【告别】李飞飞深情回顾ImageNet 8年:改变AI和世界的数据(PPT)
【新智元招聘】AI 盛夏,星舰启航。《新一代人工智能发展规划》发布之际,新智元也正式入驻融科资讯中心 B 座,整装待发。天时地利,星辰大海,我们召唤你——新船员的加入!COO、总编、主笔、内容运营、客户总监、客户经理、视觉总监(兼职) 7 大职位招聘全新启动。点击文末 阅读原文 查看详情。
简历投递:jobs@aiera.com.cn HR 微信:Dr-wly
1 新智元专访
来源:QZ
作者:Dave Gershgorn
编译:闻菲 熊笑
【新智元导读】今天,ImageNet 创始人李飞飞在 CVPR“超越 ILSVRC” workshop 介绍了最后一届 ImageNet。回顾过去 8 年,计算机视觉中一个最艰深的学术命题物体识别被攻克,神经网络和深度学习重新定义了人工智能的方法论。李飞飞在接受新智元采访时谈了这 8 年里她印象最深的两件事——在线众包平台 Amazon Mechanical Turk 的发现和深度学习的应用,前者令她意识到构建 ImageNet 大规模数据集的可行性,后者开启了深度学习乃至人工智能新的篇章。
在 CVPR 会议期间,计算机视觉期刊 IJCV 举办了 IJCV Asia Night 学术主题活动,李飞飞作为当晚嘉宾,对一些曾给予她帮助的朋友和同事表示了真挚的感谢,其中包括 UC 伯克利教授 Jitendra Malik,李飞飞称他是在 CV 和 AI 方面对她启发最大的人之一;UCLA 终身教授朱松纯,李飞飞认为他在计算机视觉领域的思考和研究对她也有巨大的启发;中国工程院、中国科学院外籍院士黄煦涛,李飞飞在 UIUC 获得的第一份教授职位在很大程度上得到了他的提携;微软全球执行副总裁沈向洋,他在李飞飞去谷歌时给出了很好的建议;普林斯顿大学的李凯,他在李飞飞开始做 ImageNet 时给予了巨大的鼓励和支持。另外,李飞飞特别提到了,她一共有 23 个学生和博士后是亚洲血统,他们来自中国、印度、日本、韩国、伊朗等等。李飞飞特别对她的两个学生邓嘉和李佳表示了感谢。李飞飞引用了蜘蛛侠的名言“能力越大,责任越大”,指出人工智能工作者重任在肩。李飞飞同时指出,中国是世界上第一个发布人工智能白皮书的国家,领先于美国、英国和所有业界力量看到人工智能的潜能。李飞飞引用了现代哲学家 Shannon Vallor 的话作为她分享的结束语:机器没有独立的价值观,机器的价值观就是人类的价值观。
如今看,ImageNet 及其竞赛的重要性已经不言而喻,但实际上,从更长的周期看,ImageNet 系列工作对计算机视觉、机器学习、人工智能乃至人类进步的影响都更为巨大——ImagNet 数据集让人们意识到,构建优良数据集的工作是 AI 研究的核心,数据和算法一样至关重要。ImageNet 开源开放的原则也代表了 AI 研究的根本,我们需要让所有人都参与开发更好的 AI 算法和模型。
本文后附李飞飞今天在最后一届 ImageNet workshop 的演讲 PPT。

2006 年,李飞飞开始反复思考一个问题。
当时的李飞飞才刚刚在伊利诺伊大学香槟分校(UIUC)任教,她看到整个学界和工业界普遍流行一种想法,都在致力于打造更好的算法,认为更好的算法将带来更好的决策,不论数据如何。
但李飞飞意识到了这样做的局限——即使是最好的算法,如果没有好的、能够反映真实世界的训练数据,也没办法用。
李飞飞的解决方案是:构建一个更好的数据集。
“我们决定我们想做一件史无前例的事情,”李飞飞说,这里的“我们”指的是最初与她合作的一个小团队。“我们要详细描绘出整个世界的物体。”
由此生成的数据集名叫 ImageNet。相关论文发表于 2009 年,最初作为一篇研究海报在迈阿密海滩会议中心的角落展示出来。但没过多久,这个数据集就迅速发展成为一项年度竞赛,衡量哪些算法可以以最低的错误率识别数据集图像中的物体。 许多人都认为 ImageNet 竞赛是如今席卷全球 AI 浪潮的催化剂。
ImageNet 竞赛的历届参赛成员散布在科技界的每一个角落。2010 年比赛第一名的获奖者,之后依次在百度、谷歌和华为担任要职。2013 年 ImageNet 获奖者 Matthew Zeiler 根据他的获奖方案建立了 Clarifai,现在得到了 4000 万美元的风险投资支持。2014 年,来自牛津大学的两名研究人员和谷歌共同获得了 ImageNet 竞赛,他们迅速被吸收然后加入了 DeepMind。
李飞飞现在是谷歌云的首席科学家、斯坦福大学教授,斯坦福 AI 实验室的主任。
今天,她在 CVPR 上介绍 2017 年 ImageNet 的成果——而 2017 年是比赛的最后一年。在短短 7 年时间里,物体分类冠军的精确度从 71.8% 上升到 97.3%,超越了人类物体分类水平,也有力证明了更大的数据会带来更好的决策。
就算 ImageNet 竞争结束,其遗产已经形成。自 2009 年以来,在计算机视觉、自然语言处理和语音识别等子领域,研究人员也引入了几十种新的 AI 研究数据集。
“ImageNet 思维所带来的范式转变是,尽管很多人都在注意模型,但我们要关心数据,”李飞飞说:“数据将重新定义我们对模型的看法。”
在 20 世纪 80 年代后期,普林斯顿心理学家乔治·米勒(George Miller)创建了一个名为 WordNet 的项目,旨在建立一个英语层级结构。WordNet 像字典一样,但其中单词会被显示为与其他单词相关的形式,而不是依照字母顺序排列。例如在 WordNet 中,“狗”这个词将被嵌套在“犬”这个类别下,而“犬”又被嵌套在“哺乳动物”下,以此类推。这是按照机器可读的逻辑组织的语言的一种方式,WordNet 积累了超过 155,000 个有索引的单词。
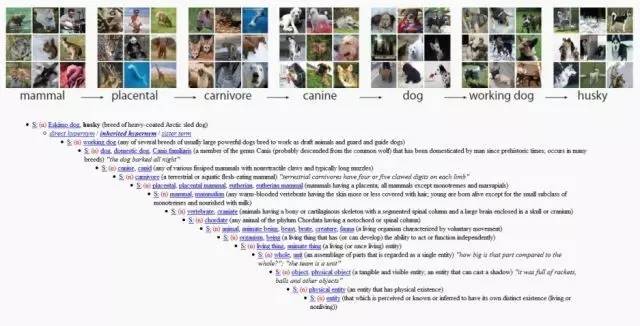
李飞飞在 UIUC 的第一份教学工作中,一直在努力解决机器学习中的一个核心矛盾:过拟合和泛化。过拟合就是指算法只能处理与之前见过的数据类似的数据;变化稍微大一点的问题就不能理解。另一方面,如果一个模型无法在数据之间找到正确的模式,那么它就属于 overgeneralizing。
李飞飞说,要找到完美的算法似乎还很遥远。她发现以前的数据集并没有反映出世界的多变,就连只是识别猫的图片都是件无限复杂的事情。但是,通过给算法更多的样本,向算法展示世界是多么复杂,算法在数学意义上对现实有了更好的理解。如果你只看 5 张猫的照片,那么你只知道这 5 个摄像机角度、照明条件和最多 5 种不同种类的猫。但是,如果你看过 500 张猫的照片,你就能从更多的例子中发现共同点。
李飞飞开始阅读其他人如何构建数据集对世界进行真切表示的文献。在这个搜索的过程中,她发现了 WordNet。
看过 WordNet 的方法后,李飞飞在 2006 年访问普林斯顿期间,见到了 Christiane Fellbaum 教授,后者在持续构建 WordNet 方面有很大的影响力。Fellbaum 认为,WordNet 可以可以让每个单词都有一张相关联的图像,更多地作为参考而不是一个计算机视觉数据集。这次会见后,李飞飞产生了一个更宏大的想法——一个大规模的数据集,每个单词都有很多张图像例子。
几个月后,李飞飞加入了她的母校普林斯顿大学任职,并于 2007 年初开始从事 ImageNet 项目。她开始建立一个团队来做这件事情,首先找到了同校的 Kai Li 教授,后者说服博士生 Jia Deng 转入李飞飞的实验室。Jia Deng 一直参与 ImageNet 项目,直到 2017 年。
“对我而言,这显然与其他人正在做的事情有很大的不同,与其他人当时关注的焦点有很大不同。” Jia Deng 说:“我很清楚地知道这将为整个视觉研究带来改变,但我不知道具体会如何改变。”
ImageNet 数据集中的物体(对象)将覆盖实物(如大熊猫或教堂)到抽象概念,比如爱情。
李飞飞首先想到雇用本科生,10 美元一小时,手动查找图像并将其添加到数据集中。但简单的数学很快就让李飞飞意识到,以本科生收集图像的速度,项目需要 90 年才能完成。
在本科生工作团队解散后,李飞飞和她的团队又开始重新思考。如果让计算机视觉算法从互联网上收集照片,人类只负责标注呢?但经过数月修改算法后,团队得出的结论,这种方法也不可持续——当使用这种方法构建的数据集弄好以后,未来的算法将只能判断算法能够识别的图像。
本科生耗费时间,算法有缺陷,团队没有钱——李飞飞说,项目不仅没有赢得任何联邦拨款,还收到很多负面评论,称普林斯顿研究这课题太浪费(shameful),项目申请唯一可以称道的点就是李飞飞是女人。
最终,李飞飞在跟研究生闲聊的时候意外浮现出了一个解决方案。这个研究生问李飞飞有没有听说过 Amazon Mechanical Turk,这项服务让世界各地坐在电脑前的人完成一小笔小笔的在线工作。
“他向我展示了网站,就是那一天,我知道 ImageNet 项目一定能成功,”李飞飞说:“突然间,我们发现了一个可以扩展的工具,这是招聘普林斯顿的大学生完全不能想象的。”
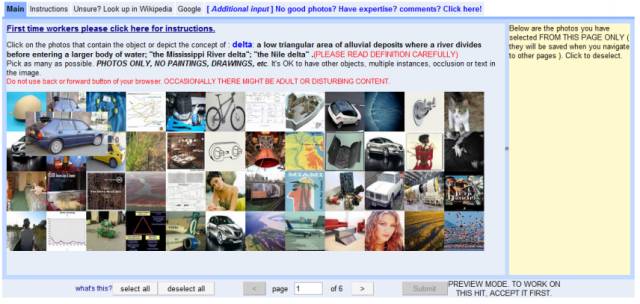
众包平台 Mechanical Turk 本身也带来了一大堆问题,其中许多工作都是由李飞飞的两名博士生学生,Jia Deng 和 Olga Russakovsky 完成的。例如,每张图像需要多少个众包工人来看?也许两个人就能确定一只猫是一只猫,但是一张微型哈士奇的图片可能需要 10 轮验证。如果一些众包工人胡乱标注怎么办?李飞飞的团队最终为众包工人的行为创建了一批统计模型,帮助确保数据集只包含正确的图像。
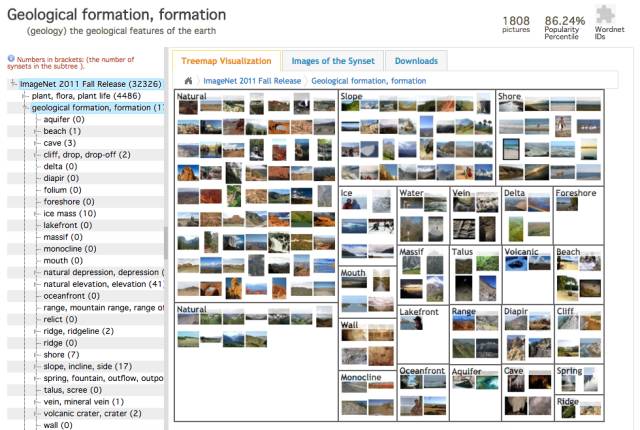
即使在发现 Mechanical Turk 这个平台后,数据也花了两年半的时间才完成。ImageNet 数据集由 320 万个标记图像组成,分为 5,247 个类别,归到 12 个子例里,比如“哺乳动物”,“车辆”和“家具”。
2009 年,李飞飞和她的团队发表了 ImageNet 数据集的论文,基本没有引发什么反响。李飞飞回忆说,计算机视觉研究领域的顶级会议 CVPR,只给了那篇论文一张海报展示(poster)的位置,而不是口头介绍(oral)。李飞飞和她的团队在会场发带有 ImageNet 字样的笔来吸引人们的兴趣。当时的人都很怀疑他们更多的数据有助于开发更好算法的看法。
“当时有人说‘如果你连一个物体都做不好,为什么要做上千乃至上万个呢?”Jia Deng 说。
如果数据是新的原油,那么在 2009 年,它还处于恐龙化石的形态。
2009 年晚些时候,在京都举行的计算机视觉会议上,一位名叫 Alex Berg 的研究员找到李飞飞,建议在比赛中增加一个命题,让算法找到图片中物体(对象)所在的位置,而不仅仅说图中有这么个东西。李飞飞回应说:那你来和我一起工作吧。
于是,李飞飞、Berg 和 Deng 一起,根据数据集撰写了 5 篇论文,探讨了算法如何解释这样大量的数据。第一篇论文后来成为如何处理几千种图像的基准,这也是 ImageNet 竞赛的前身。
对于这第一篇论文,李飞飞说,“我们意识到要把这个想法推广出去,我们需要找到更多人。”
然后,李飞飞联系了欧洲知名图像识别大赛 PASCAL VOC,后者同意与 ImageNet 合作,在宣传 ImageNet 竞赛时带上他们的名字。PASCAL 是业界知名的竞赛和数据集,但代表的是以前的思维方式。这个数据集只有 20 个类别,而 ImageNet 的这个数字是 1000。
随着 ImageNet 在 2011 年和 2012 年连续举办,它很快成为图像分类算法在处理当时最复杂视觉数据集时的基准。
不仅如此,研究人员也开始注意到更多的事情,不仅仅是竞赛——他们的算法在使用 ImageNet 数据集训练时表现更好。
“令人惊喜的是,你可以用在 ImageNet 上训练的模型启动其他识别任务。你从 ImageNet 模型开始,然后微调来进行另一个任务,”Berg说:“这是神经网络的突破,也是整个视觉识别的突破。”
在第一次 ImageNet 竞赛的两年后,2012 年,发生了一件更大的事情。事实上,如果我们今天看到的人工智能繁荣可以归功于一个事件,那么这件事就是 2012 年 ImageNet 竞赛结果的公布。
多伦多大学的 Geoffrey Hinton,Ilya Sutskever 和 Alex Krizhevsky 提交了一个名为 AlexNet 的深度卷积神经网络架构——至今仍在研究中使用——实现了准确率 10.8% 的大幅提升,高出第二名 41%。
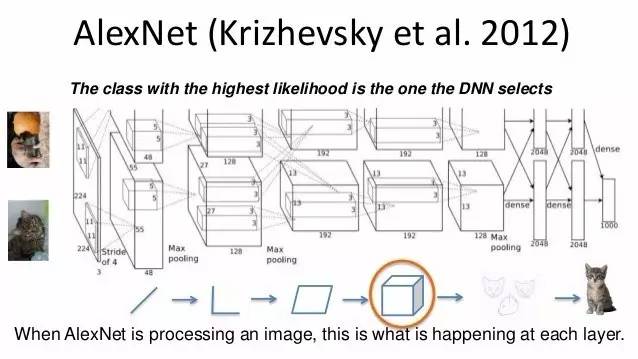
对于 Hinton 和他的两个学生来说,ImageNet 的出现恰逢其时。自 20 世纪 80 年代以来,Hinton 一直致力于人工神经网络的研究,尽管有些像 Yann LeCun 一样,能够通过贝尔实验室的影响将这项技术应用于 ATM 支票识别,但是 Hinton 的研究却无处可用。几年前,显卡制造商英伟达的研究让这些网络的处理速度更快,但神经网络仍然不如其他技术。
Hinton 和他的团队表明,他们的网络可以在较小的数据集上执行较小的任务,如手写字符检测。但是,他们需要更多的数据才能在现实世界中有用。
“如果你在 ImageNet 上做得很好,你就能解决图像识别问题,这是再清楚不过的。”Sutskever 说。
今天,这些卷积神经网络已经无处不在——LeCun 现在是 Facebook AI Research 的主管,Facebook 使用它们来标记你的照片,自动驾驶汽车在使用它们来检测物体,基本上任何识别图像和视频的系统都使用卷积神经网络(CNN)。CNN 可以通过抓取抽象特征分辨图像中的内容,找到模式与新输入的图像模式相匹配。Hinton 几十年来一直试图说服同行他的研究有用,现在他终于有了证据。
“更令人惊奇的是,人们能够通过深度学习来不断改进,”Sutskever 说,指多层神经网络能够处理更复杂的模式,也是现在最受欢迎的人工智能技术。“深度学习就是我们要的东西(Deep learning is just the right stuff)。”
2012 年 ImageNet 竞赛的结果使计算机视觉研究人员纷纷开始复现这一过程。纽约大学的博士生 Matthew Zeiler 曾经跟着 Hinton 学习,他发现了 ImageNet 竞赛的结果,并通过多伦多大学的联系很早获知了论文和代码。他开始与 Rob Fergus 合作,Fergus 是纽约大学的教授,也一直研究神经网络。两人开始为 2013 年的 ImageNet 竞赛设计自己的方案,Zeiler 最后提前几周结束了在谷歌实习,专注于提交 ImageNet 竞赛结果。
2014 年,也就是 Zeiler 和 Fergus 获胜那一年,所有的高分结果使用的方法都是深度神经网络。
“2012 年的 ImageNet 竞赛无疑引发了 AI 大爆炸,”Zeiler 表示:“在此之前,语音识别有一些非常有希望的结果(其中许多是由多伦多大学开启的),但是都没有像 2012 年和接下来的 ImageNet 竞赛冠军一样广为流传。”
现在,许多人都认为 ImageNet 已经被解决了——误差率在 2% 左右真的很低了。但是,这是分类的结果,也就是识别图像中的物体是什么。这并不代表算法知道这个物体的属性,它来自哪里、功能是什么、如何使用,或者如何与其周围环境进行交互。总之,算法实际上并不理解它看到了什么。这在语音识别中,甚至在很多自然语言处理中也是如此。虽然 AI 今天在分辨事物上十分厉害,但接下来要在现实世界情景中理解事物是什么。至于怎么做到这一点,AI 研究人员目前还不清楚。
尽管 ImageNet 竞赛结束了,但 ImageNet 数据集——经过多年来更新,现在已经超过 1300 万张图片将会继续。
Berg 表示,团队试图在 2014 年结束竞赛的一个子命题,但却遭到了来自包括谷歌和 Facebook 等公司的阻力。产业界非常喜欢这个基准,他们可以指着一个数字说:“看我们这么牛。”
自 2010 年以来,谷歌、微软和 CIFAR 推出了其他一些数据集,因为事实表明深度学习需要像 ImageNet 这样的大数据。
数据集已经变得非常重要。创始人和风险投资家会在 Medium 写文章介绍最新发布的数据集,以及他们的算法在 ImageNet 上的表现。互联网公司,比如谷歌、Facebook 和亚马逊已经开始创建自己的内部数据集,数据都来自每天在他们的平台上输入和共享的数百万图像、语音片段和文本片段。即使是初创公司也开始构建自己的数据集——TwentyBN,一个专注于视频理解的 AI 初创公司,发布了两个免费的学术数据集,每个数据集有超过 100,000 个视频。
李飞飞说:“各种数据集,从视频到语音到游戏,都有很大的发展。”
有时人们理所当然的认为这些花了大力气收集、组合、检验的数据集是免费的。开放和自由使用是 ImageNet 的原始宗旨,这一宗旨也将超越 ImageNet 竞赛,甚至数据集传承下去。
2016 年,谷歌发布了 Open Images 数据集,其中包含 6000 多个类别的 900 万张图像。谷歌最近更新了数据集,在每个图像中包含了特定对象所在的标签,这个特点在 2014 年的ImageNet 竞赛后成了图像数据集的标配。DeepMind 最近也发布了人类进行各种行为的视频数据集。
“ImageNet 让 AI 领域发生的一个重大变化是,人们突然意识到构建数据集这个苦活累活是 AI 研究的核心,”李飞飞说: “人们真的明白了,数据集跟算法一样,对研究都至关重要。”

