一个更加强力的ReID Baseline
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:罗浩
https://zhuanlan.zhihu.com/p/61831669
本文已授权,未经允许,不得二次转载
旷视Video组 这个专栏是旷视科技北京研究院Video Team对外分享与交流的栏目,主要由Team leader @张弛、AlignedReID作者 @zhangxuan,PCB论文作者 @孙奕帆、Pytorch教程书作者廖星宇 @Sherlock以及 @罗浩.ZJU等人维护。如果有兴趣加入Video Team可以把简历发给zhangchi@megvii.com,具体方向包括但不限于ReID、Tracking、Activity Recognition、GAN以及网络压缩等等。第一期文章介绍我上个月做的一个工作,是一个非常强力的ReID Baseline,这个工作也被CVPR2019的TRMTMCT Workshop接收。
Bag of Tricks and A Strong Baseline for Deep Person Re-identification
arXiv:https://arxiv.org/abs/1903.07071
https://github.com/michuanhaohao/reid-strong-baseline
1、前言
行人重识别最近两三年发展十分迅速,每年都以10~15%的Rank1准确度在增长。当然快速发展的背后离不开Baseline的逐渐提高。早期的Baseline还比较低,大部分工作都在很低的Baseline上完成,因此准确度不高。而2017~2018这个时期,随着Pytorch框架的崛起,很多学者基于Pytorch框架开始调ReID的Baseline,因此性能也就越来越强(很多博士和博士生都做出了巨大贡献)。2018年暑期我和廖星宇师弟在旷视实习的时候,开源过一个GitHub项目,并且发布一篇知乎文章:一个强力的ReID basemodel
https://zhuanlan.zhihu.com/p/40514536
基于这个项目,我们最近这个项目进行扩展,完成一个更加强力的ReID Baseline。通过引入一些低消耗的训练Tricks,使用ResNet50的Backbone,这个Baseline在Market1501可以达到94.5%的Rank1和85.9%的mAP。当然使用更深的Backbone还可以继续提高性能。值得一提的是,和大量拼接多个local feature的方法取得高准确度的方法不同,我们只使用了一个global feature。目前代码已经开源了,欢迎学术界和工业界使用这个Baseline进行论文和产品的研究,comments are welcome!
https://github.com/michuanhaohao/reid-strong-baseline
