【深度学习】从Pix2Code到CycleGAN:2017年深度学习重大研究进展全解读
选自Statsbot
作者:Eduard Tyantov
机器之心编译
2017 年只剩不到十天,随着 NIPS 等重要会议的结束,是时候对这一年深度学习领域的重要研究与进展进行总结了。来自机器学习创业公司的 Eduard Tyantov 最近就为我们整理了这样一份列表。想知道哪些深度学习技术即将影响我们的未来吗?本文将给你作出解答。

1. 文本
1.1 谷歌神经机器翻译
去年,谷歌宣布上线 Google Translate 的新模型,并详细介绍了所使用的网络架构——循环神经网络(RNN)。
关键结果:与人类翻译准确率的差距缩小了 55-85%(研究者使用 6 个语言对的评估结果)。但是该模型如果没有谷歌的大型数据集,则很难复现这么优秀的结果。

参考阅读:
重磅 | 谷歌翻译整合神经网络:机器翻译实现颠覆性突破(附论文)
专访 | 谷歌神经网络翻译系统发布后,我们和 Google Brain 的工程师聊了聊
1.2 谈判会达成吗?
你或许听说过「Facebook 因为聊天机器人失控、创造自己语言而关闭聊天机器人」的消息。这个机器人是用来进行谈判的,其目的是与另一个智能体进行文本谈判,然后达成协议:如何把物品(书籍、帽子等)分成两份。谈判中每个智能体都有自己的目标,而对方并不知道。谈判不可能出现未达成协议的情况。
研究者在训练过程中收集人类谈判的数据集,训练监督式循环网络。然后,让用强化学习训练出的智能体自己与自己交流,直到获得与人类相似的谈判模式。
该机器人学会了一种真正的谈判策略——对某个交易的特定方面假装产生兴趣,然后再放弃它们,以达到真实目标。这是第一次尝试此类互动机器人,而且也比较成功。
当然,称该机器人创造了一种新语言的说法过于夸张了。和同一个智能体进行谈判的训练过程中,研究者无法限制文本与人类语言的相似度,然后算法修改了互动语言。这是很寻常的事。
参考阅读:
业界 | 让人工智能学会谈判,Facebook 开源端到端强化学习模型
2. 语音
2.1 WaveNet:一种针对原始语音的生成模型
DeepMind 的研究者基于先前的图像生成方法构建了一种自回归全卷积模型 WaveNet。该模型是完全概率的和自回归的(fully probabilistic and autoregressive),其每一个音频样本的预测分布的前提是所有先前的样本;不过研究表明它可以有效地在每秒音频带有数万个样本的数据上进行训练。当被应用于文本转语音时,它可以得到当前最佳的表现,人类听众评价它在英语和汉语上比当前最好的参数(parametric)和拼接(concatenative)系统所生成的音频听起来都显著更为自然。
单个 WaveNet 就可以以同等的保真度捕获许多不同说话者的特点,而且可以通过调节说话者身份来在它们之间切换。当训练该模型对音乐建模时,我们发现它可以生成全新的、而且往往具有高度真实感的音乐片段。该研究还证明其可以被用作判别模型,可以为音速识别(phoneme recognition)返回很有希望的结果。

该网络以端到端的方式进行训练:文本作为输入,音频作为输出。研究者得到了非常好的结果,机器合成语音水平与人类差距缩小 50%。

该网络的主要缺陷是低生产力,因为它使用自回归,声音按序列生成,需要 1-2 分钟的时间才能生成一秒音频。
参考阅读:
DeepMind WaveNet,将机器合成语音水平与人类差距缩小 50%
2.2 唇读
唇读(lipreading)是指根据说话人的嘴唇运动解码出文本的任务。传统的方法是将该问题分成两步解决:设计或学习视觉特征、以及预测。最近的深度唇读方法是可以端到端训练的(Wand et al., 2016; Chung & Zisserman, 2016a)。目前唇读的准确度已经超过了人类。

Google DeepMind 与牛津大学合作的一篇论文《Lip Reading Sentences in the Wild》介绍了他们的模型经过电视数据集的训练后,性能超越 BBC 的专业唇读者。
该数据集包含 10 万个音频、视频语句。音频模型:LSTM,视频模型:CNN + LSTM。这两个状态向量被馈送至最后的 LSTM,然后生成结果(字符)。

训练过程中使用不同类型的输入数据:音频、视频、音频+视频。即,这是一个「多渠道」模型。

参考阅读:
如何通过机器学习解读唇语?DeepMind 要通过 LipNet 帮助机器「看」懂别人说的话
2.3 人工合成奥巴马:嘴唇动作和音频的同步
华盛顿大学进行了一项研究,生成美国前总统奥巴马的嘴唇动作。选择奥巴马的原因在于网络上有他大量的视频(17 小时高清视频)。

研究者使用了一些技巧来改善该研究的效果。

3. 计算机视觉
3.1. OCR:谷歌地图与街景
谷歌大脑团队在其文章中报道了如何把新的 OCR(光学字符识别)引擎引入其地图中,进而可以识别街头的标志与商标。


在该技术的发展过程中,谷歌还给出了新的 FSNS(French Street Name Signs),它包含了大量的复杂案例。
为了识别标志,网络最多使用 4 张图片。特征通过 CNN 提取,在空间注意力(考虑像素坐标)的帮助下缩放,最后结果被馈送至 LSTM。

相同方法被用于识别广告牌上店铺名称的任务上(存在大量噪音数据,网络本身必须关注正确的位置)。这一算法被应用到 800 亿张图片之上。
3.2 视觉推理
视觉推理指的是让神经网络回答根据照片提出的问题。例如,「照片中有和黄色的金属圆柱的尺寸相同的橡胶物体吗?」这样的问题对于机器是很困难的,直到最近,这类问题的回答准确率才达到了 68.5%。
为了更深入地探索视觉推理的思想,并测试这种能力能否轻松加入目前已有的系统,DeepMind 的研究者们开发了一种简单、即插即用的 RN 模块,它可以加载到目前已有的神经网络架构中。具备 RN 模块的神经网络具有处理非结构化输入的能力(如一张图片或一组语句),同时推理出事物其后隐藏的关系。
使用 RN 的网络可以处理桌子上的各种形状(球体、立方体等)物体组成的场景。为了理解这些物体之间的关系(如球体的体积大于立方体),神经网络必须从图像中解析非结构化的像素流,找出哪些数据代表物体。在训练时,没有人明确告诉网络哪些是真正的物体,它必须自己试图理解,并将这些物体识别为不同类别(如球体和立方体),随后通过 RN 模块对它们进行比较并建立「关系」(如球体大于立方体)。这些关系不是硬编码的,而是必须由 RN 学习——这一模块会比较所有可能性。最后,系统将所有这些关系相加,以产生场景中对所有形状对的输出。

