基于图像的大规模室外三维重建技术进展综述
基于图像的三维重建,旨在从一组二维多视角图像精确地恢复真实场景的几何形状,是计算机视觉和摄影测量中一个基础且活跃的研究领域,具有重要的理论研究意义和应用价值,在智慧城市、虚拟旅游、数字遗产保护、数字地图和导航等领域有着广泛的应用。近年来,随着图像采集系统(包括智能手机、消费级数码相机、民用无人机)的普及和互联网的高速发展,用户可以通过搜索引擎(例如谷歌)轻松获取大量的关于某个室外场景的互联网图像。如何利用这些图像进行高效、鲁棒、准确的三维重建,为用户提供真实感知和沉浸式体验,已经成为研究热点,引发了学术界和产业界的广泛关注,现已涌现多种多样的解决方法。特别地,深度学习的出现为大规模室外图像三维重建的研究提供了新的契机。本文首先阐述大规模室外图像三维重建的基本串行过程,包括图像检索、图像特征点匹配、运动恢复结构、多视图立体。然后,本文将区分传统方法和基于深度学习的方法,系统而全面地回顾大规模室外图像三维重建技术在各个重建子过程中的发展和应用。之后,本文详细总结各个子过程中适用于大规模室外场景的数据集和评价指标。最后,本文将介绍现有主流的开源和商业三维重建系统以及国内相关产业的发展现状。
http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?flag=2&file_no=202012270000001&journal_id=jig
近年来,随着图像采集设备(如智能手机、消费级数码相机、民用无人机)的普及和互联网的高速发展,人类采集到的图像越来越丰富,并通过互联网分享到世界各个角落。如果用户想了解某个场景(如圣彼得广场),可以简单地在搜索引擎中检索关键字“圣彼得广场”,即可得到成千上万幅关于圣彼得广场的图像结果。
然而,由于从三维场景到二维图像的映射损失了深度信息,导致用户无法获得沉浸式体验。对于类似于圣彼得广场这样的开阔室外场景,更好的方案是直接提供真实的三维场景模型,如图2所示。因此,如何利用互联网中关于某个室外场景丰富的二维图像,挖掘其内在的联系和多视图几何关系,进而生成场景的三维模型,已成为近年来研究的热点,具有重要的理论和实践意义。相较于基于Lidar、Radar等扫描设备的方法而言,利用图像进行三维重建具有数据易获取、普适性好、成本低廉、易于推广等优点。
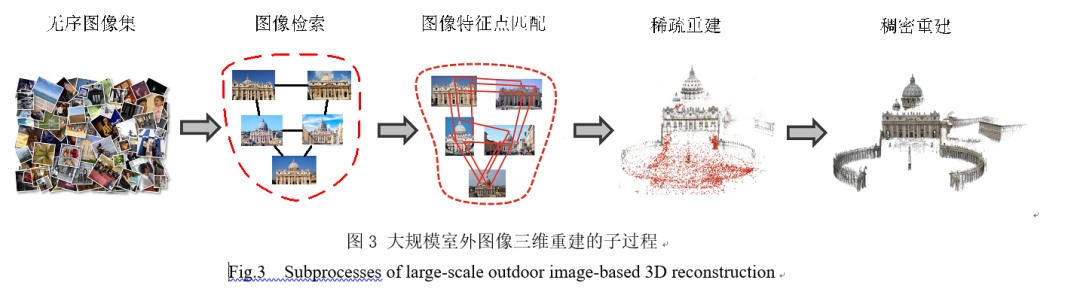
对于人类而言,通过视觉构建真实、准确、完整的三维模型是自然而然的事,但是在计算机程序中抽象出该过程却绝非易事。为了使大规模图像三维重建在计算机程序中可行,通用的方法是将重建分解为几个更小、更易处理的串行子过程。本文重点关注这些子过程中点云生成部分,如图3所示。对于后续的表面重建和纹理映射,本文不进行具体阐述。
子过程1:图像检索。由于互联网图像缺少时空关联的信息,任意两幅图像间是否拍摄到相同场景是未知的。在图像检索阶段,需要判断数据集中哪些图像之间具有重叠关系。图像检索通常由以下两个阶段实现:1)通过一个映射函数抽象图像的内容,把数据集中所有图像投影到某个紧凑的向量空间,利用投影后的一维向量来表示数据集中每幅图像。2)对于检索图像,通过某种向量距离度量的方式(如L2范式),找到其最近邻邻居。
