Facebook最新论文:跨语言模型预训练,三大任务刷新最高性能

新智元报道
新智元报道
来源:arxiv
编辑:肖琴
【新智元导读】Facebook最新研究将NLP中模型预训练方法扩展到跨语言模型,在跨语言分类、无监督机器翻译和有监督机器翻译任务中都取得了最先进的结果。
最近的研究已经证明,生成式预训练对于英语自然语言理解很有效。但该领域的研究基本上都是单语的,主要集中在英语。
近日,Facebook发表最新论文“Cross-lingual Language Model Pretraining”,将这种方法扩展到多种语言,并展示了跨语言预训练的有效性。

论文地址:https://arxiv.org/pdf/1901.07291.pdf
这篇论文提出两种学习跨语言模型的方法:一种是只依赖单语数据的无监督方法,另一种是利用具有新的跨语言模型目标的并行数据的有监督方法。
他们表示,两种方法在跨语言分类、无监督机器翻译和有监督机器翻译方面都取得了最先进的成果。
在 XNLI 上,新方法将最先进技术水平提高了 4.9% 的绝对准确度。
在无监督的机器翻译中,我们在 WMT’16 德语 - 英语数据集中获得了 34.3 BLEU 分数,比之前的最高分数提高了 9 BLEU 以上。
在有监督机器翻译任务中,我们在 WMT'16 罗马语 - 英语数据集中获得了 38.5 BLEU 的最高分,比之前的最佳方法高了 4 BLEU。
该方法的代码和预训练模型将在近期公开提供。
句子编码器的生成式预训练(Generative pretraining)已经使许多自然语言理解的 benchmark 取得了显著的进步。在此背景下,Transformer 语言模型是在大型无监督文本语料库上学习的,然后针对自然语言理解 (NLU) 任务进行微调,如分类任务或自然语言推理。
尽管研究社区对学习通用句子表示的兴趣激增,但该领域的研究基本上都是单语的,主要集中在英语 Benchmark。
学习和评估多种语言的跨语言句子表示的最新进展旨在减轻以英语为中心的偏见,并提出可以构建通用的跨语言编码器,将任何句子编码到共享嵌入空间中。
在这项工作中,我们证明了跨语言模型预训练在多个跨语言理解 (XLU)benchmark 上的有效性。
具体来说,这项工作有以下贡献:
提出了一种新的无监督方法,用于使用跨语言语言建模来学习跨语言表示,并研究了两种单语预训练的目标。
提出一个新的监督学习目标,当并行数据可用时,该目标可以改进跨语言的预训练。
我们的模型在跨语言分类、无监督机器翻译和有监督机器翻译方面都显著优于以往的最优技术水平。
这一研究表明,跨语言模型可以有效地改善低资源语言的困惑度 (perplexity)。
代码和预训练模型将在不久公开。
论文接着介绍了整个工作中考虑的三个语言建模目标。其中两个只需要单语数据 (无监督),第三个需要平行句子语料 (有监督)。
我们考虑了 N 种语言。除非另有说明,我们假设我们有 N 个单语语料库 {Ci}i=1…N,用ni 表示 Ci 中的句子数。
因果语言建模 (Causal Language Modeling , CLM)
我们的因果语言建模 (CLM) 任务包括一个 Transformer 语言模型,该模型被训练来对给定句子中单词的概率进行建模。虽然 CNN 在语言建模基准测试中是性能最好的,但Transformer 模型也很有竞争力。
在 LSTM 语言模型的情况下,通过向 LSTM 提供上一个迭代的最后隐藏状态来执行时间反向传播 (backpropagation through time, BPTT)。对于 Transformer,可以将之前的隐藏状态传递给当前的 batch,为 batch 中的第一个单词提供上下文。但是,这种技术不能扩展到跨语言设置,因此为了简单起见,我们只保留每个 batch 中的第一个单词,而不考虑上下文。