2、背景
Baseline对于一个领域的研究起着非常重要的作用,但是我们观察最近一年顶会发表的ReID工作,发现论文之间Baseline的差距特别大。以Market1501为例,极少数工作在90以上的Baseline上开展,而大部分集中在80~90之间,甚至部分工作在80以下的Baseline上开展。而DukeMTMC-ReID更是没有一个Baseline超过了80的Rank1。我们都清楚,在低的Baseline上面方法涨点更加容易。另外不同的Baseline也很难统一比较不同方法的优劣性。基于这个因素考虑,我们觉得需要统一一个强力的Baseline。
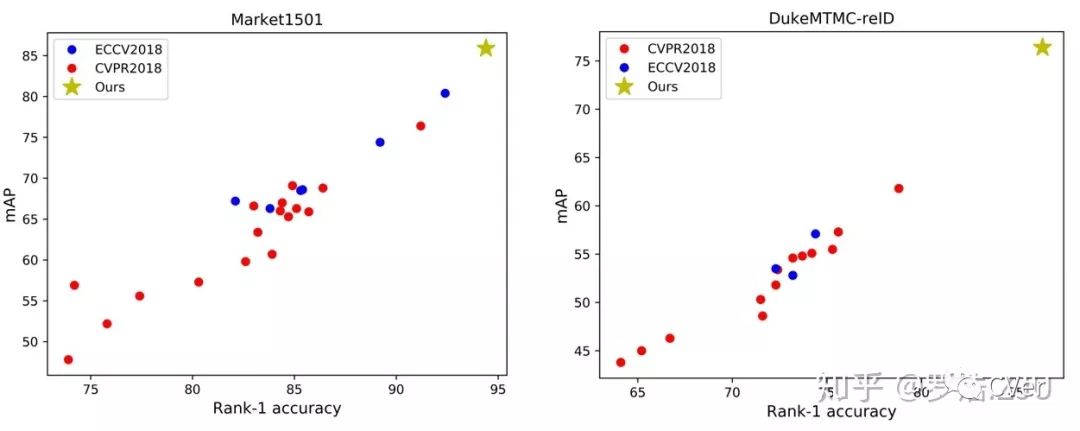
近一年顶会上ReID工作Baseline性能的统计。左图为Market1501数据集,右图为DukeMTMC-reID数据集。
另外我们发现在一些文章之后,会使用一些trick来提升模型的性能,但是在论文撰写过程中只是简单的轻描淡写一句甚至完全不写,最后阅读代码的时候才发现这些trick。然而对于一些资深的审稿人而言,通常都没有亲自运行过实验代码,因此这些trick容易“骗过”审稿人,让审稿人产生这个方法涨点很明显的错觉,然而可能大部分性能的提升是来源于trick而不是算法本身。
此外,最近出现了一些融合多个local feature达到很高性能的工作。我们不可否认,多尺度、多特征的融合本来也是CV领域很重要的一种思路。但是有了类似的工作之后,无意义地、暴力地融合大量的local feature的工作不应该再被会议期刊作为创新研究过度认可。这种工作一来无法给学界提供很有意义的insight,另一方面也并不是业界产品研发过程中喜欢的模型。融合大量的local feature,最后哪怕取得了很高的性能,也不过是“忽悠”外行人罢了。
综上我们做这个工作的目的有以下几个:
经过统计发现,最近一年顶会上发表工作的Baseline性能差异性很大,并且大部分处在很低的水平。因此我们希望统一一个强力的Baseline。
我们希望学术界的研究能够在这个Baseline进行扩展,这样能够早日把Market1501、DukeMTMC-reID数据集给刷爆。只有这些数据集刷爆了,学界才能意识到ReID应该进入下一阶段。
我们希望给社区的审稿人一些参考,哪些trick对模型的性能会产生重大的影响,审稿时应该考虑这些trick。
我们希望给业界提供一些训练trick,在很低的代价下提高模型的性能,加快产品研发的过程。
庆幸的是,过去几年我们在ReID研究过程中,收集了一些训练的trick。通过把这些trick引入到现有的Baseline上面,我们得到了一个强力的Baseline,以ResNet50位Backbone,最终在Market1501取得了94.5%的Rank1。当然,为了判断这些trick是在训练域上疯狂overfit,还是增加了模型的泛化能力,我们同时做了cross-domain实验。
