人工智能 60 年技术简史


作者 | 李理,环信人工智能研发中心 VP
封图 | CSDN 付费下载自视觉中国
出品 | CSDN AI 科技大本营(ID:rgznai100)
人类的进化发展史就是一部人类制造和使用工具的历史,不同的工具代表了人类的进化水平。从石器时代、铁器时代、蒸汽时代、电气时代再到现在的信息时代,我们使用更加先进便捷的工具来改变生产和生活。
工具的目的是延伸和拓展人类的能力,我们跑得不快,但可以借助骑马和开车日行千里,跳得不高,更不会飞,但是借助飞机火箭上天入地。工具总体来看可以分为两类:拓展人类体力的工具和拓展人类脑力的工具。
在计算机发明之前,人类制造的大多数工具都是前者,它可以帮助我们减少体力劳动。比如使用牛或者拖拉机来耕地的效率更高。当然也有少量的减少脑力劳动的工具,比如算盘,也包括文字——它可以极大的扩充人类的记忆容量,现在很多机械的脑力劳动都可以由计算机完成。但传统的计算机程序只能帮我们扩充记忆和完成简单机械的计算,我们有容量更大速度更快的存储器,可以编制财务软件来帮助进行财务核算。
我们无法实现需要“智能”才能来完成的事情,比如无法让计算机进行汽车驾驶,计算机目前也无法像人类一样用自然语言和人类进行日常沟通,而人工智能的目标就是让计算机能够像人类一样“智能”的解决这些复杂问题。现在的人工智能系统已经能够在围棋上战胜人类世界冠军,现在的语音识别系统已经能在某些特定场景下达到人类的识别准确率,无人驾驶的汽车也已经在某些地方实验性的上路了。未来,人工智能会有更多的应用场景,我们的终极目标是制造和人类一样甚至超越人类智能的机器。

人工智能发展简史
人工智能最早的探索也许可以追溯到莱布尼茨,他试图制造能够进行自动符号计算的机器,但现代意义上人工智能这个术语诞生于 1956 年的达特茅斯会议。
关于人工智能有很多的定义,它本身就是很多学科的交叉融合,不同的人关注它的不同方面,因此很难给出一个大家都认可的一个定义。我们下面通过时间的脉络来了解 AI 的反正过程。
黄金时期(1956-1974)
这是人工智能的一个黄金时期,大量的资金用于支持这个学科的研究和发展。这一时期有影响力的研究包括通用问题求解器(General Problem Solver),以及最早的聊天机器人 ELIZA。
很多人都以为与其聊天的 ELIZA 是一个真人,但它只是简单的基于匹配模板的方式来生成回复(我们现在很多市面上的聊天机器人其实也使用了类似的技术)。
当时人们非常乐观,比如 H. A. Simon 在 1958 年断言不出 10 年计算机将在下(国际)象棋上击败人类。他在 1965 年甚至说“二十年后计算机将可以做所有人类能做的事情”。
第一次寒冬(1974-1980)
到了这一时期,之前的断言并没有兑现,因此各种批评之声涌现出来,国家(美国)也不再投入更多经费,人工智能进入第一次寒冬。这个时期也是联结主义(connectionism)的黑暗时期。1958 年 Frank Rosenblatt 提出了感知机(Perception),这可以认为是最早的神经网络的研究。但是在之后的 10 年联结主义没有太多的研究和进展。
兴盛期(1980-1989)
这一时期的兴盛得益于专家系统的流行。联结主义的神经网络也有所发展,包括 1982 年 John Hopfield 提出了 Hopfield 网络,以及同时期发现的反向传播算法,但主流的方法还是基于符号主义的专家系统。
第二次寒冬(1989-1993)
之前成功的专家系统由于成本太高以及其它的原因,商业上很难获得成功,人工智能再次进入寒冬期。
发展期(1993-2006)
这一期间人工智能的主流是机器学习。统计学习理论的发展和 SVM 这些工具的流行,使得机器学习进入稳步发展的时期。
爆发期(2006-现在)
这一次人工智能的发展主要是由深度学习,也就是深度神经网络带动的。上世纪八九十年度神经网络虽然通过非线性激活函数解决了理论上的异或问题,而反向传播算法也使得训练浅层的神经网络变得可能。不过,由于计算资源和技巧的限制,当时无法训练更深层的网络,实际的效果并不比传统的“浅度”的机器学习方法好,因此并没有太多人关注这个方向。
直到 2006 年,Hinton 提出了 Deep Belief Nets (DBN),通过 pretraining 的方法使得训练更深的神经网络变得可能。2009 年 Hinton 和 DengLi 在语音识别系统中首次使用了深度神经网络(DNN)来训练声学模型,最终系统的词错误率(Word Error Rate/WER)有了极大的降低。
让深度学习在学术界名声大噪的是 2012 年的 ILSVRC 评测。在这之前,最好的 top5 分类错误率在 25%以上,而 2012 年 AlexNet 首次在比赛中使用了深层的卷积网络,取得了 16%的错误率。之后每年都有新的好成绩出现,2014 年是 GoogLeNet 和 VGG,而 2015 年是 ResNet 残差网络,目前最好系统的 TOP5 分类错误率在 5%以下了。
真正让更多人(尤其是中国人)了解深度学习进展的是 2016 年 Google DeepMind 开发的 AlphaGo 以 4 比 1 的成绩战胜了人类世界冠军李世石。因此人工智能进入了又一次的兴盛期,各路资本竞相投入,甚至国家层面的人工智能发展计划也相继出台。

