【新智元导读】朱松纯教授团队的最新研究工作,可在协作任务中提高人机协作效率,进而提升人机信赖关系,实现真正自主智能,在迈向通用AI的道路上更进一步!
7月14日,国际顶级学术期刊<Science Robotics >发表了朱松纯团队(UCLA袁路遥、高晓丰、北京通用人工智能研究院郑子隆、北京大学人工智能研究院朱毅鑫等作者)的最新研究成果——实时双向人机价值对齐 In-situ bidirectional human-robotvalue alignment。
论文同时被Science官网和Science Robotics官网头条刊登。
论文地址:
https://www.science.org/doi/10.1126/scirobotics.abm4183
本论文提出了一个可解释的人工智能(XAI)系统,阐述了一种机器实时理解人类价值观的计算框架,并展示了机器人如何与人类用户通过实时沟通完成一系列复杂人机协作任务。
朱松纯团队长期从事可解释人工智能相关工作。此文是团队第二篇发表在 Science Robotics 的关于可解释人工智能的论文。这项研究涵盖了认知推理、自然语言处理、机器学习、机器人学等多学科领域,是朱松纯教授团队交叉研究成果的集中体现。
![]()
在这个人机共存的时代,为了让机器更好地服务于人类,理想的人机协作应该是什么样的?
我们不妨借鉴一下人类社会的协作,在人类团队合作过程中,共同的价值观和目标是保证团队之间齐心协力、高效合作的基础。
当前机器智能大多数基于数据驱动(且很多情况下获取不了数据)、且是单方面接受人类指令(一种是人类观测受限的情况下是没法给到指令的)。
为了解决上述问题,以及为了让机器能够进行更好地「自主」探索,我们要让机器学会「读懂」人类价值观,因此我们提出「实时双向价值对齐」。
这就要求人类要想办法一次次地给到AI反馈,逐渐地教会AI「
读
懂」
人类的价值观,也就是让机器和人类的「
价值观」
保持一致。
这个问题也被称为价值对齐(value alignment),即如何保证人工智能在执行任务过程中所实现的价值和用户所在意的价值是一致的?
可以说,价值对齐是人机协作过程中达成共识(common ground)的基础,具有非常重要的研究价值。价值对齐也是未来的一个重要发展方向,是让机器实现「自主智能」的关键所在,也是实现通用人工智能的必经之路。