李飞飞演讲开始:IMAGENET,我们做了哪些事情?现在将去向何方?

开端: CVPR 2009,迈阿密

IMAGENET 的影响

IMAGENET on Google Scholar

从参赛者到初创企业

深度学习的革命,深度学习为何突然改变了你的生活
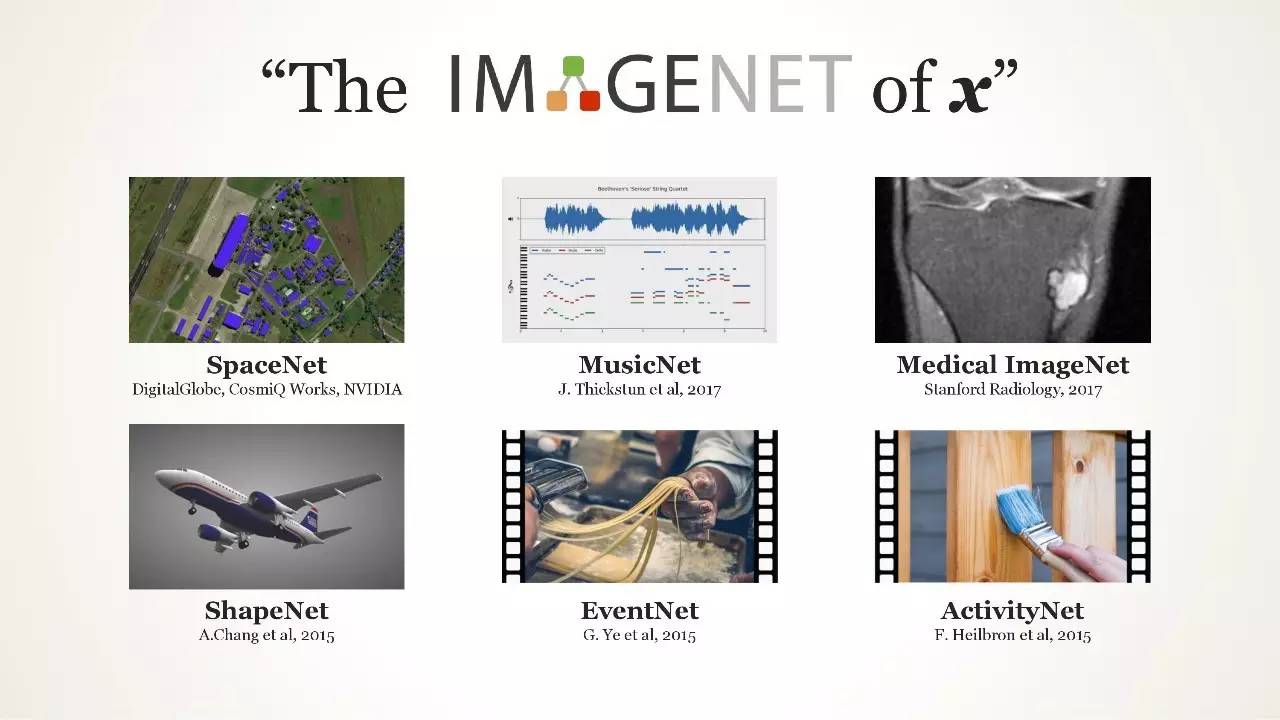
“The IMAGENET of x”

数据集的爆发 Kaggle

李飞飞演讲中

“数据集—而非算法—可能是人类水平人工智能发展的关键性限制因素”

IMAGENET,不为人知的历史

“几乎不算是第一个图像数据集”