目前的机器学习系统在 CLEVR 上标准问题架构上的回答成功率为 68.5%,而人类的准确率为 92.5%。但是使用了 RN 增强的神经网络,DeepMind 展示了超越人类表现的 95.5% 的准确率。RN 增强网络在 20 个 bAbI 任务中的 18 个上得分均超过 95%,与现有的最先进的模型相当。值得注意的是,具有 RN 模块的模型在某些任务上的得分具有优势(如归纳类问题),而已有模型则表现不佳。
下图为视觉问答的架构。问题在经过 LSTM 处理后产生一个问题嵌入(question embedding),而图像被一个 CNN 处理后产生一组可用于 RN 的物体。物体(图中用黄色、红色和蓝色表示)是在卷积处理后的图像上使用特征图向量构建的。该 RN 网络会根据问题嵌入来考虑所有物体对之间的关系,然后会整合所有这些关系来回答问题。
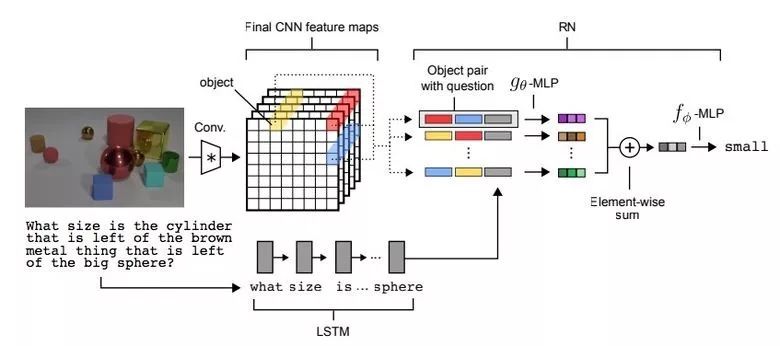
参考阅读:
关系推理水平超越人类:DeepMind 展示全新神经网络推理预测技术
3.3 Pix2Code
哥本哈根的一家初创公司 UIzard Technologies 训练了一个神经网络,能够把图形用户界面的截图转译成代码行,成功为开发者们分担了部分网站设计流程。令人惊叹的是,同一个模型能跨平台工作,包括 iOS、Android 和 Web 界面,从目前的研发水平来看,该算法的准确率达到了 77%。
为了实现这一点,研究者们需要分三个步骤来训练,首先,通过计算机视觉来理解 GUI 图像和里面的元素(按钮、条框等)。接下来模型需要理解计算机代码,并且能生成在句法上和语义上都正确的样本。最后的挑战是把之前的两步联系起来,需要它用推测场景来生成描述文本。

虽然该工作展示了这样一种能自动生成 GUI 代码的潜力系统,但该研究只是开发了这种潜力的皮毛。目前的 Pix2Code 模型由相对较少的参数组成,并且只能在相对较小的数据集上训练。而构建更复杂的模型,并在更大的数据集上训练会显著地提升代码生成的质量。并且采用各种正则化方法和实现注意力机制(attention mechanism [1])也能进一步提升生成代码的质量。同时该模型采用的独热编码(one-hot encoding)并不会提供任何符号间关系的信息,而采用 word2vec [12] 那样的词嵌入模型可能会有所好转。因此将图片转换为 UI 代码的工作仍处于研究之中,目前尚未投入实际使用。
项目地址:https://github.com/tonybeltramelli/pix2code
参考阅读:
深度学习助力前端开发:自动生成 GUI 图代码(附试用地址)
3.4 SketchRNN:教机器画画
你可能看过谷歌的 Quick, Draw! 数据集,其目标是 20 秒内绘制不同物体的简笔画。谷歌收集该数据集的目的是教神经网络画画。

研究者使用 RNN 训练序列到序列的变分自编码器(VAE)作为编解码机制。
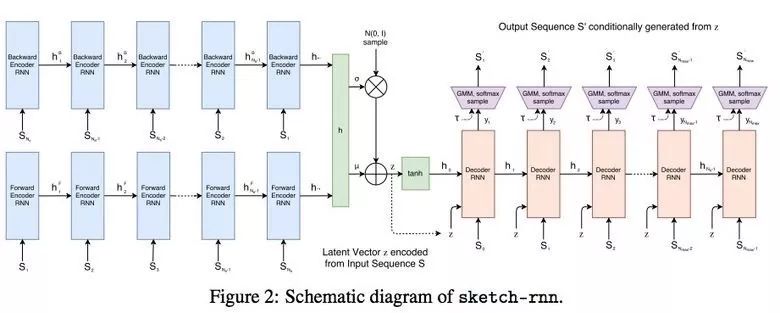
最终,该模型获取表示原始图像的隐向量(latent vector)。
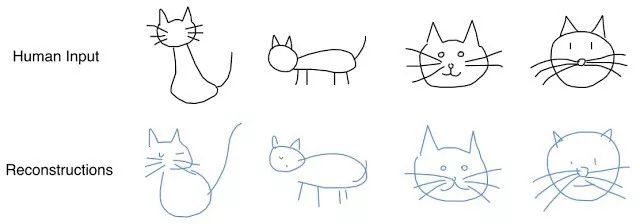
解码器可从该向量中提取图画,你可以改变它,生成新的简笔画。

甚至使用向量算术来绘制猫猪(catpig):

参考阅读:
谷歌发布 Quick Draw 涂鸦数据集:5000 万张矢量图,345 个类别
3.5 GAN
GAN 是深度学习领域里的一个热门话题。目前这种方法大多用于处理图像,所以本文也主要介绍这一方面。GAN 的全称为生成对抗网络,是 2014 年由 Ian Goodfellow 及其蒙特利尔大学的同事们率先提出的。这是一种学习数据的基本分布的全新方法,让生成出的人工对象可以和真实对象之间达到惊人的相似度。

GAN 背后的思想非常直观:生成器和鉴别器两个网络彼此博弈。生成器的目标是生成一个对象(比如人的照片),并使其看起来和真的一样。而鉴别器的目标就是找到生成出的结果和真实图像之间的差异。鉴别器通常会从数据集中给出图像用于对比。
由于很难找出两个网络之间的平衡点,训练通常难以连续进行。大多数情况下鉴别器会获胜,训练陷入停滞。尽管如此,由于鉴别器的设计可以帮助我们从损失函数设定这样的复杂问题中解决出来(例如:提升图片质量),所以 GAN 获得了众多研究者的青睐。
典型的 GAN 训练结果——卧室和人脸。


在此之前,我们通常会考虑使用自编码器(Sketch-RNN),让其将原始数据编码成隐藏表示。这和 GAN 中生成器所做的事情一样。
你可以在这个项目中(http://carpedm20.github.io/faces/)找到使用向量生成图片的方法。你可以自行尝试调整向量,看看生成的人脸会如何变化。