鉴于此,北京通用人工智能研究院院长朱松纯团队一直在致力于此方向的研究。
在人工智能发展方兴未艾之时,控制论之父诺伯特-维纳(Norbert Wiener)就提出了人机协作的基础:
「如果我们使用一个机器来实现我们的目标,但又不能有效地干预其运作方式...那么我们最好能笃定,输入给机器的目标是我们真正所预期的。」
高效的人机协作依赖于团队之间拥有一致的价值观、目标,以及对任务现状的理解。这就要求人类通过与机器的沟通来高效地建立整个团队对任务的共识,每个团队成员都采取其他伙伴更容易理解的行为决策来完成协作。
在大多数情况下,队友之间的沟通过程都是双向的,即每个成员都要扮演着倾听者和表达者两种角色。
这样的双向价值对齐决定了人机协作中的沟通是否能够成功,即机器人是否能准确地推断出用户的价值目标,并有效地解释自己的行为。
如果这两个条件没有得到满足,队友间彼此的不理解和误判很可能会导致协作失败。
因此,想要使人工智能更好地服务于人类社会,必须让它们在与人类互动时扮演好这两种角色。
从倾听者的角度来看,传统人工智能算法(如逆强化学习(IRL)等)能够将交互数据与机器学习算法相结合,以学习特定任务中用户的价值目标,即通过输入用户在特定任务中的行为方式,来恢复行为背后的奖励函数。
然而,在众多实际且重要(如军事和医疗领域)的应用中,数据的获取经常十分昂贵。这些机器学习方法对大型数据集的依赖是无法应对即时互动的人机协作场景的。
从表达者的角度来看,可解释人工智能(XAI)的引入是为了促进人机之间达成共识。当前的XAI系统通常强调的是对「模型如何产生决策过程」的解释。
然而,不管用户有多少主动的输入或互动,都只能影响机器「生成解释」的过程,而不影响机器「做出决策」的过程。
这
是一种单向的价值目标对齐,我们称之为静态机器-动态用户的交流,即在这种协作过程中只有用户对机器或任务的理解发生了变化。
为了完成人与机器之间价值目标的双向对齐,需要一种人类价值主导的、动态机器-动态用户的交流模式。
在这样一种新的模式中,机器人除了揭示其决策过程外,还将根据用户的价值目标即时调整行为,从而使机器和人类用户能够合作实现一系列的共同目标。
为了即时掌握用户信息,我们采用通讯学习取代了传统数据驱动的机器学习方法,机器将根据所推断出的用户的价值目标进行合理解释。
