Pytorch数据加载的分析
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
Pytorch数据加载的效率一直让人头痛,此前我介绍过两个方法,实际使用后数据加载的速度还是不够快,我陆续做了一些尝试,这里做个简单的总结和分析。
1、定位问题
在优化数据加载前,应该先确定是否需要优化数据加载。数据读取并不需要更快,够快就好。一般的,显存占用率很高,利用率却很低的时候,通常会怀疑是数据加载太慢导致,但不是唯一原因,比如模型内大量的循环也会导致GPU利用率低。可以尝试固定数据看看是否可以提高GPU利用率。
确定数据加载需优化后,需要判断是数据加载的哪一部分慢。整个数据处理的流程如下:
-
读取图片数据(IO,可能存在IO瓶颈) -
解码数据(一般是numpy格式,可能存在计算性能瓶颈) -
数据增强(可能存在计算性能瓶颈) -
类型变换(CPU->GPU,,可能存在数据拷贝瓶颈)
为节省阅读时间,先给结论,数据加载慢主要是由于计算性能的瓶颈,而不是IO瓶颈和数据拷贝瓶颈(测试数据为1920x1080的大图,小图片可能结论不同)。为优化加载速度应该从两个方向下手:
-
更快的图片解码 -
更快的数据增强 -
更强性能的设备,如使用GPU进行数据解码和增强(DALI库)
下面是具体的实验分析,测试环境和数据如下:
-
CPU: Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz (正常负载,利用率小于30%) -
GPU: V100 (正常负载,利用率小于30%) -
数据集数据840张,尺寸为1920x1080 -
batch size = 64 -
无特别说明下num_workers=2 -
迭代10个epoch(13x10个迭代次数)
2. Baseline
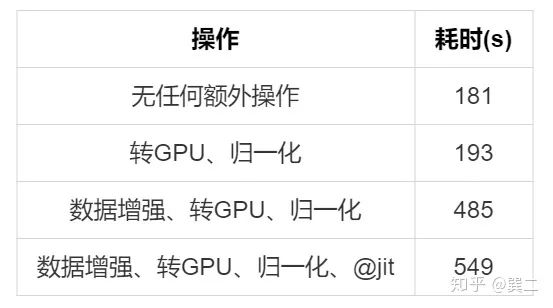
不进行任何额外优化下的速度如下:
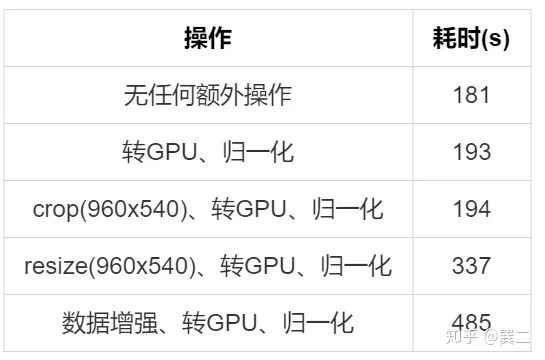
其中:
-
无任何额外操作的输出图片为原始大小(1920x1080) -
归一化的具体操作为: x = x.permute(0, 3, 1, 2).float().div(255) -
转GPU的具体操作为: x = x.cuda() -
resize为opencv的resize,插值方式为 cv2.INTER_LINEAR -
数据增强的操作使用Numpy和Opencv,包括: -
random resize -
random crop -
random filp -
random HSV
可以明显的看出耗时主要发生在数据读取和数据增强部分,而CPU到GPU的数据转换等耗时较少。
需要注意的一个地方是【crop(8960x540)、转GPU、归一化】和【转GPU、归一化】的耗时差不多,crop的耗时很小,且crop后图片较小,使得转GPU的操作也变快了,最终二者的耗时差不多。
分析将分为以下几个部分:DataLoader 图片读取 * 数据增强
此外由于【CPU转GPU、数据的归一化转秩】和【DataLoader】比较相关,会一起分析。
3. DataLoader
(1) num_workers
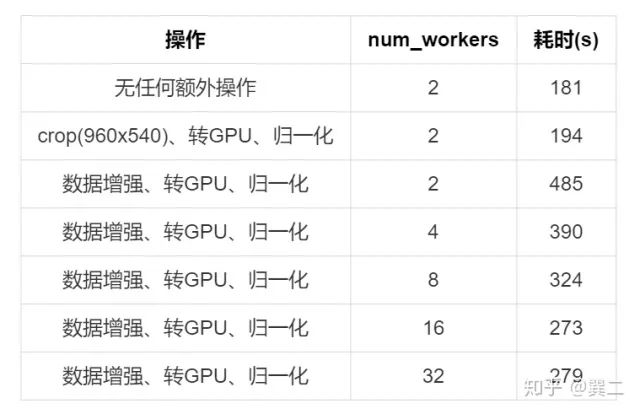
显然的是num_workers并不是越多越好,瓶颈在CPU,太多的数据worker不光不能提升,还会占用过多的CPU资源,影响其他程序的速度。
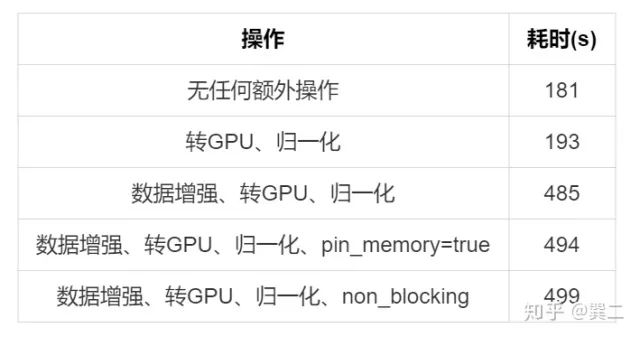
(2) pin_memory
定义DataLoader时单纯的pin_memory无用。

