自动化Web渗透Payload提取技术
本文仅作技术讨论,禁止用于其他非法用途
0x0 写在前面
做Web安全已经三四年了,从最初的小白到今天的初探门路,小鲜肉已经熬成了油腻大叔。Web安全是一个日新月异的朝阳领域,每天的互联网上都在发生着从未暴露的0 Day和N Day攻击。这时一个大家都意识到的重要问题就浮出水面了:如何能从海量Web访问日志中把那一小撮异常请求捞出来,供安全人员分析或进行自动化实时阻断和报警?
对于这个问题,传统的方法是利用传统的WAF(无机器学习引擎),进行规则匹配。传统WAF有其存在的意义,但也有其掣肘。首先,安全从业人员都懂,基于黑名单的防御往往存在各种被绕过的风险,看看安全论坛里各式花样打狗(安全狗)秘籍就可见一斑。其次,传统WAF只能发现已知的安全攻击行为或类型,对于新出现的攻击存在更新延迟,维护上也有比较大的成本。我认为这些问题都源于一个现实——传统WAF不能对其保护的网站进行建模,因此只能基于已知规则,对各式各样的Web系统进行统一的无差别的保护。
近年来,机器学习(包括深度学习)高调闯入人们的视野,也逐步应用在了信息安全领域。基于机器学习的WAF相关论文和文章也看了一些,似乎大家都主要应用了有监督机器学习,也都提到了一个问题:有标记的攻击数据集(黑样本)难于大量获取。而一小波提出无监督异常检测思路的文章,又会遇到精确度低的问题。
针对这些问题,我决定先进行一些分解。既然直接预测整个请求是否是攻击很难做到可接受的准确率,不妨就先把异常的攻击Payload找出来。找出来后,就可以用来进行精准的攻击分析,还可以帮助优化WAF规则等。本文所述的技术最大的优势是无监督,无需先验规则即可自动提取异常Payload。
项目GitHub: https://github.com/zhanghaoyil/Hawk-I (不断完善中,欢迎贡献代码)
0x1 思路
要把异常参数找出来,最显而易见要解决的问题就是如何量化请求中各参数的异常程度。为了最大化利用日志中蕴含的需要保护的Web系统自身的结构信息,我决定对请求按访问路径进行拆解,即分析参数value在同路径同参数Key的其他参数值中的异常程度。
具体算法步骤是:
1) 基于TF-IDF对不同路径下的样本分别进行特征向量化,按参数维度对特征向量进行汇聚。
2) 基于特征向量提取出样本参数在同路径同参数Key的其他参数值中异常分数AS(Anomaly Score)。
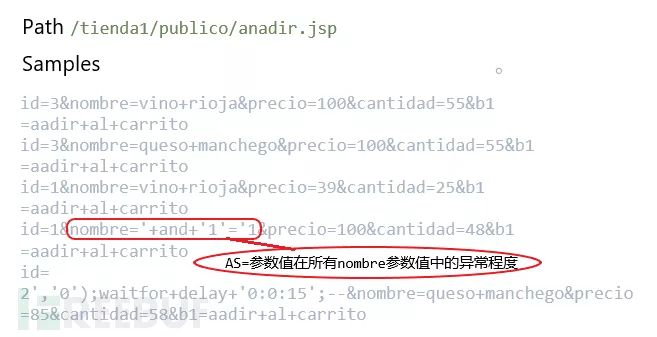
3) 设置阈值T,取出AS大于T的异常参数值作为输出。
0x2 数据集及预处理
本文使用HTTP CSIC 2010数据集。该数据集由西班牙最高科研理事会CSIC在论文Application of the Generic Feature Selection Measure in Detection of Web Attacks中作为附件给出的,是一个电子商务网站的访问日志,包含36000个正常请求和25000多个攻击请求。异常请求样本中包含SQL注入、文件遍历、CRLF注入、XSS、SSI等攻击样本。数据集下载链接:http://www.isi.csic.es/dataset/ 。在本项目Github中也准备好了。
HTTP CSIC 2010数据集单个样本为如下格式:
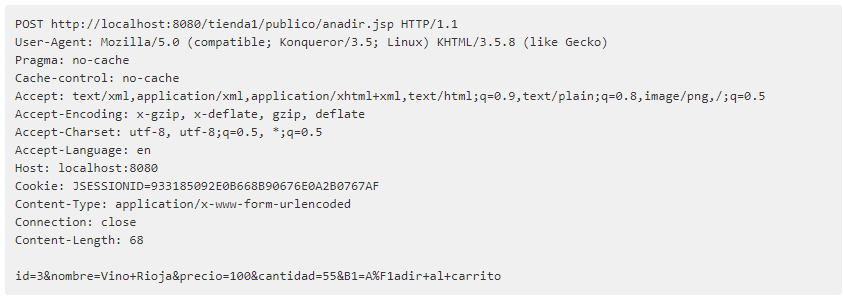
根据观察,该数据集除路径(URI)和参数外其他Header无任何攻击Payload,具有很多冗余信息。因此对该数据集进行格式化,只保留HTTP方法、路径和参数,转为JSON格式方便后面使用。具体进行了如下预处理,具体代码见data/parse.py:
1) 去除冗余信息。
2) 执行迭代的urldecode。
3) 生成标准化的参数,将大小写字母、数字分别转换为a和n。同时保留原始参数和标准化的参数,用于最终的Payload提取。