这种合作导向的人机协作要求机器具有心智理论(ToM),即理解他人的心理状态(包括情绪、信仰、意图、欲望、假装与知识等)的能力。
心智理论最早在心理学和认知科学中被研究,现已泛化到人工智能领域。心智理论在多智能体和人机交互环境中尤为重要,因为每个智能体都要理解其他智能体(包括人)的状态和意图才能更好地执行任务,其决策行为又会影响其他智能体做出判断。
设计拥有心智理论的系统不仅在于解释其决策过程,还旨在理解人类的合作需求,以此形成一个以人类为中心、人机兼容的协作过程。
为了建立一个具有上述能力的AI系统,本文设计了一个「人机协作探索」游戏。
在这个游戏中,用户需要与三个侦察机器人合作完成探索任务并最大化团队收益。本游戏设定:
1、只有侦察机器人能直接与游戏世界互动,用户不能直接控制机器人的行为;
2、用户将在游戏初始阶段选择自己的价值目标(例如:最小化探索时间,收集更多的资源,探索更大的区域等),机器人团队必须通过人机互动来推断这个价值目标。
这样的设置真实地模仿了现实世界中的人机合作任务,因为许多AI系统都需要在人类用户的监督下,自主地在危险的环境中运行(如在核电站有核泄漏的情况下)。
要成功地完成游戏,机器人需要同时掌握「听」和「说」的能力来实现价值双向对齐。
首先,机器人需要从人类的反馈中提取有用的信息,推断出用户的价值函数(描述目标的函数)并相应地调整它们的策略。
其次,机器人需要根据它们当前的价值推断,有效地解释它们「已经做了什么」和「计划做什么」,让用户知道机器人是否和人类有相同的的价值函数。同时,用户的任务是指挥侦查机器人到达目的地,并且使团队的收益最大化。
因此,用户对机器人的评价也是一个双向的过程,即用户必须即时推断侦察机器人的价值函数,检查其是否与人类的价值函数相一致。如果不一致,则选择适当的指令来调整他们的目标。
最终,如果系统运行良好,侦察机器人的价值函数应该与人类用户的价值函数保持一致,并且用户应该高度信任机器人系统自主运行。
![]()
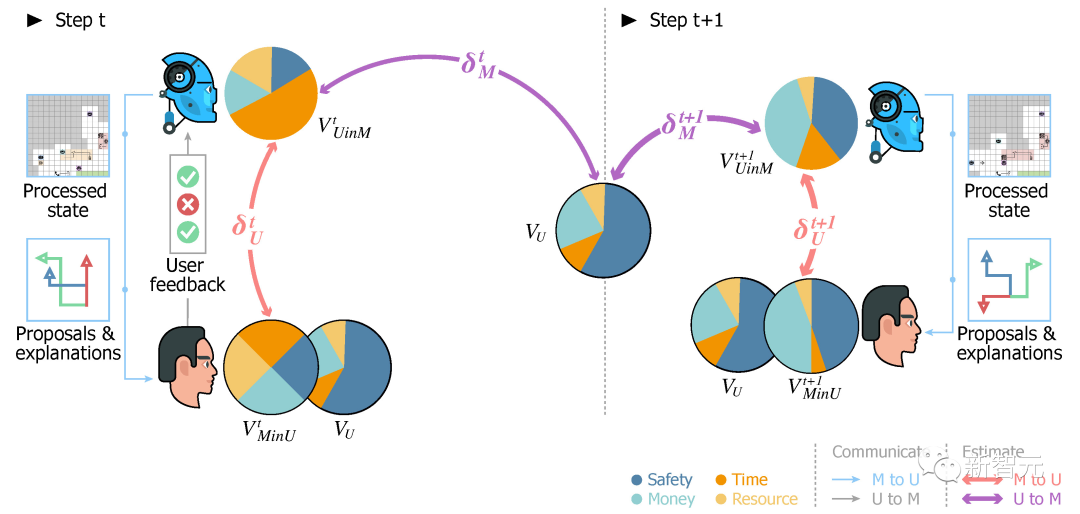
图1介绍了游戏中的双向价值调整过程。在游戏互动过程中,存在着三个价值目标,分别是:
![]() :用户的真实价值;
:用户的真实价值;
![]() :机器人对用户价值的估计(在游戏中,侦察机器人没有自己的价值,所以他们以人类用户价值的估计为依据采取行动);
