致所有开发者:警惕文本嵌入模型中的偏差
编者按:在机器学习中,偏差(bias)反映了模型无法客观地描述数据规律。而在文本分析中,模型在某些特殊情况下会产生错误的结果,多半是来源于训练数据中人类的某些“刻板印象”。为了解决这一问题,首先我们需要对其有明确地定位。这篇来自谷歌AI团队的文章为我们揭示了文本嵌入模型中的一些偏差,并且为我们提出了几种寻找问题的工具。以下是论智对原文的编译。
作为机器学习从业者,当我们面临一项任务时,我们通常会选择或是训练一个适合这项任务的模型。例如,假设我们想创建一个系统来判断某个电影评论是积极的还是消极的,我们选取了5个不同的模型,它们的表现性能如下:
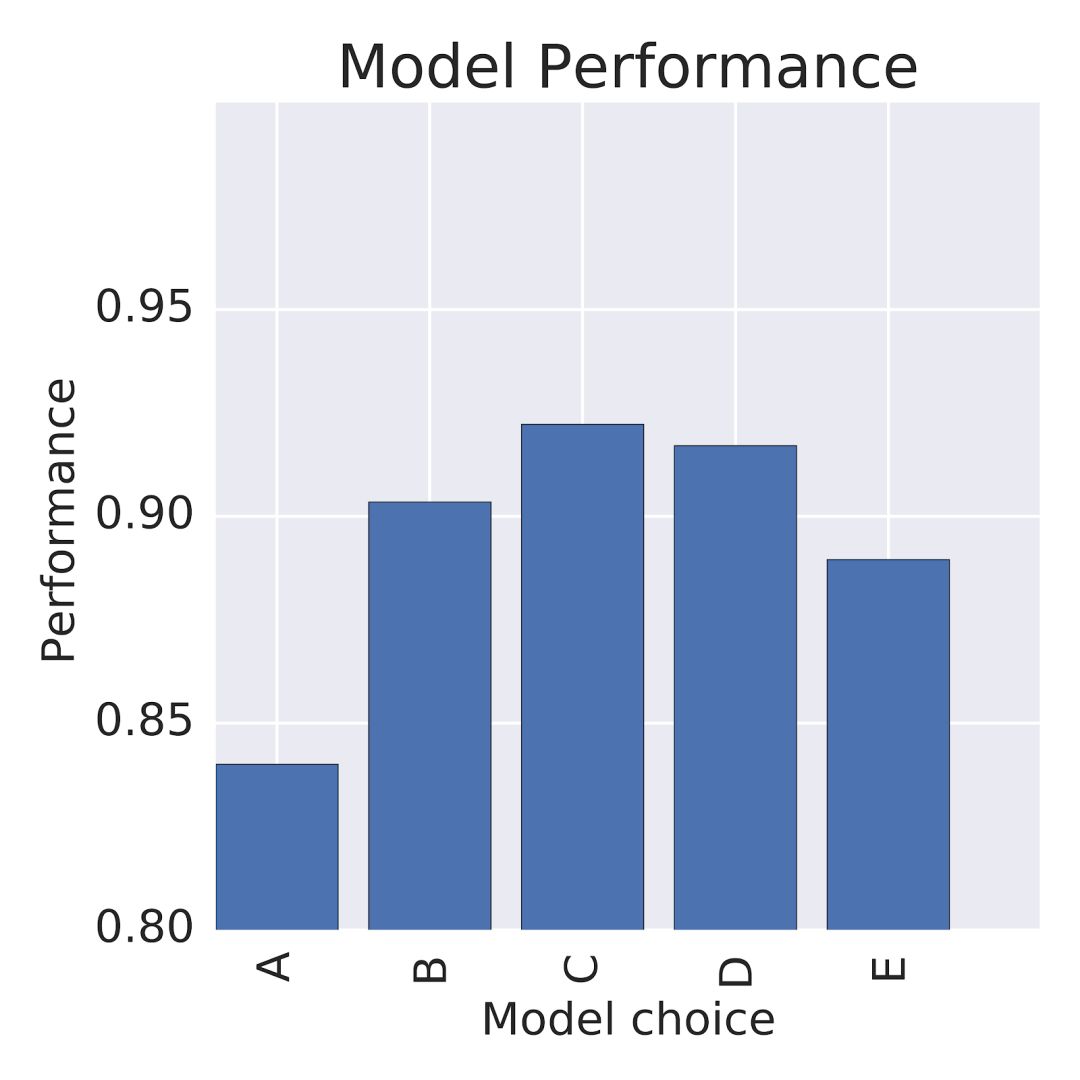
正常情况下,我们会选C模型。虽然C表现得最好,但是如果它会在判断时产生“性别偏见”怎么办?比如,他也许会认为“主角是男性”这句话比“主角是女性”这句话更积极。
机器学习模型中的偏见
神经网络模型相当强大,它们可以在多种任务中有效地帮助确定模式和网络结构,不论是语言翻译、病理解释还是玩游戏。但同时,神经模型,以及其他机器学习模型,却以各种形式反映着它们的偏见。例如,用于检测粗俗无理、暴力的评论分类器,也许对“我是同性恋”的言论比“我是直男(女)”的评论更严苛。对于有色人种中的女性来说,面部分类模型也许表现得不太好;机器在将演讲的语音转换成文字时,非洲裔美国人的话时会比美国白人的错误率更高。