视觉学习的机器学习问题
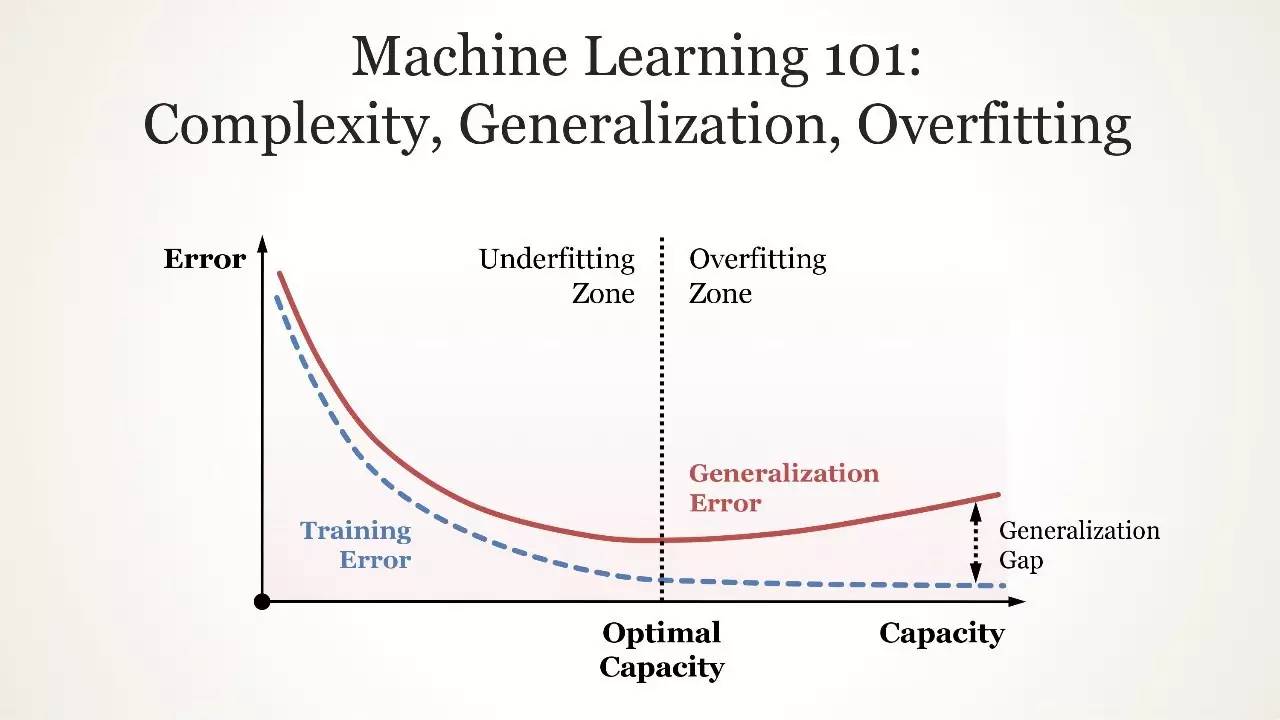
Complexity, Generalization, Overfitting
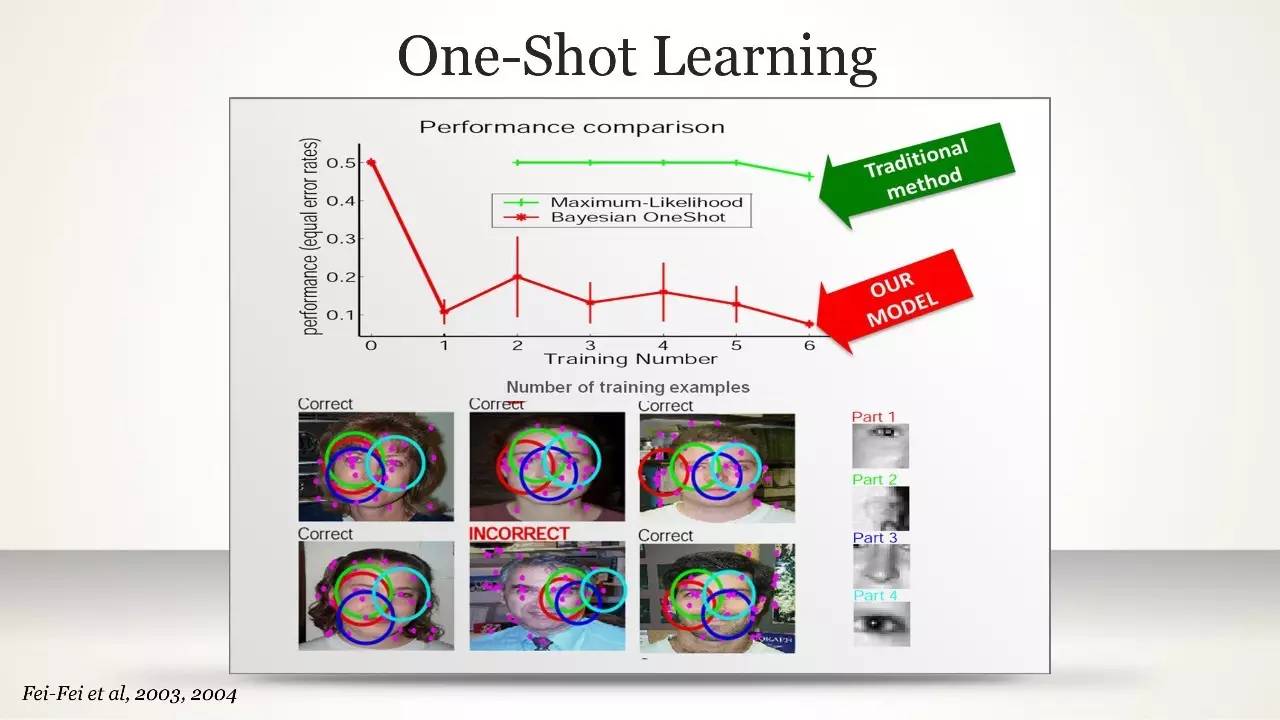
One-Shot Learning

李飞飞演讲中
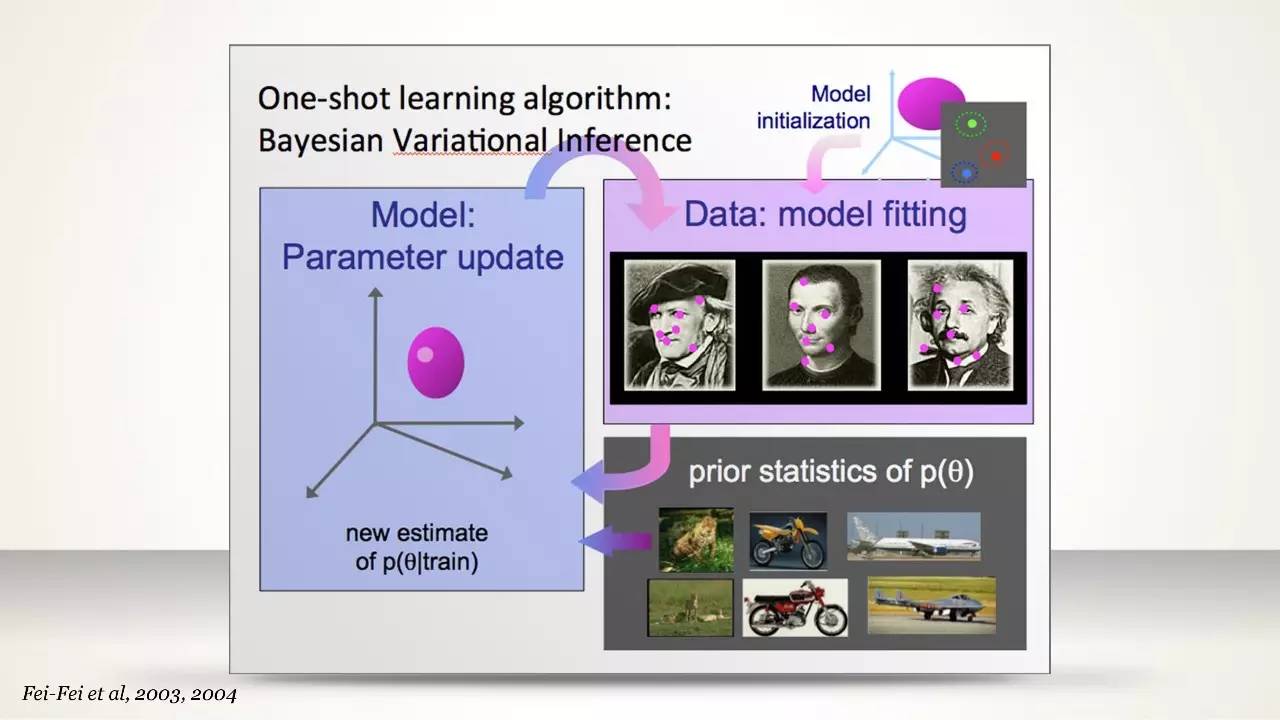
One-Shot Learning 算法:贝叶斯变分推断

孩子是如何学习去看的?
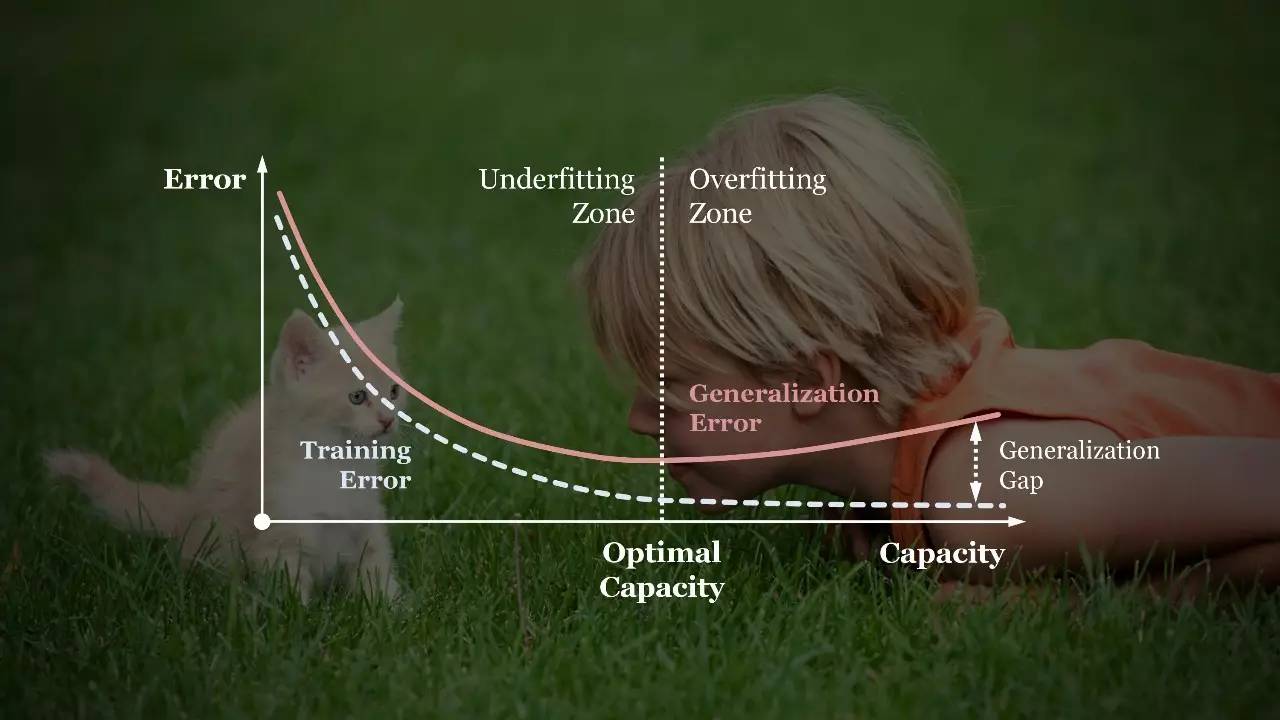
孩子是如何学习去看的?