这种算法在隐空间上同样适用:「一个戴眼镜的男人」减去「男人」加上「女人」就等于「一个戴眼镜的女人」。

参考阅读:
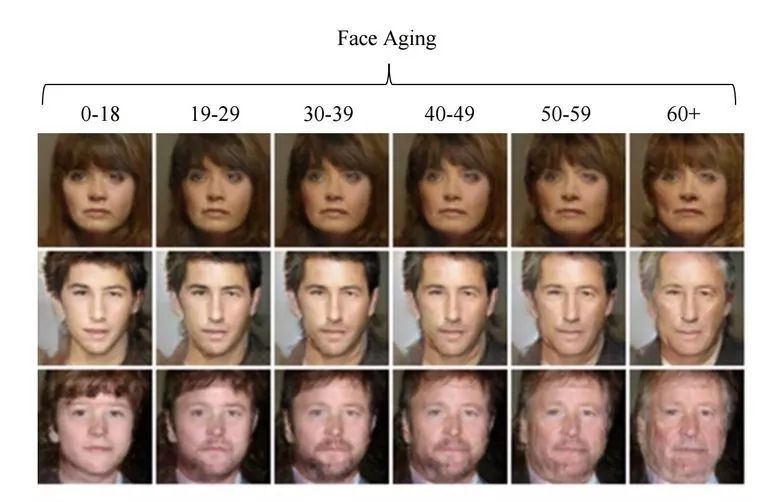
3.6 使用 GAN 改变面部年龄
如果在训练过程中获得一个可控制的隐向量参数,我们就可以在推断阶段修改这个向量以控制图像的生成属性,这种方法被称为条件 GAN。
论文 Face Aging With Conditional Generative Adversarial Networks 的作者使用在 IMDB 数据集上预训练模型而获得年龄的预测方法,然后研究者基于条件 GAN 修改生成图像的面部年龄。
参考阅读:
3.7 专业摄影作品
谷歌已经开发了另一个非常有意思的 GAN 应用,即摄影作品的选择和改进。开发者在专业摄影作品数据集上训练 GAN,其中生成器试图改进照片的表现力(如更好的拍摄参数和减少对滤镜的依赖等),判别器用于区分「改进」的照片和真实的作品。
训练后的算法会通过 Google Street View 搜索最佳构图,获得了一些专业级的和半专业级的作品评分。
参考阅读:
3.8 pix2pix
伯克利人工智能研究室(BAIR)在 2016 年非常引人注目的研究 Image-to-Image Translation with Conditional Adversarial Networks 中,研究人员解决了图像到图像的生成问题。例如需要使用卫星图像创建地图,或使用素描创建逼真的目标纹理等。

这里有另一个非常成功的条件 GAN 应用案例。在该情况下,条件将变为整张图像。此外,UNet 在图像分割中十分受欢迎,经常用于生成器的体系结构,且该论文使用了新型 PatchGAN 分类器作为处理模糊图像的判别器。
该论文的作者还发布了他们网络的在线演示:https://affinelayer.com/pixsrv/

源代码:https://github.com/phillipi/pix2pix
参考阅读:
教程 | 你来手绘涂鸦,人工智能生成「猫片」:edges2cats 图像转换详解
3.9 CycleGAN
为了应用 Pix2Pix,我们需要包含了不同领域图像对的数据集。收集这样的数据集并不困难,但对于更复杂一点的转换目标或风格化目标等操作,原则上是找不到这样的目标对。
因此,Pix2Pix 的作者为了解决这样的问题提出了在不同图像领域之间转换而不需要特定图像对的 CycleGAN 模型,原论文为《Unpaired Image-to-Image Translation》。

该论文的主要想法是训练两对生成器-判别器模型以将图像从一个领域转换为另一个领域,在这过程中我们要求循环一致性。即在序列地应用生成器后,我们应该得到一个相似于原始 L1 损失的图像。因此我们需要一个循环损失函数(cyclic loss),它能确保生成器不会将一个领域的图像转换到另一个和原始图像完全不相关的领域。

这个方法允许我们学习将马映射到斑马。

这样的转换通常是不稳定的,并且经常创建一些不成功的案例:

源代码:https://github.com/junyanz/CycleGAN
参考阅读:
3.10 肿瘤分子学的进展
机器学习正在帮助改善医疗的手段,它除了在超声波识别、MPI 和诊断等方面的应用,还能寻找对抗癌症的性药物。
简单来说,在对抗自编码器(AAE)的帮助下,我们可以学习药物分子的潜在表征,并用来搜索新的药物结构。该项研究中,研究者发现了 69 个分子,且有一半的分子可用来治疗癌症和其它一些比较严重的疾病。

参考阅读:
3.11 对抗性攻击
对抗性样本这一领域也有非常大的活力,研究者希望找到这种令模型不稳定的因素而提升识别性能。例如在 ImageNet 中,训练的模型在识别加了一些噪点的样本会完全识别错误,这样加了噪点的图像可能在我们人眼看来是没有问题的。这一问题展现在下图中,熊猫的图像加了一点噪声就会被错误识别为长臂猿。

Goodfellow et al. (2014b) 表明,出现这些对抗样本的主要原因之一是模型过度线性化。神经网络主要是基于线性模块而构建的,因此它们实现的整体函数被证明是高度线性的。虽然这些线性函数很容易优化,但如果一个线性函数具有许多输入,那么它的值可以非常迅速地改变。如果我们用 ϵ 改变每个输入,那么权重为 w 的线性函数改变可以达到 ϵ∥w∥_1,如果 w 的维度较高,那么这会是一个非常大的数值。对抗训练通过鼓励网络在训练数据附近的局部区域恒定来限制这一高度敏感的局部线性行为。这可以被看作是一种明确地向监督神经网络引入局部恒定先验的方法。
下面一个例子表示特殊的眼镜可以欺骗人脸识别系统,所以在训练特定的模型时,我们需要考虑这种对抗性攻击并使用对抗性样本提高模型的鲁棒性。

这种使用符号的方法也不能被正确地识别。

参考阅读:
学界 | OpenAI 探讨人工智能安全:用对抗样本攻击机器学习
4 强化学习
强化学习(RL)或使用了强化机制的学习也是机器学习中最有趣和发展活跃的方法之一。
该方法的本质是在一个根据经验给予奖励(正如人类的学习方式)的环境中学习智能体的成功行为。

RL 在游戏、机器人和系统控制(例如,交通)中被广泛应用。
当然,每个人都已经听说了 AlphaGo 在游戏中击败过多个顶尖专业选手。研究者使用 RL 训练 AlphaGo 的过程是:让机器通过自我对弈提升决策能力。
4.1 结合非受控辅助任务的强化训练
去年,DeepMind 通过使用 DQN 玩电子游戏取得了超越人类的表现。最近,人们已经开发出了能让机器玩更加复杂的游戏(如 Doom)的算法。
大多数研究关注于学习加速,因为学习智能体与环境交互的经验需要在现代 GPU 上执行很长时间的训练。
DeepMind 的博客(https://deepmind.com/blog/reinforcement-learning-unsupervised-auxiliary-tasks/)中报告了引入附加损失(辅助任务)的办法,例如预测帧变化(像素控制)使智能体更充分地理解动作的后果,可以显著加快学习过程。

参考阅读:
突破 | DeepMind 为强化学习引入无监督辅助任务,人工智能的 Atari 游戏水平达到人类的 9 倍
4.2 学习机器人
OpenAI 对在虚拟环境中训练智能体进行了积极的研究,相比在现实世界中进行实验要安全得多。
在其中一个研究中(https://blog.openai.com/robots-that-learn/),他们证明了一次性学习(one-shot learning)是可能实现的:在 VR 中的一个人展示如何执行任务,并且算法只需要一次展示就能学会然后在实际条件下将其重现。

如果只有人类有这个能力就好了。:)
参考阅读:
学界 | OpenAI 推出机器人新系统:机器可通过 VR 演示自主学习新任务
4.3 学习人类的偏好
这是 OpenAI(https://blog.openai.com/deep-reinforcement-learning-from-human-preferences/)和 DeepMind 都曾研究过的课题。基本目标是智能体有一个任务,算法为人类提供两个可能的解决方案,并指出那个更好。该过程需要重复迭代,并且算法接收来自学习如何解决问题的人类的 900 比特大小的反馈(二进制标记)。