:机器人对用户价值的估计(在游戏中,侦察机器人没有自己的价值,所以他们以人类用户价值的估计为依据采取行动);
![]() :用户对机器人价值的估计。
:用户对机器人价值的估计。
![]() :机器人从用户给出的反馈中学习用户的价值;
:机器人从用户给出的反馈中学习用户的价值;
![]() :用户从机器人给出的解释和互动中了解机器人的价值。
:用户从机器人给出的解释和互动中了解机器人的价值。
最终,三种价值目标将汇聚于,人-机团队将形成相互信任和高效的协作。
在即时互动和反馈过程中,机器如何准确估计人类用户的意图?
机器如何解释自己,以便人类用户能够理解机器的行为,并提供有用的反馈来帮助机器做出价值调整?
在本文提出的系统中,机器人提出任务计划的建议,并要求人类用户给出反馈(接受或拒绝建议),从人类反馈中推断出任务目标背后人类真实的价值意图。
在协作游戏中,如果用户知道机器人正在积极学习他的价值目标,那么用户就会倾向于提供更加有用的反馈,以促进价值保持对齐。
特别
地,每条信息都传达了两方面的意义,包括(1)基于价值目标的语义信息和(2)基于不同解释方式之间区别的语用信息。
利用这两方面的含义,XAI系统以一种多轮的、即时的方式展示了价值的一致性,在一个问题搜索空间大的团队合作任务中实现了高效的人机互动交流。
为了使机器人的价值目标与用户保持一致,XAI系统生成解释、揭示机器人对人类价值的当前估计、并证明提出规划的合理性。
在每一步的互动中,为了避免解释内容过于冗长,机器人会提供定制化的解释,比如省略重复的已知信息并强调重要的更新。
在收到机器人的解释并向它们发送反馈后,用户向机器人提供提示,说明他们对最新建议和解释的满意程度。
利用这些反馈,机器人会不断地更新解释的形式和内容。
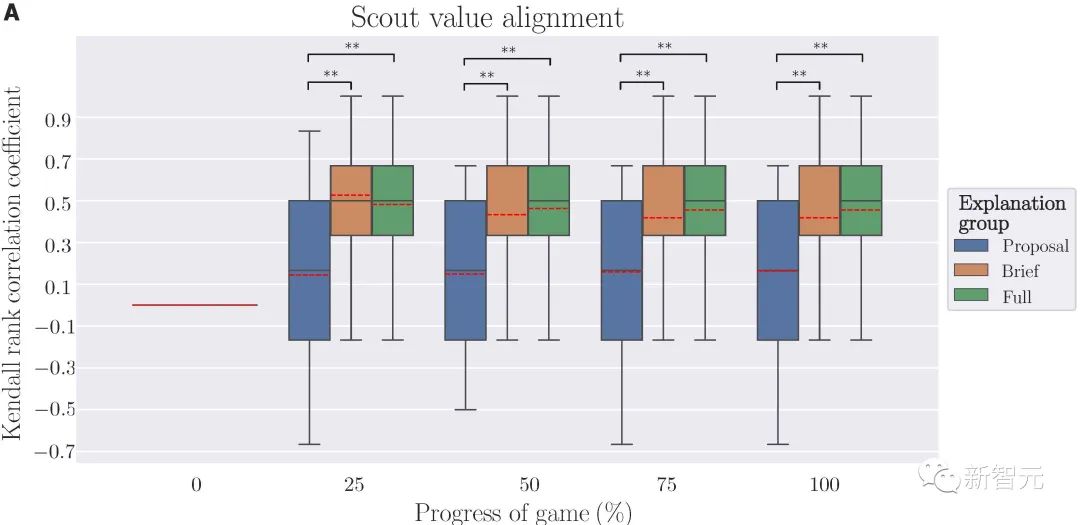
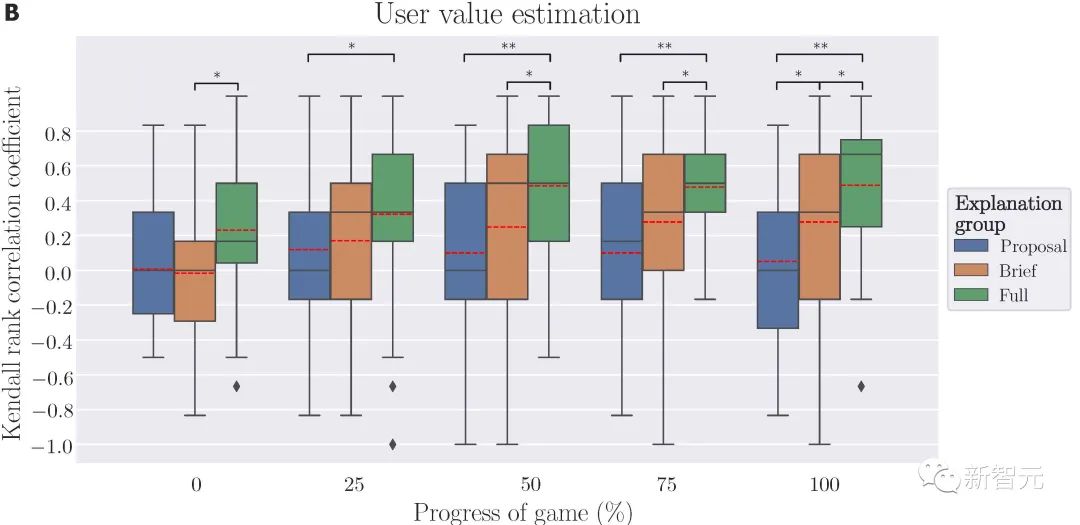
为了评估本文XAI系统的性能,我们邀请了人类用户进行了一系列实验,以此考察人类-机器双向价值协调是否成功。
我们采用了三种类型的解释,并将用户随机分配到三组中的一组。
实验结果表明,我们所提出的XAI系统能够以有效地实现即时双向的价值对齐,并用于协作任务;机器人能够推断出人类用户的价值,并调整其价值估计被用户所理解。