新思路:转换视觉识别的机器学习焦点
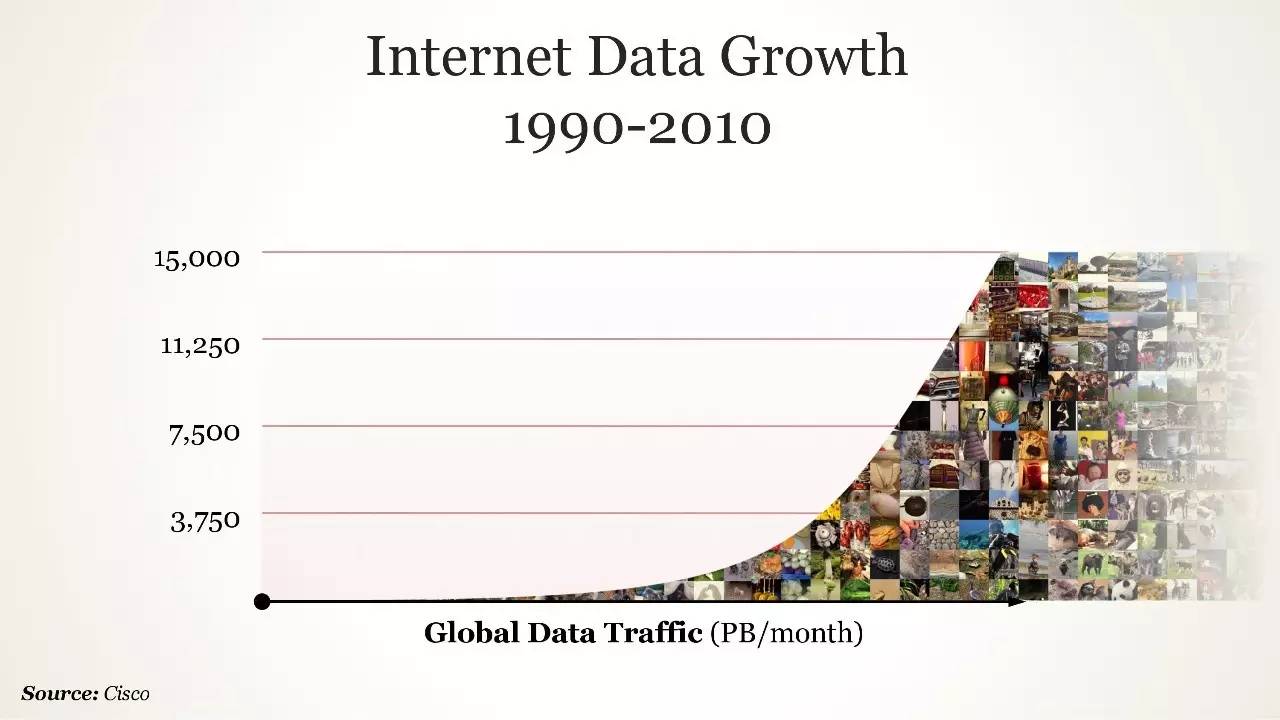
互联网数据增长(1990-2010)

WordNet 是什么?

Christiane Fellbaum

“Individually Illustrated WordNet Nodes”

IMAGENET Comrades
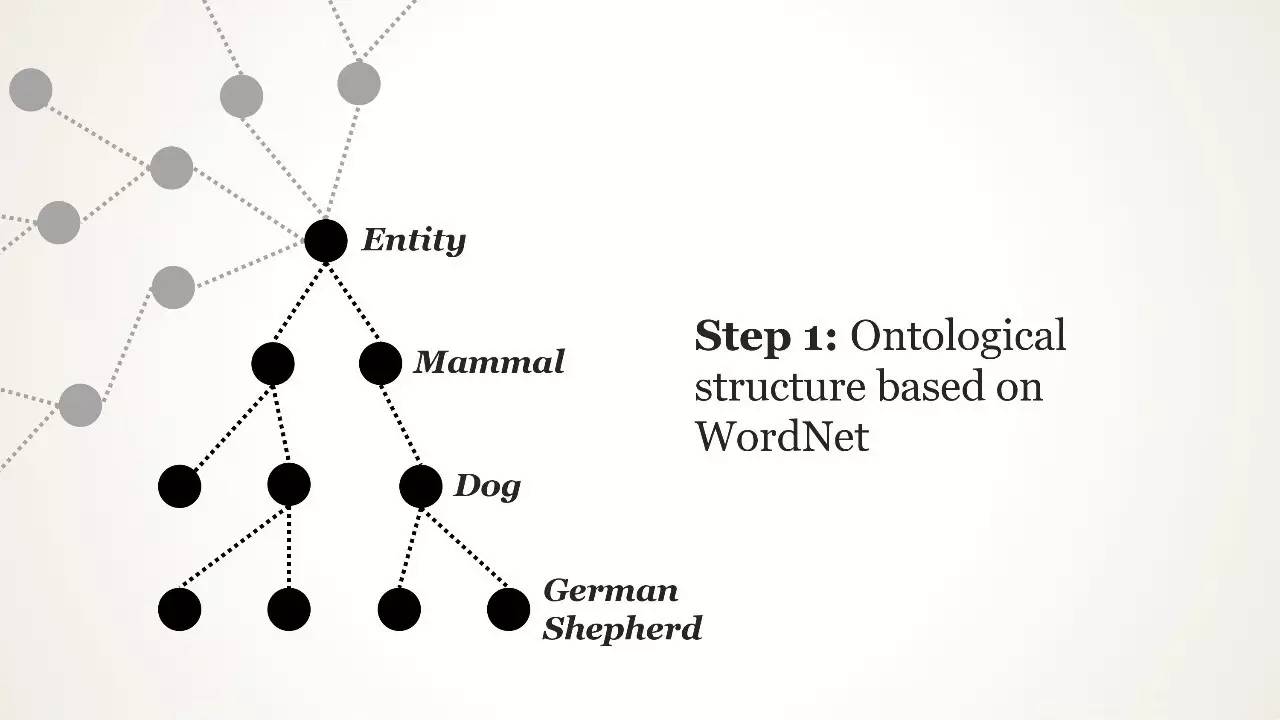
ImageNet 的建设

ImageNet 的建设

ImageNet 的建设

启动 IMAGENET 的三次尝试

第一次尝试:精神物理学实验

第一次尝试:精神物理学实验

第二次尝试:“人为介入”解决方案

第二次尝试:“人为介入”解决方案

第三次尝试:天赐良机
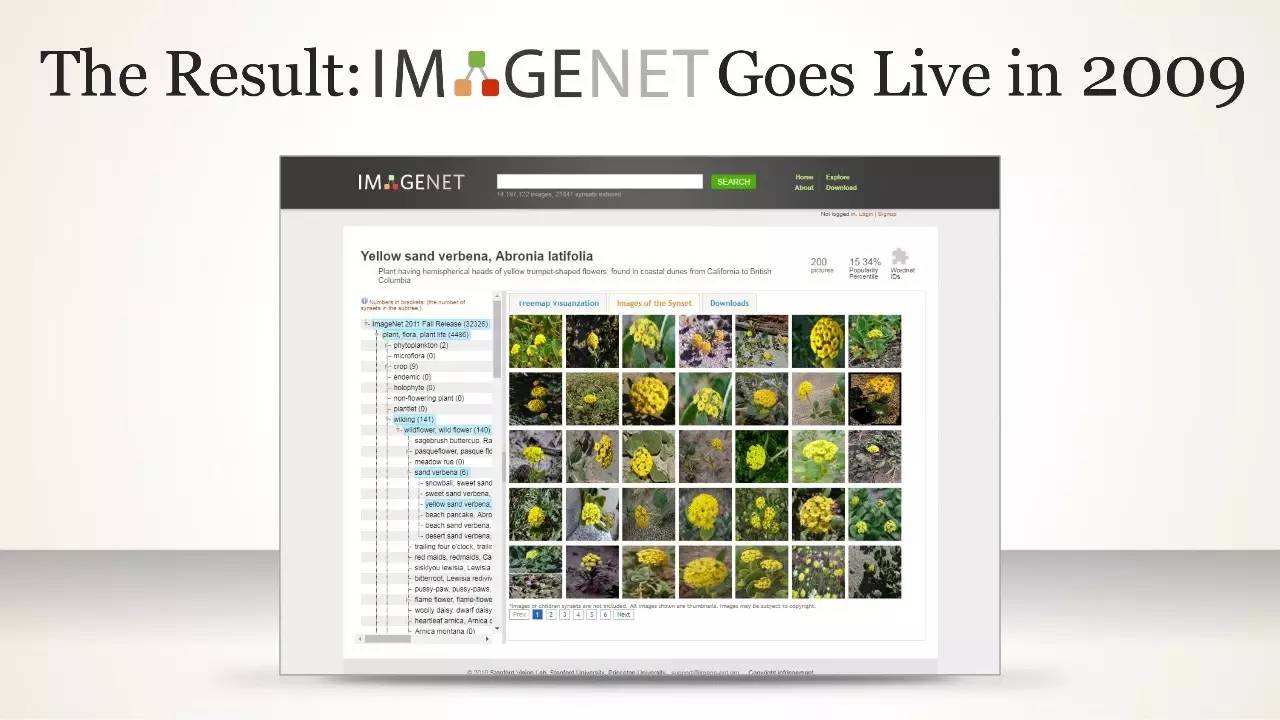
2009 年,IMAGENET "Goes Live"

我们做对的一件事是...

当其他人追求细节时...

我们追求的是规模(scale)

