Microsoft Icecaps:一个用于会话建模的开源工具包

作者 | Vighnesh Leonardo Shiv
8 月 29 日,我们正式发布了智能会话引擎 Icecaps,这是一个新的开源工具包,它不仅允许研究人员和开发人员赋予聊天机器人不同的角色,而且还集成了强调会话建模的其他自然语言处理功能。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
Icecaps 提供了来自最新会话建模文献的一系列功能。其中一些工具是由微软研究院最近的工作推动的,包括个性嵌入、基于最大互信息的解码、知识基础,以及一种强化共享特征表示结构的方法,从而实现更多样化更相关的响应。我们的库在一个模块化框架中利用了 TensorFlow,该框架旨在使用户能够轻松地使用多任务学习构建复杂的训练配置。在接下来的几个月里,我们将为 Icecaps 配备经过预训练的会话模型,研究人员和开发人员可以直接拿来用,也可以通过引导自己的系统快速适应新的场景。
Icecaps 的核心是灵活的多任务学习模式。在多任务学习中,多个任务之间共享一个参数子集,因此这些任务可以使用共享的特征表示。例如,该技术已被用于会话建模,将一般会话数据与非成对的话语组合起来;通过将会话模型与共享其解码器的自动编码器配对,就可以使用非成对数据来个性化会话模型。Icecaps 通过将大多数模型表示为组件链,并允许研究人员和开发人员使用共享组件构建任意复杂的模型配置,从而支持多任务学习。它还支持灵活的多任务训练调度,允许用户更改任务在训练过程中的权重。
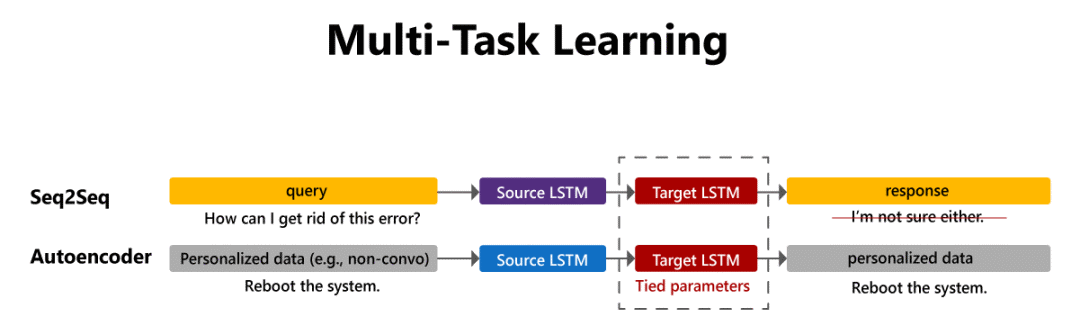
在多任务学习环境中,成对和非成对的数据可以在训练过程中进行组合。
此外,Icecaps 还实现了 SpaceFusion,这是一种专门的多任务学习范式,其初衷是联合优化生成的响应的多样性和相关性。SpaceFusion 增加了正则化项,形成了可在任务间共享的潜在空间。这些项可以更好地调整每个任务在这个潜在空间中习得的分布。
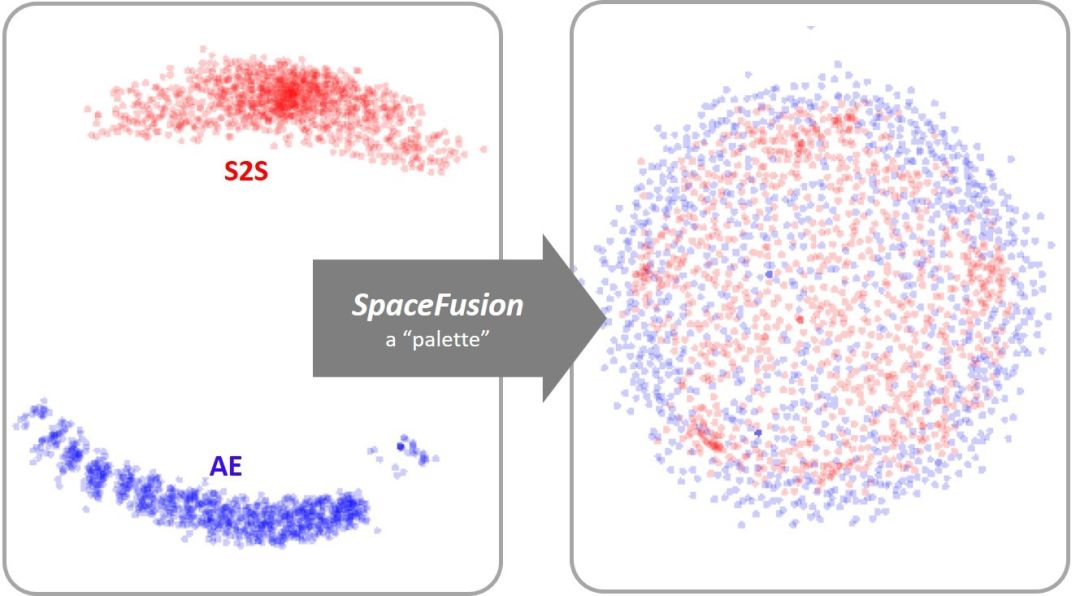
SpaceFusion 为多任务学习环境增加正则化项,结构化共享潜在空间,提高学习效率。
