【AAAI2022】受限评委下双执行者的高效连续控制
《受限评委下双执行者的高效连续控制》(Efficient Continuous Control with Double Actors and Regularized Critics,作者:控制科学与工程专业2020级博士生吕加飞,导师:李秀)
值函数衡量了从当前的状态出发,采取动作后所能取得的未来累计折扣奖励值。值函数估计问题是强化学习(Reinforcement Learning),尤其是深度强化学习中非常重要的一个问题。对于值函数的准确估计可以使得策略网络向着准确可靠的方向优化。现有的一些值函数估计的经典算法,比如DDPG、TD3等,都或多或少会对值函数进行高估(overestimation)或者低估(underestimation)。近年来的一些方法大多都集中于增强或者改进double critics架构,而长时间忽略了double actors的作用和优点。基于此,作者使用double actors进行值函数修正以获得更好的探索能力和更好的值函数估计,同时对critic网络进行约束以减小值函数估计的不确定度。
https://www.zhuanzhi.ai/paper/064ad32006247d4c1c8dc84b8c3fec1c
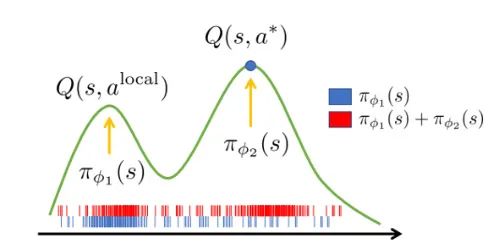
图2:Double actors帮助智能体逃离局部最优。图中绿色曲线为真实Q值的分布示意,蓝色竖线表明使用单个actor得到的分布采样点,而红色竖线表示double actors得到的分布采样点。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“ECDA” 就可以获取《【AAAI2022】受限评委下双执行者的高效连续控制》专知下载链接


登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月16日
Arxiv
0+阅读 · 2022年4月15日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月16日
Arxiv
0+阅读 · 2022年4月15日