IMAGENET 的其他目标

IMAGENET,ILSVRC 2010-2017

ILSVRC 的贡献者

我们的灵感来源:PASCAL VOC

我们的灵感来源:PASCAL VOC,Mark Everingham
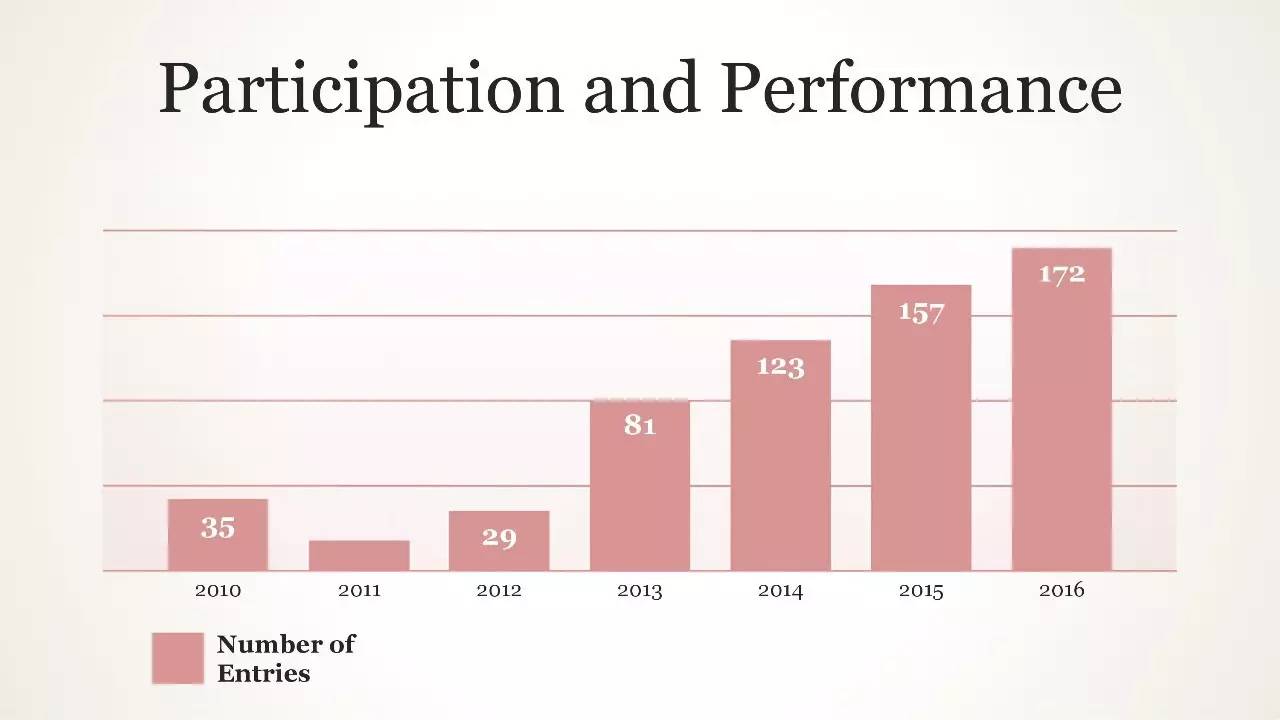
性能表现
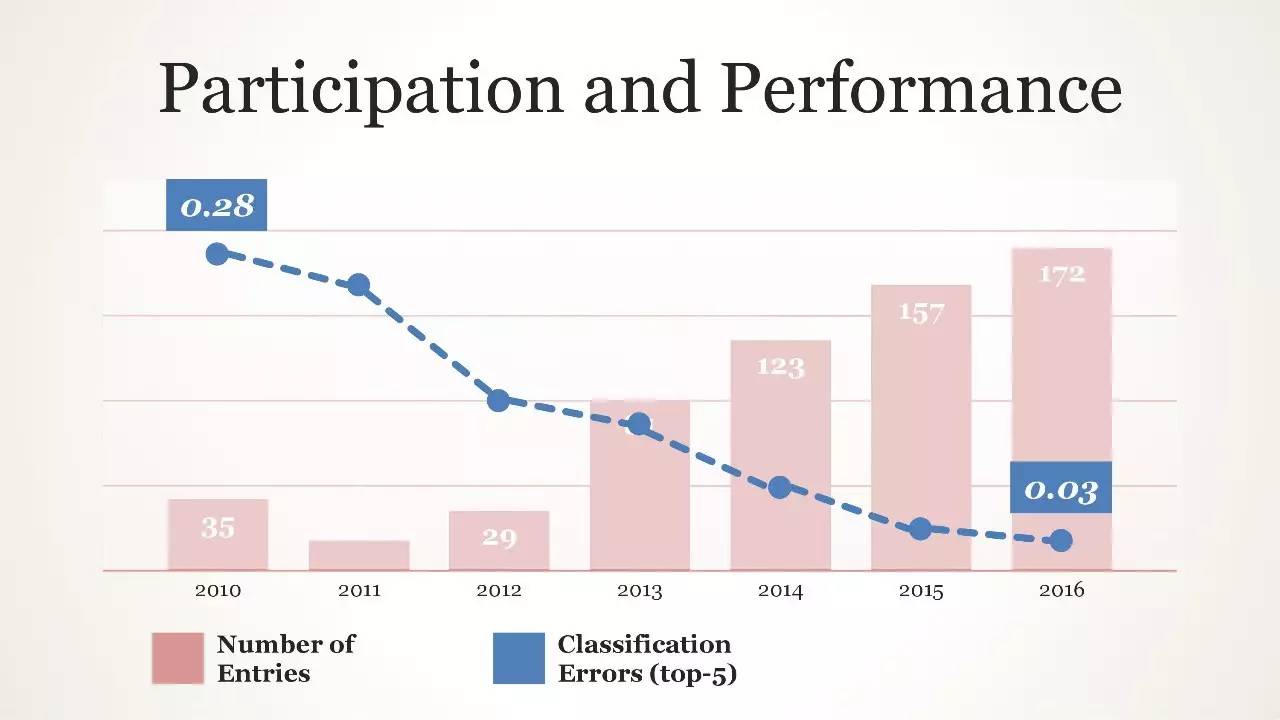
性能表现
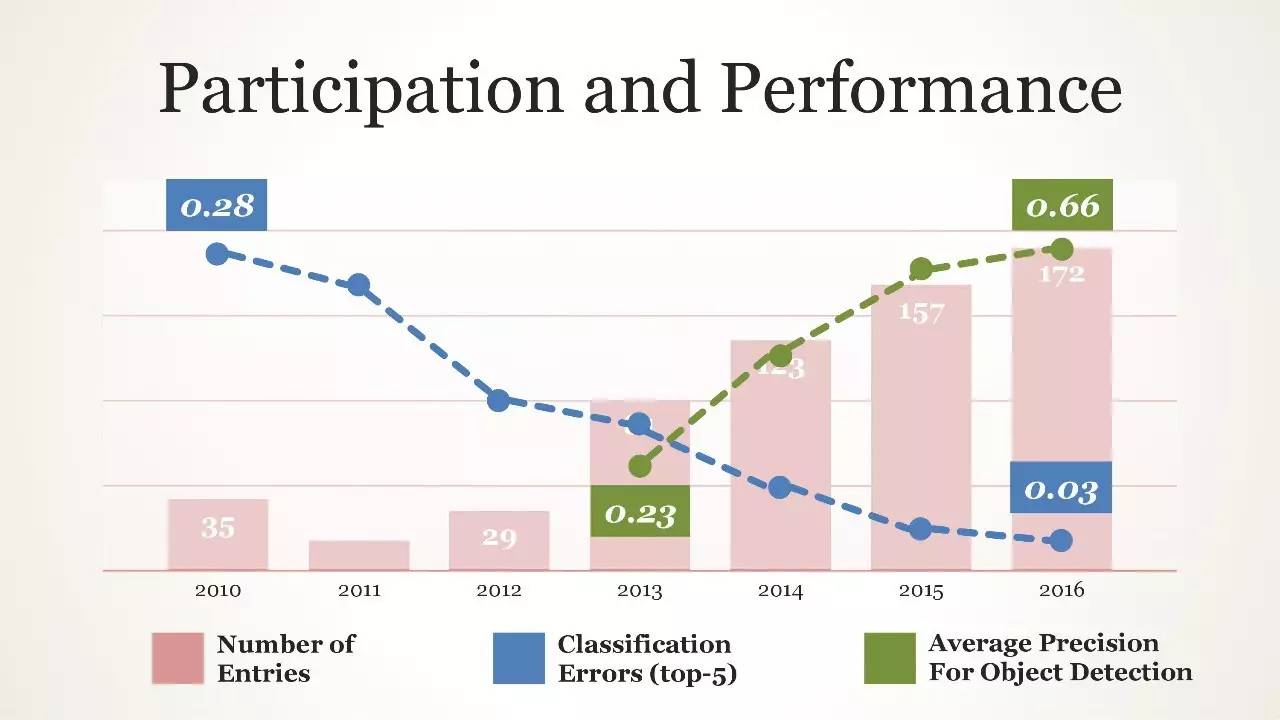
性能表现

我们做了什么让 ImageNet 变得更好
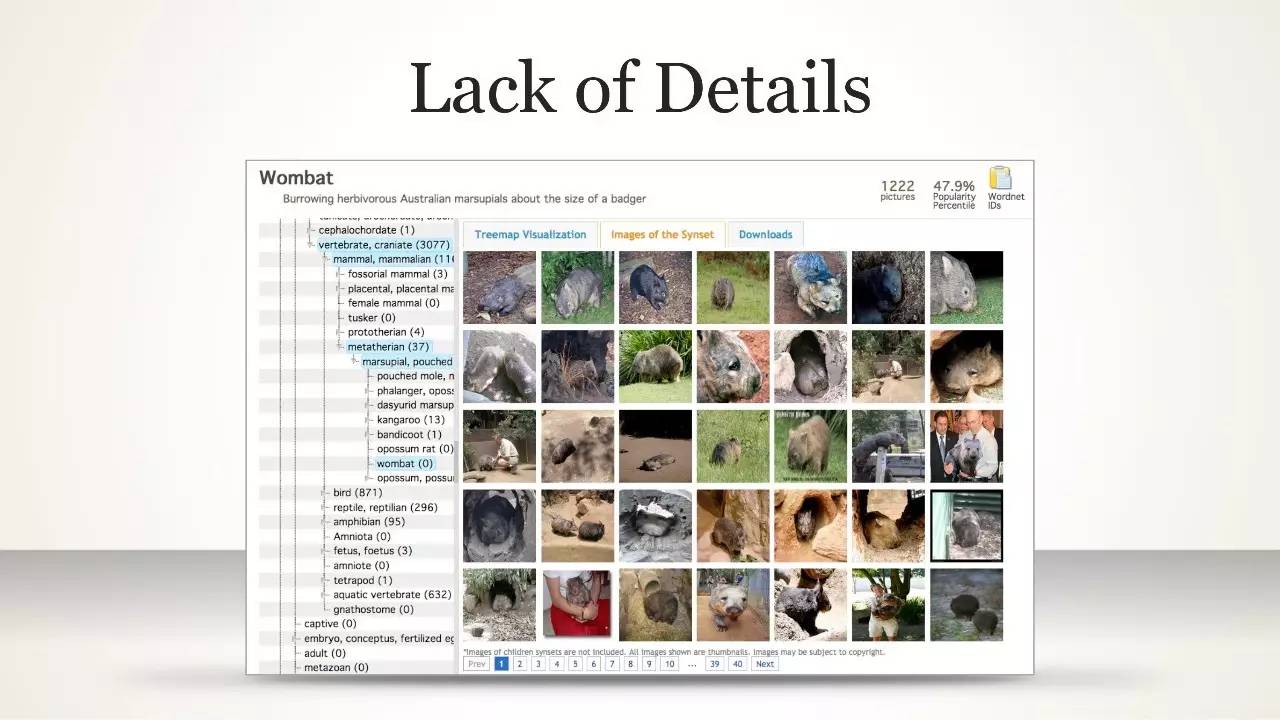
缺少细节
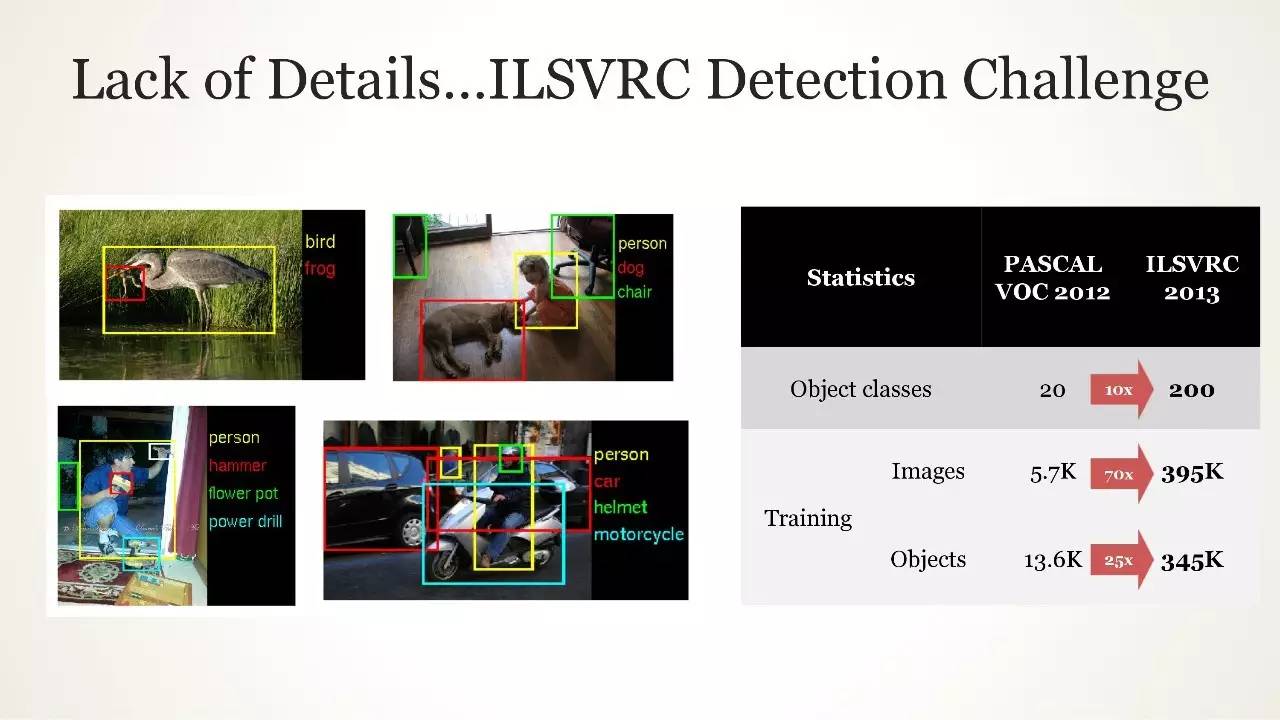
缺少细节...ILSVRC 检测挑战

