GANs为何引爆机器学习?这篇基于TensorFlow的实例教程为你解惑!(附开源代码)

「机器人圈导览」: 生成对抗网络无疑是机器学习领域近三年来最火爆的研究领域,相关论文层出不求,各种领域的应用层出不穷。那么,GAN到底如何实践?本文编译自Medium,该文作者以一朵玫瑰花为例,详细阐述了GAN的原理,以及基于谷歌TensorFlow的实现,文章略长,阅读大约需要15分钟。
想象有一天,我们可以利用一个神经网络观看电影并制作自己的电影,或者听歌和创作歌曲。神经网络将从它看到的内容中学习,而且你并不需要明确地告诉它,这种使神经网络学习的方式被称为无监督学习。
实际上,以无监督的方式训练的GAN(生成对抗网络)在过去三年中获得了极大的关注,被认为是目前AI领域最热门的话题之一。就像Facebook AI的主管Yann LeCun认为的那样:
生成对抗网络是机器学习过去十年最有趣的想法。
GAN是理想的神经网络,它在看到某些图像后生成新图像。那么,这可以用来做什么?为什么这很重要?
直到最近,神经网络(特别是卷积神经网络)只擅长分类任务,如在猫和狗、飞机和汽车之间进行分类。但现在,他们可以用来生成图片的猫或狗(即使它们看起来很奇怪),这告诉我们他们已经学会记住特征。
GAN的这种非凡的能力可以应用于许多惊人的应用程序,如:
•生成给定文本描述的图像。

点击此处链接以了解更多信息:The major advancements in Deep Learning in 2016
•图像到图像的翻译:
这可能是GAN最酷的应用。图像到图像翻译可用于很多场景,比如从草图生成逼真的图像,将白天拍摄的图像转换为夜间图像,甚至将黑白图像转换为彩色图像。