2006 年到现在分领域的主要进展
下面我们来回顾一下从 2006 年开始深度学习在计算机视觉、听觉、自然语言处理和强化学习等领域的主要进展,根据它的发展过程来分析未来可能的发展方向。因为作者水平和兴趣点的局限,这里只是列举作者了解的一些文章,所以肯定会遗漏一些重要的工作。
一、计算机视觉
无监督预训练
虽然”现代”深度学习的很多模型,比如 DNN、CNN 和 RNN(LSTM)很早就提出来了,但在 2006 年之前,大家没有办法训练很多层的神经网络,因此在效果上深度学习和传统的机器学习并没有显著的差别。
2006 年,Hinton 等人在论文《A fast learning algorithm for deep belief nets》里提出了通过贪心的、无监督的 Deep Belief Nets(DBN)逐层 Pretraining 的方法和最终有监督 fine-tuning 的方法首次实现了训练多层(五层)的神经网络。此后的研究热点就是怎么使用各种技术训练深度的神经网络,这个过程大致持续到 2010 年。主要的想法是使用各种无监督的 Pretraining 的方法,除了 DBN,Restricted Boltzmann Machines(RBM), Deep Boltzmann Machines(DBM)还有 Denoising Autoencoders 等模型也在这一期间提出。
代表文章包括 Hinton 等人的《Reducing the dimensionality of data with neural networks》发表在 Nature 上)、Bengio 等人在 NIPS 2007 上发表的《Greedy layer-wise training of deep networks》,Lee 等人发表在 ICML 2009 上的《Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations》,Vincent 等人 2010 年发表的《Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion》。
那个时候要训练较深的神经网络是非常 tricky 的事情,因此也有类似 Glorot 等人的《Understanding the difficulty of training deep feedforward neural networks》,大家在使用深度学习工具时可能会遇到 Xavier 初始化方法,这个方法的作者正是 Xavier Glorot。那个时候能把超参数选好从而能够训练好的模型是一种”黑科技”,我记得还有一本厚厚的书《Neural Networks: Tricks of the Trade》,专门介绍各种 tricks。
深度卷积神经网络
深度学习受到大家的关注很大一个原因就是 Alex 等人实现的 AlexNet 在 LSVRC-2012 ImageNet 这个比赛中取得了非常好的成绩。此后,卷积神经网络及其变种被广泛应用于各种图像相关任务。从 2012 年开始一直到 2016 年,每年的 LSVRC 比赛都会产生更深的模型和更好的效果。
Alex Krizhevsky 在 2012 年的论文《ImageNet classification with deep convolutional neural networks》开启了这段”深度”竞争之旅。
2014 年的冠军是 GoogleNet,来自论文《Going deeper with convolutions》,它提出了 Inception 的结构,通过这种结构可以训练 22 层的深度神经网络。它同年的亚军是 VGGNet,它在模型结构上并没有太多变换,只是通过一些技巧让卷积网络变得更深(18 层)。
2015 年的冠军是 ResNet,来自何恺明等人的论文《Deep residual learning for image recognition》,通过引入残差结构,他们可以训练 152 层的网络,2016 年的文章《Identity Mappings in Deep Residual Networks》对残差网络做了一些理论分析和进一步的改进。
2016 年 Google 的 Szegedy 等人在论文《Inception-v4, inception-resnet and the impact of residual connections on learning》里提出了融合残差连接和 Incpetion 结构的网络结构,进一步提升了识别效果。
下图是这些模型在 LSVRC 比赛上的效果,我们可以看到随着网络的加深,分类的 top-5 错误率在逐渐下降。
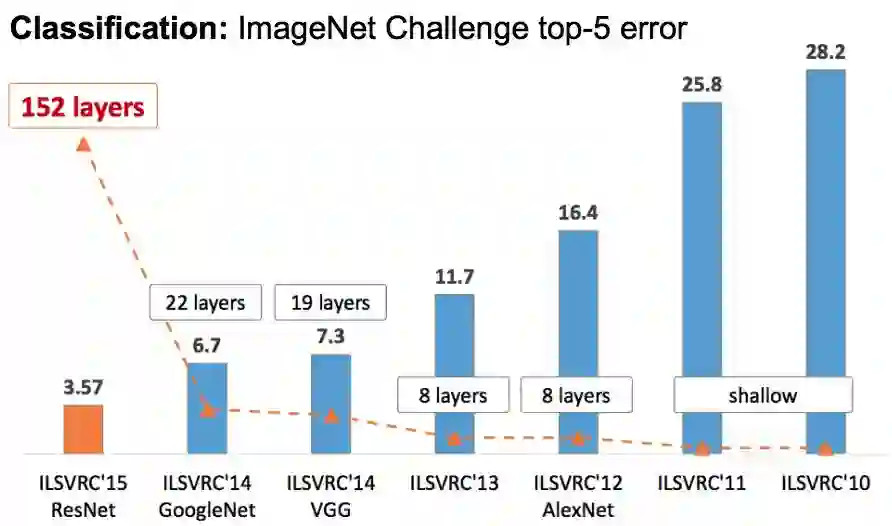
图:LSVRC 比赛
目标检测和实例分割
前面的模型主要考虑的是图片分类任务,目标检测和实例分割也是计算机视觉非常常见的任务。把深度卷积神经网络用到这两个任务上是非常自然的事情,但是这个任务除了需要知道图片里有什么物体,还需要准确的定位这些物体。为了把卷积神经网络用于这类任务,需要做很多改进工作。
当然把 CNN 用于目标检测非常自然,最简单的就是先对目标使用传统的方法进行定位,但是定位效果不好。Girshick 等人在 2014 年在论文《Rich feature hierarchies for accurate object detection and semantic segmentation》提出了 R-CNN 模型,使用 Region Proposal 来产生大量的候选区域,最后用 CNN 来判断是否是目标,但因为需要对所有的候选进行分类判断,因此它的速度非常慢。

图:R-CNN
2015 年,Girshick 等人提出了 Fast R-CNN,它通过 RoI Pooling 层通过一次计算同时计算所有候选区域的特征,从而可以实现快速计算。但是 Regional Proposal 本身就很慢,Ren 等人在同年的论文《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》提出了 Faster R-CNN,通过使用 Region Proposal Networks(RPN)这个网络来替代原来的 Region Proposal 算法,从而实现实时目标检测算法。为了解决目标物体在不同图像中不同尺寸(scale)的问题,Lin 等人在论文《Feature Pyramid Networks for Object Detection》里提出了 Feature Pyramid Networks(FPN)。

