吴恩达导师Michael I.Jordan学术演讲:如何有效避开鞍点(视频+PPT)
新智元推荐
来源:大数据文摘
翻译:Iris W、李文浩、龙牧雪 后期:龙牧雪
【新智元导读】最近,加州大学伯克利分校教授Michael I. Jordan(吴恩达的导师)进行了一场演讲:使用合理的扰动参数增强的梯度下降法可有效地逃离鞍点,视频+图文,全是干货。

机器学习中,非凸优化中的一个核心问题是鞍点的逃逸问题。梯度下降法(GD,Gradient Descent)一般可以渐近地逃离鞍点,但是还有一个未解决的问题——效率,即梯度下降法是否可以加速逃离鞍点。
加州大学伯克利分校教授Michael I. Jordan(吴恩达的导师)就此做了研究,即,使用合理的扰动参数增强的梯度下降法可有效地逃离鞍点。在去年旧金山的O'Reilly和Intel AI Conference,他就此研究做了一次演讲。
Michael I. Jordan:如何有效避开鞍点
时长13分钟,带有中文字幕
点击观看👇
暂时无法观看的小伙伴可以下拉看文字版
后台回复“鞍点”获取演讲PPT合集。
很荣幸来到这里。我刚从中国飞回来,大约是昨天午夜时分,我感觉好极了。如果有一个地方人们谈论AI比旧金山还多,那就是中国。这很神奇吧。与之相反,如果我去参加一个理论会议,我会做一个关于系统的演讲,但我更倾向在系统会议演讲中和大家探讨理论研究。我认为拓展视野并意识到所有的问题是非常重要的。

我们处在一个非常经验主义的人工智能和机器学习的时代,比我的职业生涯中的任何时刻都更重视经验。这很好,有很多新的探索,但是我们的理解理论远远落后。所以我在自己的研究中更多地关注这个问题。今天我想给大家讲一些研究结果。Chi Jin主导这项研究,他是我在伯克利的研究生,还有Ronge Ge,Praneeth Netrapalli,Sham Kakade几位学生参与了这个项目。
论文链接:
https://arxiv.org/abs/1703.00887
我要讲的是鞍点,以及如何有效地避开它们。你们都知道局部最小值是我们的克星,所以我一直在讨论这个问题,那就是如何避免局部最小值。但问题并不明显,有很多机器学习的问题没有局部最小值。即使你有局部最小值,梯度下降似乎可以轻松回避它们。神经网络如果足够大的话就会有足够的冗余,要做到这一点并不难。达到零就是全局最优解。这就是你们在实践中看到的。也许这并不是真正的问题。如果一个回路的局部最大值不是问题,它的鞍点是剩下需要解决的。