一如既往,人类必须谨慎判断,思考他教给机器究竟是什么。例如,评估器得出算法确实想要拿到某个物体,但实际上,人类只是想进行一次模拟实验。
参考阅读:
OpenAI 联合 DeepMind 发布全新研究:根据人类反馈进行强化学习
4.4 在复杂环境中的运动
这是 DeepMind 的另一项研究(https://deepmind.com/blog/producing-flexible-behaviours-simulated-environments/)。为了教会机器人执行复杂的行为(行走、跳跃,等),甚至达到类似人体的动作,你需要非常重视损失函数的选择,以获得想要的行为。然而,让算法自身通过简单的奖励机制学习复杂的行为或许会有更好的效果。
为了达到这个目标,研究者通过构建一个包含障碍物的复杂环境教智能体(人体模拟器)执行复杂的动作,结合简单的奖励机制提高动作质量。

可以通过视频查看研究取得的令人印象深刻的结果。
最后,我给出 OpenAI 近日发布的应用强化学习的算法的链接(https://github.com/openai/baselines)。这个解决方案比标准的 DQN 方法更好。
参考阅读:
学界 | DeepMind论文三连发:如何在仿真环境中生成灵活行为
5 其它
5.1 数据中心冷却系统
在 2017 年 7 月,谷歌报告称他们利用 DeepMind 的机器学习研究成果降低了数据中心的能耗。
基于来自数据中心的几千个传感器的信息,谷歌开发者训练一个神经网络集成预测能量利用效率(PUE)以及更高效的数据中心管理方法。这是机器学习中非常令人印象深刻和重要的实际应用案例。

5.2 通用模型
如你所知,已训练模型的任务迁移性能很差,因为每个模型都是为特定的任务而设计的。谷歌大脑的一篇论文(https://arxiv.org/abs/1706.05137)在通用模型的研究上跨出了一小步。
研究者训练了一个模型,可以执行 8 个不同领域(文本、语音和图像)的任务。例如,不同语言的翻译、文本解析,以及图像、语音识别。
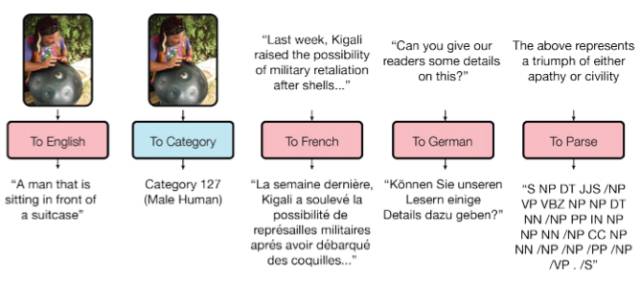
为了达到这个目的,他们使用多种不同的模块构建了一个复杂的网络架构以处理不同的输入数据并生成结果。编码器/解码器模块包含三种类型:卷积、注意和 MoE(https://arxiv.org/abs/1701.06538)。


他们几乎得到了完美的模型(作者并没有细调超参数)。
模型中存在不同领域知识的迁移,即,相比使用大量数据训练的任务(无迁移),该模型能获得几乎相同的性能。并且这个模型在小数据任务上表现得更好(例如,文本解析)。
不同任务所需的模块之间并不会互相干扰,有时甚至能互相辅助,例如,MoE 可以辅助 ImageNet 图像识别任务。
模型的 GitHub 地址:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/multimodel.py
参考阅读:
一个模型库学习所有:谷歌开源模块化深度学习系统 Tensor2Tensor
5.3. 一小时训练 ImageNet
Facebook 在其博文中告诉我们其工程师能够用 1 小时的时间通过 Imagenet 教会 ResNet-50 模型,不过其实现需要 256 块 GPU (Tesla P100)。
他们通过 Gloo 和 Caffe2 实现分布式学习。为了更有效,采用大批量的学习策略很有必要:梯度平均、特定学习率等。
结果,当从 8 块 GPU 扩展到 256 块时,效率可高达 90%。现在,Facebook 可以更快地进行实验。
参考阅读:
Facebook「1小时训练ImageNet」论文与MXNet团队发生争议,相关研究介绍
6. 新闻
6.1. 自动驾驶
自动驾驶领域正密集地发展,测试也在积极地开展。从最近事件中我们注意到英特尔收购 MobilEye,Uber 从谷歌剽窃自动驾驶技术的丑闻,以及首个自动驾驶死亡案例等等。
这里我提醒一件事:谷歌 Waymo 推出了 beta 版。谷歌是该领域的先驱者,可以假定他们的技术很好,因为其自动驾驶汽车里程已超过 300 万英里。
更近的事件则有自动驾驶汽车已在美国所有州允许上路测试。
6.2. 医疗

就像我说的,现代机器学习正开始应用于医疗。比如,谷歌与某医疗中心展开合作提升诊断。DeepMind 甚至还为此成立了一个独立部门。
在今年的 Data Science Bowl 上,有一个奖金高达 100 万美元的竞赛,根据标注图像预测一年之中的肺癌情况。
6.3. 投资
正如之前的大数据,机器学习当下也涌入了大量资本。中国在 AI 领域的投资高达 1500 亿美元,从而成为行业领导者之一。
相比之下,百度研究院拥有 1300 名员工,而 Facebook FAIR 则只有 80 名。在今年闭幕的 KDD 2017 上,阿里巴巴介绍了其参数服务器鲲鹏,它带有万亿个参数,并使得运行 1000 亿个样本成为常规任务。

人工智能仍处于起步阶段,入门学习机器学习永远不嫌晚。不管怎样,所有开发者会慢慢用起机器学习,这项技术会成为程序员的必备技能之一,就像现在每个人都会使用数据库一样。