(3) non_blocking
谈到pin_memory就不得不说一下non_blocking=true操作,先来看一下过程吧:
1. x = x.cuda(non_blocking=True)
2. 进行一些和x无关的操作
3. 执行和x有关的操作
在non_blocking=true下,1不会阻塞2,1和2并行。但我们已经知道x.cuda()实际上耗时并不多(181s -> 194s,并不算是耗时的主要原因,就算去掉也不能加速太多。
一个比较常见的用法如下:
class DataPrefetcher(): def __init__(self, dataset, batch_size=64, shuffle=True, num_workers=2): self.data_loader = DataLoader( dataset=dataset, batch_size=batch_size, shuffle=shuffle, pin_memory=True, num_workers=num_workers, drop_last=True) self.loader = iter(self.data_loader) self.stream = torch.cuda.Stream() self.preload()
def preload(self): try: self.next_x, self.next_y = next(self.loader) except StopIteration: self.loader = iter(self.data_loader) self.next_x, self.next_y = next(self.loader) with torch.cuda.stream(self.stream): self.next_x = self.next_x.cuda(non_blocking=True) self.next_y = self.next_y.cuda(non_blocking=True) self.next_x = self.next_x.permute(0, 3, 1, 2).float().div(255) self.next_y = self.next_y.float()
def next(self): torch.cuda.current_stream().wait_stream(self.stream) data = (self.next_x, self.next_y) self.preload() return data
DataPrefetcher对DataLoader又包了一层,需要注意pin_memory=True时non_blocking=true才才生效,next()函数直接返回data而无需等待cuda()。实验结果如下,和预期的差不多,并无明显的改善。
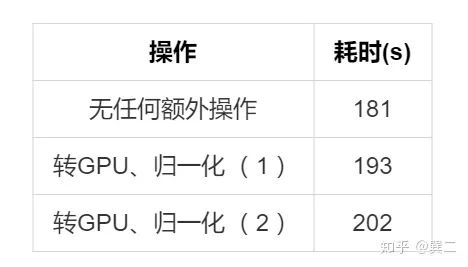
说到cuda(),有个小细节需要注意:
1. x = x.cuda().permute(0, 3, 1, 2).float().div(255)2. x = x.permute(0, 3, 1, 2).float().div(255).cuda()
这两种方式的耗时是不一样的
4. 读取图片
读取图片实际上包括了两部分,一个是图片数据读进内存,一个是图片的解码。耗时主要在图片的解码上,常见的优化方法主要是转换图片的格式(如lmdb)、使用解码更快的库。
(1) lmdb 先分析一下lmdb,一个jpg转lmdb的例子:
import numpy as npimport cv2import osimport lmdb