图:Fast R-CNN
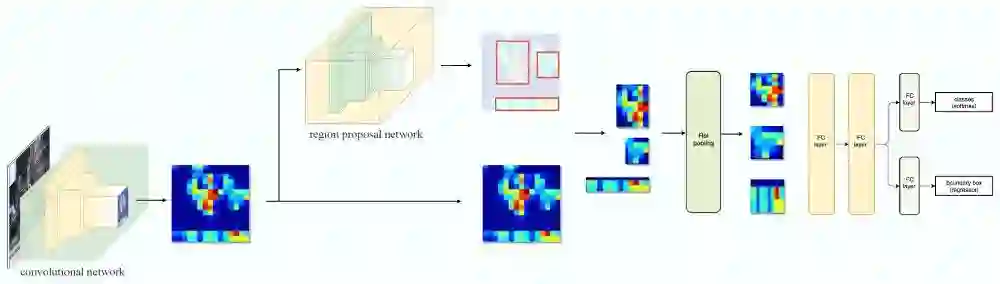
图:Faster R-CNN
因为 R-CNN 在目标检测任务上很好的效果,把 Faster R-CNN 用于实例分割是很自然的想法。但是 RoI Pooling 在用于实例分割时会有比较大的偏差,原因在于 Region Proposal 和 RoI Pooling 都存在量化的舍入误差。因此何恺明等人在 2017 年提出了 Mask R-CNN 模型。
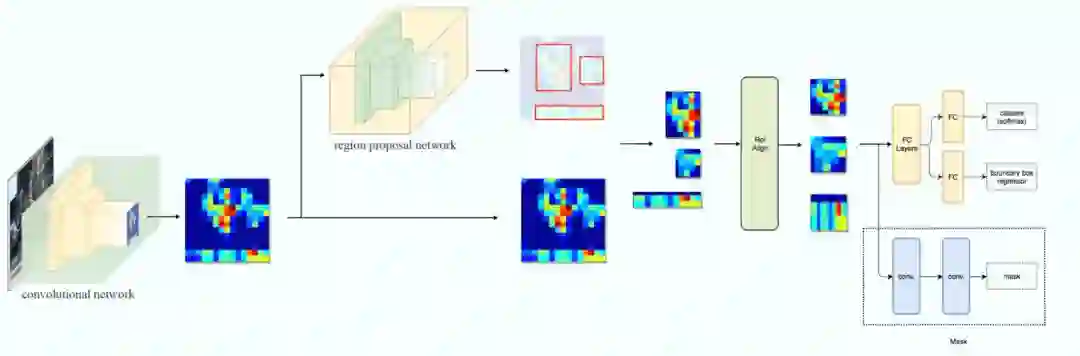
图:Mask R-CNN
从这一系列文章我们可以看到深度学习应用于一个更复杂场景的过程:首先是在一个复杂的过程中部分使用深度神经网络,最后把所有的过程 End-to-End 的用神经网络来实现。
此外,Redmon 等人《You only look once: Unified, real-time object detection》提出了 YOLO 模型(包括后续的 YOLOv2 和 YOLOv3 等),Liu 等人也提出的 SSD: Single Shot MultiBox Detector 模型,这些模型的目的是为了保持准确率不下降的条件下怎么加快检测速度。
生成模型
如果要说最近在计算机视觉哪个方向最火,生成模型绝对是其中之一。要识别一个物体不容易,但是要生成一个物体更难(三岁小孩就能识别猫,但是能画好一只猫的三岁小孩并不多)。而让生成模型火起来的就是 Goodfellow 在 2014 年提出的 Generative Adversarial Nets(简称 GAN)。
因为这个领域比较新,而且研究的”范围”很广,也没有图像分类这样的标准任务和 ImageNet 这样的标准数据集,很多时候评测的方法非常主观。很多文章都是找到某一个应用点,然后生成(也可能是精心挑选)了一些很酷的图片或者视频,”有图有真相”,大家一看图片很酷,内容又看不懂,因此不明觉厉。要说解决了什么实际问题,也很难说。但是不管怎么说,这个方向是很吸引眼球的,比如 DeepFake 这样的应用一下就能引起大家的兴趣和讨论。我对这个方向了解不多,下面只列举一些应用。
style-transfer
最早的《A Neural Algorithm of Artistic Style》发表于 2015 年,这还是在 GAN 提出之前,不过我还是把它放到生成模型这里了。它当年可是火过一阵,还因此产生了一个爆款的 App 叫 Prisma。如下图所示,给定一幅风景照片和一幅画(比如 c 是梵高的画),使用这项技术可以在风景照片里加入梵高的风格。

图:Neural Style Transfer
朱俊彦等人在《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》提出的 CycleGAN 是一个比较有趣其的模型,它不需要 Paired 的数据。所谓 Paired 数据,就是需要一张普通马的照片,还需要一张斑马的照片,而且要求它们内容是完全匹配的。要获得配对的数据是非常困难的,我们拍摄的时候不可能找到外形和姿势完全相同的斑马和普通马,包括相同的背景。另外给定一张梵高的作品,我们怎么找到与之配对的照片?或者反过来,给定一张风景照片,去哪找和它内容相同的艺术作品?
本文介绍的 Cycle GAN 不要求有配对的训练数据,而只需要两个不同 Domain 的未标注数据集就行了。比如要把普通马变成斑马,我们只需要准备很多普通马的照片和很多斑马的照片,然后把所有斑马的照片放在一起,把所有的普通马照片放到一起就行了,这显然很容易。风景画变梵高风格也很容易——我们找到很多风景画的照片,然后尽可能多的找到梵高的画作就可以了。它的效果如下图所示。

图:CycleGAN
text-to-image
text-to-image 是根据文字描述来生成相应的图片,这和 Image Captioning 正好相反。Zhang 等人 2016 年的《StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks》是这个方向较早的一篇文章,其效果如下图最后一行所示。

图:StackGAN 和其它模型的对比
super-resolution
super-resolution 是根据一幅低分辨率的图片生成对应高分辨率的图片,和传统的插值方法相比,生成模型因为从大量的图片里学习到了其分布,因此它”猜测”出来的内容比插值效果要好很多。《Enhanced Super-Resolution Generative Adversarial Networks》是 2018 年的一篇文章,它的效果如下图中间所示。

图:ESRGAN 效果
image inpainting
image inpainting 是遮挡掉图片的一部分,比如打了马赛克,然后用生成模型来”修补”这部分内容。下图是 Generative Image Inpainting with Contextual Attention 的效果。

图:DeepFill 系统的效果
《EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning》这篇文章借鉴人类绘画时先画轮廓(线)后上色的过程,通过把 inpainting 分成 edge generator 和 image completion network 两个步骤,如下面是它的效果。