3、Standard Baseline
首先我们来回顾一下标准的Baseline。通常我们使用ResNet50来Backbone,一个mini-batch包含了P个人的各K张图片,图片经过Backbone之后得到global feature,然后这个特征分别计算一个分类损失(ID loss)和一个triplet loss(batch hard mining)[1]。如果这个baseline调的好话,应该会接近90%的rank1水平。我们得到的结果是87.7%的rank1。

4、Our tricks
这一小节我们将会逐个介绍我们使用的trick,包括:Warmup学习率、随机擦除增广、Label Smoothing、Last Stride、BNNeck和Center loss。
(1) Warmup Learning
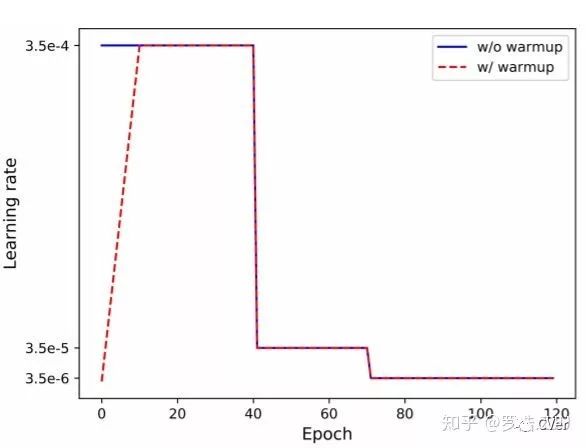
Warmup学习率并不是一个新颖的东西, 在很多task上面都被证明是有效的,在我们之前的工作[1]中也有过验证。标准Baseline使用是的常见阶梯下降型学习率,初始学习率为3.5e-4,总共训,120个epoch,在第40和70个epoch进行学习率下降。用一个很大的学习率初始化网路可能使得网络震荡到一个次优空间,因为网络初期的梯度是很大的。Warmup的策略就是初期用一个逐渐递增的学习率去初始化网络,渐渐初始化到一个更优的搜索空间。本文使用最简单的线性策略,即前10个epoch学习从0逐渐增加到初始学习率。
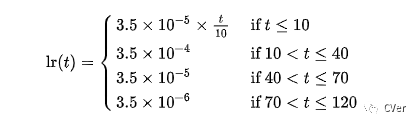
(2) Random Erasing Augmentation
Random Erasing Augmentation(REA)[2]是一种随机擦除的数据增广方法。简单而言就是在图像中随机选择一个区域,打上噪声mask。这个mask可以是黑块、灰块也可以是随机正太噪声。直接看图就能明白,具体细节可以看论文。所有参数都是直接利用原论文的参数。随机擦除是一种数据增广的方式,可以降低模型过拟合的程度,因此可以提升模型的性能。

(3) Label Smoothing
标签平滑(LS)是论文[3]提出的一种方法,应用于分类任务。传统的分类任务用的是交叉熵损失,而监督label用的是one-hot向量。因为交叉熵是相对熵在one-hot向量前提下的一种特例。但是one-hot是一种很强的监督约束。为了缓和label对于网络的约束,LS对标签做了一个平滑:
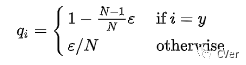