查看此链接了解更多详情:基于条件抗网络的图像到图像的翻译
让我们了解一下GAN有什么能力让所有人都对齐大肆吹捧。我们用一个简单的GAN实例生成玫瑰图像。
我们来看看GAN到底是什么?
在我们开始构建GAN之前,我们可以了解它的工作原理。 生成对抗网络包含两个神经网络,一个鉴别器和一个生成器。鉴别器是一个卷积神经网络(CNN)(不知道CNN是什么?请看这个帖子),学习区分真实和假的图像。真实的图像是从数据库中获取的,而假的图像来自生成器。
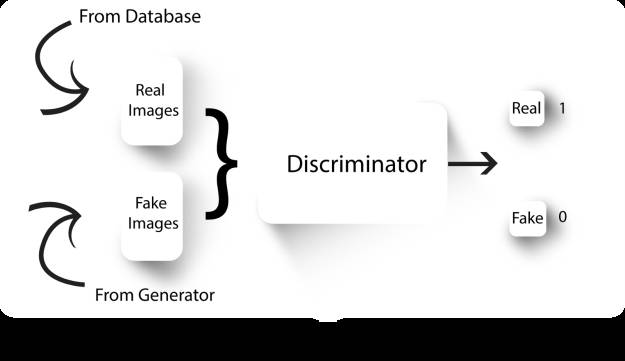
鉴别器
生成器的工作原理就像CNN反向运行,它将一个随机数向量作为输入,并在输出端生成一个图像。
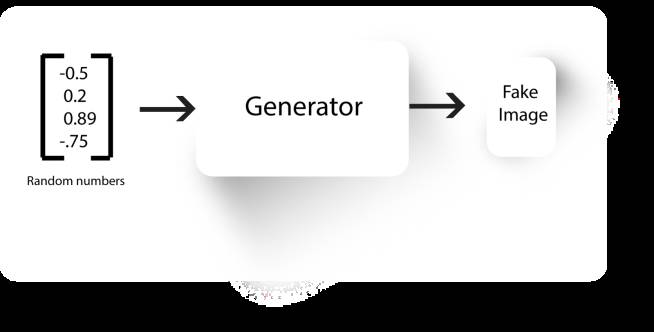
生成器
稍后我们将介绍生成器和鉴别器的工作和实现,但现在我们通过一个非常有名的实例来解释GAN(滥用生成对抗网络生成8位像素艺术)。
我们可以把生成器比作一个伪造者,而把鉴别器视作一个警察,他必须从两枚货币中区分真假。在最开始的时候,我们要确保伪造货币的伪造者和警察都是同样不擅长他们的工作的。因此,伪造者首先生成一些随机的噪声图像。
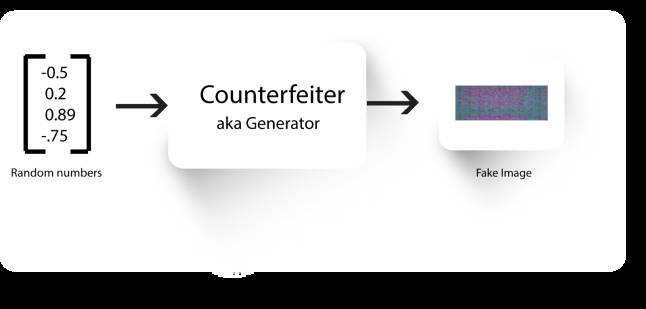
伪造者产生的噪声图像
现在警察接受训练来区分伪造者产生假的的图像和真实的货币。
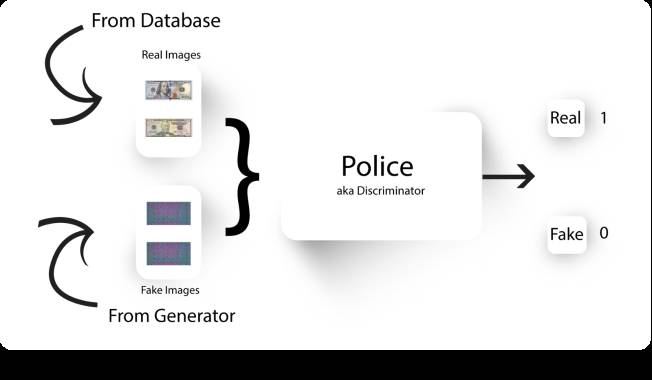
训练警察