ILSVRC 检测任务的评估
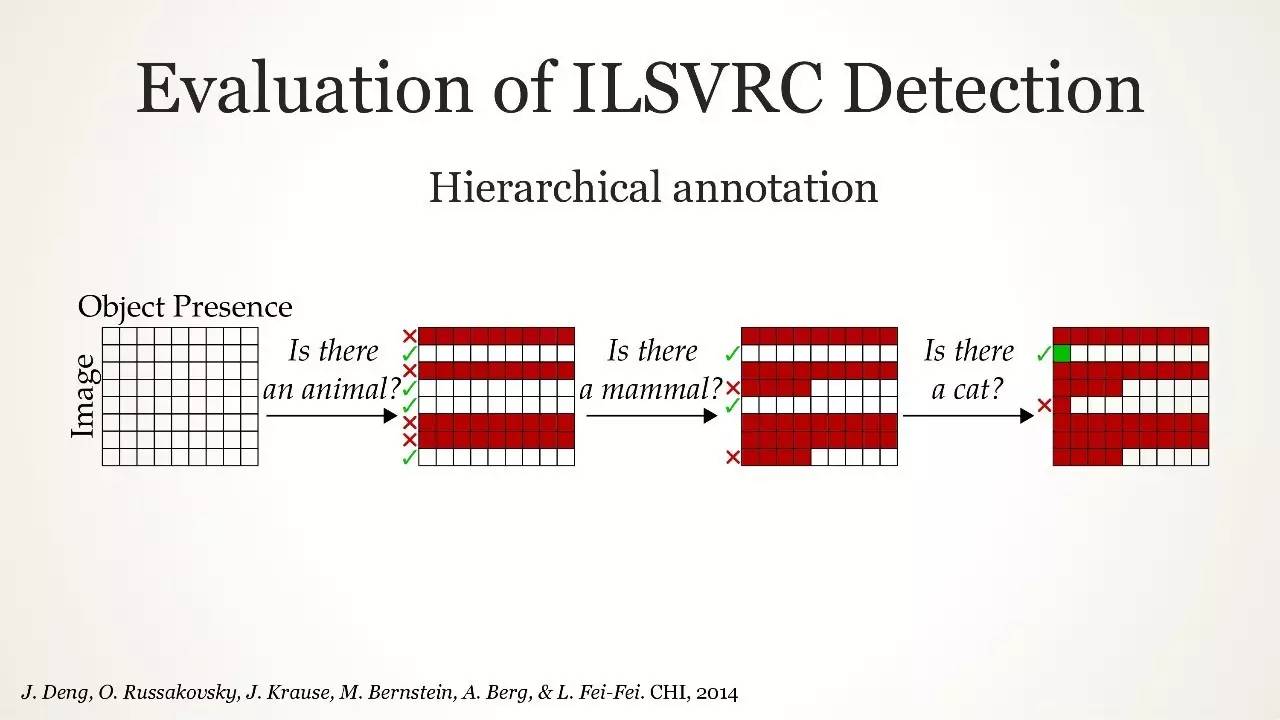
ILSVRC 检测任务的评估
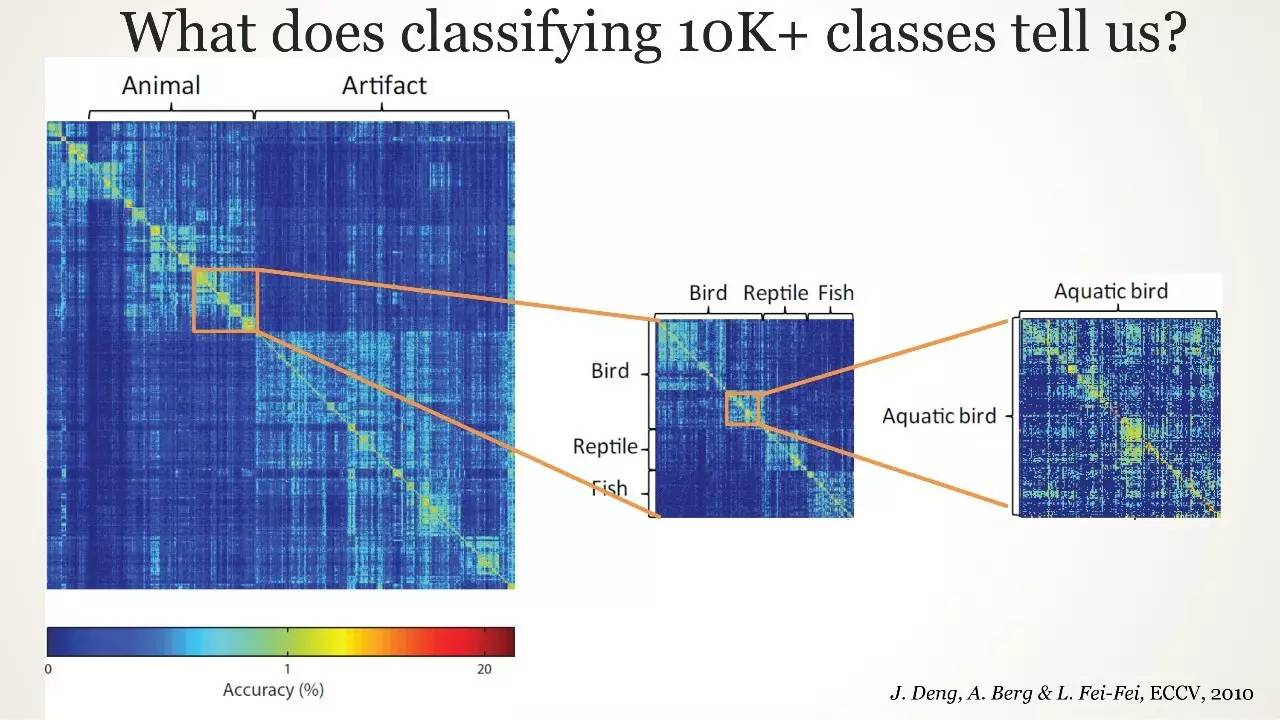
10K+ classes 分类告诉了我们什么

细粒度识别

细粒度识别

预期结果

非预期结果
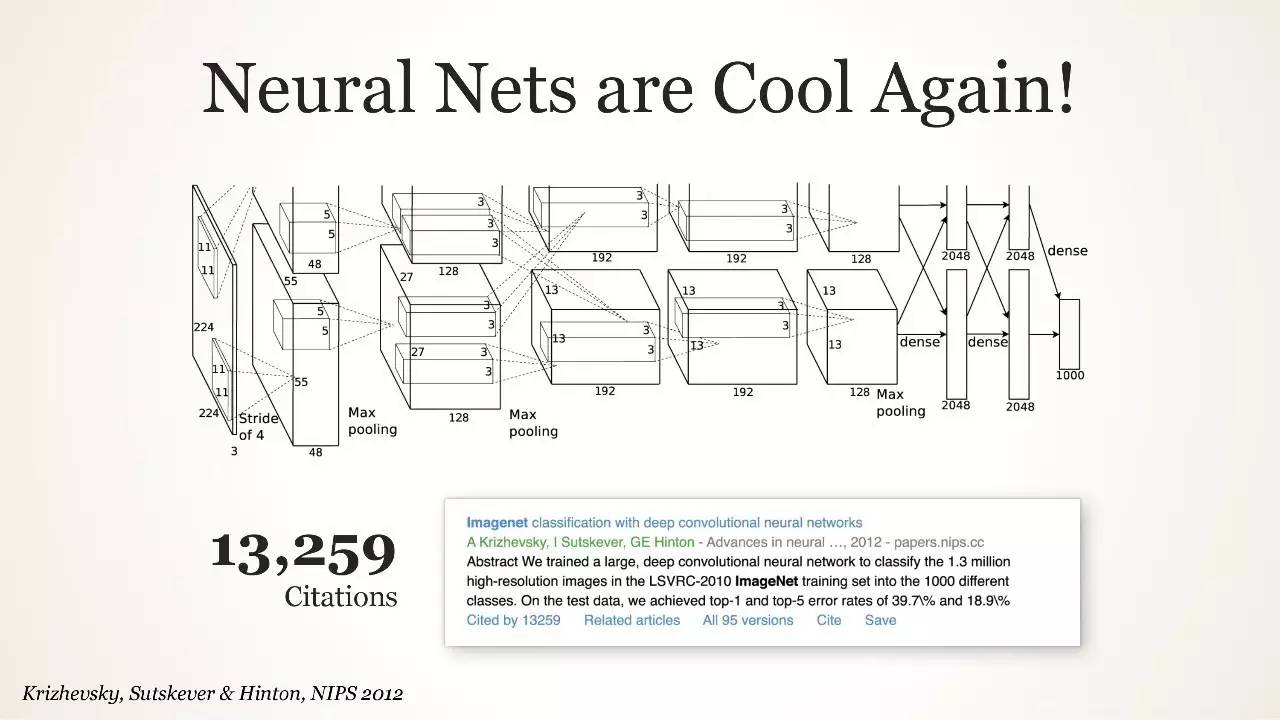
Neural Nets are Cool Again!

Cooler and Cooler...
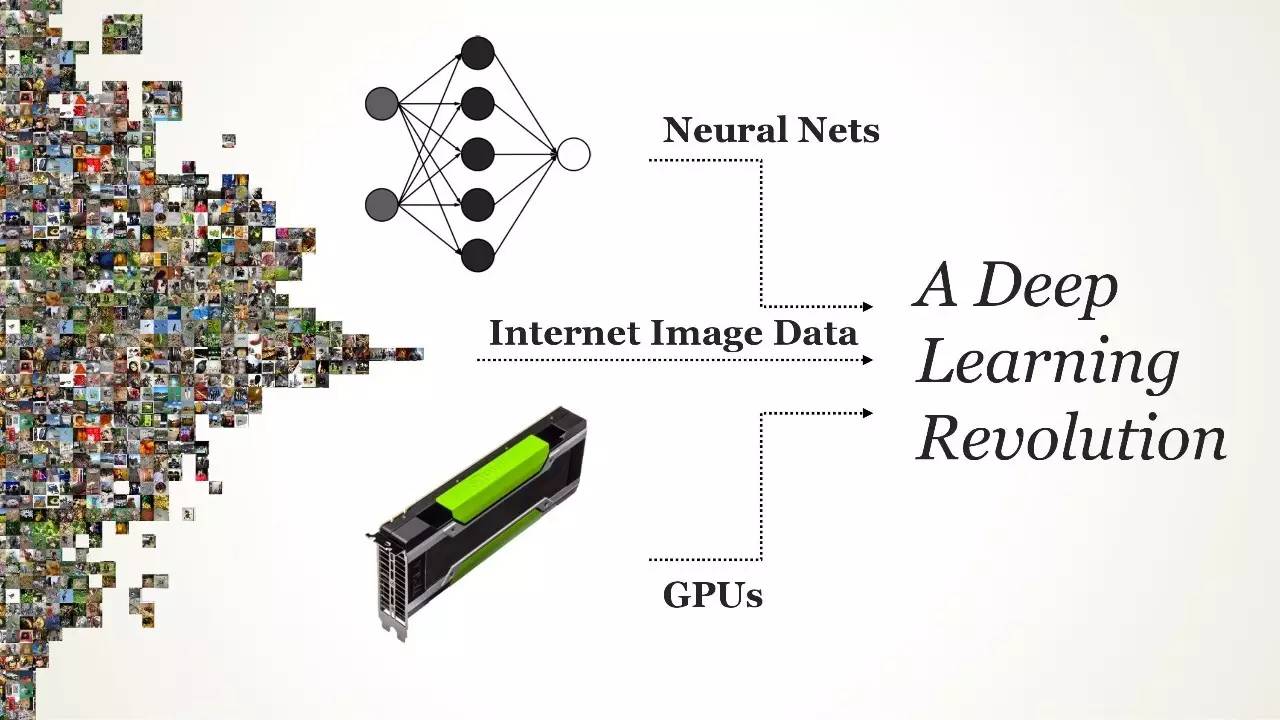
深度学习革命三要素:神经网络、互联网图像数据、GPU

