Tesla V100之NVCaffe混合精度训练深度解析篇
混合精度训练种类
| 训练类型 | 数据类型 | 矩阵乘积累加器 | Weights类型 | GPU |
|---|---|---|---|---|
| FP32 | FP32 | FP32 | FP32 | |
| "Pascal" FP16 | FP16 | FP16 | FP16/FP32 | Pascal(GP100) |
| 混合精度 | FP16 | FP32 | FP16/FP32 | Volta |
"Master" weights —— 用以更新时使用的weights(随机梯度下降)
Volta: 混合精度训练中Master weights采用FP32精度
Volta:Tensor Core 4x4 矩阵乘积累加器
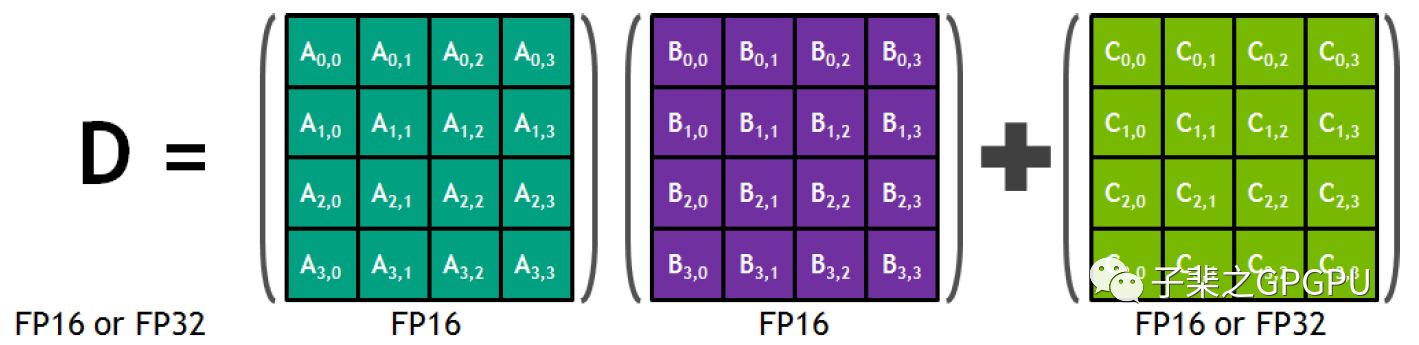
矩阵乘积累加操作支持两个FP16矩阵乘法以及FP16或FP32的加法操作
Volta Tensor 操作
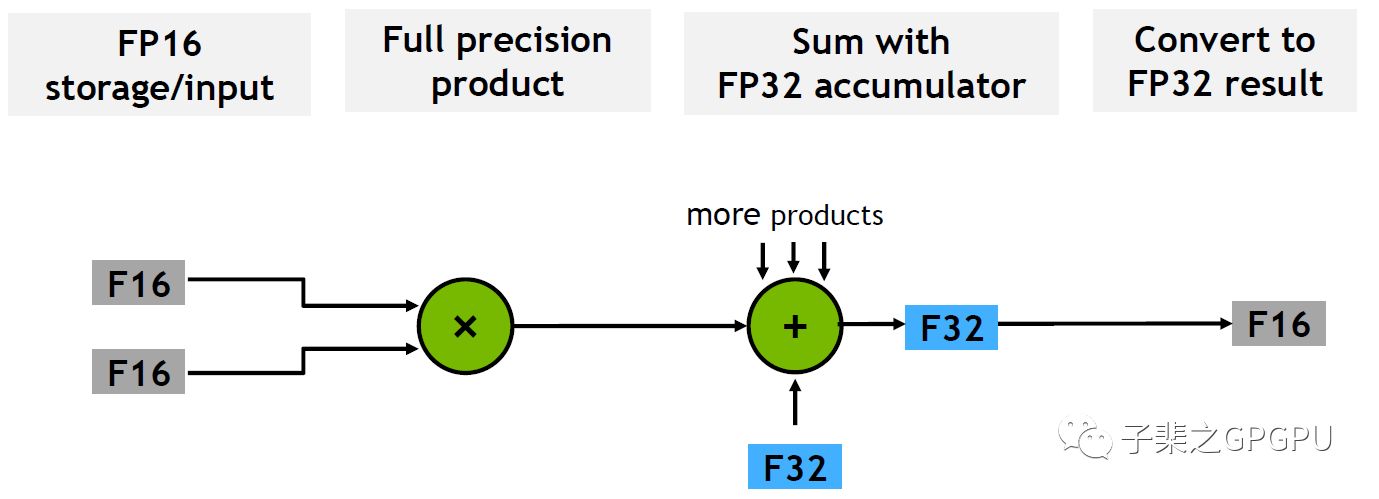
Volta 同时支持FP16的累加模式,可以在推理中使用
训练中建议使用FP32的累加操作,能获得更好的性能;在NVCaffe中默认是使用FP32的累加操作,如果需要切换至FP16累加模式可以在网络结构文件中添加(例如文件train_val.prototxt中):
default_forward_math: FLOAT16 default_backward_math: FLOAT16
训练流程