许多预训练的机器学习模型可供开发者进行广泛地使用。例如,TensorFlow Hub最近公开发布了它的平台,开发者需要了解这些模型在应用时会产生怎样的偏见,并且这些偏见是如何在应用中显现出来的。
人类产生的数据将其中的偏见默默带入模型中。意识到这一点是一个好的开始,目前围绕这一问题的解决方案正在展开。在谷歌,我们正积极地研究无意识偏见分析以及解决策略,因为谷歌的愿景是为每位用户创造优秀的产品。在这篇文章中,我们将对几个文本嵌入模型进行检测,介绍一些用于评估特定偏见的工具,并且讨论这些偏见在应用中会带来怎样的影响。
WEAT分数,一种通用测评工具
文本嵌入模型可将任意输入文本转换成数字向量,并且在嵌入空间中,按照语义将相似的词语汇集到一起:
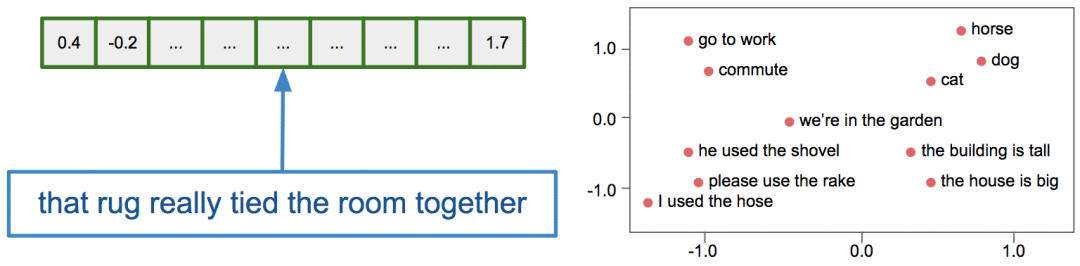
给定一个经过训练的文本嵌入模型,我们可以直接测量模型对词语或短语之间的联系。其中许多联系对自然语言处理任务非常有用。然而,有些联系可能是有问题的,甚至是有害的。例如,在Bolukbasi等人突破性的论文中,他们发现“man”和“woman”之间的向量关系与在谷歌新闻文本上训练过的word2vec嵌入中“physician”和“register nurse”、“shopkeeper”或“housewife”的关系很相似。
最近,由Caliskan等人提出的文本嵌入关系测试(WEAT)是一种用于测试隐含关系检测中词嵌入之间关系的方法。在这里,我们用WEAT检测有偏见的问题关系。
