这是我看过,最好懂的神经网络
猜一猜,下图中是什么动物?

图1 看图猜动物
尽管图中的动物胖得出奇,你也应该能够猜到它是一只长颈鹿。人类的大脑拥有强大的辨识能力,它是一个由差不多 800 亿个神经元组成的复杂网络。即使某物并非我们熟知的模样,我们也能够轻松地识别。
大脑神经元彼此协同工作,它们把输入信号(比如长颈鹿的图片)转换成相应的输出标签(比如“长颈鹿”)。
神经网络技术的诞生正是受到人脑神经元的启发。
1. 神经网络
神经网络是自动图像识别的基础,由神经网络衍生出的一些技术在执行速度和准确度上都超过了人类。近年来,神经网络技术大热,这其中主要有 3 个原因。
数据存储和共享技术取得进步。这为训练神经网络提供了海量数据,有助于改善神经网络的性能。
计算能力越来越强大。GPU(graphics processing unit,图形处理器)的运行速度最快能达到CPU(central processing unit,中央处理器)的 150 倍。之前,GPU 主要用来在游戏中显示高品质图像。后来,人们发现它能为在大数据集上训练神经网络提供强大的支持。
算法获得改进。虽然目前神经网络在性能上还很难与人脑媲美,但是已有一些能大幅改善其性能的技术。本文会介绍其中一些技术。
自动图像识别是神经网络技术的有力例证,它被应用于许多领域,包括视觉监控和汽车自主导航,甚至还出现在智能手机中,用来识别手写体。下面来看看如何训练能识别手写体的神经网络。
2. 示例:识别手写数字
下面示例中使用的手写数字来自于 MNIST 数据库,如下图所示。

图2 MNIST 数据库中的手写数字
为了让计算机读取图像,必须先把图像转换成像素。黑色像素用 0 表示,白色像素用 1 表示,如图 3 所示。如果图像是彩色的,则可以使用三原色的色相值来表示。

图3 把一幅图像转换为像素
一旦图像完成像素化,就可以把得到的值交给神经网络。在本例中,神经网络总共得到 10 000 个手写数字以及它们实际所表示的数字。在神经网络学过手写数字及其对应标签的联系之后,我们拿 1000 个新的手写数字(不带标签)来测试它,看看它是否能够全部识别出来。
测试发现,神经网络从 1000 个新的手写数字中正确识别出了 922 个,即正确率达到了 92.2%。下图是一张列联表,可以用它来检查神经网络的识别情况。
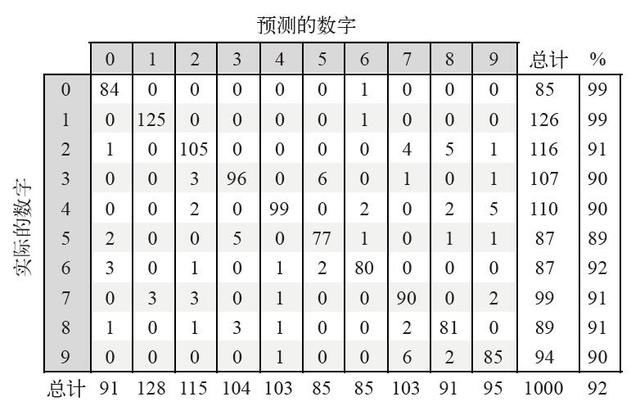
图4 列联表
图4 列联表总结了神经网络的表现:第一行指出,共有 85 个“0”,神经网络正确识别出 84 个,最后一个“0”被错误地识别为“6”。最后一列是识别准确率。
从图4 可以看到,“0”和“1”的手写图像几乎全部被正确识别出来了,而“5”的手写图像最难识别。接下来详细看看那些被识别错的数字。
“2”被错误识别成“7”或“8”的情况大约占8%。虽然人能够轻松识别出图5 中的这些数字,神经网络却可能被某些特征给难住,比如“2”的小尾巴。有趣的是,神经网络对“3”和“5”也比较困惑(如图6 所示),识别错误的情况约占10%。

图5 错误识别“2”