举个例子,加入原始的label是[0,0,1,0,0,0],平滑参数设置为0.1,则平滑之后的label就会变成[0.02,0.02,0.9,0.02,0.02,0.02],计算损失时由交叉熵换回原始的相对熵。经过标签平滑之后,网络的过拟合程度也会被抑制一点。
(4) Last Stride
ResNet50 Backbone的每个block最后一层conv都会有一个下采样的过程,即最后一层conv的stride=2。正常输入一张256×128的图像,网络会输出一个8×4的feature map。通常而言,增大尺寸一般是能够提升性能的。一个很简单的操作就是把最后一个conv的stride改为1,我们把这个stride叫做last stride。这个操作不需要增加任何的参数量,也不改变模型的参数结构,但是会把feature map尺寸扩大为16×8。更大的feature map可以提取到更加细粒度的特征,因此能够提升模型的性能。
(5) BNNeck
这是这篇文章的核心点。我们常用的Baseline通常会同时使用ID损失和triplet损失一起优化同一个feature。但是在大量前置的研究发现,分类损失其实是在特征空间学习几个超平面,把不同类别的特征分配到不同的子空间里面。并且从人脸的SphereFace [4]到ReID的SphereReID [5]等工作都显示,把特征归一化到超球面,然后再优化分类损失会更好。triplet loss适合在自由的欧式空间里约束。我们经常观察到,如果把feature归一化到超球面上然后再用triplet loss优化网络的话,通常性能会比不约束的时候要差。我们推断是因为,如果把特征约束到超球面上,特征分布的自由区域会大大减小,triplet loss把正负样本对推开的难度增加。而对于分类超平面,如果把特征约束到超球面上,分类超平面还是比较清晰的。对于标准的Baseline,一个可能发生的现象是,ID loss和triplet loss不会同步收敛。通常会发现一个loss一直收敛下降,另外一个loss在某个阶段会出现先增大再下降的现象。也就是说这两个task在更新的过程中梯度方向可能不一致。但是由于最终都能够收敛,所以可能容易引起大家的忽视,我相信应该不只是我们观察到过这个现象。
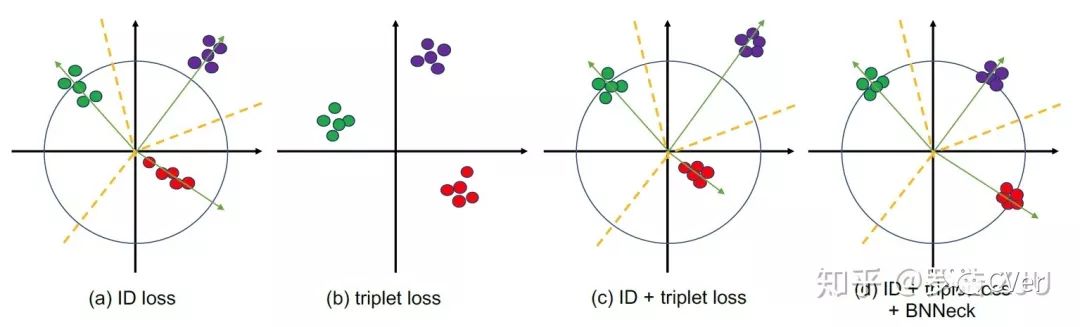
基于以上现象考虑,我们希望找个一种方式,使得triplet loss能够在自由的欧式空间里约束feature,而ID loss可以在一个超球面附近约束feature,于是乎就出现了以下的BNNeck。BNNeck的原理也很简单,网络global pooling得到的feature是在欧式空间里的,我们直接连接triplet loss,我们把这个feature记作 

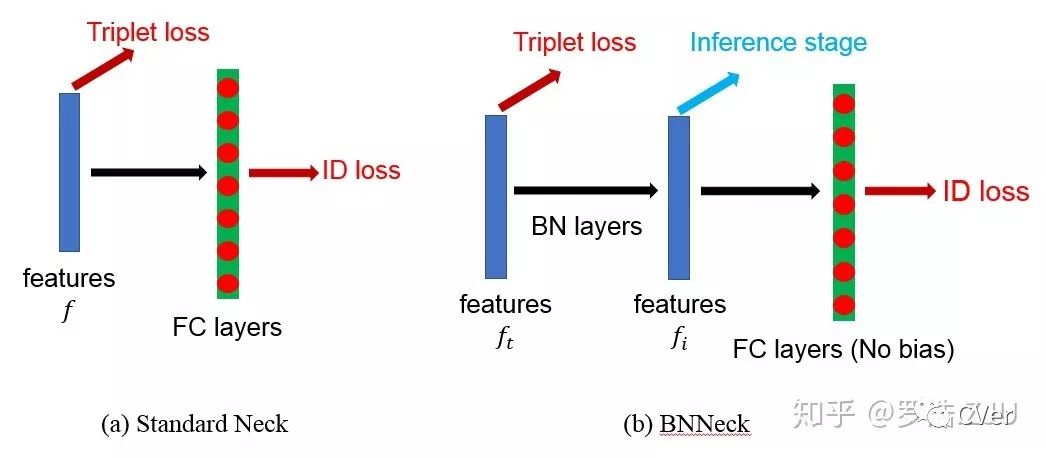
(6) Center Loss
