【注意力机制】一系列关于attention的高效改进大集合
前几天逛github刷到一个『awesome-fast-attention』大列表,整理了一系列关于attention的高效改进文章,包括论文、引用量、源码实现、算法复杂度以及关键亮点。其中一部分论文,我们在之前的『Transformer Assemble』系列文章中也都有作过解读~
Efficient Attention
| Paper (引用量) | 源码实现 | 复杂度 | AutoRegressive | Main Idea |
|---|---|---|---|---|
| Generating Wikipedia by Summarizing Long Sequences[1] (208) | memory-compressed-attention[2] |
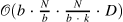 |
 |
|
| CBAM: Convolutional Block Attention Module[3] (677) | attention-module[4]  |
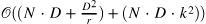 |
|
|
| CCNet: Criss-Cross Attention for Semantic Segmentation[5] (149) | CCNet[6] |
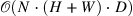 |
|
|
| Efficient Attention: Attention with Linear Complexities[7] (2) | efficient-attention[8] |
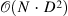 |
|
|
| Star-Transformer[9] (24) | fastNLP[10] |
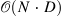 |
|
|
| Generating Long Sequences with Sparse Transformers[11] (139) | torch-blocksparse[12] |
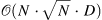 |
 |
|
| GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond[13] (96) | GCNet[14]  |
|
|
|
| SCRAM: Spatially Coherent Randomized Attention Maps[15] (1) | - | 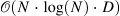 |
|
|
| Interlaced Sparse Self-Attention for Semantic Segmentation[16] (13) | IN_PAPER | 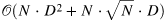 |
|
|
| Permutohedral Attention Module for Efficient Non-Local Neural Networks[17] (2) | Permutohedral_attention_module[18] |
|
|
|
| Large Memory Layers with Product Keys[19] (28) | XLM[20] |
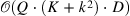 |
|
|
| Expectation-Maximization Attention Networks for Semantic Segmentation[21] (38) | EMANet[22] |
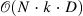 |
|
|
| Compressive Transformers for Long-Range Sequence Modelling[23] (20) | compressive-transformer-pytorch[24] |
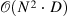 |
|
|
| BP-Transformer: Modelling Long-Range Context via Binary Partitioning[25] (8) | BPT[26] |
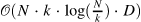 |
|
|
| Axial Attention in Multidimensional Transformers[27] (5) | axial-attention[28] |
|
|
|
| Reformer: The Efficient Transformer[29] (69) | trax[30] |
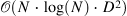 |
|
|
| Transformer on a Diet[31] (2) | transformer-on-diet[32] |
|
||
| Sparse Sinkhorn Attention[33] (4) | sinkhorn-transformer[34] |
|
||
| SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection[35] (1) | - | |
||
| Efficient Content-Based Sparse Attention with Routing Transformers[36] (11) | routing-transformer[37] |
|
||
| Longformer: The Long-Document Transformer[38] (15) | longformer[39] |
|
||
| Neural Architecture Search for Lightweight Non-Local Networks[40] (2) | AutoNL[41] |
|
||
| ETC: Encoding Long and Structured Data in Transformers[42] (2) | - | |
||
| Multi-scale Transformer Language Models[43] (1) | IN_PAPER | |
||
| Synthesizer: Rethinking Self-Attention in Transformer Models[44] (5) | - | |
||
| Jukebox: A Generative Model for Music[45] (9) | jukebox[46] |
|
||
| GMAT: Global Memory Augmentation for Transformers[47] (0) | gmat[48] |
|
||
| Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers[49] (0) | google-research[50] |
|
||
| Hand-crafted Attention is All You Need? A Study of Attention on Self-supervised Audio Transformer[51] (0) | - | |
||
| Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention[52] (1) | fast-transformers[53] |
|
||
| Linformer: Self-Attention with Linear Complexity[54] (3) | linformer-pytorch[55] |
|
||
| Real-time Semantic Segmentation with Fast Attention[56] (0) | - | |
||
| Fast Transformers with Clustered Attention[57] (0) | fast-transformers[58] |
|
||
| Big Bird: Transformers for Longer Sequences[59] (0) | - | |
文章
-
A Survey of Long-Term Context in Transformers [60] -
Transformers Assemble(PART I)
-
Transformers Assemble(PART II)
-
Transformers Assemble(PART III)
-
Transformers Assemble(PART IV)
-
Transformers Assemble(PART V)
-
ICLR2020 | 深度自适应Transformer
-
Memory Transformer,一种简单明了的Transformer改造方案
-
【ICLR2020】Transformer Complex-order:一种新的位置编码方式
本文参考资料
Generating Wikipedia by Summarizing Long Sequences: https://arxiv.org/abs/1801.10198v1
[2]memory-compressed-attention: https://github.com/lucidrains/memory-compressed-attention
[3]CBAM: Convolutional Block Attention Module: https://arxiv.org/abs/1807.06521v2
[4]attention-module: https://github.com/Jongchan/attention-module
[5]CCNet: Criss-Cross Attention for Semantic Segmentation: https://arxiv.org/abs/1811.11721v2
[6]CCNet: https://github.com/speedinghzl/CCNet