Ontological Structure 用得不那么多
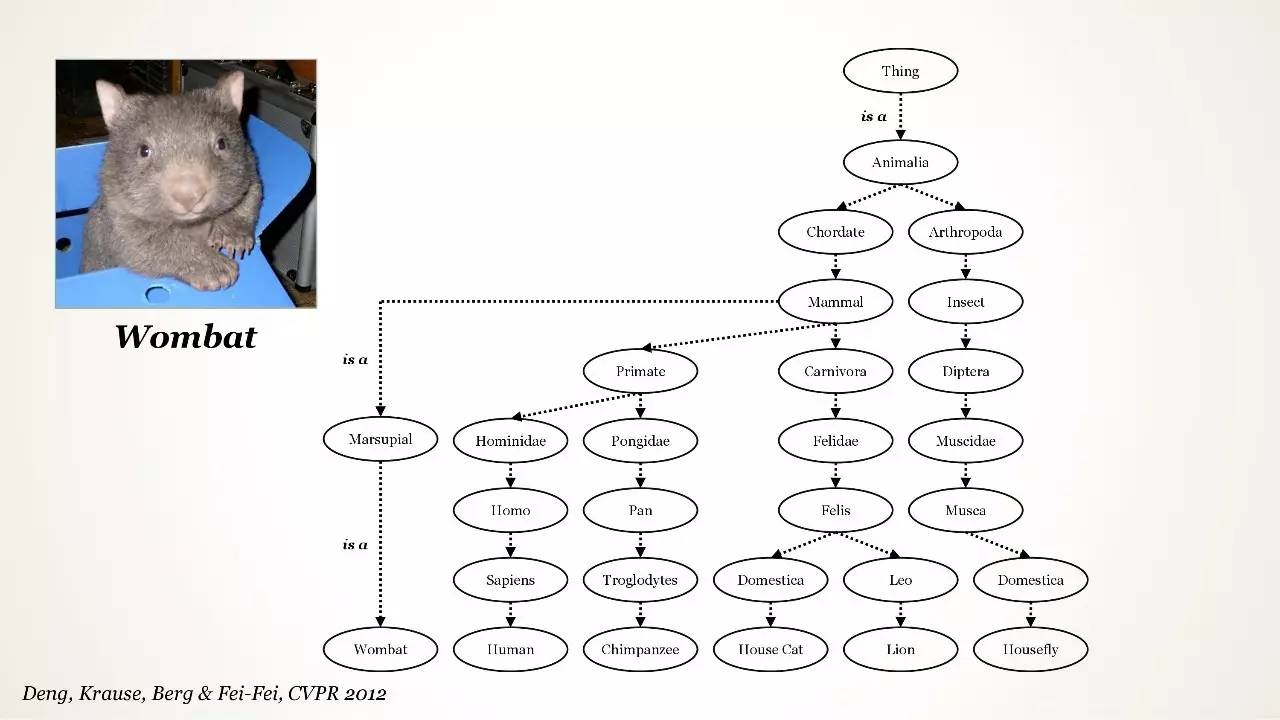
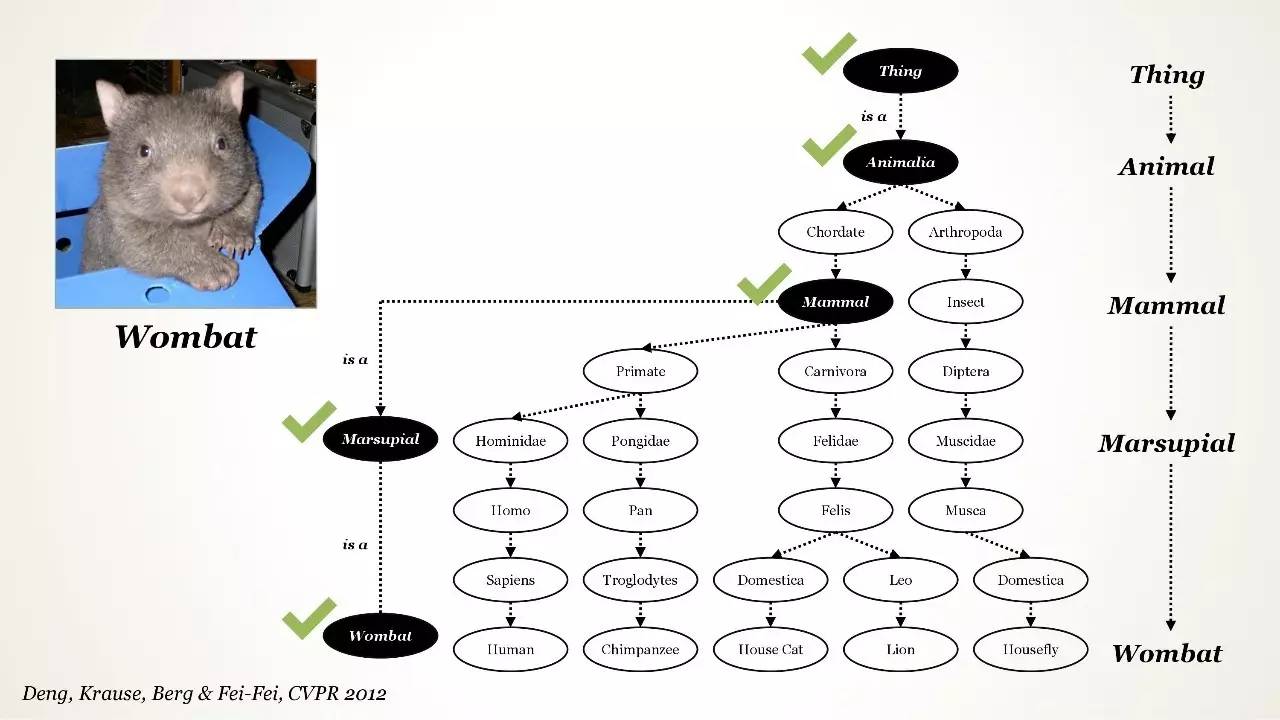

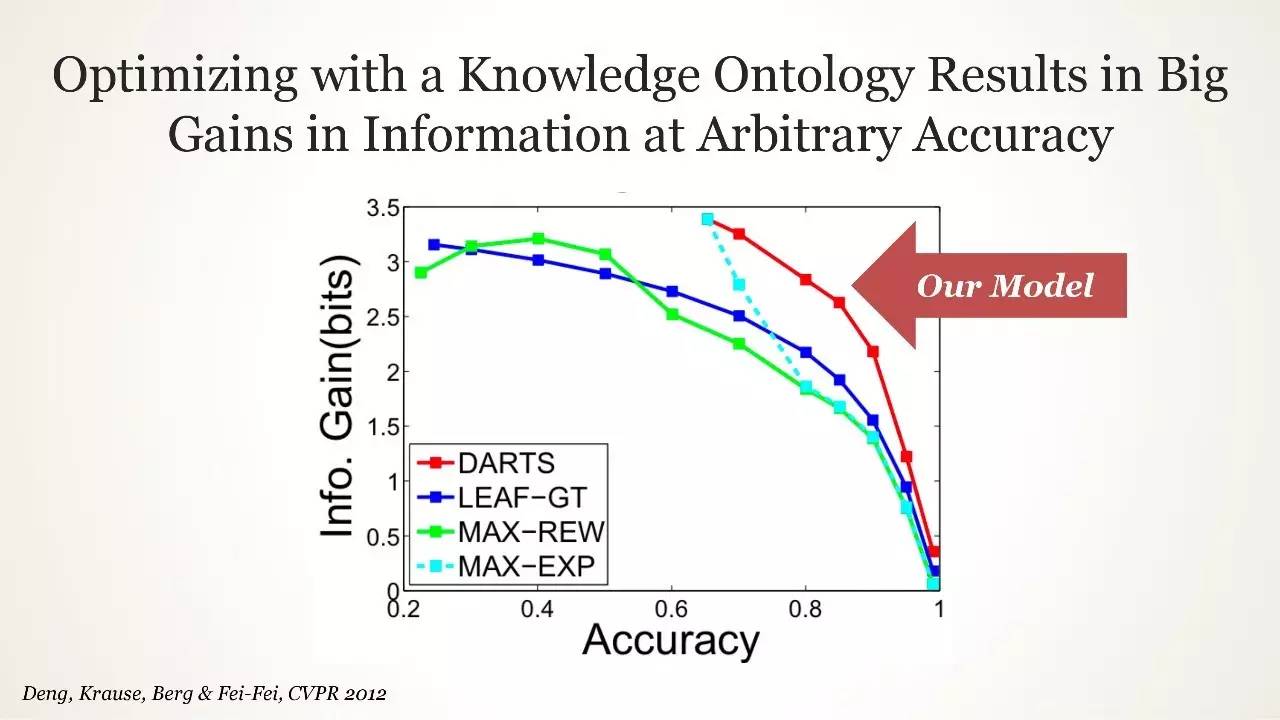

使用 Ontology 的工作相当少

大多数工作仍在用 1M 图像做预训练

“我们发现在视觉任务中的表现和训练数据集的 size 数量级成正比.”

比起人类如何?
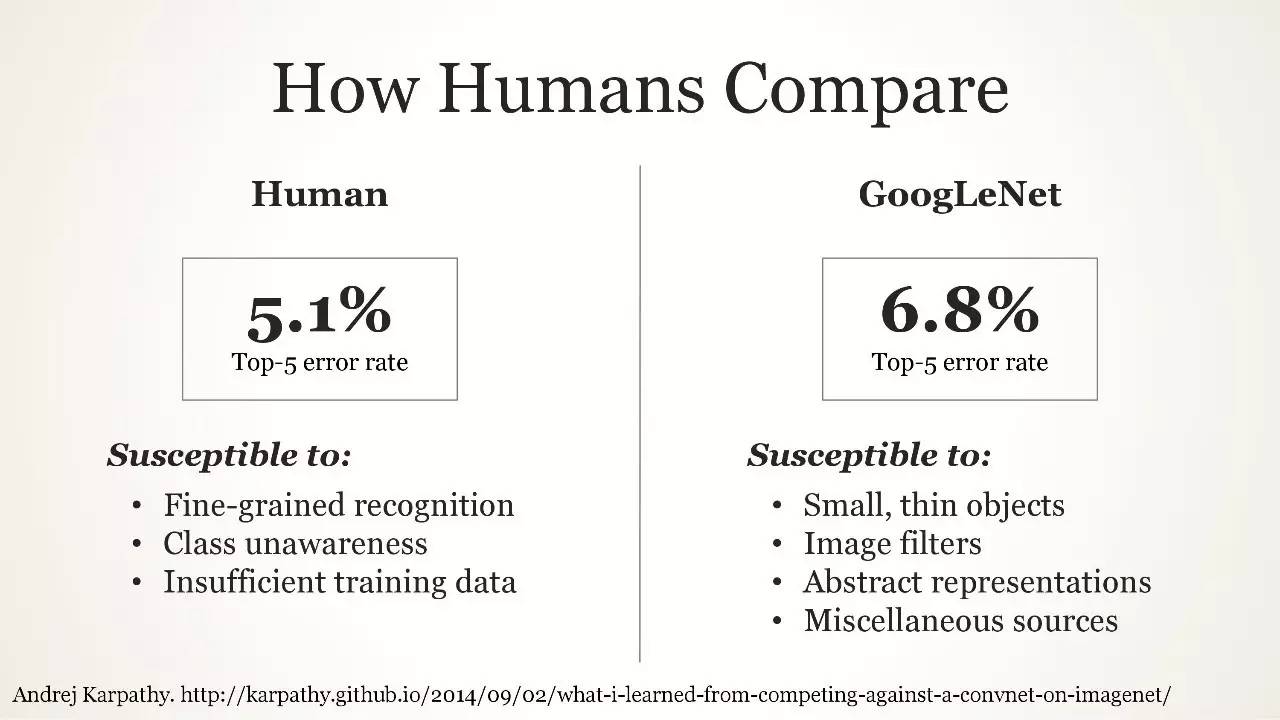
比起人类如何?