0x3 实现
根据算法步骤,项目主要分为向量化和参数异常评估和异常Payload提取两部分。
0x3a 向量化和参数异常分数
一个Web访问记录的成分是比较固定的,每个部分(方法、路径、参数、HTTP头、Cookie等)都有比较好的结构化特点。因此可以把Web攻击识别任务抽象为文本分类任务,而且这种思路应用在了安全领域,如有监督的攻击识别[1]、 XSS识别[2] 等。文本分类任务中常用的向量化手段有词袋模型(Bag of Word,BOW)、TF-IDF模型、词向量化(word2vec)等,兜哥的文章[3]已经做了详细的讲解。
经过对Web日志特点的分析,本文认为使用TF-IDF来对样本进行向量化效果更好。一是经过标准化后请求参数的值仍会有非常多的可能性,这种情况下词袋模型生成的特征向量长度会非常大,而且没法收缩;二是每个请求中参数个数有大有小,绝大多数不超过10个,这个时候词向量能表达的信息非常有限,并不能反映出参数value的异常性;三是TF-IDF可以表达出不同请求同一参数的值是否更有特异性,尤其是IDF项。
举个例子, http://ip.taobao.com/ipSearch.html?ipAddr=8.8.8.8 是一个查询IP详细信息的页面(真实存在),在某一段时间内收到了10000个请求,其中9990个请求中ipAddr参数值是符合xx.xx.xx.xx这个IP的格式的,通过0x2中提到的标准化之后,也就是9990个请求的ipAddr参数为n+.n+.n+.n+ (当然这里做了简化,数字不一定为多位)。此外有10个请求的ipAddr是形如alert('XSS')、'or '1' = '1之类的不同的攻击Payload。
经过TF-IDF向量化后,那9900个请求ipAddr=n+.n+.n+.n+这一项的TF-IDF值:
TF-IDF normal = TF IDF = 1 log(10000/(9990+1)) = 0.001
而出现ipAddr=alert('XSS')的请求的TF-IDF值:
TF-IDF abnormal = TF IDF = 1 log(10000/(1+1)) = 8.517
可以看出异常请求参数value的TF-IDF是远大于正常请求的,因此TF-IDF可以很好地反映出参数value的异常程度。
熟悉TF-IDF的同学一定有疑问了,你这TF-IDF的字典也会很大呀,如果样本量很大而且有各式各样的参数value,你的特征向量岂不是稀疏得不行了?对于这个问题,我有一个解决方案,也就是将所有的TF-IDF进一步加以处理,对参数key相同的TF-IDF项进行求和。设参数key集合为K={k1, k2, …, kn},TF-IDF字典为集合x={x1, x2, …, xm}。则每个参数key的特征值为:
vn = ∑TF-IDFxn xn∈{x | x startswith ‘kn=’}
具体代码在vectorize/vectorizer.py中:

这些特征向量能否充分反映样本的异常性呢?我使用未调参的随机森林模型进行验证,得到了大于95%准确率的结果,比较满意。下图是模型学习曲线,可以看出仍处于欠训练的状态,如果样本量更充足的话将会得到更好的效果。
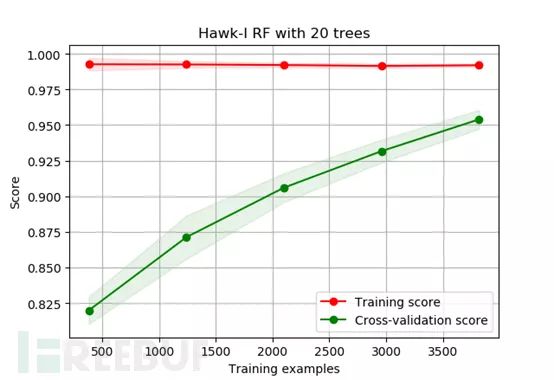
由于本文所述方法旨在使用无监督学习提取异常参数,并不用纠结于有监督分类的结果,只要验证了提取的特征的确可以反映出参数的异常性即可。
0x3b 异常参数值提取
得到参数值的异常分数下面的工作就简单多了,主要就是:
1)数据的标准化(Standardization)
2)根据阈值确定异常参数
3)根据异常分数在训练集矩阵的位置提取对应的参数值
这部分没有什么特别的逻辑,直接看代码吧:

提取结果:

可以看到,至此已经把异常参数值提取出来了,包括SQL注入、XSS、命令注入、CRLF注入、文件包含等典型的攻击Payload。
0x4 后续计划
这篇文章算是我在信息安全领域应用机器学习一系列尝试的第一篇,思路不算清奇,也没有什么特别的难点。但我个人喜欢先抑后扬,不管怎么样先把成果搞出来,然后再慢慢优化和进步嘛。路总是一步一步走的。
后面我打算还是在Web安全这个领域做一些机器学习应用尝试。这篇文章只是静态地提取出异常Payload,而没有利用到关键的Web系统结构信息,包括访问时序的特征,访问来源主体(IP、UID、设备指纹等)、访问分布的特征,我将充分利用这些信息,尝试开发一个无规则化的简易机器学习WAF。
参考链接:
[1]: https://github.com/Monkey-D-Groot/Machine-Learning-on-CSIC-2010
[2]: http://www.freebuf.com/news/142069.html
[3]: http://www.freebuf.com/column/167084.html
*本文原创作者:zhanghaoyil,本文属FreeBuf原创奖励计划,未经许可禁止转载