图:EdgeConnect 的效果
最新热点:自动优化网络结构和半监督学习
最近有两个方向我觉得值得关注:一个是自动优化网络结构;另一个是半监督的学习。
自动网络优化最新的文章是 Google 研究院的《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》,它希望找到一个神经网络扩展方法可以同时提高网络的准确率和效率(减少参数)。要实现这点,一个很关键的步骤便是如何平衡宽度、深度和分辨率这三个维度。
作者发现,可以使用一种固定比例的缩放操作简单地实现对三者的平衡。最终,作者提出了一种简单却有效的 compound scaling method。如果想使用 2𝑁倍的计算资源,只需要对网络宽度增加𝛼𝑁,深度增加𝛽𝑁和增加𝛾𝑁倍的图像大小。其中𝛼,𝛽,𝛾是固定的系数,最优的值通常使用小范围的 grid search 得到。通过这种方法他们实现了 EfficientNet 模型,这个模型使用非常少的参数就达到了很好的效果,如下图所示。
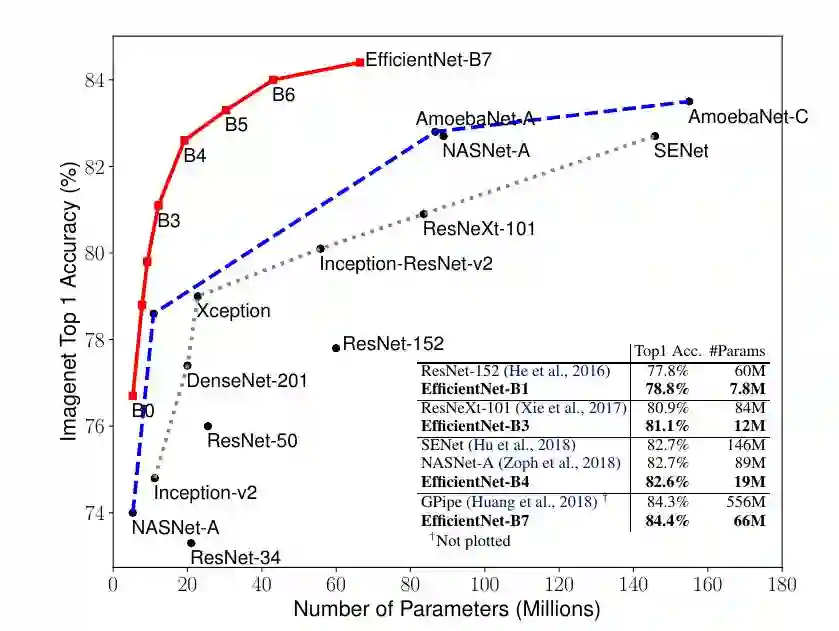
图:模型参数和准确率图
我们可以看到,EfficientNet 比之前最好的模型 GPipe 要小 8.4 倍,但是效果比它还要好。
半监督学习这里指的是通过未标注的图片来预训练学习特征,然后用少量监督的数据进行学习。最新的文章是 Google DeepMind 的《Data-Efficient Image Recognition with Contrastive Predictive Coding》。这篇文章通过 Contrastive Predictive Coding 的方法来从大量未标注的数据量提取特征。在这些特征上简单的加上一个线性的 softmax 层,在 ImageNet 上就可以超过使用 AlexNet 有监督学习的模型。
如果每个类的训练数据只有 13 个,则本文的方法比只用 13 个数据训练的模型的 Top-5 准确率要高 20%,比之前最好的半监督模型高 10%。传统的很多无监督的特征在少量数据会比较好,但是当数据量足够多的时候会比完全的监督学习要差,但是本文的方法得到的特征使用全部的 ImageNet 数据训练,也可以达到和完全监督学习类似的效果,这说明它学到的特征足够好。
二、语音识别
语音识别系统是一个非常复杂的系统,在深度学习技术之前的主流系统都是基于 HMM 模型。它通常时候 HMM-GMM 来建模 subword unit(比如 triphone),通过发音词典来把 subword unit 的 HMM 拼接成词的 HMM,最后解码器还要加入语言模型最终来融合声学模型和语言模型在巨大的搜索空间里寻找最优的路径。
Hinton 一直在尝试使用深度神经网络来改进语音识别系统,最早(2006 年后)的工作是 2009 年发表的《Deep belief networks for phone recognition》,这正是 Pretraining 流行的时期,把 DBN 从计算机视觉用到语音识别是非常自然的想法。类似的工作包括 2010 年的《Phone Recognition using Restricted Boltzmann Machines》。但是这些工作只是进行最简单的 phone 分类,也就是判断每一帧对应的 phone,这距离连续语音识别还相差的非常远。
真正把深度神经网络用于语音识别的重要文章是 Hinton 等人 2012 年《Deep Neural Networks for Acoustic Modeling in Speech Recognition》的文章,这篇文章使用 DNN 替代了传统 HMM-GMM 声学模型里的 GMM 模型,从此语音识别的主流框架变成了 HMM-DNN 的模型。接着在 2013 年 Sainath 等人在《Deep convolutional neural networks for LVCSR》用 CNN 替代普通的全连接网络。从 George 等人的文章《Improving deep neural networks for LVCSR using rectified linear units and dropout》也可以发现在计算机视觉常用的一些技巧也用到了语音识别上。
前面的 HMM-DNN 虽然使用了深度神经网络来替代 GMM,但是 HMM 和后面的 N-gram 语言模型仍然存在,而且 DNN 本身的训练还需要使用 HMM-GMM 的强制对齐来提供帧级别的训练数据。
怎么构建一个 End-to-end 的语音识别系统一直是学术界关注的重点。RNN 我们现在处理时序数据的有力武器,2013 年的时候 Graves 等人在论文《Speech Recognition with Deep Recurrent Neural Networks》里把 RNN 用于了语音识别。这篇文章使用了 RNN 加上 CTC 损失函数,CTC 是后来的 Deep Speech 的核心。虽然”真正”把 CTC 用于语音识别是在 2013 年,但是 Graves 却是早在 2006 年的时候就在论文《Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks》提出了 CTC。
Hannun 等人在 2014 年提出的《Deep Speech: Scaling up end-to-end speech recognition》是首个效果能和 HMM-DNN 媲美的 End-to-end 系统,包括后续的《Deep Speech 2: End-to-End Speech Recognition in English and Mandarin》。Deep Speech 的系统非常简单,输入是特征序列,输出就是字符序列,没有 HMM、GMM、发音词典这些模块,甚至没有 phone 的概念。
除了基于 CTC 损失函数的 End-to-end 系统,另外一类 End-to-end 系统借鉴了机器翻译等系统常用的 seq2seq 模型。这包括最早的《Listen, attend and spell: A neural network for large vocabulary conversational speech recognition》,Google 的《State-of-the-art Speech Recognition With Sequence-to-Sequence Models》总结了用于语音识别的 SOTA 的一些 Seq2Seq 模型,并且称他们在实际的系统中使用了这个模型之后词错误率从原来的 6.7%下降到 5.6%。这是首个在业界真正得到应用的 End-to-end 的语音识别系统(虽然 Andrew Ng 领导的百度 IDL 提出了 Deep Speech 和 Deep Speech2,但是在百度的实际系统中并没有使用它)。
下图是常见数据集上的效果,拿 SwitchBoard 为例,在 2006 年之前的进展是比较缓慢的,但是在使用了深度学习之后,词错误率持续下降,图中是 2017 年的数据,微软的系统已经降到了 6.3%的词错误率。