WEAT测量了模型将目标词(例如非洲裔美国人的名字、欧洲裔美国人的名字、花卉、昆虫等)与定语(例如“稳定”、“愉快”或“不愉快”等)之间的联系程度。两个词语之间的关系用嵌入向量之间的余弦相似度表示。
例如,WEAT测试的第一组目标词是花卉和昆虫的类型,定语是表示快乐的词(例如“爱”、“和平”)和不愉快的词(例如“仇恨”、“丑陋”)。总体测试的分数显示,相比于昆虫,花卉与愉快的词关系更密。
虽然最初由Caliskan等人提出的两个WEAT测试并不能展示更多的社会问题,不过接下来的测试更能体现偏见问题。
我们用WEAT分数测试了几个词语嵌入模型:word2vec和GloVe,以及最近新发布的三个基于TensorFlow Hub平台的模型——nnlm-en-dim50、nnlm-en-dim128以及universal-sentence-encoder。具体分数如下表所示:
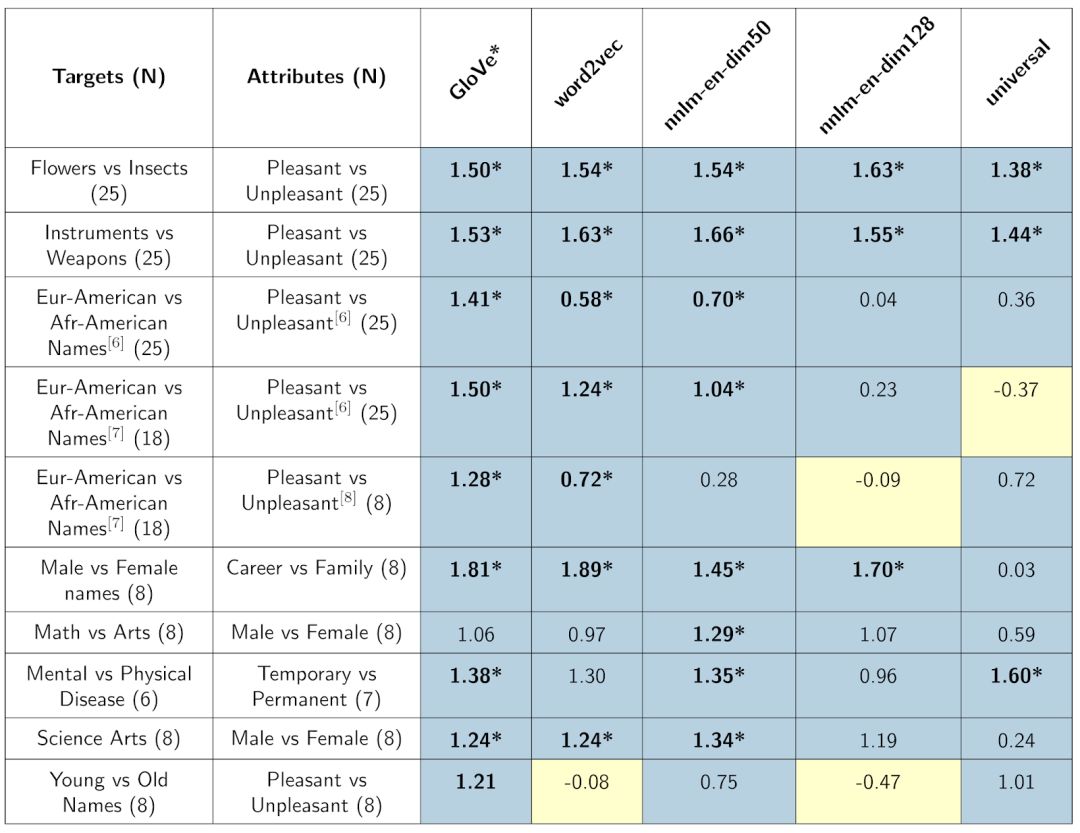
表格中的颜色表示所测偏见与人类的是否相符,蓝色表示相符,黄色表示不符
这种关系是从训练这些模型中的数据中得来。所有的模型学习了花卉、昆虫、乐器和武器等等这些我们认为可能对文本理解有用的关系。然后再将这些学来的关系用于其他目标词,强化模型对人类常有的偏见理解。
对于使用这些模型的开发者来说,必须意识到这些关系的存在是非常重要的,然而上述测试只评估了小部分存在问题的偏见。如何减少无意识产生的偏见是目前一个新的研究领域,并且没有一个通用的应用。