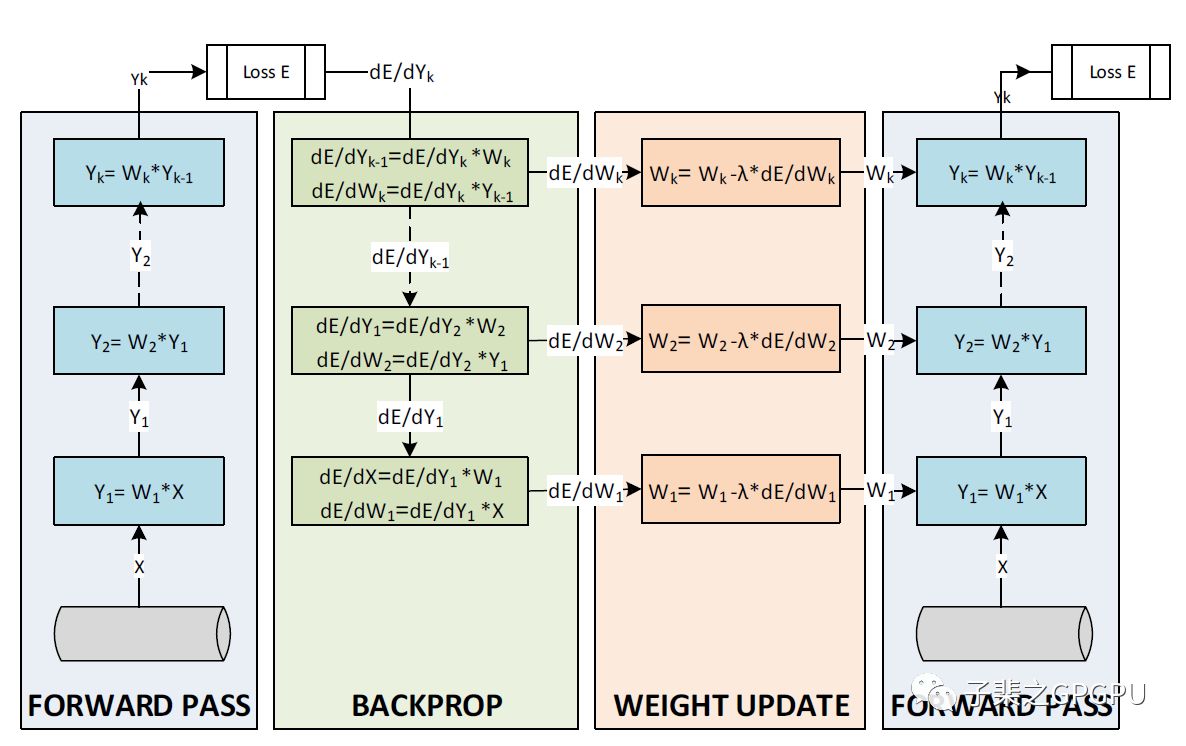
一次训练迭代可以分为以下三个部分:
前项传递通过将输入值与权重进行计算获得网络预测的结果
预测结果与真值比对并获得两者之间的损失(Loss),为了减少Loss,通过计算损失函数梯度获取最好的梯度下降方向
根据梯度计算结果更新网络权重
训练原理
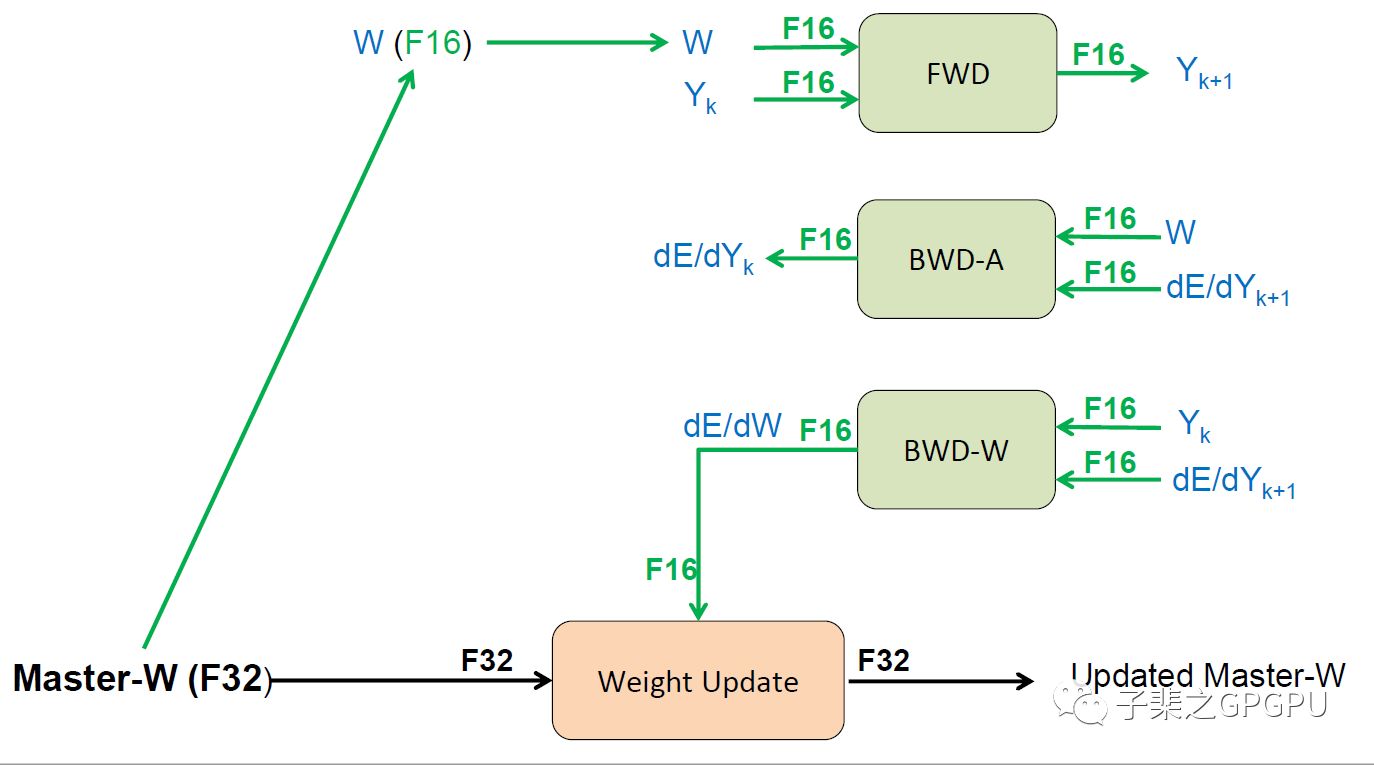
混合精度训练中,我们选择的数据类型为FP16,因此对于每一次迭代,我们会复制保存并维护一个FP32的weights,我们称之为Master-W,在开始迭代前将FP32的weights转换成为FP16的weights,之后载入进Tensor Core进行计算,计算结果都会在最后转换成FP16格式。