图6 错误识别“3”和“5”
尽管出现了这些错误,但是神经网络的识别速度远快于人类,并且从总体上看,神经网络的识别准确率很高。
3. 神经网络的构成
为了识别手写数字,神经网络使用多层神经元来处理输入图像,以便进行预测。图7 为双层神经网络示意图。
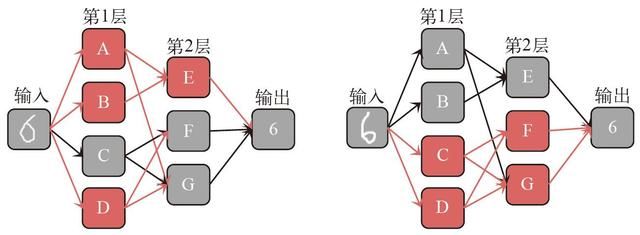
图7 双层神经网络示意图。
输入不同,但是输出相同,其中红色表示被激活的神经元。
在图7 双层神经网络中,虽然输入是“6”的两幅不同形态的图像,但输出是一样的,并且该神经网络使用不同的神经元激活路径。尽管每一个神经元组合产生的预测是唯一的,但是每一个预测结果都可以由多个神经元组合实现。
神经网络通常由如下几部分组成。
输入层:该层处理输入图像的每个像素。如此说来,神经元的数量应该和输入图像的像素数一样多。为简单起见,图7 把大量神经元“凝聚”成一个节点。
为了提高预测准确度,可以使用卷积层。卷积层并不处理单个像素,而是识别像素组合的特征,比如发现“6”有一个圈和一条朝上的尾巴。这种分析只关注特征是否出现,而不关注出现的位置,所以即使某些关键特征偏离了中心,神经网络仍然能够正确识别。这种特性叫作平移不变性。
隐藏层:在像素进入神经网络之后,它们经过层层转换,不断提高和那些标签已知的图像的整体相似度。标签已知是指神经网络以前见过这些图像。虽然转换得越多,预测准确度就会越高,但是处理时间会明显增加。一般来说,几个隐藏层就足够了。每层的神经元数量要和图像的像素数成比例。前面的示例使用了一个隐藏层,它包含 500 个神经元。
输出层:该层产生最终预测结果。在这一层中,神经元可以只有一个,也可以和结果一样多。
损失层:虽然图7 并未显示损失层,但是在神经网络的训练过程中,损失层是存在的。该层通常位于最后,并提供有关输入是否识别正确的反馈;如果不正确,则给出误差量。
在训练神经网络的过程中,损失层至关重要。若预测正确,来自于损失层的反馈会强化产生该预测结果的激活路径;若预测错误,则错误会沿着路径逆向返回,这条路径上的神经元的激活条件就会被重新调整,以减少错误。这个过程称为反向传播。
通过不断重复这个训练过程,神经网络会学习输入信号和正确输出标签之间的联系,并且把这些联系作为激活规则编入每个神经元。因此,为了提高神经网络的预测准确度,需要调整管理激活规则的部件。
4. 激活规则
为了产生预测结果,需要沿着一条路径依次激活神经元。每个神经元的激活过程都由其激活规则所控制,激活规则指定了输入信号的来源和强度。在神经网络的训练过程中,激活规则会不断调整。
图8 展示了神经元 G 的一条激活规则,它模拟的是图7 中的第一个场景。经过训练,神经网络认识到神经元 G 和上一层的神经元 A、C、D 有联系。这 3 个神经元中的任何一个被激活,都会作为输入信号传递给神经元 G。
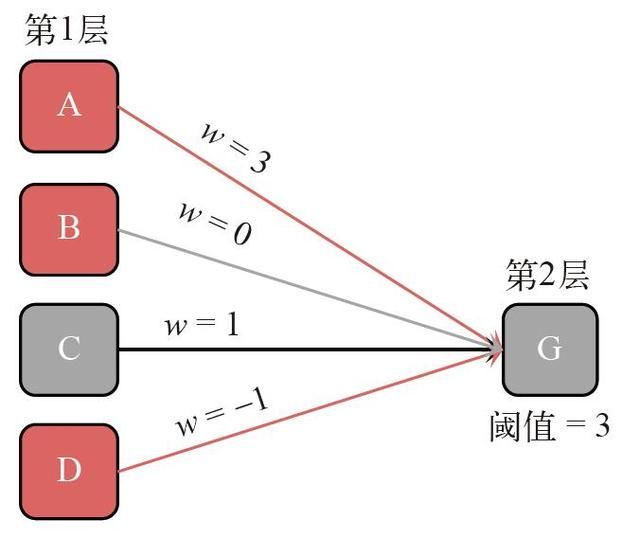
图8 神经元激活规则示例
这些联系的强度各不相同,联系强度也被称为权重,记作w。在图8 中,与神经元 C 相比(w = 1),神经元 A 激活后发送的信号更强(w = 3)。联系也是有方向的,例如神经元 D(w = –1)实际上会减弱传送给神经元G 的输入信号。
在计算神经元 G 的输入信号总强度时,把上一层与之有关联的所有激活神经元的权重加起来。如果信号强度大于指定的阈值,神经元 G 就会被激活。在图8 中,最终的信号强度为2(即3 – 1),由于神经元 G 的阈值为3,因此它仍然处于未激活状态。
良好的激活规则有助于产生准确的预测结果,其关键在于确定合适的权重和阈值。另外,神经网络的其他参数也需要调整,比如隐藏层的数量、每层的神经元数量等。(可以使用梯度下降法优化这些参数。)
5. 局限性
尽管神经网络能在一定程度上模拟人脑,但其本身仍然存在一些缺点。为了克服这些缺点,人们提出了各种各样的方法。
▶ 需要大样本:
神经网络的复杂性使之能够识别带有复杂特征的输入,但前提是我们能为它提供大量训练数据。如果训练集太小,就会出现过拟合问题(算法过度敏感,它把数据中的随机波动错误地当成持久模式)。如果很难获得更多训练数据,则可以使用如下几种技术来最大限度地降低过拟合风险。
二次取样:为了降低神经元对噪声的敏感度,需要对神经网络的输入进行“平滑化”处理,即针对信号样本取平均值,这个过程叫作二次取样。以图像处理为例,可以通过二次取样缩小图像尺寸,或者降低红绿蓝3 个颜色通道的对比度。