伪造者现在已经知道它的图像已被归类为“假”,而警察正在寻找货币所具有的一些独特的特征(如颜色和图案)。伪造者现在在学习这些特征,并生成具有这些特征的图像。
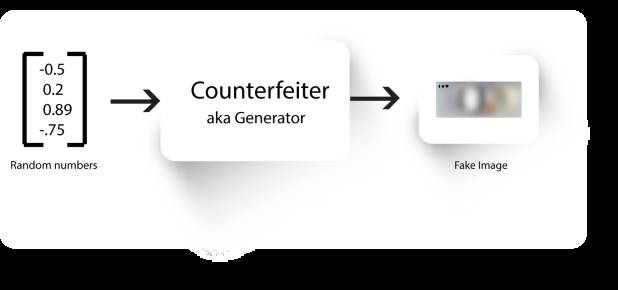
训练伪造者
现在,警察再次区分出数据集中的出真正货币和来自伪造者新改进的图像,并要求对它们进行分类,因此,该警察将会学到更多的关于真实图像的特征(如货币的表面特征)。
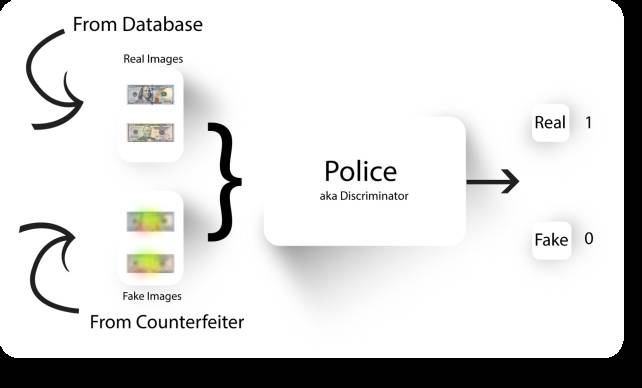
用新的虚假图像来训练警察
而伪造者再次学习这些特征,并产生更好看的假图像。
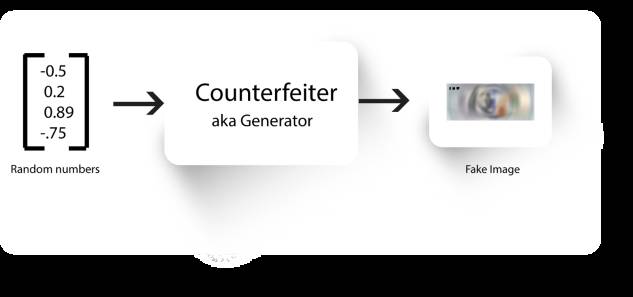
再次训练伪造者
伪造者和警察之间的这场拉锯战将一直持续,直到伪造者生成的图像看起来与真实的图像完全相同,而且警察将无法对其进行分类。
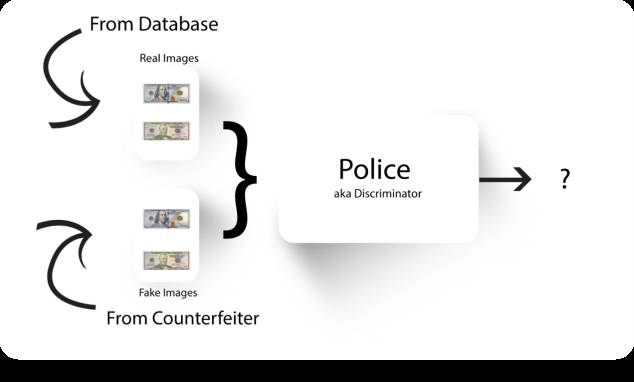
真假难辨
在Tensorflow上生成玫瑰花
我们只用tensorflow而不用其它(除了pillow)来构建一个简单的DCGAN(深度卷积生成对抗式网络)。那么,DCGAN是什么呢?
DCGAN是普通GAN的一个修改版本,以解决普通GAN所涵盖的一些难题,例如:使伪造的图像视觉上看起来比较满意,通过反复输出符合鉴别器正在寻找的但不在实际图像附近的数据分布的图像,在训练过程中提高稳定性,从而使发生器不会在鉴别器中找到缺陷。
下图就是我们正在尝试去构建的鉴别器架构:
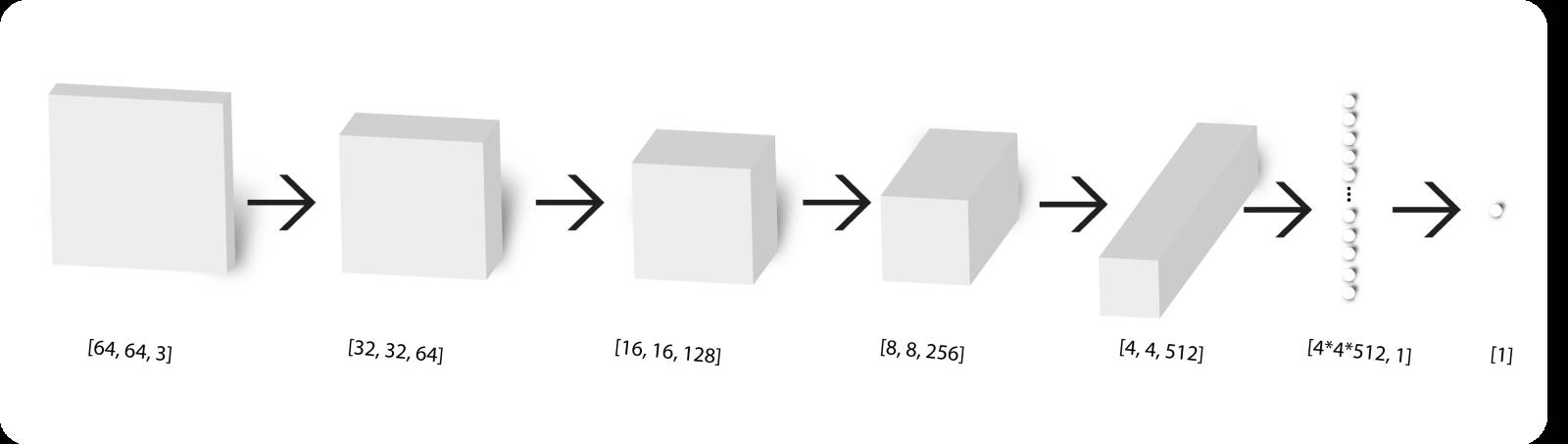