在完成所有计算之后,我们会将计算获得的FP16的weights更新部分更新至Master-W中,从而完成weights的更新流程。
完美支持的网络结构
NVCaffe中是默认使用FP32的累加操作和FP32的Master weights的,部分网络使用混合精度训练只需要在网络结构文件(train_val.prototxt)中添加以下内容即可:
default_forward_type: FLOAT16 default_backward_type: FLOAT16
该种训练方法直接完美训练的网络包括:
图片分类任务 - 数据集 ILSVRC12
GoogleNet, VGG-D, Inception v3, Resnet-50
Solver: SGD with momentum
语言模型和机器翻译
NMT
Solver: ADAM
网络实验结果
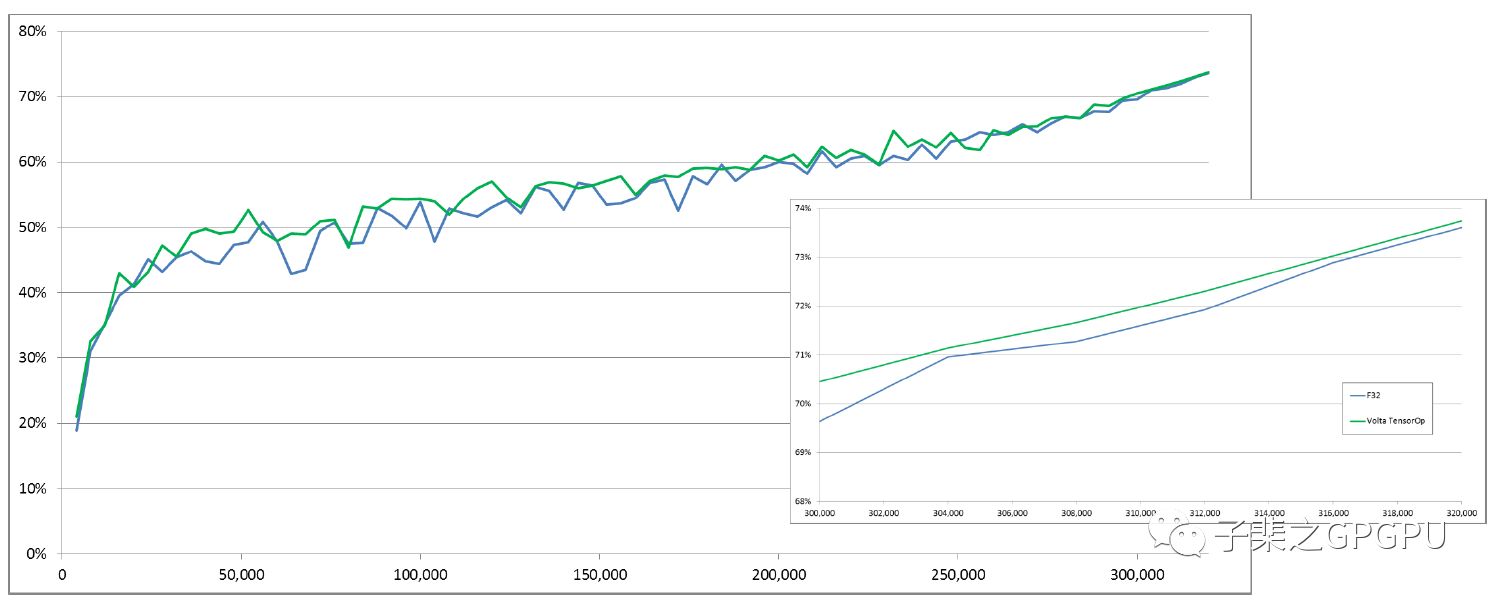
以下分别是Googlenet/Inception v1/Resnet50分别采用Volta混合精度训练和FP32训练的Accuracy曲线图:
很明显两者Accuracy的增长具有极其相似的曲线。
分别在1百万次,50万次,30万次迭代后混合精度训练都取得了相同甚至好于FP32训练的Accuracy。
此外,混合精度训练还能显著降低显存消耗并具有更快的单次迭代速度。
因此在上文的网络中,混合精度训练相较于FP32能有效的提升我们的训练效率并取得更好的训练结果。

GOOGLENET
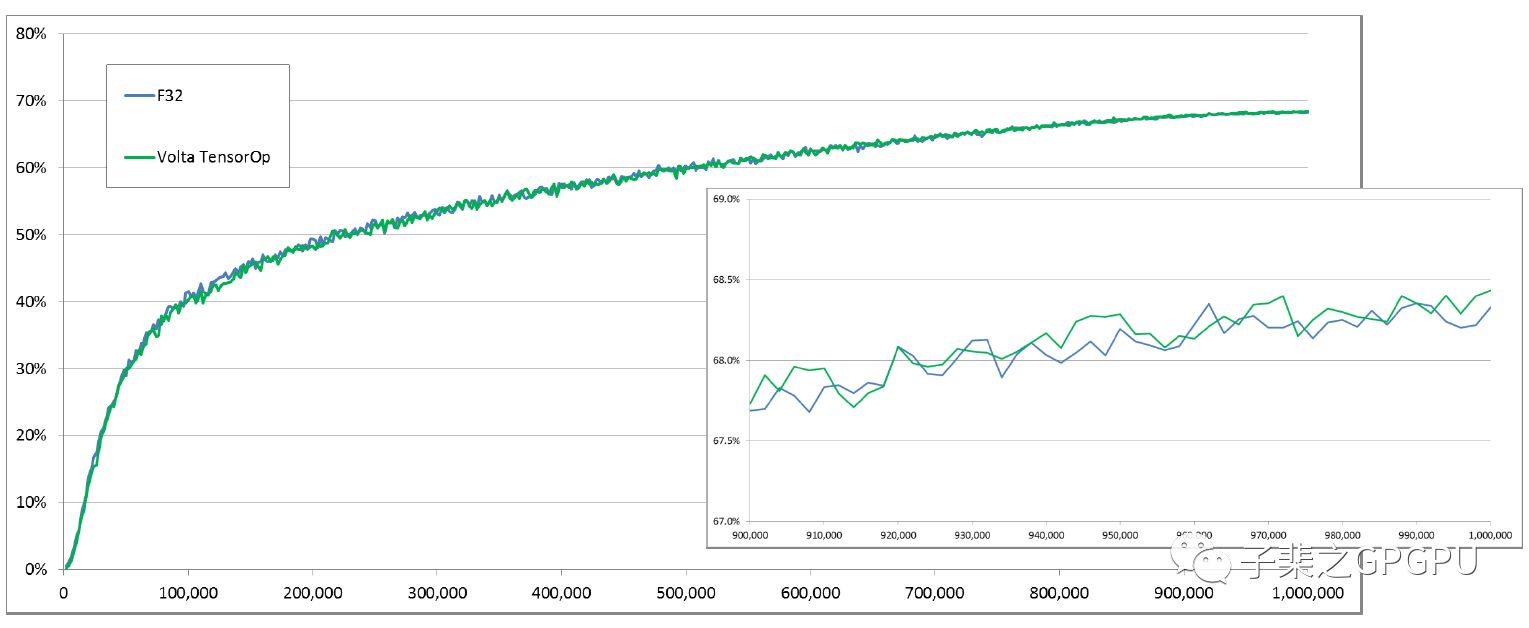