鞍点在这些体系结构中大量存在,不论是在简单的模型还是在神经网络中。它们会导致学习曲线变平。你会经常看到一个学习曲线下降很快,之后很久都是平的。这就是靠近鞍点的表现。最终你会逃离鞍点。继续下去,你可能会碰到另一个鞍点。你会看到一个学习曲线,它这样上升和下降。某种意义上,这不是问题,如果你最终得到正确答案。但是你可能会碰到一个鞍点并在那里停滞很长一段时间,时间过久,以至于你都不知道在某个地方能找到更好的答案。特别是如果你没有那么多时间来运行你的算法。所以你可以在多维度中理解这个。
让我给你们看一张鞍点的图片。在左边我们有一个“严格”的鞍点。有一个负曲率的方向,这个负曲率是严格小于零的。在右边,它是个非严格鞍点,但第二个特征值严格为零。
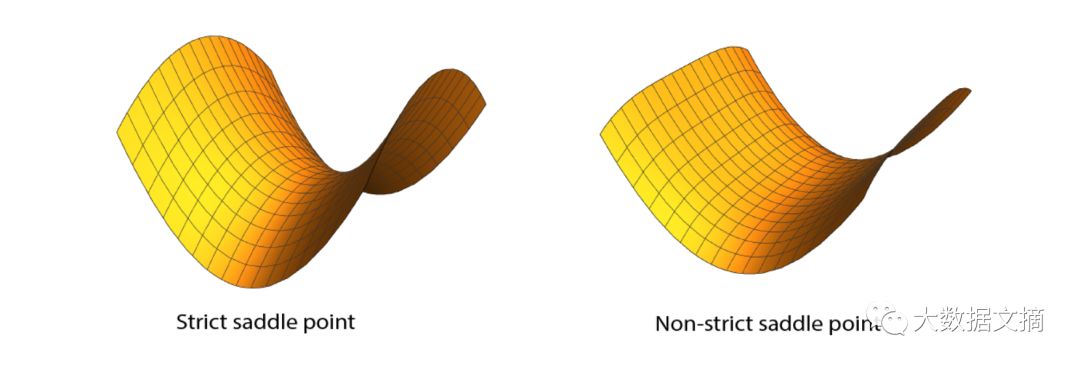
如何逃离鞍点?如果你沿着中间部分往下走,你最终会摆脱它,但这可能需要很长时间。这只是两个维度上,但如果你有上十万甚至上百万维度呢?就像现在一般的研究中一样。在这种情况下,可能只有一条出路,其他的方向都不行,所以要找到逃逸的方向可能要花很长时间。当维度越来越大的时候,就有问题了。基于梯度下降的算法可能会有麻烦。
如果你有一个海森矩阵,这个问题将会消失,因为你会知道所有的方向,但你必须计算一个海森矩阵的特征向量。这两种情况都不好,因为它太复杂了也太慢。所以,梯度方法是个问题。

在这个领域还有很多有待证明的东西,这些是最近的结果。对于连续时间上的梯度流,梯度下降将会逐渐避开鞍点。逐渐(asymptotic)意味着要耗费很长的时间来避开鞍点,特别是在高维情况下。所以你需要考虑这个问题。
梯度下降可以用指数时间来逃离鞍点,这是另一个新结果。我们都喜欢随机评级,因为每次迭代都很简单。有一篇重要的论文证明在多项式时间内你会逃离鞍点,这是最近的工作。多项式级的复杂度是不好的。这对理论学家来说是好事,但这对实际的操作是不利的。所以这是一个开放问题,我们能否证明一个更强的定理,来理解为什么梯度下降通常是好用的。
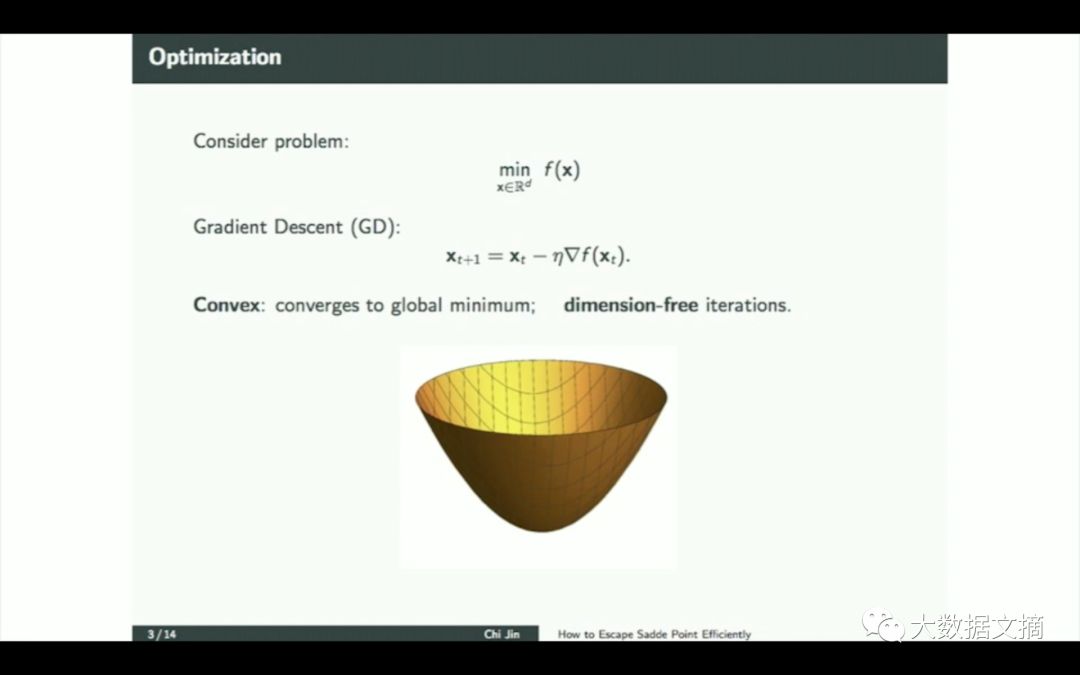
