最讨厌说大话,只想聊经验!我从创建Hello world神经网络到底学会了什么?

我开始跟神经网络打交道是在几年之前,在看了一篇关于神经网络用途的文章后,我特别渴望能够深入研究一下这个在过去几年间吸引了众多关注的问题解决方案。
2015年,斯坦佛大学研发了一个模型,当时我被这个模型惊艳到了,因为它可以生成图片以及其所属区域的自然语言描述。看完之后,我非常想要做一些类似的工作,于是我开始了搜索。
根据我在其他机器学习领域的相关专题的经验,非常详细的数学解释,各种各样的衍生以及公式让人理解起来特别困难。于是,我决定暂时抛开这些。
当然这并不是说能立即上手写代码。必须学习一些关于神经网络的基本概念,这样才能对神经网络的基本概念有一个了解。
在Google上搜索时,我发现了很多关于神经网络基本概念的线上课程,博客以及学习指南。其中包括梯度下降法,前向和后向的传播,以及我如何在创建神经网络的时候运用它们。非常的简洁实用,我把这些方法总结如下:
前向传播是指通过所有的下面的层来传播每一层的输出,直到我们的输出层。它通常是指一个神经网络在做预测的时候用到的实际计算过程。
后向传播,相反,是指每一次神经网络输出一个预测的时候,会产生一个大的误差,对最小化有影响的输入权重就会相应得到加强。
误差的最小值可以通过梯度下降方法来计算,梯度下降算法是一个可以通过寻找输入函数的逻辑最小值的优化算法。
当然,我们需要学习的东西远不止这些。每一种类型的神经网络,无论是简单的多层感知器还是递归神经网络,都有它们各自的技术细节以及算法,这在我们实施之前是必须要学习的。
倒不是说在我脑子里有某一个特定问题需要解决,只是我决定从最简单的神经网络开始下手研究。利用多层感知器,我们可以轻易地布置回归和分类的任务。把Python定为我的首选语言,可以利用的神经网络的库,包括scikit-learn,Google的Tensorflow ,Keras等等,选择太多了。
我的数据集
我会像其他人那样,使用其中的某一个库,尽管如此,我还是从头开始创建了我的第一个宝贝感知器。尽管我做出来的网络非常简单而且一点儿都不好看。
而这是通往理解的非常关键的一步。我认真选择了架构中的每一个细节,看了训练过程中的计算步骤,最后,我评估了各个结果。
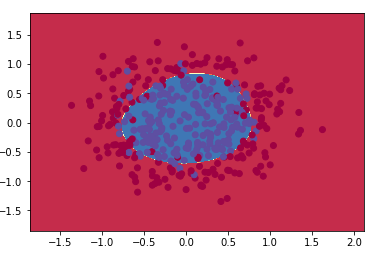
我在这项任务中的输入是scikit-learn 提供的包含400个点的make circle玩具数据集。尽管结果还算令人满意,很显然对于一个更复杂的数据集来讲,我的感知器还不够准确。
MNIST 数据集
随着网络复杂性的上升,从头开始创建神经网络实在是很痛苦的一件事儿。所以,Tensorflow 就是一个非常好的工具。相比Keras我比较喜欢用Tensorflow,Keras可扩展性不强,更像一个黑盒子。
对于新尝试来讲,我需要的数据集要比之前那个更像实际应用中的数据集。这个著名的MNIST数据集是一个很好的选择,它含了具有手写数字的需要被分类的图片。在使用了不同的调试参数实验之后,我们通过具有多个隐藏层和更多计算节点的感知器实现了第一个网络没有达到的很高的精确度。
如果你问我怎么知道每一个调试参数的正确值,我会告诉你其实我也不知道。从我短暂的实操经验和我做过的研究来讲,我想说调试神经网络更像是一种艺术,因为这个过程通常没有固定的规则来引导你去做每一个场景。尽管如此,随着经验的增加,你会通过调试得到一些直觉。
我个人的所有使用技巧,都是通过搜索和询问其他人,包括在这个领域的很多专家得到的。包括以下的建议:
输入和输出的数量:这个决定真的非常简单。输入的数量通常都设置成和输入数据的特征数量相等。而在分类任务中的输出的数量,则是由我们要分的类的数目决定的。
隐藏层的数量:选择的方法有一点模糊。通常对于大多数的任务来说,你可以选择从某一个或者两个层开始完成,评估结果,然后分析你的选择。要记住,只要神经元的数目足够多,再复杂的功能都可以被一个层模拟出来。另一方面,随着隐藏层的增长会导致每层需要神经元的指数级的下降。
