斗鱼大佬分享!基于图的团伙挖掘算法实践
来自公众号:极验

AI-Talking

嘉宾:王璐
编辑整理:萝卜兔
嘉宾简介
本期我们邀请到的分享嘉宾是来自斗鱼的算法工程师王璐,曾先后在阿里、斗鱼从事推荐、风控等方向的算法工作,目前致力于图算法在风控业务中的应用落地。
本次分享的主题是《基于图的团伙挖掘算法实践》,主要包括三个方面:
团伙定义和特点
团伙挖掘流程和方法
经验与总结
团伙的定义和特点
我们这里所指的团伙是网络中的黑产团伙,这些团伙主要从事网络上的薅羊毛,刷单等非法活动,和金融场景中的团伙定义还是有一些差别。主要特点表现为:
1、 团伙账号规模较大;
2、脚本或者软件操控;
3、每个账号一次恶意行为获利较少;
4、短时间行为频次高,账号之间具有同步性和聚集性。
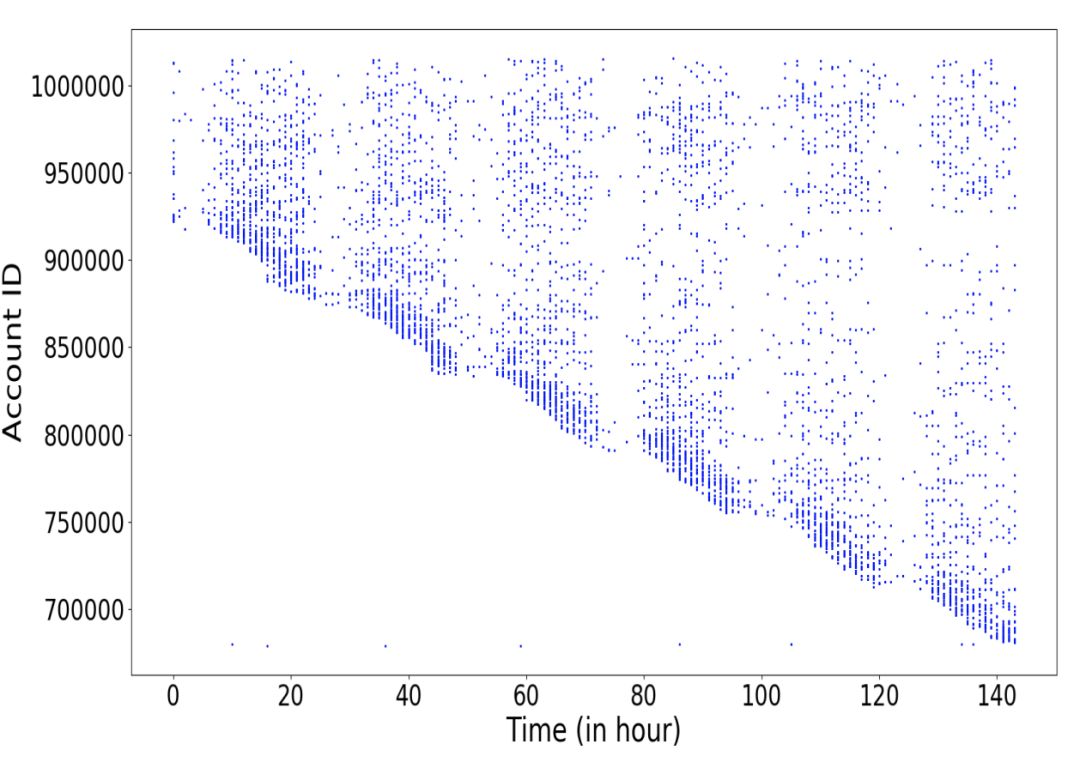
如上图所示,横轴是时间轴,纵轴是账户 ID,可以看到,有风险的账户在时间上面的聚集性是非常明显的,而正常账号的行为是比较分散的。
团伙挖掘流程和方法
建立关联关系
主要就是需要从业务实际出发,去建立一个有业务含义的图。这里的关联关系,可以是有向图,也可以是无向图,根据业务而定。不过,我们期望的图一般是有权重的,因为没有权重的图在后面做社区检测的时候,可能会不太好用。
如何建立关联关系呢?
建立关联关系的方法还是有很多的,这里我们简单的介绍几种。
使用资源的关联做图的构建
原理就是账号之间有一些资源会重复的使用,比如设备、IP、手机号码、身份证号码等。关联的方法很简单,比如说在某个时间窗口,某个账号使用了某一设备,我们就可以把两者关联起来。这时候可以构建一个二部图,节点就是账号和设备,边就是两者之间的关系。当然,也可以不构建二部图,比如两个账号使用了同一个设备,那么两个账号之间就有关联。
这种构图方法的缺陷是,黑产会伪造设备ID 以及使用 IP代理,这时候设备和 IP 的重用就变得很低了。还有一点是这个关联可能是有误的,比如一些网吧、机房等,这种有误的关联可能最终反应在误差上面。
采用行为同步性
黑产的特点是在短时间内有高频的行为,所以在非常短的时间间隔内,如果两个账号的行为非常趋同,那么可以在两个账号之间建立关联。构建的方法可以参考 Facebook 的论文《Uncovering Large Groups of Active Malicious Accounts in Online Social Networks》[1]
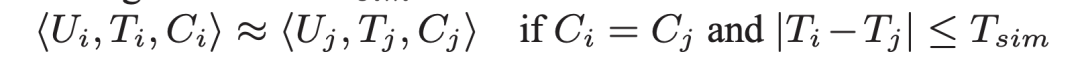
U是指账号,T是指行为发生的时间戳,C就是限制资源(两个账号有相同的行为,使用同一个 IP,或作用对象一致都可以作为限制资源),如果两个账号的行为的时间间隔小于 Tsim ,那么可以认为这两个行为是一致的。
我们可以通过上述的方式对账号与账号之间的相似行为的次数做统计,统计之后可以根据次数或者距离做关联。
这种方式建立关联需要注意的就是区分事件和时间段。
采用相似度
原理就是团伙账号之间他们在属性和行为上有很高的相似性。构建的方法就是构建账号之间的相似度,如果两个账号之间的相似度高于某阈值,则账号之间会形成一条边。这里最主要的问题就是计算相似度,有两种方法:
采用自定义的距离公式和权重,自己定义每个维度的计算公式和权重。
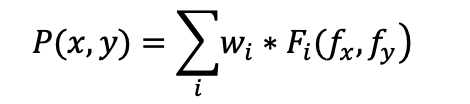
距离和权重过于依赖人工,难以确定,只有在计算维度较少时可以这样做。
另一种就是对账号进行Embedding,可以基于序列,也可以基于图结构,采用余弦距离计算相似度,这种方法更具有通用性。
若干弱的特征组合
原理就是团伙账号在一些弱信息上面具有一定的共性。构建的第一步需要抽取一些具有业务含义的属性或者指标,如果多个账号都满足这个指标,就把这些账号看成一个团体,然后采取一些社区分析的方法对团队进行分割成个个子簇,最后将子簇看成一个节点。这个图的节点就不是一个账号了,而是一个账号集合。然后再通过相似度等方法再来生成节点之间的关联关系。
这种方法需要有一个筛选的过程,特征的选取最好有一定的业务意义,并且具有一定的区分性。
上述四种就是常见的构图方法,完成了构图之后,就要进行团伙发现。
团伙发现
团伙发现我在这里主要讲两种方法,一是连通子图或强连通子图,二是 Graph Partition 。
连通子图
这种方法的优势是,在当前连接下可以得到的最大规模团伙。当建立的关系非常可靠(边相连的两个顶点是一个团伙的概率非常大)时,使用连通图查找就可以到达不错的效果
主要的问题是:
存在度数很高的节点,使得划分后某些社区规模很大,没有起到团伙挖掘的作用;
噪音数据会带来误杀,为了保证准确率会牺牲较多的覆盖。
解决上述问题的一些方法,可以参考论文[2]
Graph Partition
Graph Partition 的主要思想就是怎么样把图上的顶点进行切分。既然要切分就需要一个度量的准则,一般我们是希望切分之后,社区内部的节点之间关系比较紧密,社区内部与社区外部的节点之间联系比较稀疏。所以解决这个问题的一般方法就是定义一个优化目标。
两种处理方式,一种是图分割:

这两种是局部切分的度量准则,图分割划分的社区数量是要事先设定的,不太灵活,所以平时用的并不多。
第二种就是基于模块度(pModularity-based)的方法,主要思想就是定义一个全局的优化目标,采用启发式算法寻优。我们在这里讲两种:

参考论文[3][4]
我们可以根据自己的业务特点去定义合适的全局优化指标和社区合并条件。
团伙验证
我们发现团伙之后,需要去验证一下,看是否是真正的团伙。需要一个评价方法去评价团伙。评判的标准主要分为两个方面,一是嫌疑度,二是聚集性。
嫌疑度一般就是基于一些已有的经验,规则,看一下团伙中被识别为黑产的团伙占比有多少。团伙的规模也是一个很重要的指标,规模很大的化,是黑产的可能性就大。还有就是从图的基本统计指标入手,比如社区内部的 density,还有特殊形状的统计(三角形状,环状)等。
聚集性分析,一是看团体成员是否在某些属性或者行为上表现出了一致性,二是看团体整体的Profile 是否与团伙中已知黑账号的 Profile 类似。
经验与总结
对团伙要有业务上的认识,不是臆想出来的;通过具体的case分析,了解模式并制定相应的算法。
构建关联是团伙挖掘最核心的内容,节点和边的定义非常重要,抽象成图依赖于业务的理解。
团伙发现算法出来的结果可能不能直接使用,需要对团伙进行精修(合并、细分和剪枝)。
通过图算法挖掘出来的团伙,需要引入业务经验进行验证和定性。
互动问答
1. fraudar 和直接用社区发现找社区有什么区别?
回答:基于模块度的方法都是去直接定义一个最优化的指标,区别有两点,第一是定义的指标不一样,第二是寻优算法有差异,不过大体上的套路是长不多的。
2. 对于Fraudar算法,算法大体上采用贪心的算法串行的删节点并记录当前的密度指标,这种算法对于大数据集下有效吗?
回答:对于大数据来说,这种寻优的算法效率肯定是不高的,可以改成一些并行的算法。
3. 对于存在节点度长尾分布的场景,这些基于社区发现如何避免自然密集的簇导致的误判?
回答:这就是讲的团伙验证的内容,通过团伙验证可以对团伙的属性做一个评估,主要还是嫌疑性和聚集性两个方面。也可能会有单个节点的误判,这个就采取一些方法,把明显不同模式的节点剔除掉。
更多资源
[1] https://www.eecis.udel.edu/~ruizhang/CISC859/S17/Paper/p19.pdf
[2] https://www.usenix.org/legacy/events/nsdi09/tech/full_papers/zhao/zhao.pdf
[3] https://arxiv.org/pdf/0803.0476.pdf
[4] kdd.org/kdd2016/papers/files/rfp0191-wangAemb.pdf
回看链接戳原文阅读
●编号889,输入编号直达本文
●输入m获取文章目录

开源最前线