此外,有必要进行多样化的解释,以提高机器的决策性能和它们的社会智能。
合作式的人工智能的目标是减少人类的认知负担,并协助完成任务,我们相信,主动即时推断人类的价值目标,并促进人类对系统的理解,将会为通用智能体的人机合作铺平道路。
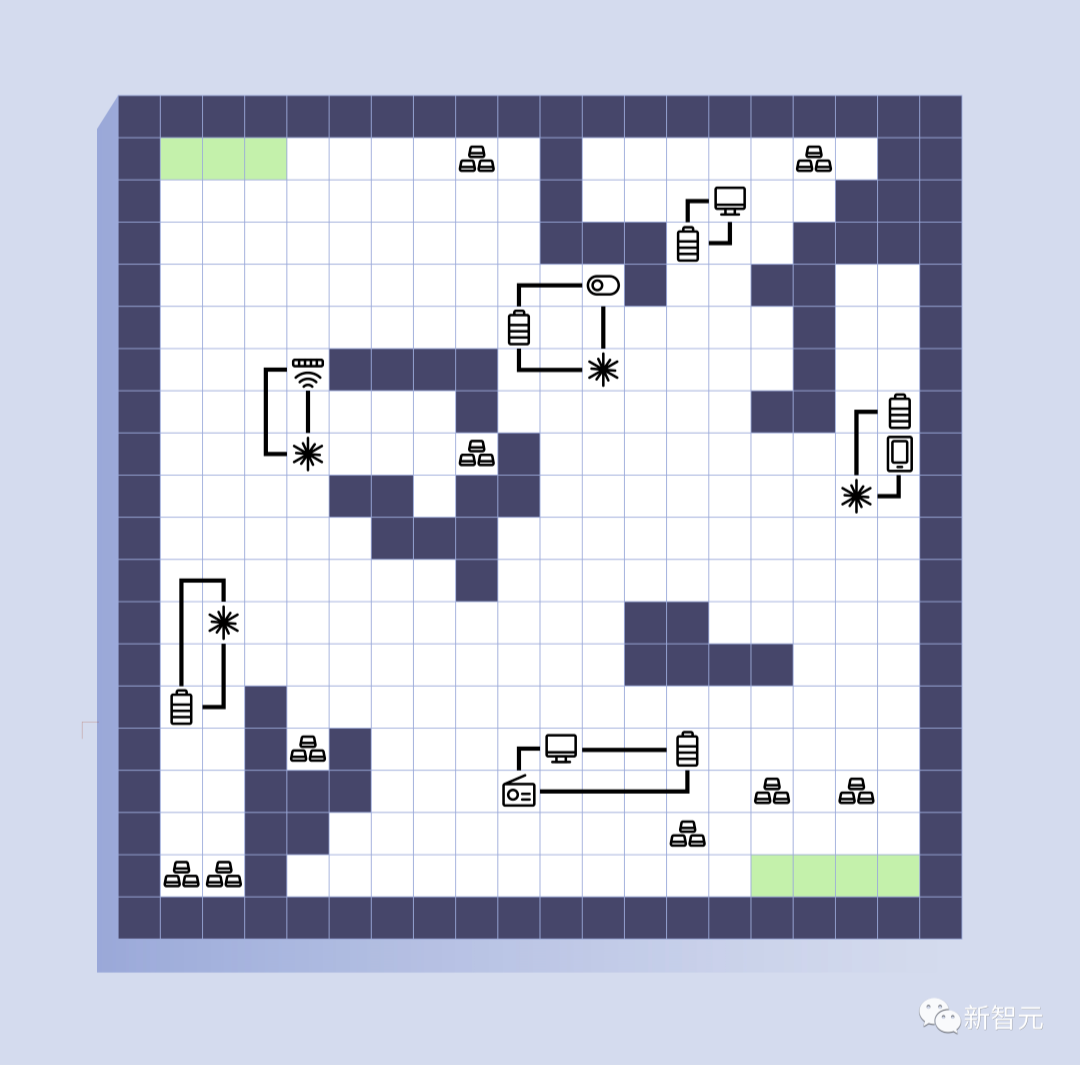
如图2所示,在我们设计的合作游戏中,包含一个人类指挥官和三个侦察机器人。
游戏的目标是需要在一张未知的地图上找到一条从基地(位于地图的右下角)到目的地(位于地图的左上角)的安全路径。
该
地图被表示为一个部分可见的20×20网格图,每个格子都可能有一个不同的装置,只有在侦察机器人靠近它之后才可见。
在游戏中,人类指挥官和侦察机器人具有结构性的相互依赖关系,一方面人类指挥官需要依靠侦察机器人探索危险区域并排除爆炸物,另一方面,侦察机器人需要依赖人类指挥官提供的反馈更好地理解当前任务的目标。
![]()
图2. 侦察探索游戏的用户界面。从左到右,图例面板显示游戏地图中的图例。价值函数面板显示这局游戏的价值函数,侦察机器人不知道这个函数,用户也不能修改。中心地图显示当前地图上的信息。分数面板显示了用户的当前分数。总分的计算方法是将各个目标的分数用价值函数加权后的总和。状态面板显示系统的当前状态。提议面板显示侦察机器人当前的任务计划提议,用户可以接受/拒绝每个建议。解释面板显示侦察机器人提供的解释。
我们为侦察机器人制定了在寻找到路径时额外的一系列目标,包括1)尽快到达目的地,2)调查地图上的可疑装置,3)探索更大的区域,以及4)收集资源。
游戏的表现是由侦察机器人完成这些目标的情况和它们的相对重要性(权重)来衡量的,其中的权重就是人类用户的价值函数。
例如,如果人类指挥官更注重时效而不是获取更多的资源,那么侦察机器人则应该忽略沿途上的部分资源以保证尽快到达目的地。
(注,这个价值函数只在游戏开始时向人类用户透露,
而不对侦察机器人透露。
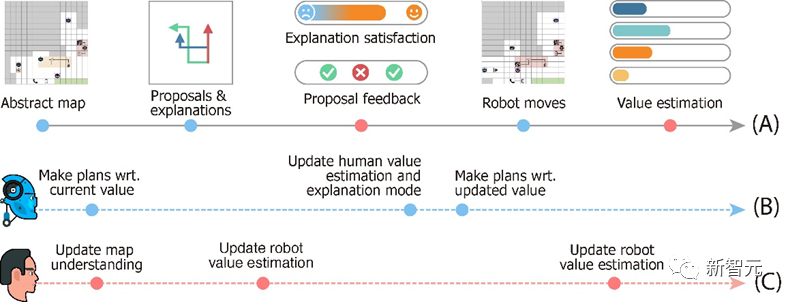
图
3总
结了人机互动的流程。
)
在不清楚人类指挥官价值取向的情况下,机器人侦察兵小队必须快速推断出人类的价值判断,在每一步行动中,机器人侦察小队每一个成员都要给出下一步行动方案,由人类指挥官选择。