鉴别器架构
可以看出,它将图像作为输入并输出一个logit(1为真类,0为伪类)。
接下来,我们用一个生成器架构,它由conv_transpose层组成,它们将一组随机数作为输入,并在输出端生成一个图像。
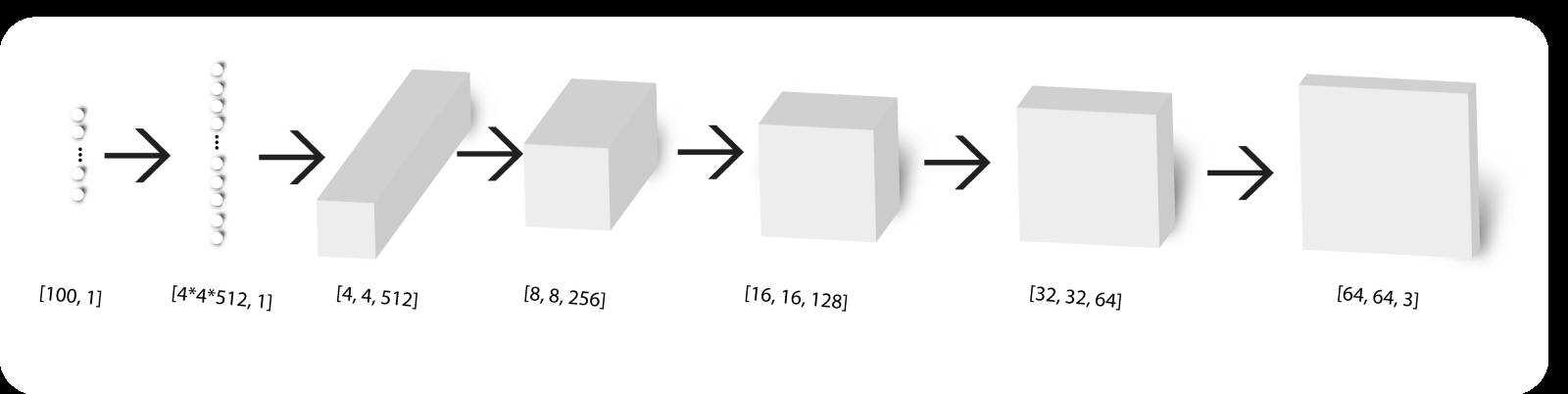
生成器架构
DCGAN可直接产生这篇论文中提到的变化:
•用分段卷积(鉴别器)和分数阶卷积(生成器)替换任何合并层。
•在发生器和鉴别器中使用batchnorm。
•删除完全连接的隐藏层以进行更深层次的体系结构。
•在除了使用Tanh的输出之外的所有图层中的生成器中使用ReLU激活函数。
•在所有层的鉴别器中使用LeakyReLU激活函数。
我们首先需要收集玫瑰图像。一个简单方法就是在Google上进行玫瑰图像搜索,并使用诸如ImageSpark这样的Chrome插件下载搜索结果中的所有图像。
我们收集了67张图片(当然是越多越好)并在这里可用。在以下目录中提取这些图像:
<Project folder>/Dataset/Roses。
点击链接获取更多信息:GANs_N_Roses
既然我们已经有了图像,下一步就是通过将它们重构为64 * 64,并将其缩放值设置为-1和1之间,以预处理这些图像。
def load_dataset(path, data_set='birds', image_size=64):
"""
Loads the images from the specified path
:param path: string indicating the dataset path.
