor-critic神经网络,其目标是建模 MOBA 1v1 游戏中的动作依赖关系。如图2所示。
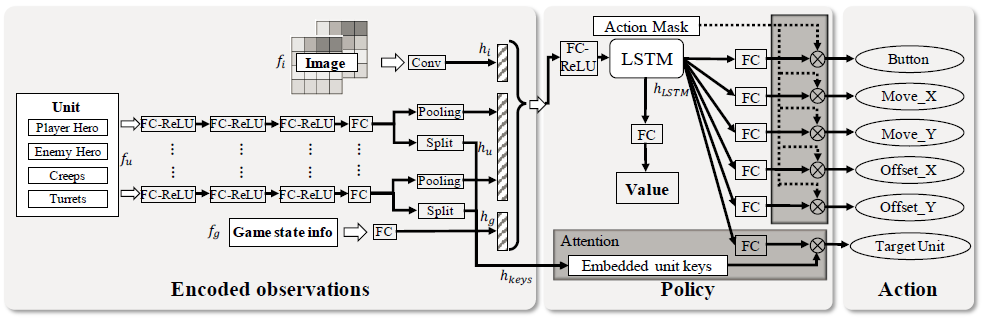
图 2:论文实现的actor-critic网络
为了实现有效且高效的训练,本文提出了一系列创新的算法策略:
-
目标注意力机制 ;用于帮助AI在 MOBA 战斗中选择目标。 -
LSTM ;为了学习英雄的技能释放组合,以便AI在序列决策中,快速输出大量伤害。 -
动作依赖关系的解耦 ;用于构建多标签近端策略优化(PPO)目标。 -
动作掩码 ;这是一种基于游戏知识的剪枝方法,为了引导强化学习过程中的探索而开发。 -
dual-clip PPO ;这是 PPO 算法的一种改进版本,使用它是为了确保使用大和有偏差的数据批进行训练时的收敛性。如图3所示。
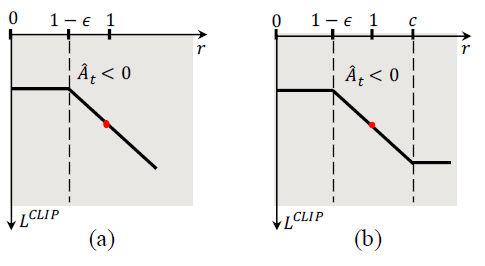
图 3:论文提出的dual-clip PPO算法示意图,左为标准PPO,右为dual-clip PPO
有关这些算法的更多详情与数学描述请参阅原论文。
实验
系统设置
