【CVPR2022】通过特征Mixing进行主动学习

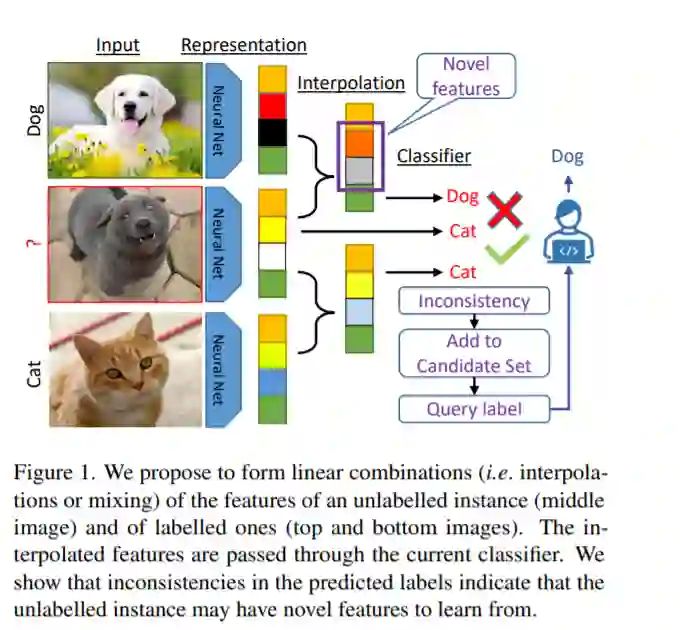
主动学习(AL)的前景是通过从一组未标记的数据中选择最有价值的例子进行注释来降低标签成本。在高维数据(如图像、视频)和低数据状态下,识别这些样例尤其具有挑战性。在本文中,我们提出了一种新的批量主动学习的方法,称为ALFA-Mix。我们通过寻找对其表征的干预所导致的预测的不一致性,来识别具有足够明显特征的未标记实例。我们在带标签和未带标签的实例之间构建插值,然后检查预测的标签。我们表明,这些预测中的不一致性有助于发现模型在未标记的实例中无法识别的特征。我们推导了一个有效的实现基于一个封闭的解决方案的最优插值引起变化的预测。我们的方法在图像、视频和非视觉数据的12个基准上,在30种不同的设置下,比最近所有的人工智能方法表现都好。这种改进在低数据状态下和自训练的视觉transformers上尤为显著,其中ALFA-Mix在试验中分别有59%和43%的表现优于目前的先进水平。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ALFM” 就可以获取《【CVPR2022】通过特征Mixing进行主动学习》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~



登录查看更多
相关内容

主动学习是机器学习(更普遍的说是人工智能)的一个子领域,在统计学领域也叫查询学习、最优实验设计。“学习模块”和“选择策略”是主动学习算法的2个基本且重要的模块。
主动学习是“一种学习方法,在这种方法中,学生会主动或体验性地参与学习过程,并且根据学生的参与程度,有不同程度的主动学习。” (Bonwell&Eison 1991)Bonwell&Eison(1991) 指出:“学生除了被动地听课以外,还从事其他活动。” 在高等教育研究协会(ASHE)的一份报告中,作者讨论了各种促进主动学习的方法。他们引用了一些文献,这些文献表明学生不仅要做听,还必须做更多的事情才能学习。他们必须阅读,写作,讨论并参与解决问题。此过程涉及三个学习领域,即知识,技能和态度(KSA)。这种学习行为分类法可以被认为是“学习过程的目标”。特别是,学生必须从事诸如分析,综合和评估之类的高级思维任务。
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月18日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月18日