:param data_set: 'birds' -> loads data from birds directory, 'flowers' -> loads data from the flowers directory.
:param image_size: size of images in the returned array
:return: numpy array, shape : [number of images, image_size, image_size, 3]
"""
all_dirs = os.listdir(path)
image_dirs = [i for i in all_dirs if i.endswith(".jpg") or i.endswith(".jpeg") or i.endswith(".png")]
number_of_images = len(image_dirs)
images = []
print("{} images are being loaded...".format(data_set[:-1]))
for c, i in enumerate(image_dirs):
images.append(np.array(ImageOps.fit(Image.open(path + '/' + i),
(image_size, image_size), Image.ANTIALIAS))/127.5 - 1.)
sys.stdout.write("\r Loading : {}/{}"
.format(c + 1, number_of_images))
print("\n")
images = np.reshape(images, [-1, image_size, image_size, 3])
return images.astype(np.float32)
首先,我们写出可用于执行卷积、卷积转置、致密完全连接层和LeakyReLU激活(因为它在Tensorflow上不可用)的函数。
def conv2d(x, inputFeatures, outputFeatures, name):
with tf.variable_scope(name):
w = tf.get_variable("w", [5, 5, inputFeatures, outputFeatures],
initializer=tf.truncated_normal_initializer(stddev=0.02))
b = tf.get_variable("b", [outputFeatures], initializer=tf.constant_initializer(0.0))
conv = tf.nn.conv2d(x, w, strides=[1, 2, 2, 1], padding="SAME") + b
return conv
实现卷积层的函数
我们使用get_variable()而不是通常的Variable(),在tensorflow上创建一个变量,以便以后在不同的函数调用之间共享权重和偏差。 查看这篇文章了解更多有关共享变量的信息。
def conv_transpose(x, outputShape, name):
with tf.variable_scope(name):
w = tf.get_variable("w", [5, 5, outputShape[-1], x.get_shape()[-1]],
initializer=tf.truncated_normal_initializer(stddev=0.02))
b = tf.get_variable("b", [outputShape[-1]], initializer=tf.constant_initializer(0.0))
convt = tf.nn.conv2d_transpose(x, w, output_shape=outputShape, strides=[1, 2, 2, 1])
return convt
实现卷积转置的函数
# fully-conected layer
def dense(x, inputFeatures, outputFeatures, scope=None, with_w=False):
with tf.variable_scope(scope or "Linear"):
matrix = tf.get_variable("Matrix", [inputFeatures, outputFeatures], tf.float32,
tf.random_normal_initializer(stddev=0.02))
bias = tf.get_variable("bias", [outputFeatures], initializer=tf.constant_initializer(0.0))
if with_w:
return tf.matmul(x, matrix) + bias, matrix, bias
else:
return tf.matmul(x, matrix) + bias
实现致密完全连接层的函数
def lrelu(x, leak=0.2, name="lrelu"):
with tf.variable_scope(name):
f1 = 0.5 * (1 + leak)
f2 = 0.5 * (1 - leak)
return f1 * x + f2 * abs(x)
Leaky ReLU
下一步是构建生成器和鉴别器。我们先从主角—生成器开始。我们需要构建的生成器架构如下所示:
我们又一次试图实现的生成器架构
def generator(z, z_dim):
"""
Used to generate fake images to fool the discriminator.
:param z: The input random noise.
:param z_dim: The dimension of the input noise.