测试平台为热门 MOBA 游戏《王者荣耀》的 1v1 游戏模式。为了评估 AI 在现实世界中的表现,这个 AI 模型与《王者荣耀》职业选手和顶级业余人类玩家打了大量比赛。实验中 AI 模型的动作预测时间间隔为 133 ms,这大约是业余高手玩家的反应时间。另外,论文方法还与已有研究中的基准方法进行了比较,其中包括游戏内置的决策树方法以及其它研究中的 MCTS 及其变体方法。实验还使用Elo分数对不同版本的模型进行了比较。
实验结果
探索动作决策能力的上限
表 3 给出了AI和多名顶级职业选手的比赛结果。需要指出这些职业玩家玩的都是他们擅长的英雄。可以看到 AI 能在多种不同类型的英雄上击败职业选手。
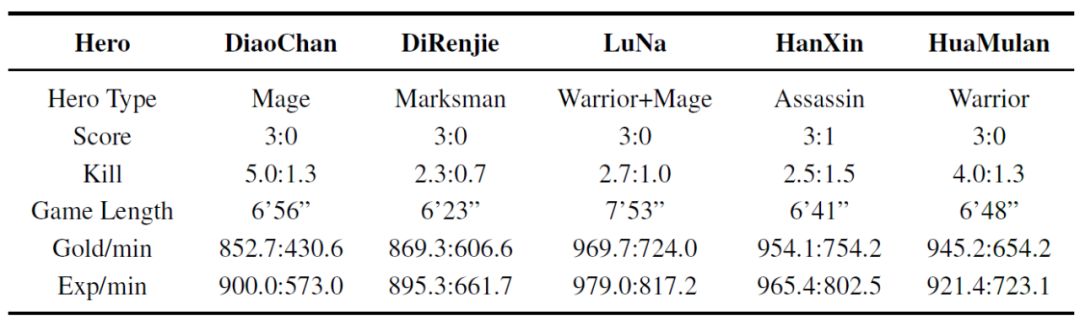
表3:AI 与职业选手使用不同类型英雄比赛的结果
评估动作决策能力的稳健性
实验进一步评估了 AI 学习的策略能否应对不同的顶级人类玩家。在2019年8月份,王者荣耀1v1 AI对公众亮相,与大量顶级业余玩家进行了2100场对战。AI胜率达到99.81%。
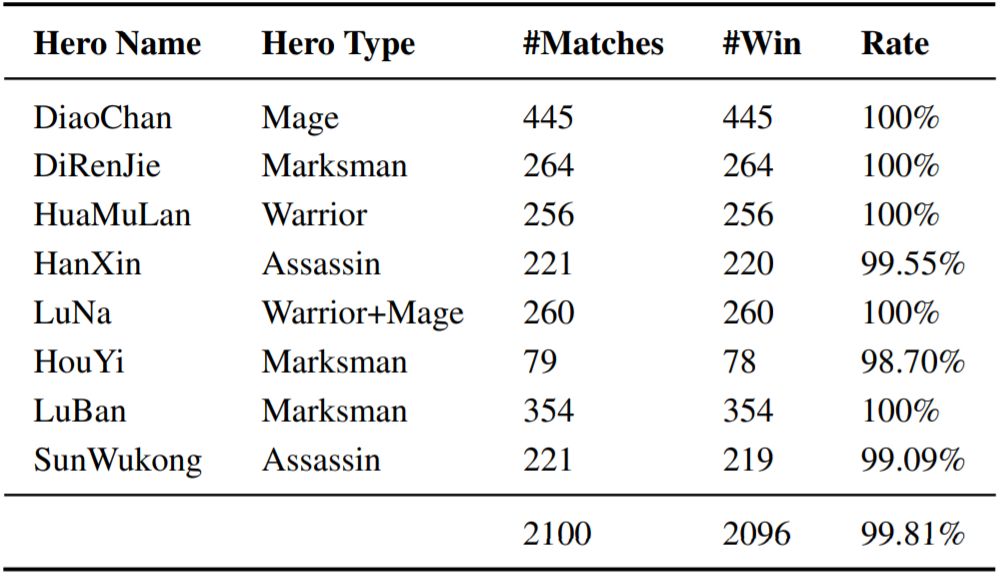
表4:AI 与不同顶级人类玩家的比赛结果
基准比较
可以看到,用论文新方法训练的 AI 的表现显著优于多种baseline方法。