子过程2:图像特征点匹配。图像特征点匹配是三维重建的基础,其任务是将不同图像上相同的特征点进行关联。图像特征点匹配通常由以下四个阶段实现:1)图像特征点检测。图像特征点检测,是利用检测子(detector)定位图像的局部特征点。特征点往往是物体边界方向突然改变的点或两个或多个边缘段之间的交点,它在图像空间中具有明确的位置。2)图像特征点描述。图像特征点描述,是利用描述子(descriptor)编码特征点的局部邻域(patch)。理想情况下,特征点描述应该满足不同物体特征能相互区分,相同物体特征在不同图像中能重复识别的要求。3)特征点匹配。特征点匹配,是利用最近邻搜索(nearest neighborsearch)或者图匹配,计算两幅或者多幅图像的特征点对应关系。4)误匹配过滤。由于特征点匹配过程中存在光照、尺度、旋转、弱纹理、重复纹理等因素的干扰,匹配结果或多或少会出现错误。因此,为了提高匹配成功率,通常使用误匹配过滤算法进行后处理。
子过程3:稀疏重建, 又称为运动恢复结构(Structure-from-Motion,以下简称SfM)。稀疏重建,是根据图像上二维特征点的匹配关系,自动地计算出相机姿态参数和稀疏点云的三维坐标的过程,该过程为三维重建的核心。稀疏重建通常由以下两个阶段实现:1)场景图(View Graph)构建与优化。场景图是一种用来描述多视图图像之间几何关系的图数据结构,由顶点和带权重的无向边组成,其中顶点表示图像,边表示两张图像的特征匹配和双视图几何模型。为了提升后续重建的效率和保证场景图的环一致性(loop consistency),可以对场景图进行优化。2)运动恢复结构。现有的运动恢复结构大致可以分为以下三种方式:增量式(Incremental)、全局式(Global)和分布式(Distributed)。本文会在1.3节对这三种方式分别进行详细介绍。
子过程4:稠密重建,又称为多视图立体(Multi-View-Stereo,以下简称MVS)。稠密重建,是根据场景中相机的姿态参数,获取更丰富的场景表达形式(例如稠密点云)的过程。稠密重建有多种实现方案,如点云扩散法(Lhuillier等,2005),体素重建法(Kutulakos等,2000),深度图融合法(Shen,2013)。相比于前两种方法,深度图融合法最为灵活且实验效果最好。基于深度图融合法的稠密重建通常由以下四个阶段实现:1)参照图像选取。对于每幅图像,需要在图像集中找到一组能协助其估计深度的参照图像,尽量使得原图中每一个像点与参照图像存在对应。2)深度图估计。对于原图中的每个像点,需要估计一个合适的深度,使得原图和参照图像中以该像点为中心的对应窗口具有最大的光度一致性(photo consistency)。光度一致性的度量方法有误差平均和法(SSD)(Sum of Squared Differences)、误差绝对和法(SAD)、归一化互相关算法(NCC)、Census、Rank等。3)深度图提炼。由于图像之间存在遮挡、镜面反射、弱纹理、重复纹理等干扰,相邻的深度图可能存在不一致的现象。如果在相邻深度图中检测到了不一致的深度值,则需要把该深度值从深度图中剔除。4)深度图融合。深度图融合,是利用多视角的深度图生成稠密点云。由于不同视角的深度图覆盖了场景的相同区域,若直接对所有深度图进行反向投影,会出现很多冗余。通常利用深度图反向投影的遮挡关系和距离度量,来去除冗余。
本文整体结构安排如下,第一章为基于传统方法的三维重建技术,第二章是基于深度学习的三维重建技术,第三章是标准数据集和评价指标,第四章是现有三维重建系统及相关产业发展。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“3DRI” 就可以获取《基于图像的大规模室外三维重建技术进展综述》专知下载链接