:return: Fake images -> [BATCH_SIZE, IMAGE_SIZE, IMAGE_SIZE, 3]
"""
gf_dim = 64
z2 = dense(z, z_dim, gf_dim * 8 * 4 * 4, scope='g_h0_lin')
h0 = tf.nn.relu(batch_norm(tf.reshape(z2, [-1, 4, 4, gf_dim * 8]),
center=True, scale=True, is_training=True, scope='g_bn1'))
h1 = tf.nn.relu(batch_norm(conv_transpose(h0, [mc.BATCH_SIZE, 8, 8, gf_dim * 4], "g_h1"),
center=True, scale=True, is_training=True, scope='g_bn2'))
h2 = tf.nn.relu(batch_norm(conv_transpose(h1, [mc.BATCH_SIZE, 16, 16, gf_dim * 2], "g_h2"),
center=True, scale=True, is_training=True, scope='g_bn3'))
h3 = tf.nn.relu(batch_norm(conv_transpose(h2, [mc.BATCH_SIZE, 32, 32, gf_dim * 1], "g_h3"),
center=True, scale=True, is_training=True, scope='g_bn4'))
h4 = conv_transpose(h3, [mc.BATCH_SIZE, 64, 64, 3], "g_h4")
return tf.nn.tanh(h4)
generator()函数使用上图中的体系架构构建一个生成器。诸如除去所有完全连接层,仅在发生器上使用ReLU以及使用批量归一化,这些任务DCGAN要求已经达标。
类似地,鉴别器也可以很容易地构造成如下图所示:
所需架构:
鉴别器架构
def discriminator(image, reuse=False):
"""
Used to distinguish between real and fake images.
:param image: Images feed to the discriminate.
:param reuse: Set this to True to allow the weights to be reused.
:return: A logits value.
"""
df_dim = 64
if reuse:
tf.get_variable_scope().reuse_variables()
h0 = lrelu(conv2d(image, 3, df_dim, name='d_h0_conv'))
h1 = lrelu(batch_norm(conv2d(h0, df_dim, df_dim * 2, name='d_h1_conv'),
center=True, scale=True, is_training=True, scope='d_bn1'))
h2 = lrelu(batch_norm(conv2d(h1, df_dim * 2, df_dim * 4, name='d_h2_conv'),
center=True, scale=True, is_training=True, scope='d_bn2'))
h3 = lrelu(batch_norm(conv2d(h2, df_dim * 4, df_dim * 8, name='d_h3_conv'),
center=True, scale=True, is_training=True, scope='d_bn3'))
h4 = dense(tf.reshape(h3, [-1, 4 * 4 * df_dim * 8]), 4 * 4 * df_dim * 8, 1, scope='d_h3_lin')
return h4
我们再次避免了密集的完全连接的层,使用了Leaky ReLU,并在Discriminator处进行了批处理。
下面到了有趣的部分,我们要训练这些网络:
鉴别器和发生器的损耗函数如下所示:
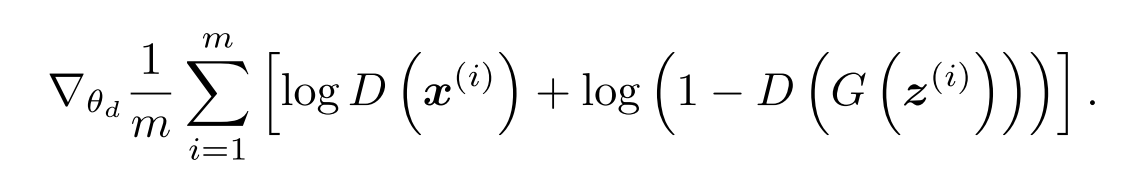
鉴别器损耗函数
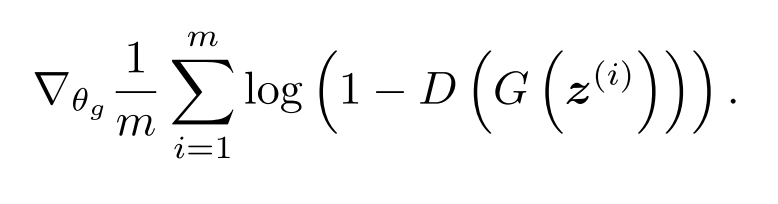
生成器损耗函数
G = generator(zin, z_dim) # G(z)
Dx = discriminator(images) # D(x)
Dg = discriminator(G, reuse=True) # D(G(x))
我们将随机输入传递给发生器,输入阻抗为[BATCH_SIZE,Z_DIM],生成器现在应该在其输出端给出BATCH_SIZE伪图像数。生成器输出的大小现在将为[BATCH_SIZE,IMAGE_SIZE,IMAGE_SIZE,3]。
D(x)是识别真实图像或虚假图像,进行训练以便区分它们的鉴别器。为了在真实图像上训练鉴别器,我们将真实图像批处理传递给D(x),并将目标设置为1。类似地,想要在来自生成器的假图像上对其进行训练的话,我们将使用D(g)将生成器的输出连接到鉴别器的输入上。D的损失是使用tensorflow的内置函数实现的:
d_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dx, targets=tf.ones_like(Dx)))
d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dg, targets=tf.zeros_like(Dg))) d_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dg, targets=tf.zeros_like(Dg)))
dloss = d_loss_real + d_loss_fake
我们接下来需要训练生成器,以便D(g)将输出为1,即我们将修正鉴别器上的权重,并且仅在生成器权重上返回,以便鉴别器总是输出为1。
因此,生成器的损耗函数为:
gloss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=Dg, targets=tf.ones_like(Dg)))
接下来我们将收集鉴别器和生成器的所有权重(以后需要对发生器或判别器进行训练):
# Get the variables which need to be trained
t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if 'd_' in var.name]
g_vars = [var for var in t_vars if 'g_' in var.name]
我们使用tensorflow的AdamOptimizer来学习权重。接下来我们将需要修改的权重传递给鉴别器和生成器的优化器。
with tf.variable_scope(tf.get_variable_scope(), reuse=False) as scope:
d_optim = tf.train.AdamOptimizer(learning_rate, beta1=beta1).minimize(dloss, var_list=d_vars)
g_optim = tf.train.AdamOptimizer(learning_rate, beta1=beta1).minimize(gloss, var_list=g_vars)
最后一步是运行会话并将所需的图像批处理传递给优化器。我们将对这个模型进行30000次迭代训练,并定期显示鉴别器和发生器损耗。
with tf.Session() as sess:
tf.global_variables_initializer().run()
writer = tf.summary.FileWriter(logdir=logdir, graph=sess.graph)
if not load:
for idx in range(n_iter):
batch_images = next_batch(real_img, batch_size=batch_size)
batch_z = np.random.uniform(-1, 1, [batch_size, z_dim]).astype(np.float32)
for k in range(1):
sess.run([d_optim], feed_dict={images: batch_images, zin: batch_z})
for k in range(1):
sess.run([g_optim], feed_dict={zin: batch_z})
print("[%4d/%4d] time: %4.4f, " % (idx, n_iter, time.time() - start_time))
if idx % 10 == 0:
# Display the loss and run tf summaries
summary = sess.run(summary_op, feed_dict={images: batch_images, zin: batch_z})
writer.add_summary(summary, global_step=idx)
d_loss = d_loss_fake.eval({zin: display_z, images: batch_images})
g_loss = gloss.eval({zin: batch_z})
print("\n Discriminator loss: {0} \n Generator loss: {1} \n".format(d_loss, g_loss))
if idx % 1000 == 0:
# Save the model after every 1000 iternations
saver.save(sess, saved_models_path + "/train", global_step=idx)
为了简化调整超参数,并在每次运行时保存结果,我们实现了form_results函数和mission_control.py文件。
该网络的所有超参数可以在mission_control.py文件中进行修改,之后运行的main.py文件将自动为每次运行创建文件夹,并保存数据库文件和生成的图像。
"""
Contains all the variables necessary to run gans_n_roses.py file.