原文链接:https://blog.statsbot.co/deep-learning-achievements-4c563e034257
除了深度学习,还有哪些值得期待?!
导读: 毫无疑问,AI 的终极未来是达到并超越人类的智能。但是,这是一个非常遥远的目标。即使我们之中最乐观的人,也只敢打赌称人类级别的 AI(泛人工智能(AGI)或者超人工智能(ASI))将会在 10~15 年之后出现。而怀疑论者甚至打赌称,即使人类级别的人工智能出现,这个过程也需要几个世纪。不过,这不是我们这篇文章所关注的(如果你对学习超人工智能非常感兴趣,你可以阅读这篇文章)。这里我们将讲述一个触手可及的、更近的未来,讨论一些新兴的并且强大的 AI 算法。我认为,这些算法正在塑造 AI 不远的将来。
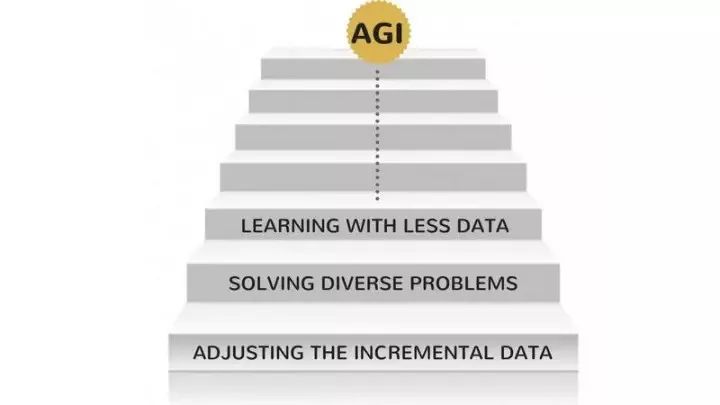
当你环顾四周,AI 正在一个一个地攻破各种难题。在这样一个双赢的情况下,可能会出现什么样的问题呢?人类在制造越来越多的数据(这是 AI 的基础)。同时,我们的硬件性能也在变得越来越好。毕竟,数据和更强的计算能力是深度学习在 2012 年开始复兴的原因,不是吗?然而真相是,人们的期待增长得远比数据和计算能力增长得要快。数据科学家将必须思考比现在已有的解决方案更好的方案,用于解决真实世界的问题。例如,大多数人以为图像分类是一个科学上已经解决了的问题(如果我们忍住说 100% 精确度的冲动)。我们能够通过 AI 达到与人类相当的图像分类的能力(比如说猫的图片和狗的图片)。但是,这能够在真实世界的情况下使用吗?在某些情况下,可以,但是在很多情况下,我们还不能做到。
我们将会带你了解在使用 AI 构建真实世界解决方案时候,那些主要的“挡路石”。假设我们想要分类猫和狗的图像。我们将会在整篇文章中使用这个例子。

我们的示例算法:分类猫和狗的图片
下面这张图总结了各种挑战:

构建真实世界的 AI 所涉及的挑战
图中英文翻译如下:
你可以识别出星球大战中的绝地武士是吧?一旦它我们把它记在脑海里,我们就能每次都能认出绝地武士。然而,一个算法却需要大量标记过的图像来学习、测试和训练。
假设一个算法输入了一种非常罕见的狗。该算法很难正确地把它分类为狗。真实世界的问题则更加多样,并且需要对这些更为多样的问题进行一定的调整和重新评估。
这是”Kotpies“,世界上第一个成功生下来的的猫狗杂交。一旦新的物种加进来,模型需要输入这些图像来识别新的物种,并且最终的模型必须重新训练来适应新加入的物种。
让我们仔细地讨论这些挑战的细节:
通过更少的数据来学习:
成功的深度学习算法所使用的训练数据都要求包含有其内容或者特征的标签。这个过程叫做打标签。
这些算法不能直接使用我们身边的数据。几百个标记(或者几千个)很简单,但是达到人类级别的图像分类算法需要输入上百万的标记过的图像来学习。
所以,问题在于:为一百万个图像进行标记是否可行?如果不可行,那么 AI 如何才能在更少量的标记数据上进行扩展。
解决真实世界中多种多样的问题:
虽然数据集是固定的,但真实世界的使用情况是多种多样的(例如,与人类不同,在彩色图像上训练的算法可能会在灰度图像上表现的非常差)。
尽管我们能够提高计算机视觉算法检测物体的能力并达到人类的水平。但是,正如刚刚提到的,这些算法只能解决非常特定的问题。与人类的智能相比,这些算法不能广泛应用于多种场景。
我们的举例说明的猫狗图像分类算法,它如果之前没有输入过某种罕见品种的狗,那也就不能识别出该种类的狗。
调整增量数据:
另一个大的挑战是增量数据。在我们的例子中,如果我们想要识别出是猫还是狗,在第一次部署的时候,我们可能需要为各种品种的猫和狗来训练我们的 AI 算法。但是,当我们发现新的品种时,我们需要训练这个算法,让它能够在之前的品质中识别出“Kotpies"这个品种。
尽管新的品种与其他品种之间可能比我们想象的更相似,并且能够通过简单的训练使算法得到适应,但这就是其中最困难的一点并且需要完整的重新训练和重新评估的方法。
问题在于,我们是否能够让 AI 能至少在这种小的变化上有足够的适应能力。
迁移学习是什么?
正如它的名字所示,在迁移学习中,习得的知识是在相同的算法上,从一个任务迁移到另一个任务上的。算法先在一个拥有更大的数据集的任务(源任务)上训练,然后再被迁移为学习另一个只有较少数据集的任务(目标任务)的算法。
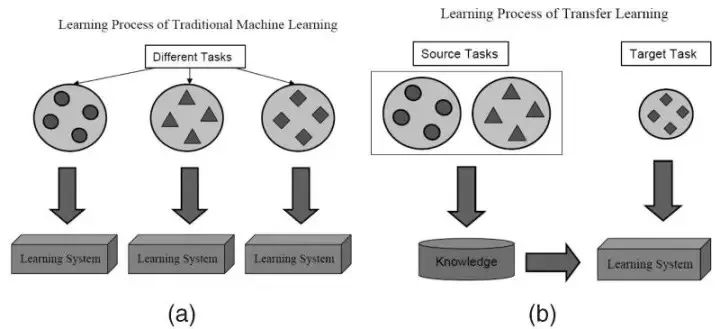
传统学习 vs 迁移学习。图片来源:IEEE Computer Society
举几个例子
在图像分类算法中使用参数在不同的任务中提取特征(例如:物体识别)是迁移学习里的一个简单的例子。与之相反,这种方法也能用在完成复杂的任务。最近,Google 开发的用来分类糖尿病性视网膜病变的算法表现超过了人类。这个算法就是用的迁移学习。出乎意料的是,该糖尿病性视网膜病变识别器实际上就是一个真实世界里的图像分类器(猫狗图像分类器),使用迁移学习来分类眼部扫描的图像。
多任务学习是什么?
在多任务学习中,通过利用任务之间的相同和不同,多个学习任务可以同时解决。出人意料的是,有的时候,同时学习两个或多个任务(有时也叫主任务和辅助任务)可以让结果变得更好。请注意:并不是每一对(或者三个一组,四个一组)的任务都是相互辅助的。但是当它们是相互辅助的关系时,我们就能“免费地”得到精度上的提升。举几个例子。
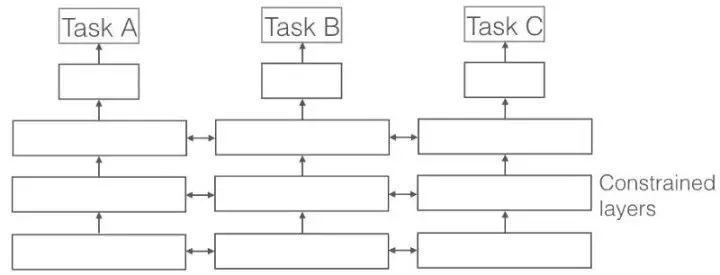
用多任务学习同时解决三个任务。图片来源:Sebastian Ruder
对抗学习这是什么?
对抗学习是从 Ian Goodfellow 的研究工作里演化出来的一个领域。尽管对抗学习最流行的应用是生成对抗网络(Generative Adversarial Networks,GANs),用它可以生成令人惊叹的图像,我们还是有很多其他应用该技术的方法。这个由博弈论启发而产生的技术包含两个算法,一个是生成器算法,一个是鉴别器算法,它们的目标是在训练的过程中欺骗对方。生成器可以生成我们所提到的非常新奇的图像,但是也可以生成任何其他用来向鉴别器隐藏细节的数据。后者就是这个概念的有趣之处。
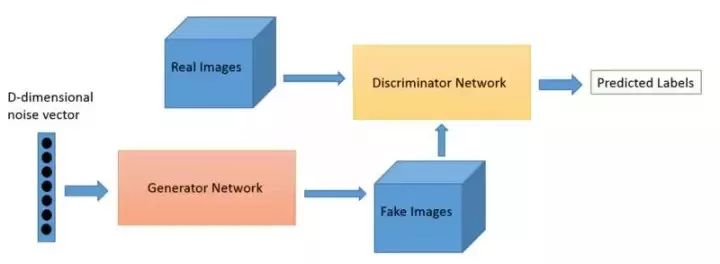
生成对抗网络。图片来源:O’Reilly
举几个例子
这是一个新的领域,并且它的图像生成能力吸引了像宇航员这样的人的关注。但是,我们相信它会演化出更新颖的使用场景。
少样本学习(Few Shot Learning)这是什么?
少样本学习是一种能够让深度学习(或者任何机器学习算法)通过更少的样本学习,而不像传统的那样使用大量样本的技术。单样本学习(One Shot Learning)就是通过每个分类中取一个样本来学习。推而广之,K 样本学习(K-shot Learning)就是每个分类中取 K 个样本学习。
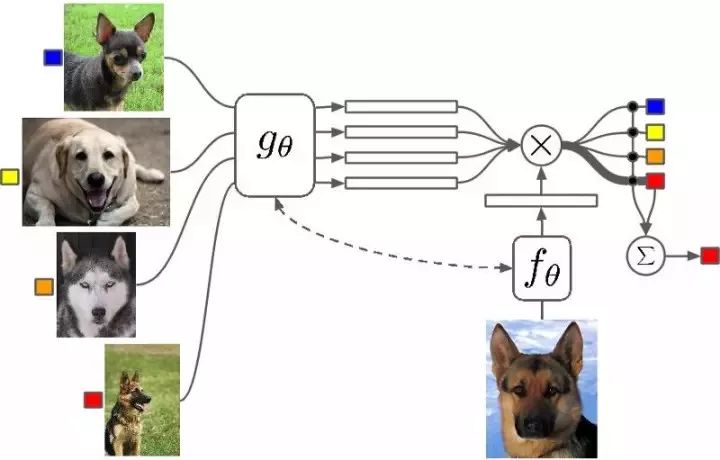
使用每个类别中的少量样本进行单样本学习。图片来源:Google DeepMind
举几个例子
少样本学习是在所有深度学习的会议上都能看到大量论文的一个领域。现在有一些特定的数据集可以用来衡量它们的性能,例如 MNIST 和 CIFAR,这些一般用于机器学习的数据集。单样本学习有不少在特定图像分类问题上的应用,例如特征识别和表示。
元学习这是什么?
元学习就像它听起来的那样,是一种可以通过一个数据集,生成一个专为这个数据集准备的新机器学习算法。这个定义第一眼看感觉非常前卫。你会感觉到,“哇,这不就是数据科学家们做的事情吗!”,它把“21 世纪最性感的工作”给自动化了!在某种程度上,元学习算法已经开始做这样的事情了(引用自 Google 的博文和这篇论文)。
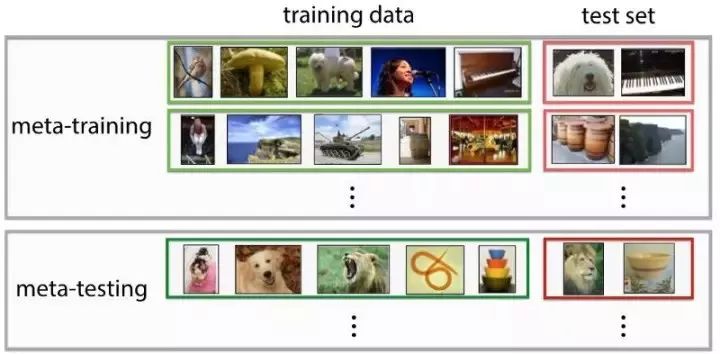
在一些少样本图像分类问题上构建元学习的例子。图片来源:Ravi et.al.
举几个例子
元学习已经成为了最近深度学习领域的热门话题。有非常多的研究论文发表,大多数都使用了超参数和神经网络调优的方法,寻找好的网络架构,少样本的图像识别和高速的强化学习。你可以在这里找到更多易于理解的关于应用场景的文章。
神经推理这是什么?
神经推理是在图像分类领域里的下一个重磅新事物。神经推理在模式识别上更深入了一步,其算法不再只是简单地认出和分类文本和图像。神经推理正在解决文本分析和视觉分析中更通用的问题。例如,下面的图片中展示了一系列问题,而这些问题神经推理能够通过图像给出解答。