[7]Efficient Attention: Attention with Linear Complexities: https://arxiv.org/abs/1812.01243v8
[8]efficient-attention: https://github.com/cmsflash/efficient-attention
[9]Star-Transformer: https://arxiv.org/abs/1902.09113v2
[10]fastNLP: https://github.com/fastnlp/fastNLP/blob/master/fastNLP/modules/encoder/star_transformer.py
[11]Generating Long Sequences with Sparse Transformers: https://arxiv.org/abs/1904.10509v1
[12]torch-blocksparse: https://github.com/ptillet/torch-blocksparse
[13]GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond: https://arxiv.org/abs/1904.11492v1
[14]GCNet: https://github.com/xvjiarui/GCNet
[15]SCRAM: Spatially Coherent Randomized Attention Maps: https://arxiv.org/abs/1905.10308v1
[16]Interlaced Sparse Self-Attention for Semantic Segmentation: https://arxiv.org/abs/1907.12273v2
[17]Permutohedral Attention Module for Efficient Non-Local Neural Networks: https://arxiv.org/abs/1907.00641v2
[18]Permutohedral_attention_module: https://github.com/SamuelJoutard/Permutohedral_attention_module
[19]Large Memory Layers with Product Keys: https://arxiv.org/abs/1907.05242v2
[20]XLM: https://github.com/facebookresearch/XLM
[21]Expectation-Maximization Attention Networks for Semantic Segmentation: https://arxiv.org/abs/1907.13426v2
[22]EMANet: https://github.com/XiaLiPKU/EMANet
[23]Compressive Transformers for Long-Range Sequence Modelling: https://arxiv.org/abs/1911.05507v1
[24]compressive-transformer-pytorch: https://github.com/lucidrains/compressive-transformer-pytorch
[25]BP-Transformer: Modelling Long-Range Context via Binary Partitioning: https://arxiv.org/abs/1911.04070v1
[26]BPT: https://github.com/yzh119/BPT
[27]Axial Attention in Multidimensional Transformers: https://arxiv.org/abs/1912.12180v1
[28]axial-attention: https://github.com/lucidrains/axial-attention
[29]Reformer: The Efficient Transformer: https://arxiv.org/abs/2001.04451v2
[30]trax: https://github.com/google/trax/tree/master/trax/models/reformer
[31]Transformer on a Diet: https://arxiv.org/abs/2002.06170v1
[32]transformer-on-diet: https://github.com/cgraywang/transformer-on-diet
[33]Sparse Sinkhorn Attention: https://arxiv.org/abs/2002.11296v1
[34]sinkhorn-transformer: https://github.com/lucidrains/sinkhorn-transformer
[35]SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection: https://arxiv.org/abs/2003.09833v2
[36]Efficient Content-Based Sparse Attention with Routing Transformers: https://arxiv.org/abs/2003.05997v1
[37]routing-transformer: https://github.com/lucidrains/routing-transformer
[38]Longformer: The Long-Document Transformer: https://arxiv.org/abs/2004.05150v1
[39]longformer: https://github.com/allenai/longformer
[40]Neural Architecture Search for Lightweight Non-Local Networks: https://arxiv.org/abs/2004.01961v1
[41]AutoNL: https://github.com/LiYingwei/AutoNL
[42]ETC: Encoding Long and Structured Data in Transformers: https://arxiv.org/abs/2004.08483v2
[43]Multi-scale Transformer Language Models: https://arxiv.org/abs/2005.00581v1
[44]Synthesizer: Rethinking Self-Attention in Transformer Models: https://arxiv.org/abs/2005.00743v1
[45]Jukebox: A Generative Model for Music: https://arxiv.org/abs/2005.00341v1
[46]jukebox: https://github.com/openai/jukebox
[47]GMAT: Global Memory Augmentation for Transformers: https://arxiv.org/abs/2006.03274v1
[48]gmat: https://github.com/ag1988/gmat
[49]Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers: https://arxiv.org/abs/2006.03555v1
[50]google-research: https://github.com/google-research/google-research/tree/master/performer/fast_self_attention
[51]Hand-crafted Attention is All You Need? A Study of Attention on Self-supervised Audio Transformer: https://arxiv.org/abs/2006.05174v1
[52]Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention: https://arxiv.org/abs/2006.16236v2
[53]fast-transformers: https://github.com/idiap/fast-transformers
[54]Linformer: Self-Attention with Linear Complexity: https://arxiv.org/abs/2006.04768v3
[55]linformer-pytorch: https://github.com/tatp22/linformer-pytorch
[56]Real-time Semantic Segmentation with Fast Attention: https://arxiv.org/abs/2007.03815v2
[57]Fast Transformers with Clustered Attention: https://arxiv.org/abs/2007.04825v1
[58]fast-transformers: https://github.com/idiap/fast-transformers
[59]Big Bird: Transformers for Longer Sequences: https://arxiv.org/abs/2007.14062v1
[60]A Survey of Long-Term Context in Transformers: https://www.pragmatic.ml/a-survey-of-methods-for-incorporating-long-term-context/
- END -
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!