Masked Language Modeling (MLM)
Devlin et al. (2018) 论文中提出的 MLM 也是我们的一个语言建模目标,也成为完形填空任务。根据 Devlin 等人的研究,我们从文本流中随机抽取 15% 的 BPE token,80%的时间用 [MASK] token 替换,10% 的时间用随机 token 替换,10% 的时间保持不变。
我们的 MLM 目标如图 1 所示:
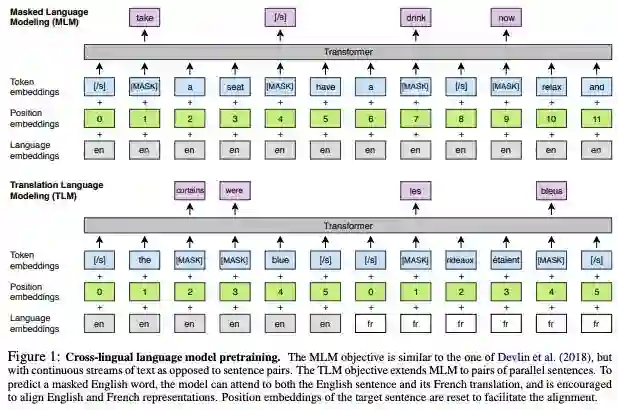
图 1: 跨语言模型预训练。 MLM 目标类似于 Devlin et al. (2018) 里的,但不是句子对,是连续的文本流。TLM 目标将 MLM 扩展到并行句子对。为了预测一个被遮挡的英语单词,该模型可以同时考虑英语句子及其法语翻译,并鼓励将英语和法语表示对齐。目标句子的位置嵌入被重置以方便对齐。
翻译语言建模 (TLM)
CLM 和 MLM 的目标都是无监督的,只需要单语数据。但是,当并行数据可用时,这些目标不能用于利用并行数据。我们提出一种新的翻译语言建模方法 (TLM) 来提高跨语言训练的效果。我们的 TLM 目标是 MLM 的扩展,其中不考虑单语文本流,而是将并行的句子连接起来,如图 1 所示。
在这项工作中,我们考虑 CLM、MLM,或与 TLM 结合的 MLM 预训练的跨语言模型。对于 CLM 和 MLM 目标,我们使用由 256 个 token 组成的 64 个连续句子流的batches 来训练模型。对于 TLM 与 MLM 结合的目标,我们在这两个目标之间交替,并使用类似的方法对语言对进行取样。
跨语言模型预训练
在本节中,我们将解释如何使用跨语言模型来获得:
为 zero-shot 跨语言分类更好地初始化的句子编码器
更好地初始化有监督和无监督的神经机器翻译系统
低资源语言的语言模型
无监督的跨语言词汇嵌入
我们实验证明了跨语言模型预训练对几个 benchmark 的强大影响,并将我们的方法与当前的最优技术水平进行比较。
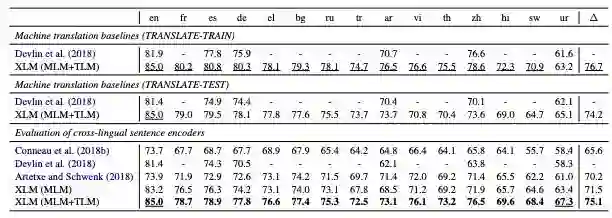
表 1:跨语言分类准确率结果。测试了 15 种 XNLI 语言的准确性。我们报告了基于跨语言句子编码器的机器翻译 baselines 和 zero-shot 分类方法的结果。XLM (MLM) 对应于只在单语语料库上训练的无监督方法,XLM (MLM+TLM) 对应于通过 TLM 目标利用单语和并行数据的监督方法。∆对应的平均精度。
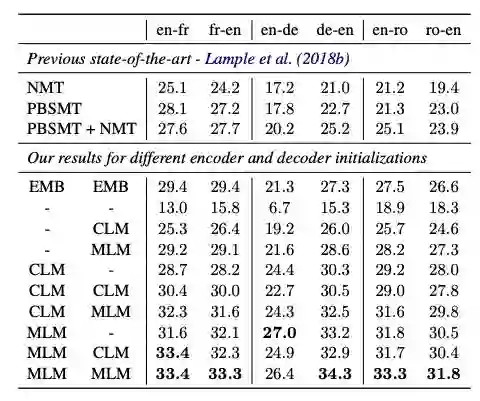
表 2:WMT’14 英语 - 法语, WMT’16 德语 - 英语 以及 WMT’16 罗马尼亚语 - 英语的无监督机器翻译 BLEU 分数结果。前两列表示用于预训练编码器和解码器的模型。“-” 表示模型被随机初始化,CLM 和 MLM 对应于针对 CLM 或 MLM 目标的模型的预训练。
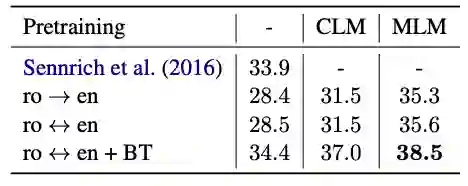
表 3:WMT’16 罗马尼亚语 - 英语的有监督机器翻译 BLEU 评分结果。Sennrich et al.(2016) 是此前最先进的技术,使用了反向翻译和集成模型。ro↔en 对应于模型训练的两个方向。
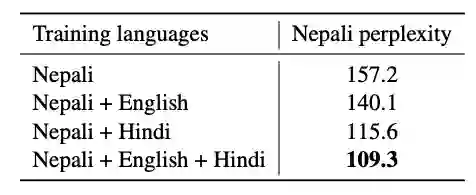
表 4:语言建模结果
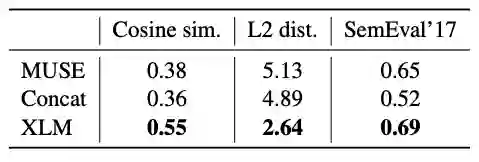
表 5:无监督跨语言词嵌入源词与其译文之间的余弦相似度和 L2 distance。
论文地址:
https://arxiv.org/pdf/1901.07291.pdf
更多阅读:
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。