当我们关注嵌入模型中的关联时,理解它们如何影响下游应用程序的最明确的方法是直接检查这些应用程序。下面,我们就对两个程序进行简要分析:情感文本分析器和一个信息通讯APP。
案例一:Tia的电影情感分析
WEAT分数测量了词嵌入的性质,但并没有告诉我们这些嵌入是如何影响下游任务的。在这里,我们研究了在一段影评中嵌入的名字是如何影响情感分析的。
Tia正在训练一个电影评论情感分析器。但是她并不具备许多影评样本,于是它利用预先训练好的嵌入,这些嵌入将文字映射成表示,能让分类任务变得容易。
假设Tia使用的是IMDB影评数据集,从中采样了1000条积极评论和1000条消极评论。我们将用一个预训练的词嵌入将IMDB中的文本映射到低维度向量中,然后利用这些向量作为线性分类器中的特征。之后将利用一些不同的次嵌入模型,为每个模型训练一个线性情感分类器。
我们将用ROC曲线下面积(AUC)来评估情感分类器的质量。
以下各电影情感分类器的AUC分数:
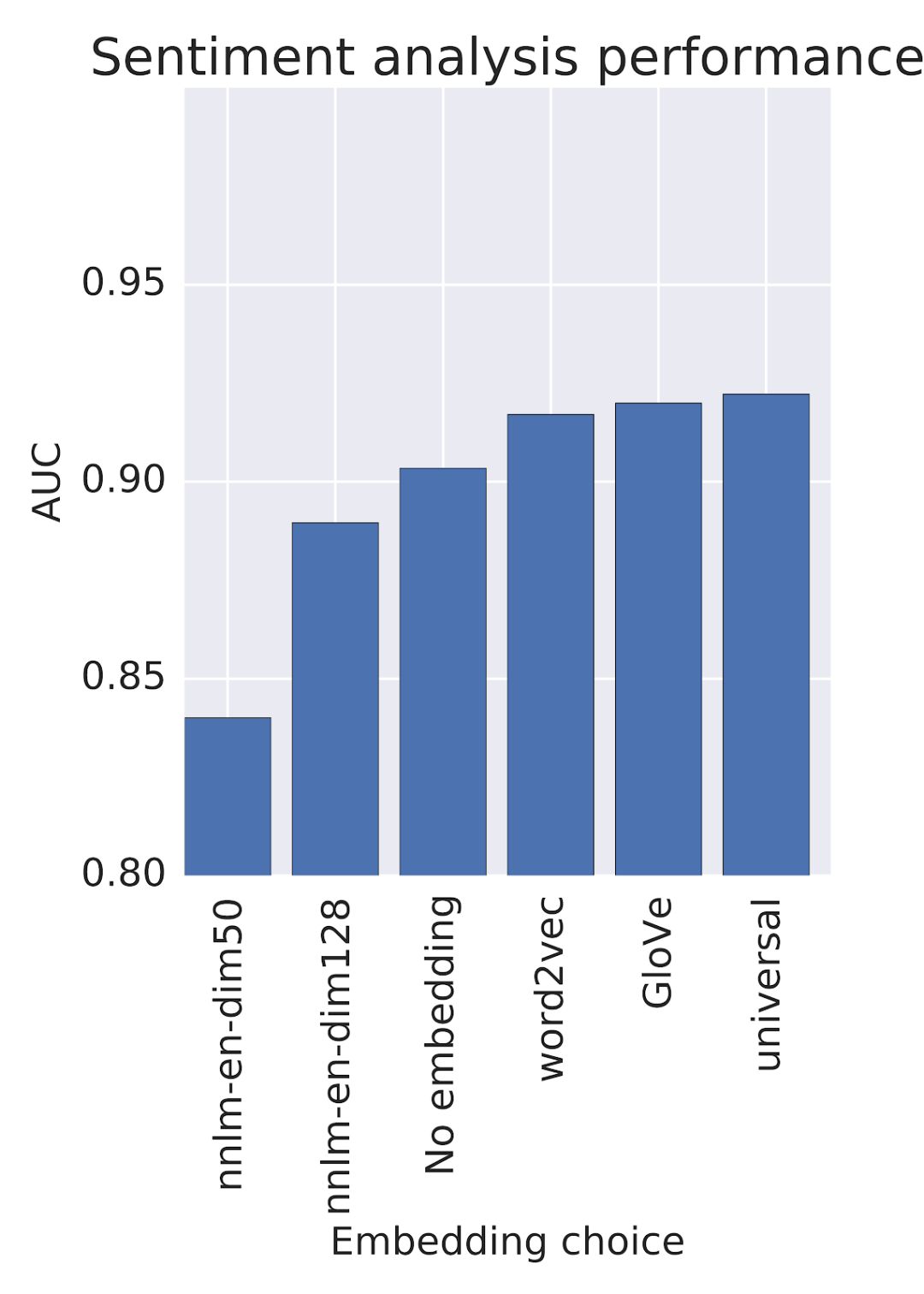
最初,Tia似乎很容易做出选择,按理来说他应该选分数最高的那个模型。
但是,让我们考虑一下其他可能影响决定的方面。词嵌入是在大型数据集上训练的,在这之前Tia可能从未接触过。她想评估一下这些数据集中的偏见是否会影响分类器的行为。