我们来回忆一下梯度下降是什么。现在我们来讨论一个凸问题,是一个类似碗的形状。我们希望寻找f(x)的最小值。这是梯度下降方程。可以证明它是收敛于全局最优解的,以1/k的速率,对于平滑函数。最重要的是,达到最优所需的迭代的次数是独立于维度的。这是一个惊人的数学事实。也许并不是所有人都这样认为,但事实的确如此。这意味着你可以运行无限维度的梯度下降,仍然不会减慢它的速度。计算梯度可能需要与维度数量成正比的时间,但只是线性的在维数中。但这是针对凸问题。
针对一个非凸的例子,我们不讨论最终值。我们将梯度设置为0,你可以证明你会得到一个驻点。但它可以是局部极小值或局部最大值或鞍点。当前最让我们困扰的是鞍点,我们到达和逃脱鞍点的速度。
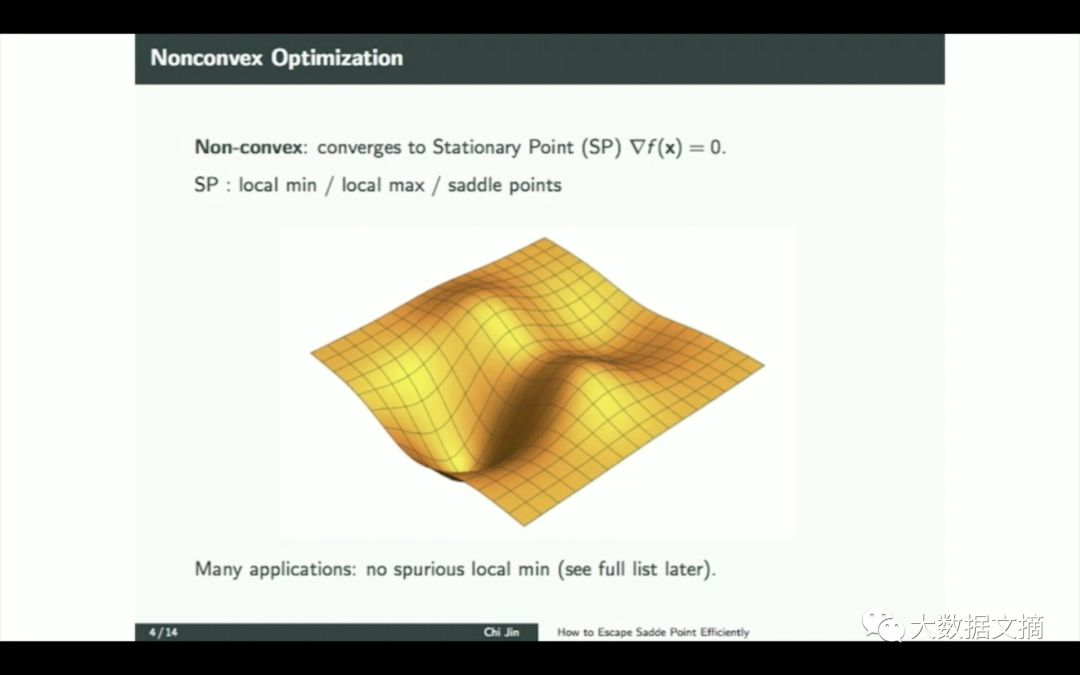
现在最流行深层神经网络,在某种意义上是非凸的。但是实际操作中有很多重要的问题,这些问题都没有虚假的局部最小值,这很好。它们有一个全局最优值。所有的鞍点都是严格鞍。也就是说,你可以漏出,找到一个有负曲率的方向。
所以对于非凸问题,如果我们可以解决基于梯度方法的收敛问题,就是作为鞍点条件的一个函数,你就可以为所有这些问题求得全局的收敛速度,这是我们今天要做的。但是如果你喜欢神经网络,那么你就得注意了。

让我们看下一般非凸性问题。这是Nesterov提出的定理。在一阶驻点,假设我们有一个具有利普希茨梯度的函数。如果你懂些数学知识你会发现,梯度在x1和x2之间变化不大。一阶驻点不意味着梯度完全等于零,而是渐进收敛的,相当于我们在零点周围放了一个半径为埃普西隆的小球。问题是击中那个球需要多长的时间。
对于任意的埃普西隆,这就给了我们一个达到最优值的收敛速度,这个速率是由Nesterov得出的,他证明收敛速度正比于1/e的平方。这是一个很好的速率,它不是非常快但是已经足够好了,但这里的关键在于公式中维度不是必须的,它是独立于维度的,这是梯度下降一个有意思的特性。
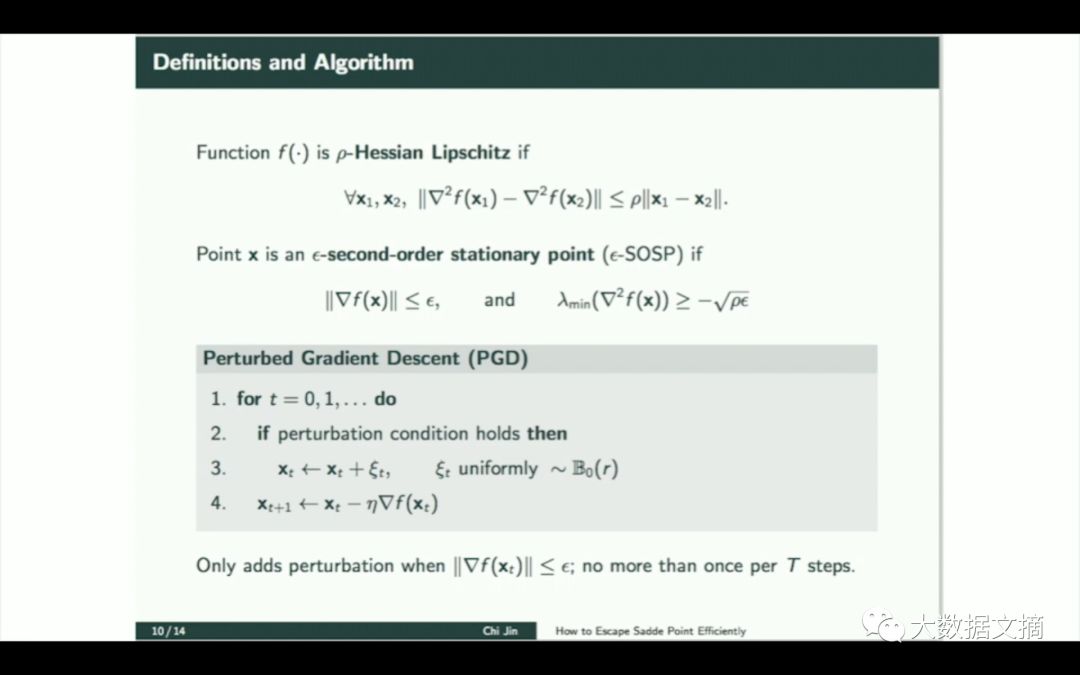
让我们来谈谈这次演讲的主要内容,那么二阶驻点有怎样的性质呢?我们对鞍点尤其感兴趣,但我们同时也很关注局部最小值,我们稍微增加光滑度,可以证明一个定理,我们引入海森-利普希茨性质,很明显二阶驻点是一阶驻点的扩展,这个梯度同样趋近零且不等于零,同时海森矩阵的最小特征值不严格大于等于零。我们给自己放松了一个小区间,从而又得到了一个收敛速度,所以可以看看我们达到二阶驻点速度有多快。这就是我们的算法,我们将其命名为扰动梯度下降。它其实就是一般的梯度下降算法,但是偶尔我们会增加一点随机噪音。