图:词错误率变化
三、自然语言处理
和语音识别不同,自然语言处理是一个很”庞杂”的领域,语音识别就一个任务——把声音变成文字,即使加上相关的语音合成、说话人识别等任务,也远远无法和自然语言处理任务数量相比。自然语言处理的终极目标是让机器理解人类的语言,理解是一个很模糊的概念。相对论的每个词的含义我都可能知道,但是并不代表我理解了相对论。
因为这个原因,在这里我关注的是比较普适性的方法,这些方法能用到很多的子领域而不是局限于某个具体的任务。
自然语言和连续的语音与图像不同,它是人类创造的离散抽象的符号系统。传统的特征表示都是离散的稀疏的表示方法,其泛化能力都很差。比如训练数据中出现了很多”北京天气”,但是没有怎么出现”上海天气”,那么它在分类的时候预测的分数会相差很大。但是”北京”和”上海”很可能经常在相似的上下文出现,这种表示方法无法利用这样的信息。
在 2003 年到时候,Bengio 在论文《A Neural Probabilistic Language Model》就提出了神经网络的语言模型,通过 Embedding 矩阵把一个词编码成一个低维稠密的向量,这样实现相似上下文的共享——比如”北京”和”上海”经常在相似的上下文出现,则它们会被编码成比较相似的向量,这样即使”上海天气”在训练数据中不怎么出现,也能通过”北京天气”给予其较大的概率。
不过 2003 年的时候大家并不怎么关注神经网络,因此这篇文章当时并没有太多后续的工作。到了 2012 年之后,深度神经网络在计算机视觉和语音识别等领域取得了重大的进展,把它应用到自然语言处理领域也是非常自然的事情。但是这个时候面临一个问题——没有大量有监督的标注数据。这其实也是前面提到的自然语言处理是很”庞杂”的有关。
自然语言处理的任务太多了,除了机器翻译等少数直接面向应用并且有很强实际需求的任务有比较多的数据外,大部分任务的标注数据非常有限。和 ImageNet 这种上百万的标注数据集或者语音识别几千小时的标注数据集相比,很多自然语言处理的标注数据都是在几万最多在几十万这样的数量级。这是由自然语言处理的特点决定的,因为它是跟具体业务相关的。因此自然语言处理领域一直急需解决的就是怎么从未标注的数据里学习出有用的知识,这些知识包括语法的、语义的和世界知识。
Mikolov 等人 2013 年在《Efficient estimation of word representations in vector space》和《Distributed representations of words and phrases and their compositionality》开始了这段征程。他们提出的 Word2Vec 可以简单高效的学习出很好的词向量,如下图所示。
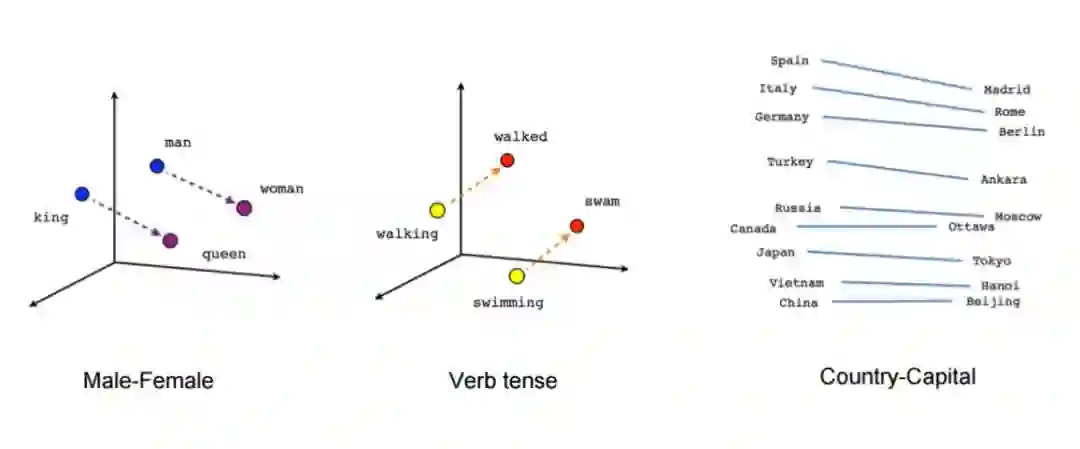
图:Word2Vec 的词向量
从上图我们可以发现它确实学到了一些语义知识,通过向量计算可以得到类似”man-woman=king-queen”。
我们可以把这些词向量作为其它任务的初始值。如果下游任务数据量很少,我们甚至可以固定住这些预训练的词向量,然后只调整更上层的参数。Pennington 等人在 2014 年的论文《Glove: Global vectors for word representation》里提出了 GloVe 模型。
但是 Word2Vec 无法考虑上下文的信息,比如”bank”有银行和水边的意思。但是它无法判断具体在某个句子里到底是哪个意思,因此它只能把这两个语义同时编码进这个向量里。但是在下游应用中的具体某个句子里,只有一个语义是需要的。当然也有尝试解决多义词的问题,比如 Neelakantan 等人在 2014 年的《Efficient Non-parametric Estimation of Multiple Embeddings per Word in Vector Space》,但都不是很成功。
另外一种解决上下文的工具就是 RNN。但是普通的 RNN 有梯度消失的问题,因此更常用的是 LSTM。LSTM 早在 1997 年就被 Sepp Hochreiter 和 Jürgen Schmidhuber 提出了。在 2016 年前后才大量被用于自然语言处理任务,成为当时文本处理的”事实”标准——大家认为任何一个任务首先应该就使用 LSTM。当然 LSTM 的其它变体以及新提出的 GRU 也得到广泛的应用。RNN 除了能够学习上下文的语义关系,理论上还能解决长距离的语义依赖关系(当然即使引入了门的机制,实际上太长的语义关系还是很难学习)。
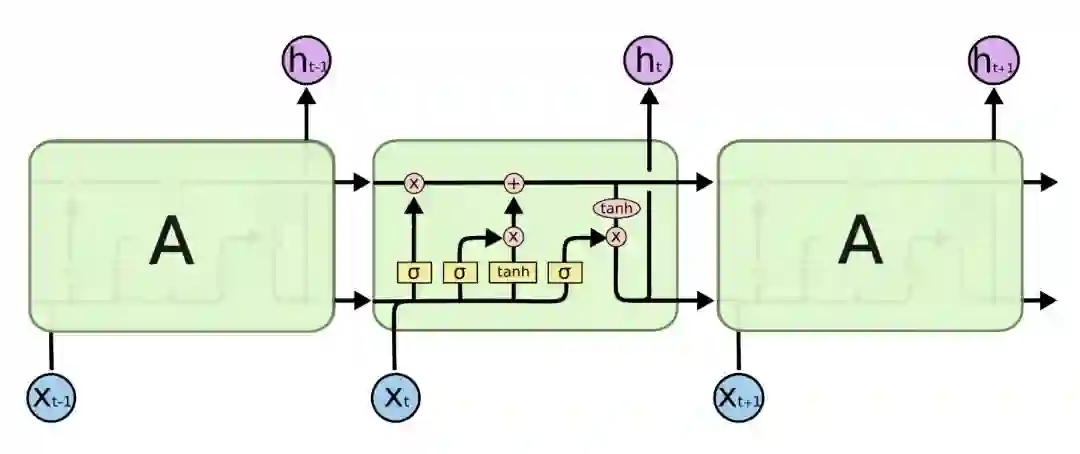
图:LSTM
很多 NLP 的输入是一个序列,输出也是一个序列,而且它们之间并没有严格的顺序和对应关系。为了解决这个问题,seq2seq 模型被提了出来。最终使用 seq2seq 的是机器翻译。Sutskever 等人在 2014 年的论文《Sequence to Sequence Learning with Neural Networks》首次使用了 seq2seq 模型来做机器翻译,Bahdanau 等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》里首次把 Attention 机制引入了机器翻译,从而可以提高长句子的翻译效果。而 Google 在论文里《Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》介绍了他们实际系统中使用神经网络机器翻译的一些经验,这是首次在业界应用的神经网络翻译系统。