小结
现在我们了解了这些技术是什么,让我们回到最开始,来看看它们如何解决我们最开始提出的问题。下面的表格给出了这些“有效学习”技术的在解决这些挑战时的能力:
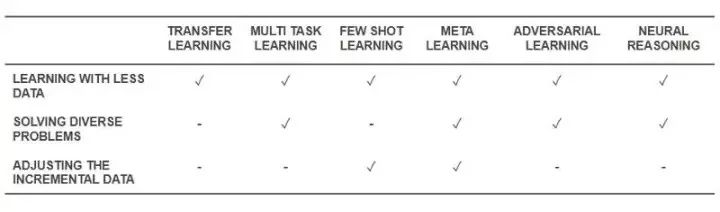
“有效学习”技术的能力
所有我们上面提到的技术都能通过某些方法,帮助我们解决在少量数据上训练的问题。元学习会给出一个与训练数据匹配的架构;迁移学习则利用一些其他领域的知识来弥补少量的训练数据;少样本学习致力于解决科学学科专业的问题;而对抗学习则可以帮助增强数据集。
领域适应(多任务学习的一种),对抗学习和元学习的架构帮助解决了数据多样性增长所引起的问题。
元学习和少样本学习帮助解决了数据量变大的问题。
通过与元学习算法和少样本学习算法结合起来,神经推理算法展现出了解决真实世界问题的潜力。
请注意:这些“有效学习”技术并不是新的深度学习或机器学习技术,而是用于增强现有技术的技巧,让他们能够在现有的情况下表现的更好。因此,你还是会在实战中使用例如卷积神经和 LSTM 网络这样的工具,不过会被加上一些“特技”。这些只需要更少的数据还能够同时解决多个问题的“有效学习”技术,能够帮助我们更简单地部署算法,更简单地商业化 AI 驱动的产品和服务。
作者是 Paralleldots 应用 AI 研究组的一员。
深度学习高手该怎样炼成?这位拿下阿里天池大赛冠军的中科院博士为你规划了一份专业成长路径
刘昕