当梯度很小的时候我们会加入噪声。这一步操作频率很低,大概每t个时间步进行一次,t是一个超参数,在这个定理中,我们通过从一个球状区域中随机采样实现噪声的注入,我们也可以做其他分析,但是这里简化了。这不是传统意义上的随机梯度,而是每一步都注入噪声的随机梯度。以上就是我们得出下面定理的背景知识。这个定理非常美妙,所以我认为这个算法也是很值得仔细研究的。

这就是我们的主要成果,即使我设置了这些约束,我们仍然可以得到一个正比于1/e平方的收敛速度,和梯度下降的性能是一样的,维度依赖也被消除了一点。这是一个标准的学术界的小技巧。这和之前梯度下降的性质是一样的,除了这里的大O里有一个跟d相关的因子,但它不是d的多项式,它是对数多项式,是对数的四次方。所以对我来说这给出了一个解释,就是为什么扰动梯度下降算法能高效解决高维问题。维度的对数不算大问题,这是一个很小的数字,你可以通过高速计算机处理它。
这是一个出人意料的结果。我们再来总结一下,这是经典梯度下降算法的研究成果,这是扰动梯度下降的结果,公式是一样的,这里我们没有写出那个关于d的对数的四次方的因子,现在我很怀疑四次方是不是最终的答案,我猜接下来的一两年里会取得新进展,使得对数的阶数降下来,达到一阶对数或者二阶对数,但是现在我们只能证明出对数的4次方这个结果。

这里简要地介绍一下此前的工作,最近的很多研究都是2014年 2015年 2016年做出的,并且到今天依旧十分热门。如果你了解海森矩阵的话,在幻灯片的底部你可以看到一些经典的结果,在小维度问题中,不包括现代机器学习中的神经网络,你可能想要计算海森矩阵,然后计算它的特征向量,它会告诉你脱离的方向,在这种情况下可以达到多快呢,最快速度可以达到1/e的1.5次方,只比埃普西隆的平方好一点点,不是特别好,所以这并不值得,你可以把这个结果先记下来。
在幻灯片顶部,你可以看到一系列引出我们这个结果的工作,Ge et al.证明收敛速度是维度的多项式复杂度,很美妙的结果,改变了我们一直认为指数级是最优结果的看法。Levy后来又将这个结果提升为d的三次方,更加精确,但仍然不是很令人满意,当d达到100或者1000的话这个结果还是不够好。然后我们的工作将它降到了对数级,所以我打算向你们展示,我不会在这里证明它,论文中详细证明了,你们可以去看看论文,对于数学功底很好的人我想说这实际上是一个非常有意思的理论,它运用了概率论,尤其是随机扩散过程,所以实际上包含了一些微分几何的东西,用概率理论证明。