为了在会话场景中实现个性化,人工智能可能需要充当具有自己特定风格和属性的某个角色,Icecaps 允许研究人员和开发人员 使用个性嵌入在多对话者数据上训练多角色会话系统。个性嵌入与词嵌入的工作原理相似;正如我们学习每个单词的嵌入来描述单词在潜在单词空间中的相互关系一样,我们也可以从多对话者数据集中学习每个说话者的嵌入来描述潜在个性空间。多角色编解码器模型为解码器提供词嵌入的同时提供个性嵌入,在选定的个性上解码响应。
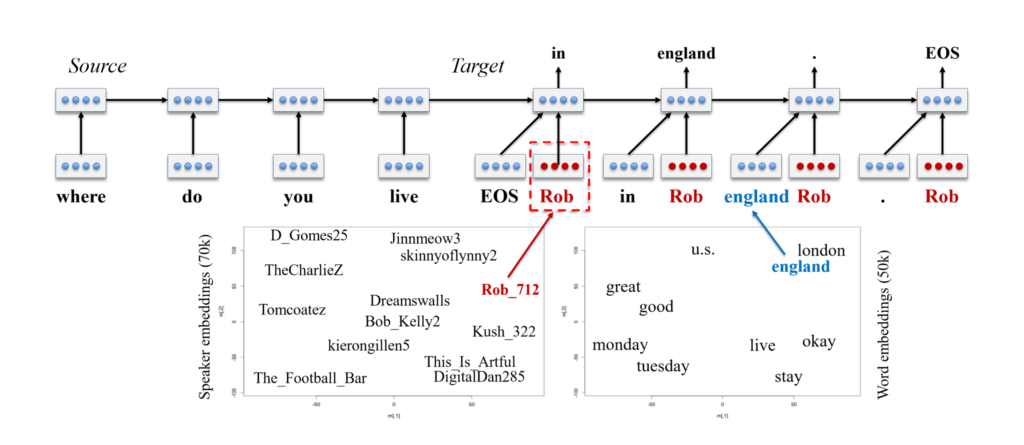
通过将单嵌入空间与角色嵌入空间相结合,个性化的序列到序列模型可以生成个性化的响应。
使用嘈杂的真实数据训练的会话系统往往会产生泛泛且乏味的回答,比如“我不知道你在说什么”。这些系统将这种行为作为一种安全的学习方式,从而始终产生与上下文相关的响应。付出的代价是响应的多样性和内容。解决这一问题的一种方法是 基于最大互信息(MMI)的假设重排。这种方法训练了第二个模型来预测给定潜在响应的上下文。这个模型为基本解码器生成的每个假设额外赋一个分数,这个额外的分数用于对假设集进行重新排序。MMI 获取对于给定上下文而言最有针对性的潜在响应,并将它们推到列表的顶部。除了其他一些解码功能外,作为其自定义定向搜索解码器的一部分,Icecaps 包含基于 MMI 的重新排序。
训练会话系统的主要瓶颈之一是缺少能够捕捉到世界上大量非会话数据中所包含的丰富信息的会话数据。因此,我们需要能够利用后者的好工具。例如,为了训练拥有维基百科或其他百科全书资源中包含的所有知识的智能代理,Icecaps 实现了一种以知识为基础的对话 方法,该方法结合了机器阅读理解和响应生成模块。该模型使用注意力将内容从与上下文相关的知识源中分离出来,从而使模型产生更明智的响应。
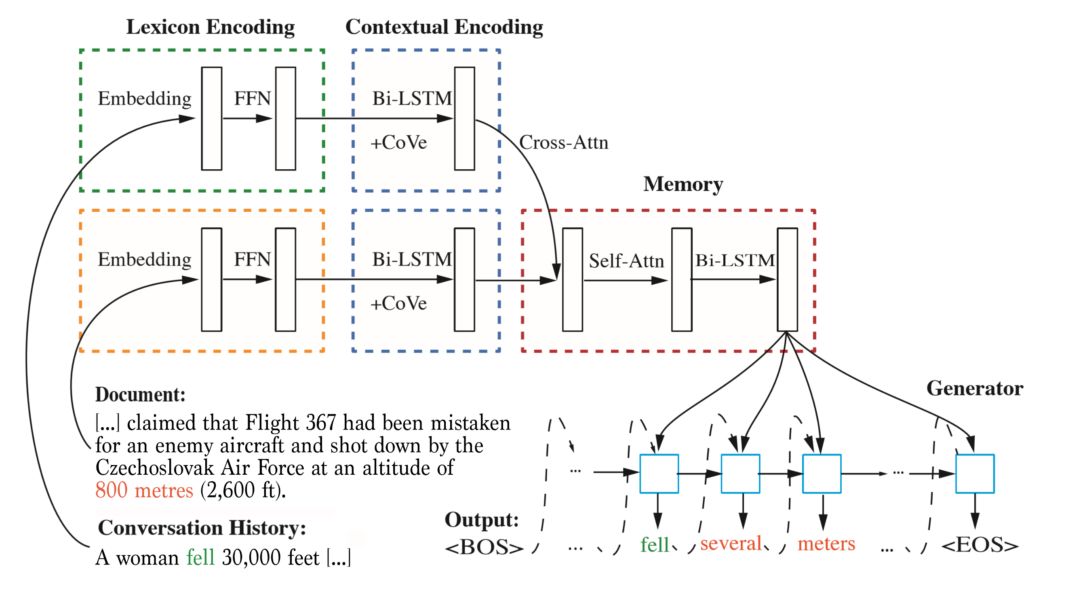
交叉注意力(Cross-attention)可用于从外部知识库中提取相关信息以生成响应。
开源项目链接:https://github.com/microsoft/icecaps
智能个性化聊天机器人只是会话建模的开始;内容过滤、多语言建模、混合会话和面向任务的功能都是有前景的新研究领域。微软将继续关注会话建模领域的发展,并利用 Icecaps 使研究人员和开发人员能够推动前沿科技的发展。
原文链接:
https://www.microsoft.com/en-us/research/blog/microsoft-icecaps-an-open-source-toolkit-for-conversation-modeling