图:LSTM
seq2seq 加 Attention 成为了解决很多问题的标准方法,包括摘要、问答甚至对话系统开始流行这种 End-to-End 的 seq2seq 模型。
Google 2017 年在《Attention is All You Need》更是把 Attention 机制推向了极致,它提出了 Transformer 模型。因为 Attention 相对于 RNN 来说可以更好的并行,而且它的 Self-Attention 机制可以同时编码上下文的信息,它在机器翻译的 WMT14 数据上取得了第一的成绩。
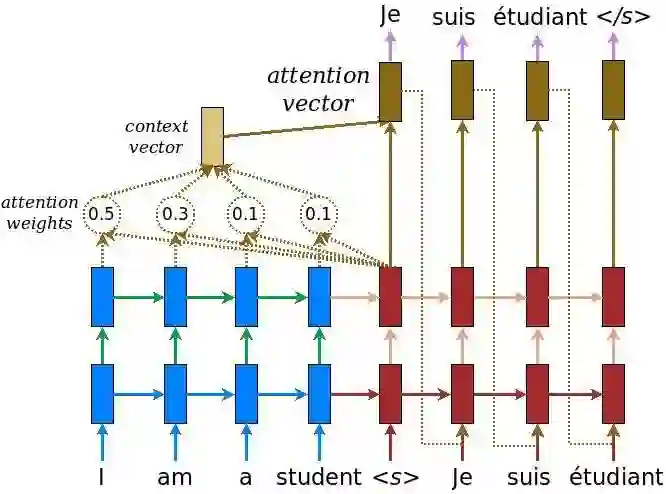
图:Neural Machine Translation
不过其实和 Attention 同时流行的还包括”Memory”,这大概是 2015 年的时候,当时流行”Reason, Attention and Memory”(简称 RAM),我记得当年 NIPS 还有个 RAM 的 workshop。Memory 就是把 LSTM 的 Cell 进一步抽象,变成一种存储机制,就行计算机的内存,然后提出了很多复杂的模型,包括 Neural Turing Machine(NTM)等等,包括让神经网络自动学习出排序等算法。当时也火过一阵,但最终并没有解决什么实际问题。
虽然 RNN/Transformer 可以学习出上下文语义关系,但是除了在机器翻译等少量任务外,大部分任务的训练数据都很少。因此怎么能够使用无监督的语料学习出很好的上下文语义关系就成为非常重要的课题。这个方向从 2018 年开始一直持续到现在,包括 Elmo、OpenAI GPT、BERT 和 XLNet 等,这些模型一次又一次的刷榜,引起了极大的关注。
ELMo 是 Embeddings from Language Models 的缩写,意思就是语言模型得到的(句子)Embedding。另外 Elmo 是美国儿童教育电视节目芝麻街(Sesame Street)里的小怪兽的名字。原始论文是《Deep contextualized word representations》,这个标题是很合适的,也就是用深度的 Transformer 模型来学习上下文相关的词表示。
这篇论文的想法其实非常非常简单,但取得了非常好的效果。它的思路是用深度的双向 RNN(LSTM)在大量未标注数据上训练语言模型,如下图所示。然后在实际的任务中,对于输入的句子,我们使用这个语言模型来对它处理,得到输出的向量,因此这可以看成是一种特征提取。但是和普通的 Word2Vec 或者 GloVe 的 pretraining 不同,ELMo 得到的 Embedding 是有上下文的。
比如我们使用 Word2Vec 也可以得到词”bank”的 Embedding,我们可以认为这个 Embedding 包含了 bank 的语义。但是 bank 有很多意思,可以是银行也可以是水边,使用普通的 Word2Vec 作为 Pretraining 的 Embedding,只能同时把这两种语义都编码进向量里,然后靠后面的模型比如 RNN 来根据上下文选择合适的语义——比如上下文有 money,那么它更可能是银行;而如果上下文是 river,那么更可能是水边的意思。但是 RNN 要学到这种上下文的关系,需要这个任务有大量相关的标注数据,这在很多时候是没有的。而 ELMo 的特征提取可以看成是上下文相关的,如果输入句子有 money,那么它就(或者我们期望)应该能知道 bank 更可能的语义,从而帮我们选择更加合适的编码。
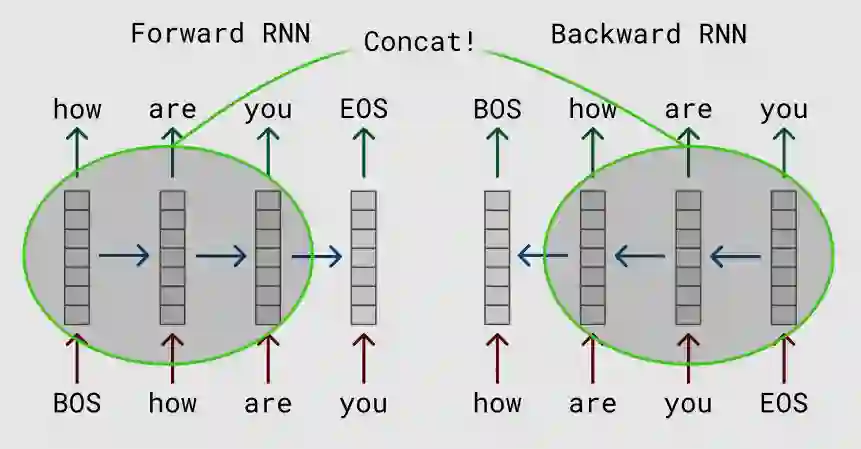
图:RNN 语言模型
ELMo 学到的语言模型参数是固定的,下游的任务把它的隐状态作为特征。而来自论文《Improving Language Understanding by Generative Pre-Training》的 OpenAI GPT 模型会根据特定的任务进行调整(通常是微调),这样得到的句子表示能更好的适配特定任务。它的思想其实也很简单,使用 Transformer 来学习一个语言模型,对句子进行无监督的 Embedding,然后根据具体任务对 Transformer 的参数进行微调。因为训练的任务语言模型的输入是一个句子,但是下游的很多任务的输入是两个,因此 OpenAI GPT 通过在两个句子之前加入特殊的分隔符来处理两个输入,如下图所示。
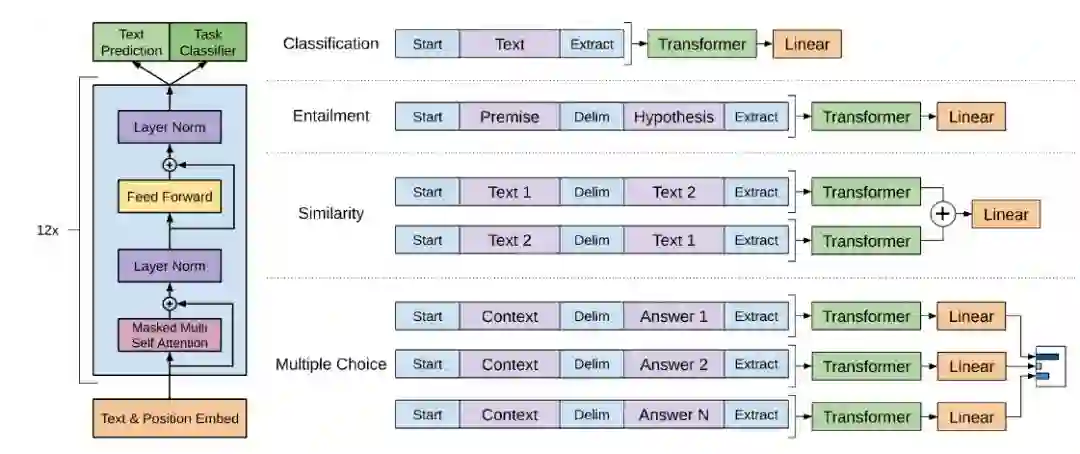
图:OpenAI GPT 处理下游任务的方法
OpenAI GPT 取得了非常好的效果,在很多任务上远超之前的第一。
ELMo 和 GPT 最大的问题就是传统的语言模型是单向的——我们是根据之前的历史来预测当前词。但是我们不能利用后面的信息。比如句子”The animal didn’t cross the street because it was too tired”。我们在编码 it 的语义的时候需要同时利用前后的信息,因为在这个句子中,it 可能指代 animal 也可能指代 street。根据 tired,我们推断它指代的是 animal,因为 street 是不能 tired。但是如果把 tired 改成 wide,那么 it 就是指代 street 了。
传统的语言模型,不管是 RNN 还是 Transformer,它都只能利用单方向的信息。比如前向的 RNN,在编码 it 的时候它看到了 animal 和 street,但是它还没有看到 tired,因此它不能确定 it 到底指代什么。如果是后向的 RNN,在编码的时候它看到了 tired,但是它还根本没看到 animal,因此它也不能知道指代的是 animal。Transformer 的 Self-Attention 理论上是可以同时 attend to 到这两个词的,但是根据前面的介绍,由于我们需要用 Transformer 来学习语言模型,必须用 Mask 来让它看不到未来的信息,因此它也不能解决这个问题。
那它是怎么解决语言模型只能利用一个方向的信息的问题?答案是它的 pretraining 训练的不是普通的语言模型,而是 Mask 语言模型。这个思路是在 Google 的论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》里提出了,也就是我们现在熟知的 BERT 模型。