作者 | 刘昕
深度学习本质上是深层的人工神经网络,它不是一项孤立的技术,而是数学、统计机器学习、计算机科学和人工神经网络等多个领域的综合。深度学习的理解,离不开本科数学中最为基础的数学分析(高等数学)、线性代数、概率论和凸优化;深度学习技术的掌握,更离不开以编程为核心的动手实践。没有扎实的数学和计算机基础做支撑,深度学习的技术突破只能是空中楼阁。
所以,想在深度学习技术上有所成就的初学者,就有必要了解这些基础知识之于深度学习的意义。除此之外,我们的专业路径还会从结构与优化的理论维度来介绍深度学习的上手,并基于深度学习框架的实践浅析一下进阶路径。
最后,本文还将分享深度学习的实践经验和获取深度学习前沿信息的经验。
数学基础
如果你能够顺畅地读懂深度学习论文中的数学公式,可以独立地推导新方法,则表明你已经具备了必要的数学基础。
掌握数学分析、线性代数、概率论和凸优化四门数学课程包含的数学知识,熟知机器学习的基本理论和方法,是入门深度学习技术的前提。因为无论是理解深度网络中各个层的运算和梯度推导,还是进行问题的形式化或是推导损失函数,都离不开扎实的数学与机器学习基础。
数学分析:在工科专业所开设的高等数学课程中,主要学习的内容为微积分。对于一般的深度学习研究和应用来说,需要重点温习函数与极限、导数(特别是复合函数求导)、微分、积分、幂级数展开、微分方程等基础知识。在深度学习的优化过程中,求解函数的一阶导数是最为基础的工作。当提到微分中值定理、Taylor公式和拉格朗日乘子的时候,你不应该只是感到与它们似曾相识。这里推荐同济大学第五版的《高等数学》教材。
线性代数:深度学习中的运算常常被表示成向量和矩阵运算。线性代数正是这样一门以向量和矩阵作为研究对象的数学分支。需要重点温习的包括向量、线性空间、线性方程组、矩阵、矩阵运算及其性质、向量微积分。当提到Jacobian矩阵和Hessian矩阵的时候,你需要知道确切的数学形式;当给出一个矩阵形式的损失函数时,你可以很轻松的求解梯度。这里推荐同济大学第六版的《线性代数》教材。
概率论:概率论是研究随机现象数量规律的数学分支,随机变量在深度学习中有很多应用,无论是随机梯度下降、参数初始化方法(如Xavier),还是Dropout正则化算法,都离不开概率论的理论支撑。除了掌握随机现象的基本概念(如随机试验、样本空间、概率、条件概率等)、随机变量及其分布之外,还需要对大数定律及中心极限定理、参数估计、假设检验等内容有所了解,进一步还可以深入学习一点随机过程、马尔可夫随机链的内容。这里推荐浙江大学版的《概率论与数理统计》。
凸优化:结合以上三门基础的数学课程,凸优化可以说是一门应用课程。但对于深度学习而言,由于常用的深度学习优化方法往往只利用了一阶的梯度信息进行随机梯度下降,因而从业者事实上并不需要多少“高深”的凸优化知识。理解凸集、凸函数、凸优化的基本概念,掌握对偶问题的一般概念,掌握常见的无约束优化方法如梯度下降方法、随机梯度下降方法、Newton方法,了解一点等式约束优化和不等式约束优化方法,即可满足理解深度学习中优化方法的理论要求。这里推荐一本教材,Stephen Boyd的《Convex Optimization》。
机器学习:归根结底,深度学习只是机器学习方法的一种,而统计机器学习则是机器学习领域事实上的方法论。以监督学习为例,需要你掌握线性模型的回归与分类、支持向量机与核方法、随机森林方法等具有代表性的机器学习技术,并了解模型选择与模型推理、模型正则化技术、模型集成、Bootstrap方法、概率图模型等。深入一步的话,还需要了解半监督学习、无监督学习和强化学习等专门技术。这里推荐一本经典教材《The elements of Statistical Learning》。
计算机基础
深度学习要在实战中论英雄,因此具备GPU服务器的硬件选型知识,熟练操作Linux系统和进行Shell编程,熟悉C++和Python语言,是成长为深度学习实战高手的必备条件。当前有一种提法叫“全栈深度学习工程师”,这也反映出了深度学习对于从业者实战能力的要求程度:既需要具备较强的数学与机器学习理论基础,又需要精通计算机编程与必要的体系结构知识。
编程语言:在深度学习中,使用最多的两门编程语言分别是C++和Python。迄今为止,C++语言依旧是实现高性能系统的首选,目前使用最广泛的几个深度学习框架,包括Tensorflow、Caffe、MXNet,其底层均无一例外地使用C++编写。而上层的脚本语言一般为Python,用于数据预处理、定义网络模型、执行训练过程、数据可视化等。当前,也有Lua、R、Scala、Julia等语言的扩展包出现于MXNet社区,呈现百花齐放的趋势。这里推荐两本教材,一本是《C++ Primer第五版》,另外一本是《Python核心编程第二版》。
Linux操作系统:深度学习系统通常运行在开源的Linux系统上,目前深度学习社区较为常用的Linux发行版主要是Ubuntu。对于Linux操作系统,主要需要掌握的是Linux文件系统、基本命令行操作和Shell编程,同时还需熟练掌握一种文本编辑器,比如VIM。基本操作务必要做到熟练,当需要批量替换一个文件中的某个字符串,或者在两台机器之间用SCP命令拷贝文件时,你不需要急急忙忙去打开搜索引擎。这里推荐一本工具书《鸟哥的Linux私房菜》。
CUDA编程:深度学习离不开GPU并行计算,而CUDA是一个很重要的工具。CUDA开发套件是NVidia提供的一套GPU编程套件,实践当中应用的比较多的是CUDA-BLAS库。这里推荐NVidia的官方在线文档http://docs.nvidia.com/cuda/。
其他计算机基础知识:掌握深度学习技术不能只满足于使用Python调用几个主流深度学习框架,从源码着手去理解深度学习算法的底层实现是进阶的必由之路。这个时候,掌握数据结构与算法(尤其是图算法)知识、分布式计算(理解常用的分布式计算模型),和必要的GPU和服务器的硬件知识(比如当我说起CPU的PCI-E通道数和GPU之间的数据交换瓶颈时,你能心领神会),你一定能如虎添翼。
深度学习入门
接下来分别从理论和实践两个角度来介绍一下深度学习的入门。
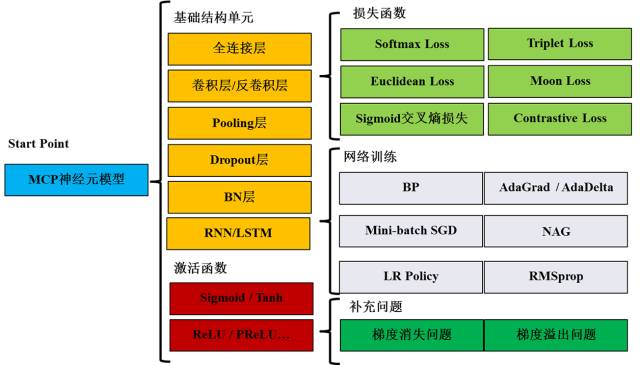
深度学习理论入门:我们可以用一张图(图1)来回顾深度学习中的关键理论和方法。从MCP神经元模型开始,首先需要掌握卷积层、Pooling层等基础结构单元,Sigmoid等激活函数,Softmax等损失函数,以及感知机、MLP等经典网络结构。接下来,掌握网络训练方法,包括BP、Mini-batch SGD和LR Policy。最后还需要了解深度网络训练中的两个至关重要的理论问题:梯度消失和梯度溢出。