Triplet loss有个缺点是只考虑了相对距离,其loss大小与正样本对的绝对距离无关。举个例子,假如margin=0.3。正样本对距离是1.0,负样本对是1.1,最后loss是0.2。正样本对距离是2.0,负样本对是2.1,最后loss还是0.2。为了增加正样本之间的聚类性能,我们加入了Center loss:

由于ReID现在的评价指标主要是cmc和mAP,这两个都是检索指标,所以center loss可能看上效果不是那么明显。但是center loss会明显提高模型的聚类性能,这个聚类性能在某些任务场景下是有应用的。比如直接卡阈值区分正负样本对tracking任务。
当然center loss有个小trick就是,更新网络参数和更新center参数的学习率是不一样的,细节需要去看代码,很难说清楚。
(7) Modified Baseline
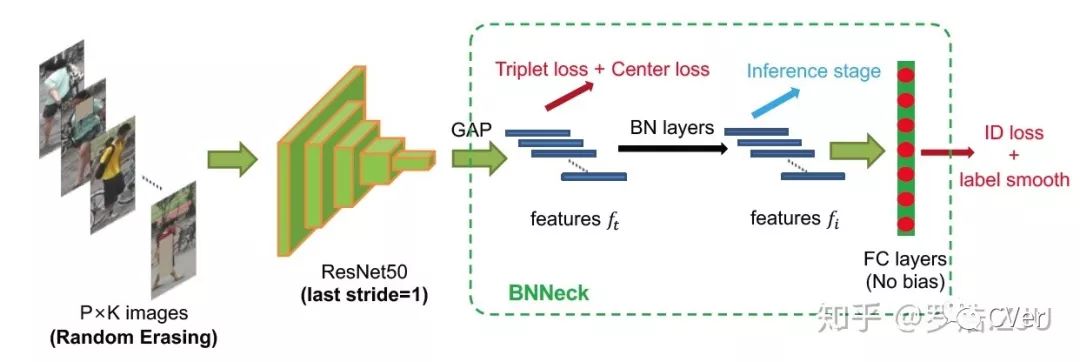
通过引入前文的各种trick,我们的Modified Baseline就如上图所示。输入的图像经过REA数据增广,然后经过ResNet50网络,last stride改为1。然后经过BNNeck,由于center loss也是一种metric loss,所以和triplet loss一起放到BN前面。最后分类损失结合LS一起计算。整个网络使用warm up学习率去优化。
5、实验结果
(1) Influences of Each Trick (Same domain)
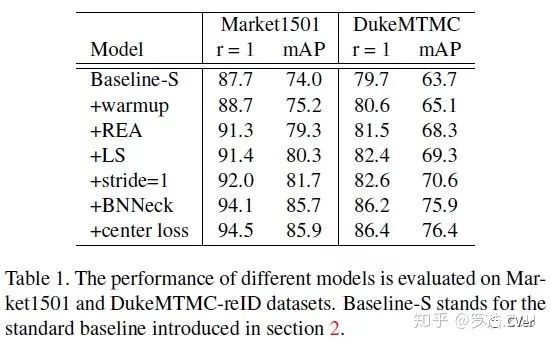
我们在Market1501和DukeMTMC-ReID上面分别测试了每个trick的效果,这个结果是在同数据集上训练测试的。具体数字就叙述了,每个trick都能涨点,其中REA、BNNeck涨点是比较明显的。
(2) Analysis of BNNeck
我们同样分析了一下BNNeck的结果,对于BN层前后的

(3) Influences of Each Trick (Cross domain)
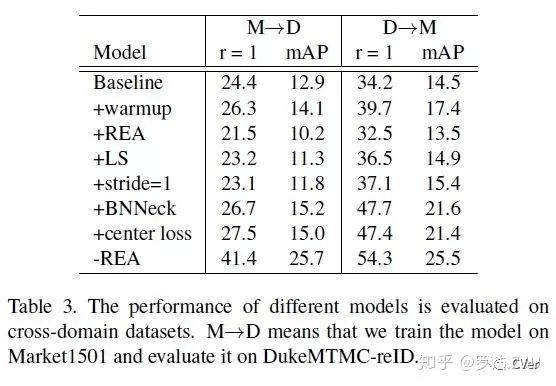
为了观察这些trick是在训练域上overfit了,还是真正的增加了网络的泛化能力,我们还做了cross domain的实验。即在一个数据集上训,在另外一个数据集上测。结果显示REA会大大的降低跨域的性能,其他的trick都还是有一定程度的涨点的。最后我们删除REA,只使用其他五个trick,M→D的结果达到了41.4的rank1。目前M→D的SOTA方法也就50左右的水平,这已经是个不错的Baseline了。当然也值得深思,为什么REA数据增广会降低跨域性能。
(4) Comparison of State-of-the-Arts
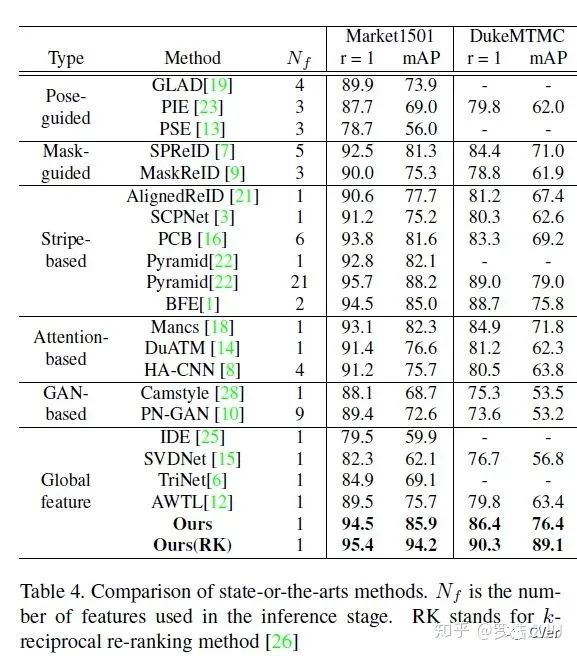