再来看看上图的WEAT分数,Tia注意到一些嵌入将某些特定对象归为“愉快”的分数比其他嵌入更高。这对电影情绪分析器来说不像是一个好特征。Tia认为,名字不应该影响电影的对影评情绪的分析。她决定检测这种偏见是如何影响分类任务的。
她开始准备一些测试案例,看看能否检测出明显的偏见。
在这个例子中,她从测试数据集中选取了100条短评,然后附上这样一句话:“由_评论”,空白处填人名。她将Caliskan的“非洲裔美国人”和“欧洲裔美国人”名字以及美国社会安全局统计的最常用男女名字填入空白处后,发现了平均情感分数之间的差异。
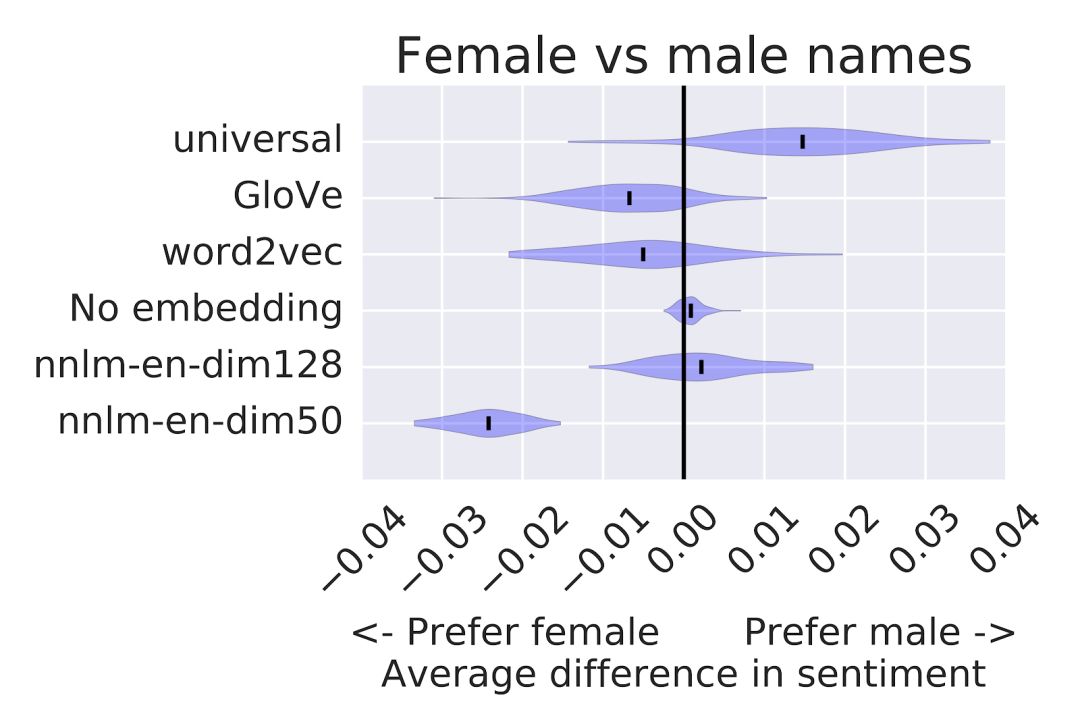
图中最上方的紫色曲线是Tia可能看到的平均情感分数,由最初IMDB的1000条积极评论和1000条消极评论生成。下面是5种词嵌入的结果(其中一种没有用词嵌入的模型结果)。
比较有嵌入和无嵌入的情感分数,可以明显得出结论:与人名相关的情感分数与IMDB数据集并没有关系,而是来源于预训练的嵌入。我们同样可以发现,不同的嵌入会导致不同的输出,说明对嵌入的选择是创建分类器时的重要因素。
Tia需要认真思考她的分类器将如何使用。也许她的目的只是为了通过看影片为自己找好电影。如果是这种情况,那就没什么大问题。出现在列表上方的就很有可能是受欢迎的电影。但如果她要根据影评雇佣电影中的演员,那就有点不妥了。
除此之外,偏见带来的影响还有很多。她也许会想到其他解决方法,例如将所有人名映射到单一词语类型中、用不敏感的人名重新训练嵌入、或是使用多种嵌入处理模型不一致的问题。