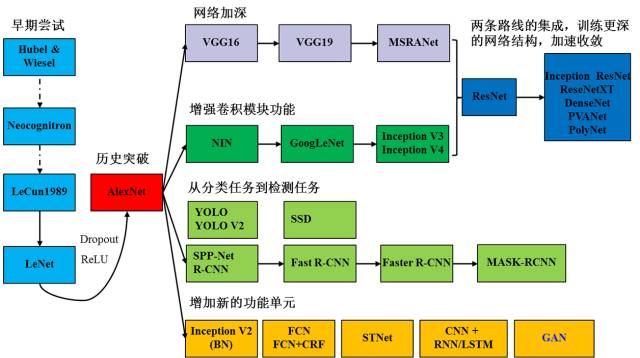
以卷积神经网络为例,我们用图2来展示入门需要掌握的知识。起点是Hubel和Wiesel的对猫的视觉皮层的研究,再到日本学者福岛邦彦神经认知机模型(已经出现了卷积结构),但是第一个CNN模型诞生于1989年,1998年诞生了后来被大家熟知的LeNet。随着ReLU和Dropout的提出,以及GPU和大数据所带来的历史机遇,CNN在2012年迎来了历史性的突破——诞生了AlexNet网络结构。2012年之后,CNN的演化路径可以总结为四条:1. 更深的网络;2. 增强卷积模的功能以及上诉两种思路的融合ResNet和各种变种;3. 从分类到检测,最新的进展为ICCV 2017的Best Paper Mask R-CNN;4. 增加新的功能模块。
深度学习实践入门:掌握一个开源深度学习框架的使用,并进一步的研读代码,是实际掌握深度学习技术的必经之路。当前使用最为广泛的深度学习框架包括Tensorflow、Caffe、MXNet和PyTorch等。框架的学习没有捷径,按照官网的文档step by step配置及操作,参与GitHub社区的讨论,遇到不能解答的问题及时Google是快速实践入门的好方法。
初步掌握框架之后,进一步的提升需要依靠于具体的研究问题,一个短平快的策略是先刷所在领域权威的Benchmark。例如人脸识别领域的LFW和MegaFace,图像识别领域与物体检测领域的ImageNet、Microsoft COCO,图像分割领域的Pascal VOC等。通过复现或改进别人的方法,亲手操练数据的准备、模型的训练以及调参,能在所在领域的Benchmark上达到当前最好的结果,实践入门的环节就算初步完成了。
后续的进阶,就需要在实战中不断地去探索和提升了。例如:熟练的处理大规模的训练数据,精通精度和速度的平衡,掌握调参技巧、快速复现或改进他人的工作,能够实现新的方法等等。
深度学习实战经验
在这里,分享四个方面的深度学习实战经验。
1. 充足的数据。大量且有标注的数据,依旧在本质上主宰着深度学习模型的精度,每一个深度学习从业者都需要认识到数据极端重要。获取数据的方式主要有三种:开放数据(以学术界开放为主,如ImageNet和LFW)、第三方数据公司的付费数据和结合自身业务产生的数据。
2. 熟练的编程实现能力。深度学习算法的实现离不开熟练的编程能力,熟练使用Python进行编程是基础。如果进一步的修改底层实现或增加新的算法,则可能需要修改底层代码,此时熟练的C++编程能力就变得不可或缺。一个明显的现象是,曾经只需要掌握Matlab就可以笑傲江湖的计算机视觉研究者,如今也纷纷需要开始补课学习Python和C++了。
3. 充裕的GPU资源。深度学习的模型训练依赖于充裕的GPU资源,通过多机多卡的模型并行,可以有效的提高模型收敛速度,从而更快的完成算法验证和调参。一个专业从事深度学习的公司或实验室,拥有数十块到数百块的GPU资源已经是普遍现象。
4. 创新的方法。以深度学习领域权威的ImageNet竞赛为例,从2012年深度学习技术在竞赛中夺魁到最后一届2017竞赛,方法创新始终是深度学习进步的核心动力。如果只是满足于多增加一点数据,把网络加深或调几个SGD的参数,是难以做出真正一流的成果的。
根据笔者的切身经历,方法创新确实能带来难以置信的结果。一次参加阿里巴巴组织的天池图像检索比赛,笔者提出的一点创新——使用标签有噪声数据的新型损失函数,结果竟极大地提高了深度模型的精度,还拿到了当年的冠军。
深度学习前沿
【前沿信息的来源】
实战中的技术进阶,必需要了解深度学习的最新进展。换句话说,就是刷论文:除了定期刷Arxiv,刷代表性工作的Google Scholar的引用,关注ICCV、CVPR和ECCV等顶级会议之外,知乎的深度学习专栏和Reddit上时不时会有最新论文的讨论(或者精彩的吐槽)。
一些高质量的公众号,例如Valse前沿技术选介、深度学习大讲堂、Paper Weekly等,也时常有深度学习前沿技术的推送,也都可以成为信息获取的来源。同时,关注学术界大佬LeCun和Bengio等人的Facebook/Quora主页,关注微博大号“爱可可爱生活”等人,也常有惊喜的发现。
【建议关注的重点】
新的网络结构。在以SGD为代表的深度学习优化方法没有根本性突破的情况下,修改网络结构是可以较快提升网络模型精度的方法。2015年以来,以ResNet的各种改进为代表的各类新型网络结构如雨后春笋般涌现,其中代表性的有DenseNet、SENet、ShuffuleNet等。
新的优化方法。纵观从1943年MCP模型到2017年间的人工神经网络发展史,优化方法始终是进步的灵魂。以误差反向传导(BP)和随机梯度下降(SGD)为代表的优化技术的突破,或是Sigmoid/ReLU之后全新一代激活函数的提出,都非常值得期待。笔者认为,近期的工作如《Learning gradient descent by gradient descent》以及SWISH激活函数,都很值得关注。但能否取得根本性的突破,也即完全替代当前的优化方法或ReLU激活函数,尚不可预测。
新的学习技术。深度强化学习和生成对抗网络(GAN)。最近几周刷屏的Alpha Zero再一次展示了深度强化学习的强大威力,完全不依赖于人类经验,在围棋项目上通过深度强化学习“左右互搏”所练就的棋力,已经远超过上一代秒杀一众人类高手的AlghaGo Master。同样的,生成对抗网络及其各类变种也在不停地预告一个学习算法自我生成数据的时代的序幕。笔者所在的公司也正尝试将深度强化学习和GAN相结合,用于跨模态的训练数据的增广。
新的数据集。数据集是深度学习算法的练兵场,因此数据集的演化是深度学习技术进步的缩影。以人脸识别为例,后LFW时代,MegaFace和Microsoft Celeb-1M数据集已接棒大规模人脸识别和数据标签噪声条件下的人脸识别。后ImageNet时代,Visual Genome正试图建立一个包含了对象、属性、关系描述、问答对在内的视觉基因组。
作者简介:刘昕,工学博士,毕业于中国科学院计算技术研究所,师从山世光研究员。主要从事计算机视觉技术和深度学习技术的研究与工业化应用,现担任人工智能初创公司中科视拓CEO。
本文为《程序员》原创文章

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“数据科学家”、“赛博物理”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com