我们把Baseline的结果直接和SOTA的方法进行比较,除了少数几个能够达到95+的结果以外,没有任何方法的结果能够超越我们。值得一提的是,我们仅仅使用一个简单global feature,加了一层BN而已。目前主流能够达到93+的方法都concatenate多个local feature。腾讯的金字塔结构更是融合21个不同尺度的local feature。在所有只使用一个global feature的方法里,我们的性能是大大领先的。而且我们的训练代价非常小,就是加了一些trick而已。(所以也验证了深度学习领域的那句名言:天下万物,多为调参?)
(5) Batch & Image Size
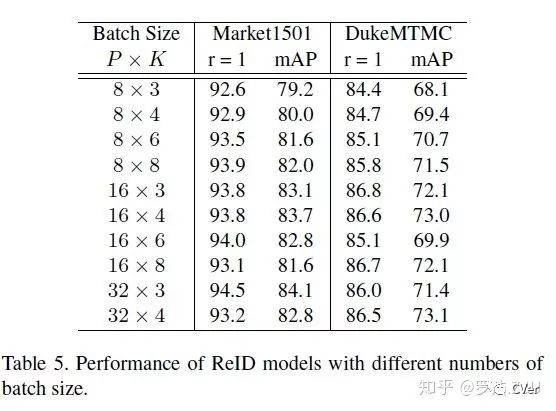
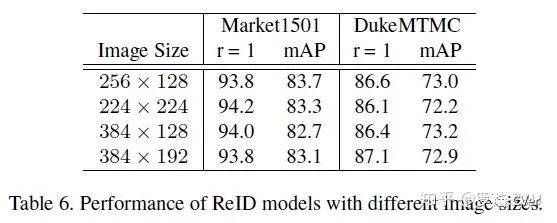
我们发现不同论文中的batch size和image size都不一样,因此我们也测试了这两个参数的影响。结果如下,简单的概括一下就是:Batch size呈现一种大batch效果更好的趋势,但是不是特别明显;而Image size对于global feature性能没有太大的影响。
我们推测是,batch越大,batch hard mining挑选的样本也就越难,因此网络性能越好。而训练图像的尺寸是128×64,不管你用多大的image size,都不增加额外的信息。所以只要大于128×64,image size就对性能没有太大的影响。
(6) Backbone
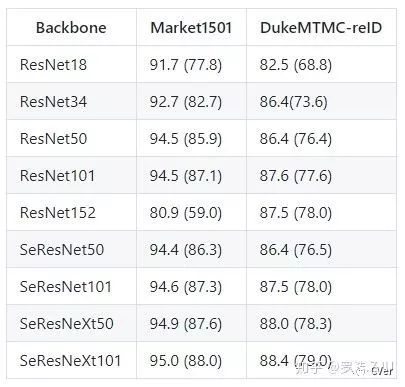
在我们开源了代码之后,有好心人帮我们扩展了Backbone,包括ResNet、SENet、SeResNet等等。大致结果呈现网络越深,效果越好,这也符合正常的结论。其中SeResNeXt101取得了95%的rank1和88%的mAP,基本已经相当高了。ResNet152在Market1501上有点反人类,可能是数据集太小,并且比较简单,所以overfit了吧。
6、结语
这篇论文给出了一个强力的Baseline,我们不希望这个工作成为一种暴力刷点的工作,而是希望这个Baseline能够促进ReID领域的发展。无论是学术界还是工业界,只要能够使用这个Baseline做有用的研究或者产品,我们就觉得这个工作是有意义的。
这个工作离不开 @古有志、 @Sherlock、 @小赖sqLai等一起付出。
这个工作是我和师弟们在寒假跑了几百组实验总结出的结果,另外mxnet版本可以看小赖的文章小赖sqLai:如何基于gluon训练一个强有力的Reid Baseline。
https://zhuanlan.zhihu.com/p/42345854