"""
# Set LOAD to True to load a trained model or set it False to train a new one.
LOAD = False
# Dataset directories
DATASET_PATH = './Dataset/Roses/'
DATASET_CHOSEN = 'roses' # required by utils.py -> ['birds', 'flowers', 'black_birds']
# Model hyperparameters
Z_DIM = 100 # The input noise vector dimension
BATCH_SIZE = 12
N_ITERATIONS = 30000
LEARNING_RATE = 0.0002
BETA_1 = 0.5
IMAGE_SIZE = 64 # Change the Generator model if the IMAGE_SIZE needs to be changed to a different value
我们可以通过打开tensorboard,在训练期间的每次迭代中查鉴别器和生成器的损耗,并将其指向在每个运行文件夹下创建的Tensorboard目录中。
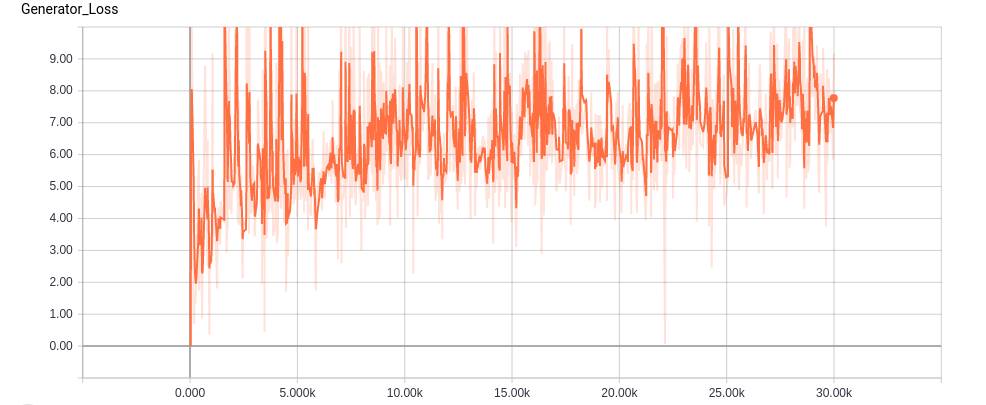
训练期间发生器损耗的变化
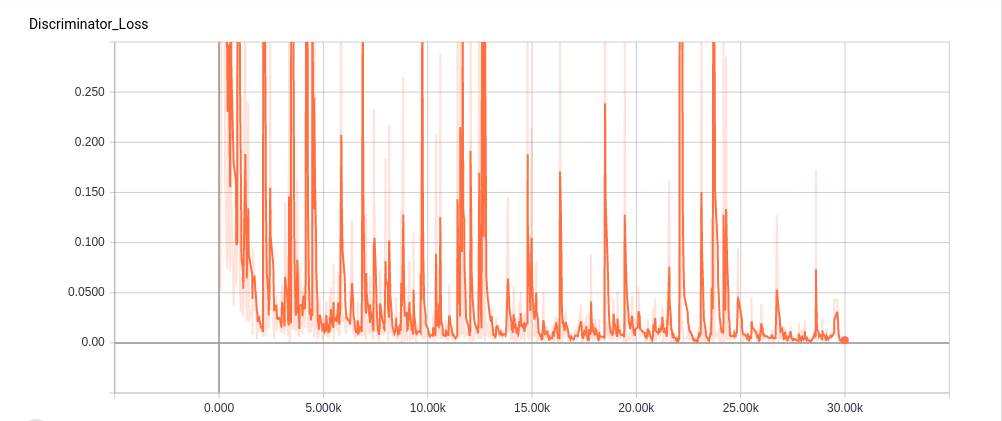
训练期间鉴别器损耗的变化
从这些图可以看出,在训练阶段,鉴别器和生成器损耗在不断增加,表明生成器和鉴别器都试图相互执行。
代码还可以为每次运行保存生成的图像,其中一些图像如下所示:
在第0次迭代:

第100次迭代:

第1000次迭代:

图像在第30000次迭代中被过度拟合:

训练阶段生成的图像如图所示:
这些图像是有希望实现目标的,但是经过大约1000次迭代,可以看出,发生器只是从训练数据集中再现图像。我们可以使用较大的数据集,并进行较少数量的迭代训练,以减少过度拟合。
GAN易于实现,但如果没有正确的超参数和网络架构,是难以进行训练的。我们写这篇文章主要是为了帮助人们开始使用生成网络。
用GAN还可以做什么呢?


中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展


关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人产业网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册