畸变:当缺少训练数据时,可以通过向每幅图像引入畸变来产生更多数据。每幅畸变图像都可以作为新的输入,以此扩大训练数据的规模。畸变应该能够反映原数据集的特征。以手写数字为例,可以旋转图像,以模拟人们写字的角度,或者在特定的点进行拉伸和挤压(这叫作弹性变形),从而把手部肌肉不受控制而抖动的特点表现出来。
丢弃:如果可供学习的训练样本很少,神经元就无法彼此建立联系,这会导致出现过拟合问题,因为小的神经元集群之间彼此会产生过度依赖。为了解决这个问题,可以在训练期间随机丢弃一半的神经元。这些遭丢弃的神经元将处于未激活状态,剩下的神经元则正常工作。下一次训练丢弃一组不同的神经元。这迫使不同的神经元协同工作,从而揭示训练样本所包含的更多特征。
▶ 计算成本高:
训练一个由几千个神经元组成的神经网络可能需要很长时间。一个简单的解决方法是升级硬件,但这会花不少钱。另一个解决方法是调整算法,用稍低一些的预测准确度换取更快的处理速度,常用的一些方法如下。
随机梯度下降法:为了更新某一个参数,经典的梯度下降法在一次迭代中使用所有训练样本。当数据集很大时,这样做会很耗时,一种解决方法是在每次迭代中只用一个训练样本来更新参数。这个方法被称为随机梯度下降法,虽然使用这个方法得到的最终参数可能不是最优的,但是准确度不会太低。
梯度下降法:简单地说,梯度下降法先初步猜测合适的权重组合,再通过一个迭代过程,把这些权重应用于每个数据点做预测,然后调整权重,以减少整体预测误差。这个过程类似于一步步走到山底下。每走一步,梯度下降法都要判断从哪个方向下是最陡峭的,然后朝着那个方向重新校准权重。最终,我们会到达最低点,这个点的预测误差最小。
小批次梯度下降法:虽然使用随机梯度下降法能够提升速度,但最终参数可能不准确,算法也可能无法收敛,导致某个参数上下波动。一个折中方法是每次迭代使用训练样本的一个子集,这就是小批次梯度下降法。
全连接层:随着加入的神经元越来越多,路径的数量呈指数增长。为了避免查看所有可能的组合,可以使初始层(处理更小、更低级的特征)的神经元部分连接。只有最后几层(处理更大、更高级的特征)才对相邻层的神经元进行全连接。
▶ 不可解释:
神经网络由多层组成,每层都有几百个神经元,这些神经元由不同的激活规则控制。这使得我们很难准确地找到产生正确预测结果的输入信号组合。这一点和回归分析不同,回归分析能够明确地识别重要的预测变量并比较它们的强弱。神经网络的“黑盒”特性使之难以证明其使用得当,在涉及伦理问题时尤其如此。不过,人们正在努力研究每个神经元层的训练过程,以期了解单个输入信号如何影响最终的预测结果。
尽管存在上述局限性,但是神经网络本身拥有的强大能力使之得以应用于虚拟助手、自动驾驶等前沿领域。除了模拟人脑之外,神经网络在一些领域已经战胜了人类,比如谷歌公司的AlphaGo 在2015 年首次战胜了人类棋手。随着算法不断改进,以及计算能力不断提升,神经网络将在物联网时代发挥关键作用。
6. 小结
神经网络由多个神经元层组成。训练期间,第 1 层的神经元首先被输入数据激活,然后将激活状态传播到后续各层的神经元,最终在输出层产生预测结果。
一个神经元是否被激活取决于输入信号的来源和强度,这由其激活规则指定。激活规则会根据预测结果的反馈不断调整,这个过程被称为反向传播。
在大数据集和先进的计算硬件可用的情况下,神经网络的表现最好。然而,预测结果在大部分时候都是无法解释的。
——
本文节选自《白话机器学习算法》
一本文科生都能看懂的算法入门书
↓↓↓


用通俗易懂的人类语言以及大量有趣的示例和插图,讲解10多种前沿的机器学习算法。
内容涵盖k均值聚类、主成分分析、关联规则、社会网络分析等无监督学习算法,以及回归分析、k最近邻、支持向量机、决策树、随机森林、神经网络等监督学习算法,并概述强化学习算法的思想。
文末畅聊
提到“白话”,你最先想到哪本书?
是《算法图解》还是《简单微积分》?
你印象中最深刻最通俗易懂的是哪本书?
......
写出来跟大家分享一下吧!
精选留言中随机挑选3位小伙伴,
赠送
《白话机器学习算法》纸质书一本。
活动截至到3月29日14:00。

点“好看”的人都不会有Bug了!
分享朋友圈的人都涨工资了!
☟ 【阅读原文】查看机器学习书单