每一层的节点数:对于每一个隐藏层的神经元数量,你必须要从新验证一遍。一般都要把每一层的神经元数量设为一个常量,或者设置一个管道化的架构,每一层比前一层都需要更少的神经元。
通过以上这些建议,我最终得到了一个包含两个隐藏层的感知器,每一个隐藏层都分别含有40和30个节点。至于激活和损失功能,我是选择的ReLu并利用交叉熵损失函数对输出层的软件激活。
之所以选择ReLu是因为它更快一些,更重要的是它不容易被困在局部极小值中,因为它不适合大的输入。Softmax适用于在分类任务上的输出层,在这里输出类是唯一的。
这个优化的结果也令人满意,在感知器的50次迭代之后达到了95%以上的精度。
一个真实世界的案例
在建立完一个简单的神经网络之后,我决定用它在一个真实问题上小试牛刀,看看能不能解决实际问题。
为此,找到一个邮件列表分类任务,带有从Mailchimp收集的数据。其中数据包括位置信息、邮件客户端和类型,当然还有接收者所属的邮件列表段。起初,我尝试了与我为MNIST建立的相同的架构,结果令人失望。我的第一个观察是,随着迭代的进行,虽然最初的准确性在增加,但在某一时刻,它开始减少。我的感知器的失败会汇聚到正确的预测,这是因为我为梯度下降中的学习速率设置了一个大值。
在这个步骤中,算法实际是在精确度开始连续下降的那一刻刚好绕过了最小值。为解决这个问题,我选择把学习速率降低到梯度下降最终收敛的程度。
在解决了这个问题之后,我重新训练了感知器,结果还是很糟因为它的准确性没超过25%。在尝试了网络的调优参数之后,我成功地达到了50%的准确率。
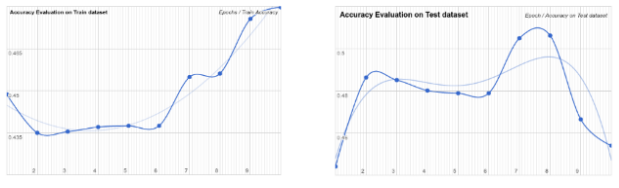
令我吃惊的是,这一精度是由相对较少的隐藏层和计算节点实现的。这是我没有预料到的结果。我的印象是,数据对输出变量没有太多的信息,因此它需要适应更复杂的功能。最让我困扰的是,在只有8次迭代之后,在培训在不断增加的同时,测试数据集的准确性开始急剧下降。根据我的经验,这是一个很明显的过度拟合的例子,但我觉得奇怪的是,这种效果在只进行了8次迭代之后就出现了。
结尾
对我来说,通过整个过程变得明显的是,不同的数据可能需要完全不同的优化。没有什么所谓一般的情况、一般的优化或者类似的东西。此外,寻找一个有效的参数组合,主要是实验的结果。
由于所开发的代码没有针对结果准确性或执行效率进行优化,所以有许多改进的方法,包括如下几点:
对调优参数、激活函数和损失函数进行进一步的试验。
实现非恒定学习速率。首先,我们需要梯度下降的高学习速率,以便快速地向最小值移动。当我们接近最小值时,我们会降低这个步骤的速率,这样算法就不会绕过它。
实现 early stopping(https://en.wikipedia.org/wiki/Early_stopping),使算法停止继续训练,在训练组外数据的精度达到上限的情况下,可以避免牺牲泛化误差的代价。
作者:Eleni Markou
原文链接
https://www.blendo.co/blog/lessons-learned-building-a-hello-world-neural-network/
AI科技大本营目前招聘资深AI采编。AI时代,和我们一起做最贴近AI的媒体!详细职位要求和简历投递方式请见☟☟☟(向下滑动详情)。
要求:
1.熟悉AI领域,对大公司、AI大牛的动态有极强敏感性,且有深度剖析的楞劲儿。
2.英语能力六级以上,看得懂文章,做得了编译,听得懂外文,做得了采访。
3.对AI相关的技术有一定的理解,能追踪最新的技术热点。
4.写稿、编译速度快,快速成稿能力非常重要。
5.语言能力强,行文流畅,写作风格不僵化不生硬。
6.相关媒体经验2年以上。
7.有过重磅深度稿件者优先。
8.对自己极高的要求,工作有极大热情,对成长有极强的动力。
9.时刻保持谦虚,能随时调整状态,跟团队目标紧密配合。
有意者,请将简历投至puge@ai100.ai,标题注明:姓名+手机号+AI采编。有疑问请加微信greta1314。

☞点击阅读原文,查看详细课程信息。