这里没有标准解决方案,具体的方法还要取决于Tia当时所处的情况。所以当Tia想要选择特征提取方法时,需要考虑多种因素。
案例二:Tamera的信息APP
Tamera正在打造一款即使通讯APP,她想用文本嵌入模型向用户提供快捷回复。她已经建立了一套回复特定信息的系统,现在她想用文本嵌入模型评估这些回复句子。具体来说,她会把要回复的信息输入模型后得到信息嵌入向量,然后将每条快捷回复的嵌入向量和信息嵌入向量之间的余弦相似性进行打分。
但是,一些快捷回复中可能存在模型的偏见,她决定专注解决其中一个方面:职业和性别的关系。其中一个典型例子是:如果收到了一条信息是“工程师完成项目了吗?”,模型经过评估后发现,“是的,他完成了”比“是的,她完成了”的分数要高。这些联系是从训练嵌入的数据中学来的,虽然它反映了任何性别都有可能出现在训练数据中(现实中这种职业确实有性别不平等的现象),但是在实际应用中,这种“默认工程师是男性”的回复确实可能造成负面体验。
为了测量这种偏见,她创建了一个模块化的提示和回复流程。其中包括的问题有“你的表亲(曾)是一名XX吗?”或者“XX今天在这里吗?”,答案模板有“是的,她(他)是/不是”。对于一个特定之一和问题,比如“水管工今天会来吗?”,模型的分数来源于模型对女性回答和男性回答的差异。
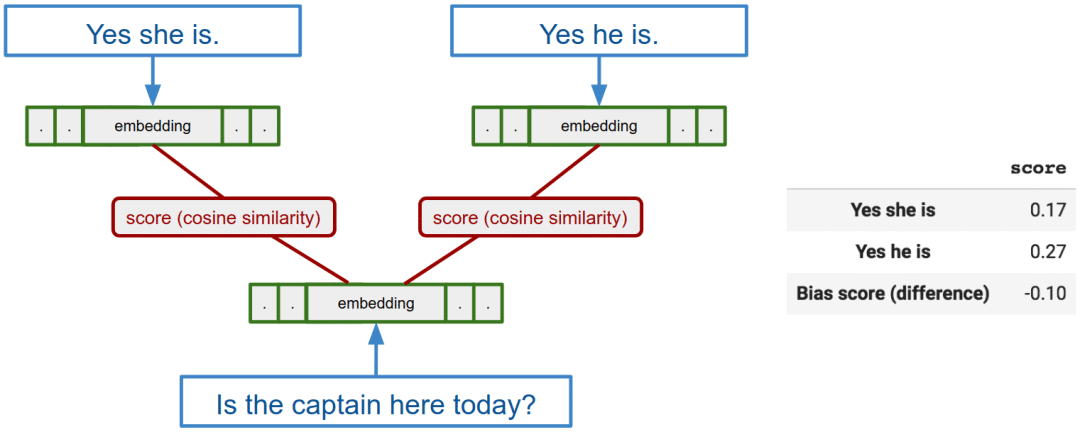
通常对于一个特定职业,模型的偏差分数是有关该职业所有问题和答案的偏差分数之和。