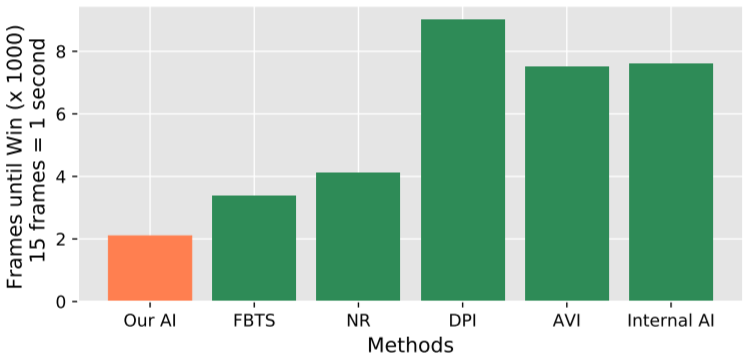
图4:击败同一基准对手的平均时长比较
训练过程中模型能力的进展
图 5 展示了训练过程中 Elo 分数的变化情况,这里给出的是使用射手英雄「狄仁杰」的例子。可以观察到 Elo 分数会随训练时长而增长,并在大约 80 小时后达到相对稳定的水平。此外,Elo 的增长率与训练时间成反比。
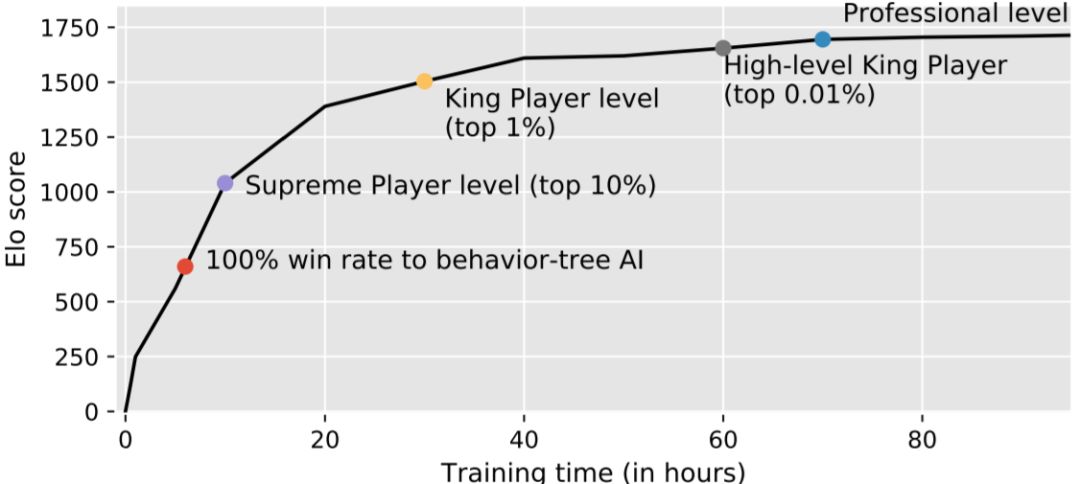
图5:训练过程中 Elo 分数的变化情况
控制变量研究
为了理解论文方法中不同组件和设置的效果,控制变量实验是必不可少的。表 5 展示了使用同样训练资源的不同「狄仁杰」AI 版本的实验结果。
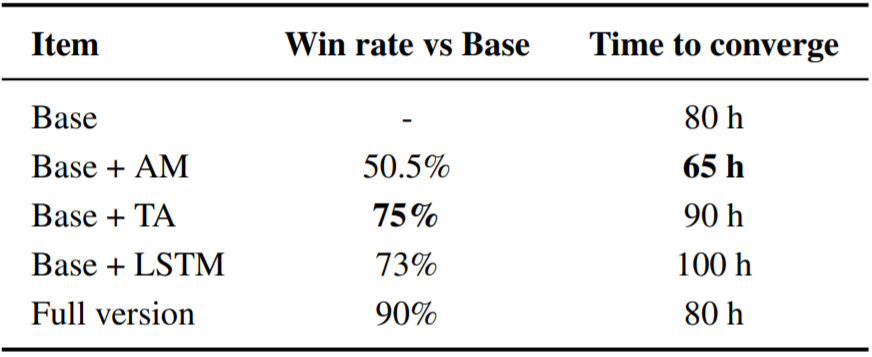
表5:控制变量实验
未来工作
本文提出的框架和算法将在未来开源,而且为了促进对复杂游戏的进一步研究,腾讯也将在未来把《王者荣耀》的游戏内核提供给社区使用,并且还会通过虚拟云的形式向社区提供计算资源。
更多阅读:
腾讯AI制霸王者荣耀,世界杯5V5 「绝悟」绝杀职业玩家,1天训练强度超人类440年