BERT 一出来就横扫了各种 NLP 的评测榜单,引起了极大的关注。就在媒体都在用”最强 NLP 模型”之类的词赞美 BERT 的时候,最近又出现了 XLNet,又一次横扫了各大榜单。它认为 BERT 有两大问题:它假设被 Mask 的词之间在给定其它非 Mask 词的条件下是独立的,这个条件并不成立;Pretraining 的时候引入了特殊的[MASK],但是 fine-tuing 又没有,这会造成不匹配。XLNet 通过 Permutation 语言模型来解决普通语言模型单向信息流的问题,同时借鉴 Transformer-XL 的优点。通过 Two-Stream Self-Attention 解决 target unaware 的问题,最终训练的模型在很多任务上超过 BERT 创造了新的记录。
四、强化学习
强化学习和视觉、听觉和语言其实不是一个层面上的东西,它更多的是和监督学习、非监督学习并行的一类学习机制(算法),但是我认为强化学习是非常重要的一种学习机制。
监督学习的特点是有一个“老师”来“监督”我们,告诉我们正确的结果是什么。在我们在小的时候,会有老师来教我们,本质上监督学习是一种知识的传递,但不能发现新的知识。对于人类整体而言,真正(甚至唯一)的知识来源是实践——也就是强化学习。比如神农尝百草,最早人类并不知道哪些草能治病,但是通过尝试,就能学到新的知识。学到的这些知识通过语言文字记录下来,一代一代的流传下来,从而人类社会作为整体能够不断的进步。
与监督学习不同,没有一个“老师”会“监督“我们。比如下围棋,不会有人告诉我们当前局面最好的走法是什么,只有到游戏结束的时候我们才知道最终的胜负,我们需要自己复盘(学习)哪一步是好棋哪一步是臭棋。自然界也是一样,它不会告诉我们是否应该和别人合作,但是通过优胜劣汰,最终”告诉”我们互相协助的社会会更有竞争力。和前面的监督、非监督学习相比有一个很大的不同点:在强化学习的 Agent 是可以通过 Action 影响环境的——我们的每走一步棋都会改变局面,有可能变好也有可能变坏。
它要解决的核心问题是给定一个状态,我们需要判断它的价值(Value)。价值和奖励(Reward)是强化学习最基本的两个概念。对于一个 Agent(强化学习的主体)来说,Reward 是立刻获得的,内在的甚至与生俱来的。比如处于饥饿状态下,吃饭会有 Reward。而 Value 是延迟的,需要计算和慎重考虑的。比如饥饿状态下去偷东西吃可以有 Reward,但是从 Value(价值观)的角度这(可能)并不是一个好的 Action。为什么不好?虽然人类的监督学习,比如先贤告诉我们这是不符合道德规范的,不是好的行为。但是我们之前说了,人类最终的知识来源是强化学习,先贤是从哪里知道的呢?有人认为来自上帝或者就是来自人的天性,比如“人之初性本善”。如果从进化论的角度来解释,人类其实在玩一场”生存”游戏,有遵循道德的人群和有不遵循的人群,大自然会通过优胜劣汰”告诉”我们最终的结果,最终我们的先贤“学到”了(其实是被选择了)这些道德规范,并且把这些规范通过教育(监督学习)一代代流传下来。
因为强化学习只是一种方法,它在很多领域都有应用,机器人、控制和游戏是其最常见的应用领域,但是其它领域包括自然语言处理的对话系统,也经常会用到强化学习技术。强化学习和机器学习一样有很多方法:根据是否对环境建模可以分为 Model based 和 Mode free 的方法;按照是否有 Value 函数又分为 Value based 方法和 Policy Gradient,但是又可以把两者结合得到 Actor-Critic 方法……
我们这里重点关注深度学习和强化学习结合的一些方法。
Google DeepMind 在 Nature 发表的文章《Human-level Control through Deep Reinforcement Learning》首次实现了 End-to-End 的深度强化学习模型 Deep Q-Networks,它的输入是游戏画面的像素值,而输出是游戏的控制命令,它的原理如下图所示。
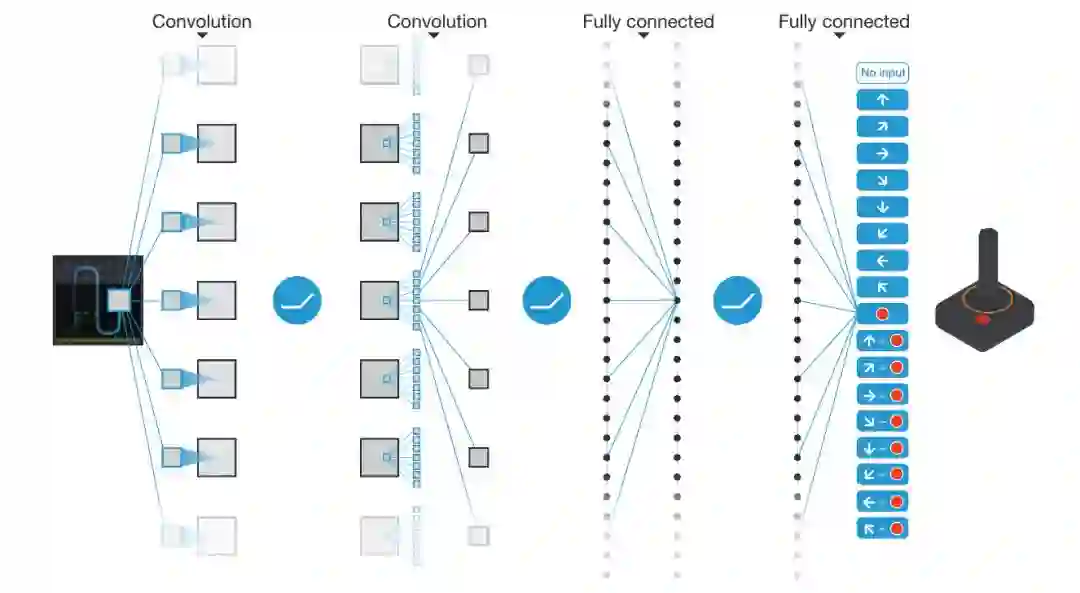
图:Deep Q-Networks
通过 Experience Replay 来避免同一个 trajectory 数据的相关性,同时使用引入了一个 Target Network 𝑄𝜃′来解决 target 不稳定的问题,Deep Q-Networks 在 Atari 2600 的 49 个游戏中,有 29 个游戏得分达到了人类的 75%以上,而其中 23 个游戏中的得分超过了人类选手,如下图所示。
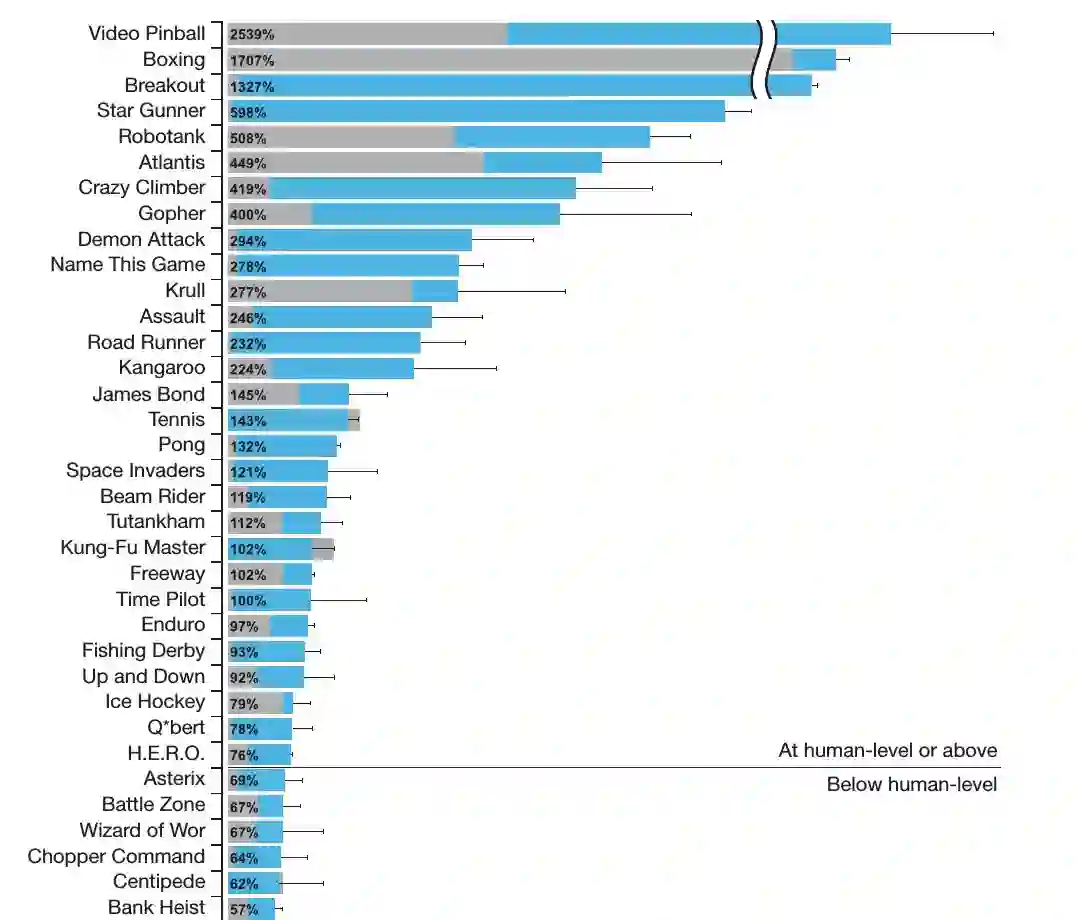
图:Deep Q-Networks 在 Atari2600 平台上的得分
Deep Q-Networks 的后续改进工作包括《Prioritized Experience Replay》、《Deep Reinforcement Learning with Double Q-learning》和《Rainbow: Combining Improvements in Deep Reinforcement Learning》等。
而 Policy Gradient 类的工作包括《Trust Region Policy Optimization》(TRPO)、Deterministic Policy Gradient Algorithms》(DPG)、《Expected Policy Gradients for Reinforcement Learning》、《Proximal Policy Optimization Algorithms》(PPO)等。
而在游戏方面,Google DeepMind 发表的大家耳熟能详的 AlphaGo、AlphaGoZero 和 AlphaZero 系列文章。
围棋解决了之后,大家也把关注点放到了即时战略游戏上,包括 DeepMind 的《AlphaStar: An Evolutionary Computation Perspective》和 OpenAI Five 在星际争霸 2 和 Dota2 上都取得了很大的进展。
此外,在 Meta Learning、Imitation Learning 和 Inverse Reinforcement Learning 也出现了一些新的进展,我们这里就不一一列举了。