最后说一点个人的看法,ReID这两年发展这么快,但是比起人脸技术而言,落地的应用少了太多。其实并不是ReID的模型不够好,不是数据集上准确度不够高,而是比起人脸任务,ReID的场景更加复杂,有一些本质的问题没有解决。最简单最迫切的,遮挡问题和不可见光的问题。遮挡问题可以使得几乎现有所有的ReID模型失效,而结构光的人脸识别准确度也还不错。但是基于不可见光的ReID,那只能说是惨不忍睹。业界的数据资源开源不出来,学界的拿不到数据就做不了研究,这也是目前学界和业界研究有点脱离的一个因素。我个人呼吁有志于入坑ReID研究的人,不妨多从实际落地的角度思考,到底哪些是阻碍ReID应用的问题。针对这些硬核问题,去做有挑战的研究。Market1501差哪几个百分点真的不是特别重要。
当然我们会抽空继续维护我们的项目,也欢迎大家给我们提供trick、改进、意见或者是指正批评,同时欢迎Valse2019和CVPR2019现场交流,comments are welcome!
参考
[1] Hermans, Alexander, Lucas Beyer, and Bastian Leibe. "In defense of the triplet loss for person re-identification."arXiv preprint arXiv:1703.07737(2017).
[2] Zhong, Zhun, Liang Zheng, Guoliang Kang, Shaozi Li, and Yi Yang. "Random erasing data augmentation."arXiv preprint arXiv:1708.04896(2017).
[3] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
[4] Liu, Weiyang, Yandong Wen, Zhiding Yu, Ming Li, Bhiksha Raj, and Le Song. "Sphereface: Deep hypersphere embedding for face recognition." InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 212-220. 2017.
[5] Fan, Xing, Wei Jiang, Hao Luo, and Mengjuan Fei. "Spherereid: Deep hypersphere manifold embedding for person re-identification."Journal of Visual Communication and Image Representation (2019): 51-58.
CVer Re-ID交流群
扫码添加CVer助手,可申请加入CVer-Re-ID交流群。一定要备注:Re-ID+地点+学校/公司+昵称(如Re-ID+上海+上交+卡卡)

▲长按加群
这么硬的资料集锦,麻烦给我一个好看

▲长按关注我们
麻烦给我一个在看!