list_path = "img_list/test.txt"img_root = './data/test/edu/test/JPEGImages'img_type = ".jpg"label_root = './data/test/edu/test/labels'label_type = ".txt"
env_db = lmdb.open("./test", map_size=1024*1024*1024*8)txn = env_db.begin(write=True)
for line in open(list_path): img_name = line.strip() + img_type img_path = os.path.join(img_root, img_name) img = cv2.imread(img_path)
label_name = line.strip() + label_type label_path = os.path.join(label_root, label_name) label = np.loadtxt(label_path).reshape(-1, 5)
print(img_name)
# txn.put(img_name.encode(), img) ### 不编码 txn.put(img_name.encode(), cv2.imencode('.jpg', img)[1]) txn.put(label_name.encode(), label)
txn.commit()env_db.close()
使用cv2.imencode('.jpg', img)对图片数据进行了编码,不然会非常大,840张图片jpg大小为350MB,lmdb不编码为4.86GB。
这里插一句,lmdb文件大小为实际使用大小且小于map_size,但window下生成lmdb大小不正常为map size大小,读取一下后会变成实际大小。
读取的操作如下:
img = np.frombuffer(self.txn.get(img_path.encode()), dtype=np.uint8)
img = cv2.imdecode(img, cv2.IMREAD_COLOR)
label = np.frombuffer(self.txn.get(label_path.encode())).reshape(-1, 5) #lmdb存储后numpy会丢失形状
实验结果如下:
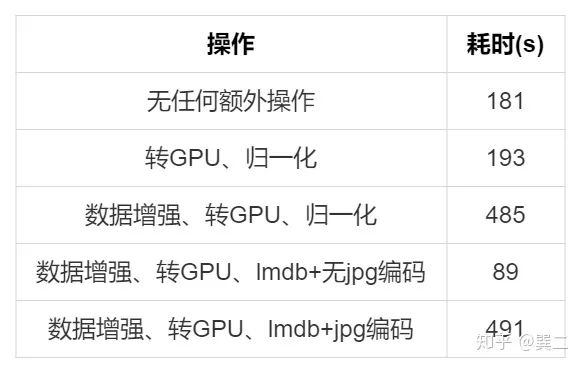
使用lmdb并没加速效果,实际上IO读取无任何优势,只是无解码时省掉了解码时间,但空间占用太多。
(2) hdf5
和lmdb类似的是hdf5,不压缩同样很大(4.86GB),但使用起来感觉较方便但存在一些bug不建议使用:
f = h5py.File('test.h5', 'w')img_dataset = f.create_dataset('img', shape=(840, 1080, 1920, 3), maxshape=(None, 1080, 1920, 3), chunks=(1, 1080, 1920, 3), dtype=np.uint8)for i, line in enumerate(open(list_path)): img_name = line.strip() + img_type img_path = os.path.join(img_root, img_name) img = cv2.imread(img_path) img_dataset[i, :] = img print(img_name, img.shape)f.close()