INCEPTION V1
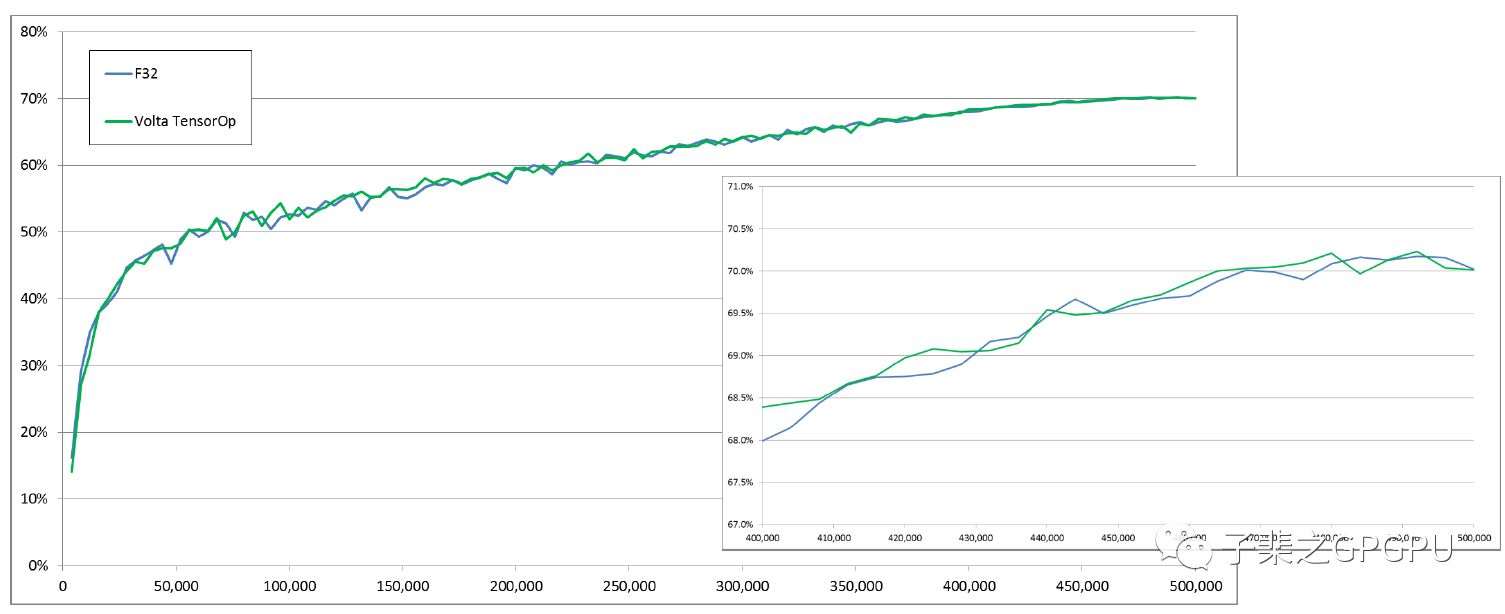
RESNET-50
END
总的来说,我们需要在混合精度训练中使用FP16的数据类型,并在使用FP32计算类型,FP32的Master weights。而如何利用Tensor Core进行混合精度训练对于部分网络只需要设置上文的两个参数即可,优化好的NVCaffe可以前往我们的NGC下载。同时我这边也抛出两个小问题给大家思考:
是不是所有的网络采用这种混合精度训练模式都能获得很好的性能提升呢?如果不是,为什么呢?又怎么解决这个问题呢?
在迭代过程中需要维护一个FP32的Master权重,可不可以直接使用FP16的Master权重呢?又怎么实现呢?