未来展望
最近一个比较明显的趋势就是非监督(半监督)学习的进展,首先是在自然语言处理领域,根据前面的分析,这个领域的任务多、监督数据少的特点一直期望能在这个方向有所突破。在计算机视觉我们也看到了 Google DeepMind 的最新进展,我觉得还会有更多的突破。
相对而言,在语音识别领域这方面的进展就慢了一些,先不说无监督,就连从一个数据集(应用场景)Transfer 到另一个数据集(场景)都很难。比如我们有大量普通话的数据,怎么能够使用少量的数据就能在其它带方言的普通话上进行很好的识别。虽然有很多 Adaptation 的技术,但是总体看起来还是很难达到预期。
另外一个就是 End-to-End 的系统在业界(除了 Google 声称使用)还并没有得到广泛应用,当然这跟语音领域的玩家相对很少有关,况且目前的系统效果也不错,完全推倒重来没有必要(除非计算机视觉领域一样深度学习的方法远超传统的方法)。原来的 HMM-GMM 改造成 HMM-DNN 之后再加上各种 Adaptation 和 sequence discriminative training,仍然可以得到 SOTA 的效果,所以相对来讲使用 End-to-end 的动力就更加不足。虽然学术界大力在往这个方向发展,但是老的语音玩家(Google 之外)并不怎么买账。
从长远来讲,要“真正”实现人工智能,我认为还得结合视觉、听觉(甚至味觉和触觉等)和语言,使用无监督、监督和强化学习的方法,让”机器”有一个可以自己控制的身体,像三岁小孩一样融入”真正”的物理世界和人类社会,才有可能实现。这除了需要科技上的进步,还需要我们人类在思想上的巨大突破才有可能实现。
作者简介:李理,环信人工智能研发中心 VP,十多年自然语言处理和人工智能研发经验。主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。



热 文 推 荐
☞Google Chrome 工程师:JavaScript 不容错过的八大优化建议
☞6月Top 20榜单出炉啦! 万万没想到区块链大佬竟在忙这个...
☞泪目!Linux之父:我就是觉得苹果太没意思!
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。
![]()
你点的每个“在看”,我都认真当成了喜欢