为了帮助指挥官进行决策,侦察机器人小队将解释行动方案的依据。结合指挥官的反馈,以往的互动历史和当前的地图情况,侦察机器人小队将调整其对指挥官当前价值观的判断,并采取相应的行动。
![]()
图3. 侦查探索游戏的设计。时间线(A)表示在一轮游戏中发生的事件,从机器人收到环境信号开始,到它们的下一步动作结束。时间线(B)和(C)分别描述了机器人和用户的心智变化过程。
为了估计人类指挥官在通信过程中的价值函数,我们将两个层次的心智理论整合到我们的计算模型中。
第1层心智理论考虑合作性假设。也就是说,给定一个合作的人类指挥官,被他接受的来自机器人的提议,更有可能与正确的价值函数相一致。
第2层心智理论进一步将用户的教育方法纳入模型,使机器人更接近人类指挥官真实价值的反馈比其他反馈更容易被人类指挥官选择。建模人类指挥官的教育倾向(pedagogical inclination)需要更高一层的心智理论。
结合这两个层次的心智理论,我们将人类指挥官的决策函数写成一个由价值函数参数化的分布,并开发出一种新的学习算法。
值得注意的是,与我们的人机合作框架有可比性但不同的方法是逆强化学习。
逆强化学习的目的是在一个被动的学习环境中,根据预先录制的、来自专家的演示(demonstration)来恢复底层的奖励函数(reward function)。
与之不同的是,在我们的环境中,侦察机器人被设计为从人类指挥官给出的稀缺监督中进行交互学习。
更重要的是,我们的设计要求机器人在任务进行的过程中即时地、主动地推断人类指挥官的价值。
此外,为了完成合作,侦察机器人不仅必须迅速理解人类指挥官的意图,还要阐明自己的决策依据,以确保在整个游戏过程中与人类指挥官顺利沟通。
总体来看,机器人的任务是通过推断人类用户的心智模型,积极提出建议,并评估人类用户的反馈来进行价值调整。这些都需要机器对人类用户进行复杂的心智建模,并具有即时更新模型的能力。
我们提出的XAI系统成功地证明了双向人机价值对齐框架的可行性。
从倾听者的角度来看,所有三个解释组中的机器人都可以在游戏进度达到25%时,通过对至少60%的目标重要性进行正确排序,快速与用户的价值进行对齐。
从表达者的角度来看,通过提供适当的解释,机器人可以向用户说明其意图,并帮助人类更好的感知机器人的价值,当给机器提供「完整解释」时,只需在游戏进度达到50%时即可实现人类用户价值与机器人价值的统一,而当只提供「简要解释」时,游戏进度需要达到75%时才能完成价值的统一。