### read,h5的多线程读写存在问题,使用压缩无法正常使用f = h5py.File('test.h5', "r", swmr=True)for i in range(840): img = f["img"][i, ...]
没有编解码,速度还是有优势的,同时也印证了瓶颈在解码上:
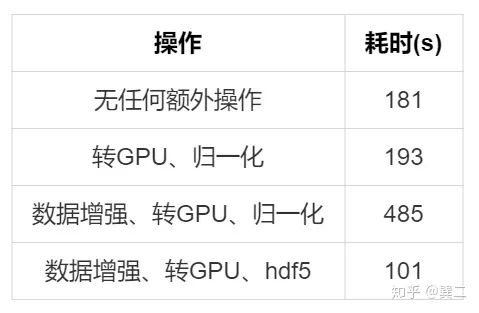
(3) libjpeg-turbo
解码更快的库,主要是使用libjpeg-turbo,分享两个python的封装,jpeg4py和PyTurboJPEG。比较推荐的是PyTurboJPEG,可以指定so位置和缩放图片。
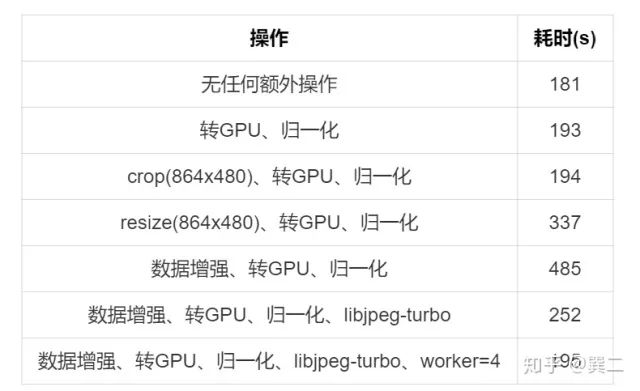
加速非常明显,推荐使用,但这个库比较吃CPU资源,worker开多之后会很卡。
(4) mxnet
mxnet的读取也测试了一下,测试时机器CPU占用发生变化,【数据增强、转GPU、归一化、libjpeg-turbo 】重新测试了一下,速度上无优势。

(5) opencv缩小比例读取
此外,opencv在读取图片时也可以指定缩小比例(1/2,1/4,1/8),提速明显,对部分需要固定缩放的比较友好:
img = cv2.imread(img_path, cv2.IMREAD_REDUCED_COLOR_2)
img = cv2.imread(img_path, cv2.IMREAD_REDUCED_COLOR_4)
img = cv2.imread(img_path, cv2.IMREAD_REDUCED_COLOR_8)
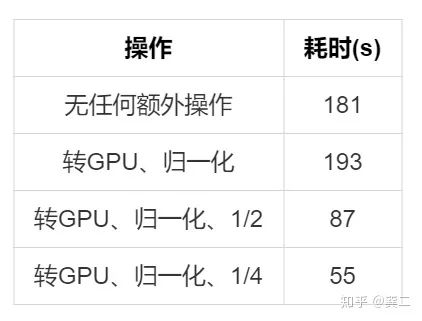
5. 数据增强
(1) 建议 这里先给大家一些建议:
-
opencv一般要比 PIL 快 -
由于数据增强操作基本是opencv的内置函数,因此cuda的@jit加速是无效的,Cython应该也无加速效果。几个操作的耗时排列应该是这样的,opencv <Cython <jit <pyhton。
-
cv2.UMat()加速几乎无效,测试与不使用无差别,本地测试单图反而比不使用耗时长。 -
由于图片数据为0~255,部分数值变换可以使用 cv2.LUT()查找表直接映射,避免多次计算数值。 -
尽量提前做好数据处理,减少预处理步骤。
(2) DALI 如果加速还不满意的话,最后还有一个大招,DALLI库,大力出奇迹,极度推荐。我们已经知道瓶颈在CPU的性能上,把这些计算放到GPU上是很合理的。NVIDIA DALI是一个GPU加速的数据增强和图像加载库,支持单个和批处理图像的解码、缩放、Crop、颜色空间转换等,具体支持的操作。
使用DALI完成所有操作的时间如下:

只要我数据加载的够快,GPU就追不上我。加载的部分和pytorch差不多,出来就是gpu的tensor,具体的代码较多,就不放在本文里了。
pipeline = DataPipeline(**dataset_dict)pipeline.build()loader = DALIGenericIterator(pipeline, ["imgs", "labels"], img_len, fill_last_batch=False)
for j in range(epoch): for i, data in enumerate(loader): x = data[0]["imgs"] y = data[0]["labels"].cuda() # train loader.reset()
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~