Tamera用Universal Sentence Encoder嵌入模型分析了200个职业后,列出了最常见的带有偏见的职业,左边是女性职业,右边是男性职业:
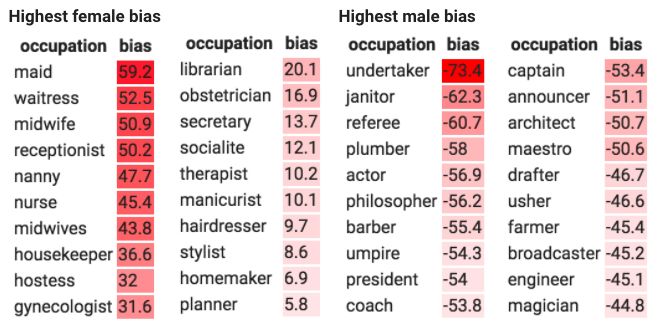
在有关“服务员”的问题上,回答中用“她”的确很常见,但是其他一些问题更应引起人们的注意。Tamera可以选择忽略这些偏见或者在用户界面上做一些更改,例如提供两种类型的回答。或是用偏见减轻技术重新训练嵌入模型,并研究这会对下游性能产生什么影响。无论她决定做什么,重要的是她已经了解过这种类型的分析了,知道她的产品会产生怎样的结果,并能为此做出明智的决定。
结语
为了更好地理解机器学习模型可能带来的潜在影响,模型创建者和使用者都应该检查其中可能蕴涵的不良偏见因素。文中我们展示了一些检测偏见的工具,但是这远远包含不了所有形式的偏见。即使是上文使用的WEAT也只涵盖了一小部分。例如,如果一个模型被训练用于消除50个名字带来的偏见,那么该模型就无法避免其他名字或类别带来的偏见。由此产生的低WEAT分数可能会给人一种错觉,即整体上的消极联系已经被解决了。通过这些评估结果我们知道了现存模型的行为方式,以及了解了偏差是如何影响我们正在使用的技术的。我们正努力解决这个问题,我们相信这对于机器学习的发展非常重要。
原文地址:developers.googleblog.com/2018/04/text-embedding-models-contain-bias.html