接下来的工作
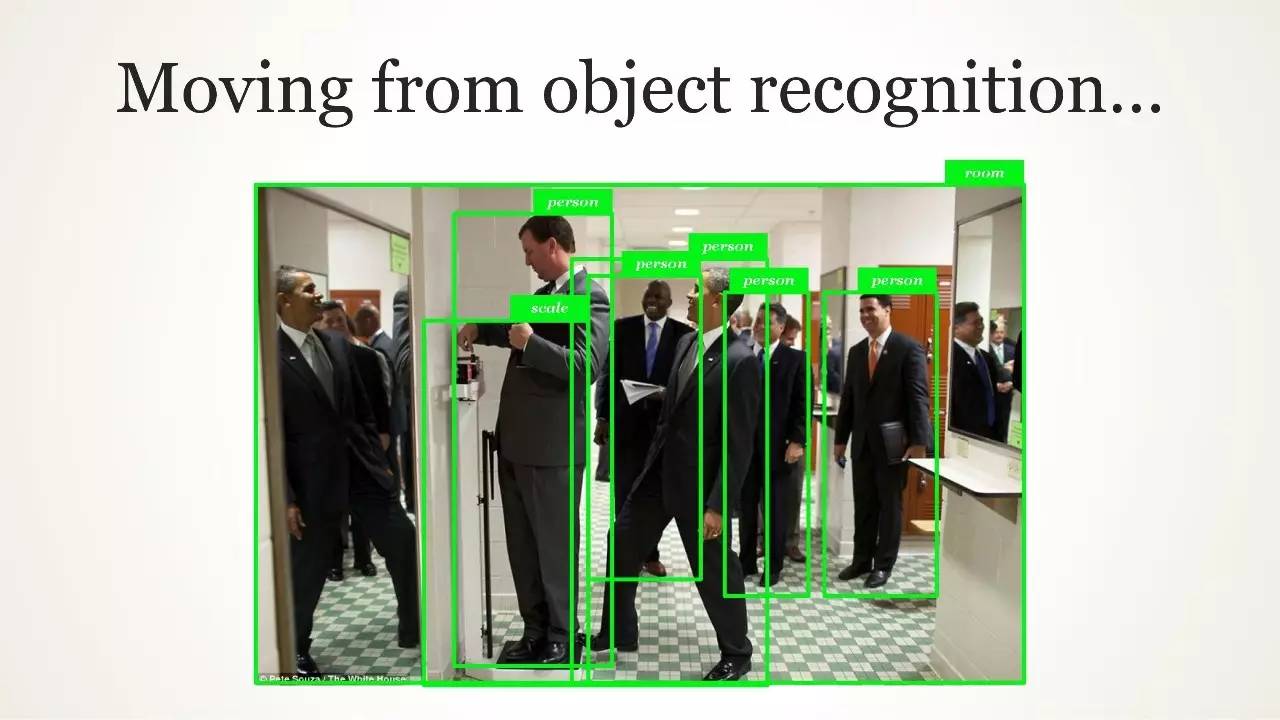
从对象识别
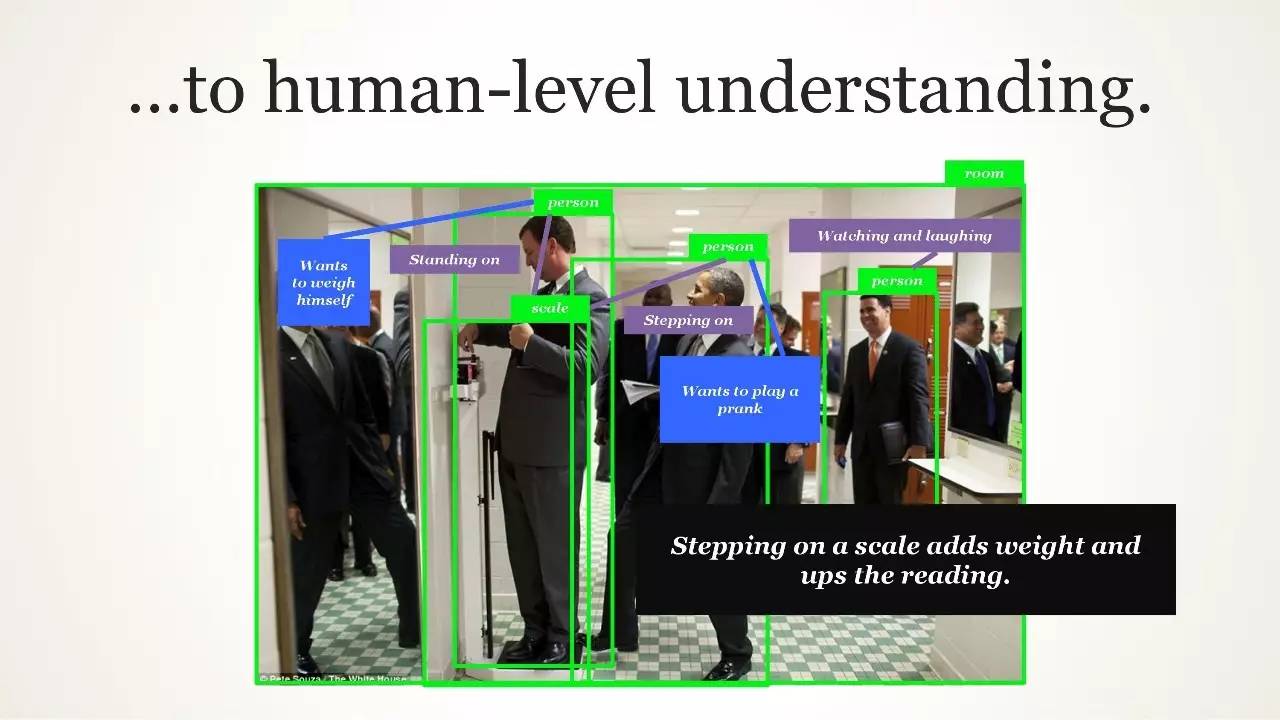
到人类水平的理解

Inverse Graphics




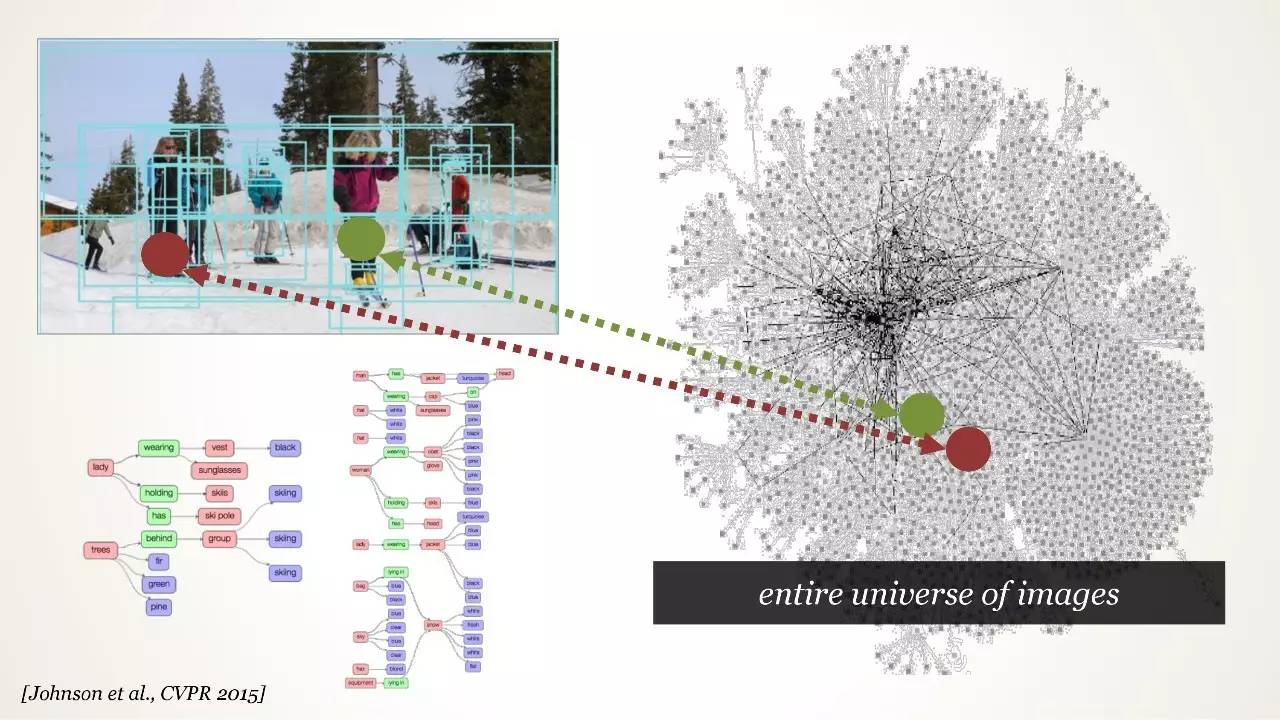
计算机视觉理解

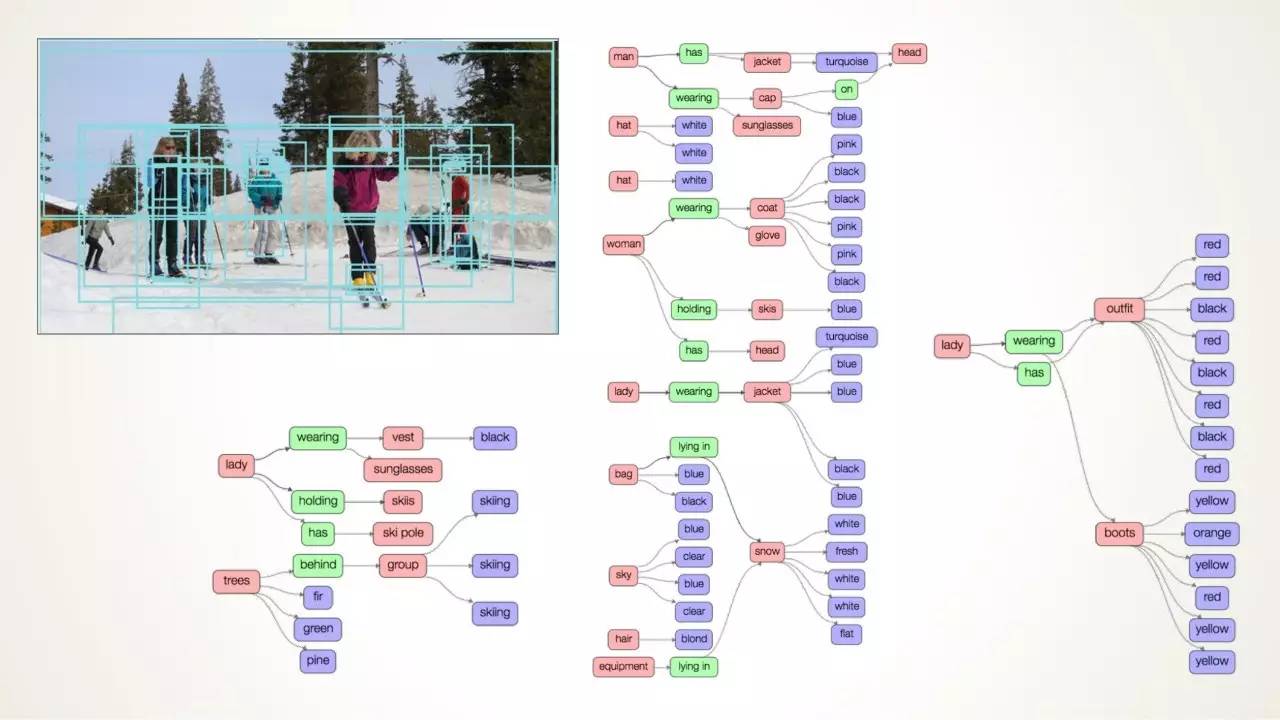
视觉基因数据集(Visual Genome Dataset)

视觉基因数据集(Visual Genome Dataset)

通过网络数据学习的视觉理解 Workshop
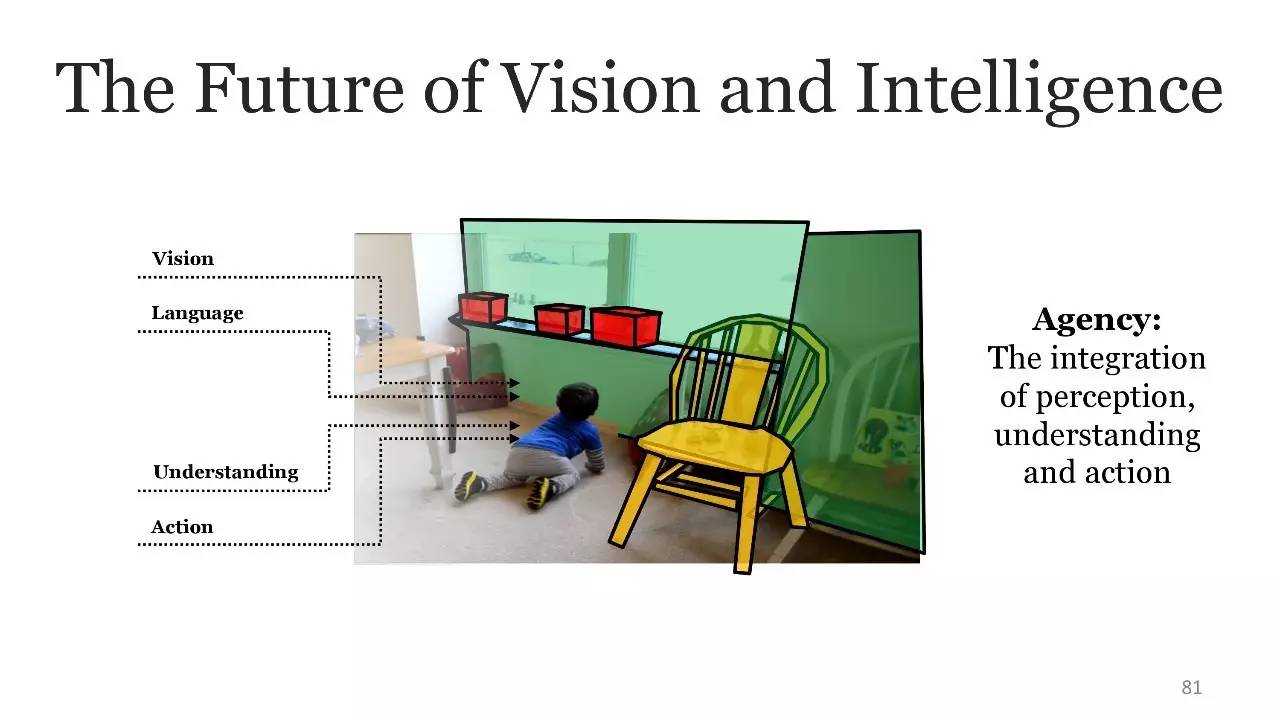
视觉和智能的未来

8 年 IMAGENET 竞赛

IMAGENET+Kaggle

IMAGENET+Kaggle

IMAGENET:贡献者/伙伴/顾问

“这并非结束,结束甚至还没有开始,但也许,我们已经起步。”
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~