我们从上述两个角度得到了令人信服的证据,实现了双向价值对齐的过程,具体来说:
通过接收人类的反馈,机器人逐渐更新其价值函数来与人类价值保持一致;
通过不断地与机器人交互,人类用户逐渐形成对系统能力和意图的感知。虽然机器人系统的价值在游戏的上半场没有与人类用户实现统一,但用户对机器人价值评估能力的感知仍然可以提高。
最终,当机器人的价值变得稳定时,用户对机器人的评估也变得稳定。从机器人对用户价值的评估到用户价值的真实值,以及从用户对机器人价值的评估到机器人当前价值的收敛配对,形成了由用户真实价值锚定的双向价值对齐。
总的来说,我们提出了一个双向人机价值对齐框架,并使用XAI系统验证其可行性。
我们提出的XAI系统表明,当把心智理论集成到机器的学习模块中,并向用户提供适当的解释时,人类和机器人能够通过即时交互的方式实现心智模型的对齐。
我们提出的计算框架通过促进人和机器之间共享心智模型的形成,为解决本文的核心问题「理想的人机协作应该是什么样的?」
提供了全新的解答。
在这个游戏任务中,我们的工作侧重于以价值和意图为核心对心智进行建模,对齐这些价值可以极大地帮助人类和机器为面向任务的协作建立共同基础,使其可以胜任更加复杂的场景和任务。
因此,我们的工作是在人机协作中朝着更通用的心智模型对齐迈出的第一步。
在未来的工作中,我们计划探索哪些因素能够进一步增强人类用户信任(例如,允许对机器人进行反事实查询),验证「对齐」对任务性能的影响,并将我们的系统应用于涉及更复杂环境和价值函数的任务。
在科幻电影《超能陆战队》中,有一个「大白」智能陪伴机器人,「大白」可以陪电影男主角一起学习、玩耍、做游戏,具有很高的实时互动性。
而当电影男主角情绪失落时,「大白」还能「读懂」他的情感价值需求,主动安慰,给一个大大的拥抱。
朱松纯团队所在的北京通用人工智能研究院,联合北京大学人工智能研究院等单位,致力追寻人工智能的统一理论与认知架构,实现具有自主的感知、认知、决策、学习、执行和社会协作能力,符合人类情感、伦理与道德观念的通用智能体。
本研究从传统AI的「数据驱动」转变为「价值驱动」,让XAI系统理解了人类价值观,朝着通用人工智能迈出了一大步。
https://www.science.org/doi/10.1126/scirobotics.abm4183
![]()