【NLTK基础】一文轻松使用NLTK进行NLP任务(附视频)
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要6分钟
跟随小博主,每天进步一丢丢


NLTK作为文本处理的一个强大的工具包,为了帮助NLPer更深入的使用自然语言处理(NLP)方法。本公众号开更Natural Language Toolkit(即NLTK)模块的“ Natural Language Processing”教程系列。
NLTK在文本领域堪称网红届一姐的存在,可以帮助在文本处理中减少很多的麻烦,比如从段落中拆分句子,拆分单词,识别这些单词的词性,突出显示主要的topic,甚至可以帮助机器理解文本的全部内容,在本系列中,我们将主要讨论观点挖掘和情感分析领域。
在之后学习NLTK的过程中,我们将主要学习以下内容:
-
将文本切分成句子或者单词 -
NLTK命名实体识别 -
NLTK文本分类 -
如何将Scikit-learn (sklearn)和NLTK结合使用 -
使用Twitter执行实时,流式传输,情感分析 -
.......
欢迎大家持续关注“AI算法之心”
在学习NLTK之前,当然是NLTK的安装。在安装NLTK之前,首先需要安装Python。
这里就此略过......
注意:请安装python3的环境
接下来就是安装NLTK3,最简单的安装NLTK模块的方法是使用pip。
这里针对Linux(Windows和Mac os应该也差不多,笔者太穷,买不起Mac,笔者就不尝试了......)
pip install nltk接下来,我们需要为NLTK安装一些组件。通过通常的方式(jupyter里面也可以哦)打开python并输入:
import nltknltk.download()
一般地,GUI会像这样弹出,只有红色而不是绿色:
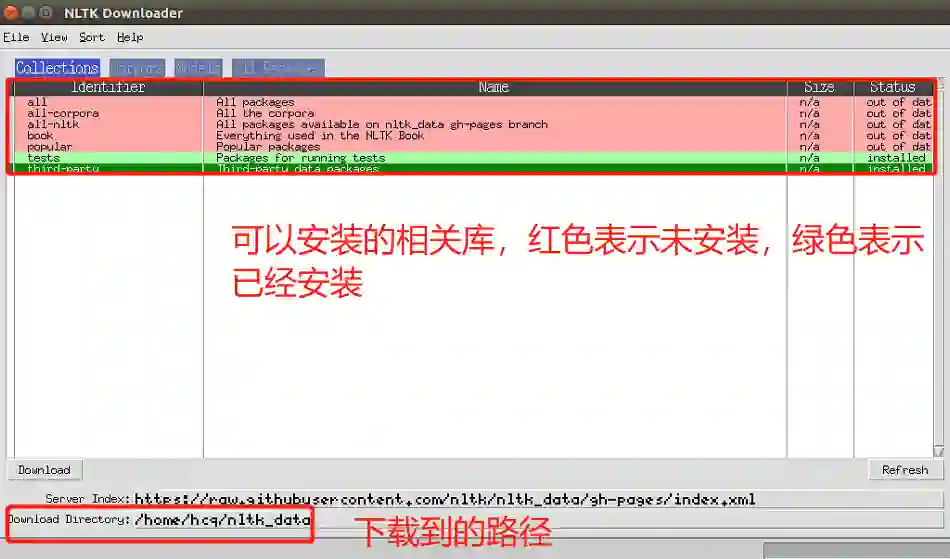
选择下载所有软件包的“all”,然后单击“download”。这将提供所有标记器,分块器,其他算法以及所有语料库。如果空间有限,可以选择手动选择下载所需要的内容。NLTK模块将占用大约7MB,整个nltk_data目录将占用大约1.8GB,其中包括分块器,解析器和语料库。
如果没有上述界面,可以通过命令行下载,
import nltknltk.download()d (for download)all (for download everything)
这样一来,就可以下载所有内容。
安装完成后,下面我们来简单的了解一些相关知识。下面举个例子,说明如何使用NLTK模块,比如将一段话按照句子粒度划分:
from nltk.tokenize import sent_tokenize, word_tokenizeEXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."print(sent_tokenize(EXAMPLE_TEXT))
最初,或许你会认为通过单词或句子之类的标记进行标记是一件微不足道的事情。对于很多句子来说都可以。第一步可能是做一个简单的.split('.'),或按句点和空格分隔。然后,也许会引入一些正则表达式以"."," "和大写字母(针对英文语料)分隔。问题是像"Mr. Smith"这样的事情会带来麻烦,还有许多其他事情。
另外,按单词拆分也是一个挑战,尤其是在考虑像我们这样的串联这样的事情时。NLTK将会继续前进,并且通过这种看似简单但非常复杂的操作在文本处理的时候节省大量时间。
上面的代码将输出句子,分为句子列表。
['Hello Mr. Smith, how are you doing today?', 'The weather is great, and Python is awesome.', 'The sky is pinkish-blue.', "You shouldn't eat cardboard."]
下面我们将这段话按照词的划分试试:
print(word_tokenize(EXAMPLE_TEXT))现在我们得到的输出是:
['Hello', 'Mr.', 'Smith', ',', 'how', 'are', 'you', 'doing', 'today', '?', 'The', 'weather', 'is', 'great', ',', 'and', 'Python', 'is', 'awesome', '.', 'The', 'sky', 'is', 'pinkish-blue', '.', 'You', 'should', "n't", 'eat', 'cardboard', '.']
这里有几件事要注意。首先,请注意,标点符号被视为单独的词。另外,请注意将单词“shouldn't”分为“should”和“n't”。最后,“pinkish-blue”确实被当作它要变成的"one word"。太酷了!
现在,看看这些标记化的单词,我们必须开始考虑下一步可能是什么。我们开始思考如何通过看这些单词来产生意义。我们可以清楚地想到为许多单词赋予价值的方法,但是我们也看到了一些基本上毫无价值的单词。这些是停用词(stopwords)的一种形式,我们也可以处理。下一篇我们将介绍NLTK中的stopwords,欢迎关注哦!!!