这里我只给你们一个概念,大家都知道鞍点周围有一个饼状区域,如果你进入了这个区域情况就会变得很糟糕,你会被困在里面,你将会在鞍点上停留很长时间,这个时候有一些随机扰动的话就可以把你踢出去,你想确保你不会一而再再而三地陷入困境,这个理论就是关于如何去远离这个饼状区域。
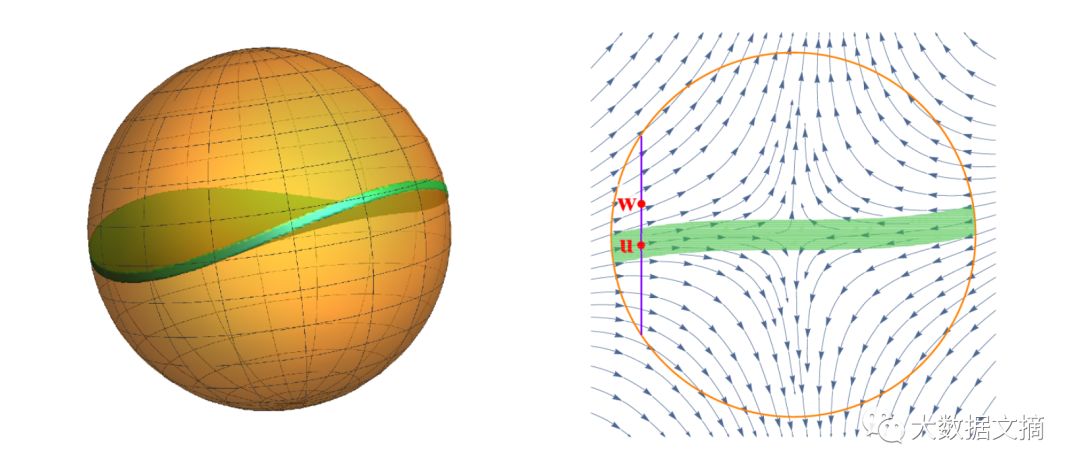
我们都知道饼状区域的存在,并且我们可以分析它,但是为了得到一个更快的收敛速度,人们会用一个更加扁平的饼状区域代替原先的,但扁平化会使得原先的区域变得更广更大,它覆盖了整个原先的饼状区域,但现在变得很大。这就给出了多项式d的三次方的收敛速度,所以你不能这样做,你不能用一个扁平的饼状区域来代替它,你要用真正的饼状区域,但这就涉及到一些很深奥的微分几何,所以我们转而使用扩散过程。
这个过程是指你从两个点开始,这两个点中间的距离正好是饼状区域的宽度,只要这两个点在饼状曲面上位置任意,你会问,他们要多久才能分开,这是一种证明风格,用到了几个内部随机过程参数以及微分几何,所以如果你真的想要去解释这些东西的话,你肯定会用到这些数学知识。传统意义上的应用优化理论还不够,你需要用到高维几何。我们虽然知道这一点,但我认为这是我们想要继续深入所必须的一种观念之一。
我来总结一下,如果我们不知道这个区域的形状应该怎么做。对我们来说,理解它是很重要的,但是我们已经证明了它很薄,我认为还需要进一步的研究,如果我们想把这个对数阶数降到平方或者更低的话,或许我们需要更高深的微分几何知识以及分析,但是我认为想到新的思路不会很困难。

扰动梯度下降,它确实能够脱离鞍点,高效性只是它的一方面,所以这有些振奋人心,你不需要去计算二阶信息,所以我们这种基于梯度的方法是很优秀的。现在我们分析下扰动版本 ,如果你分析随机梯度会怎么样,你们对于加速算法以及诸如此类的算法有什么看法,如果你们希望了解更多的话,这里有一篇博客是我的学生Chi Jin和我在一周之前写的,你可以就此继续研究。非常感谢。
博客链接:
http://www.offconvex.org/2017/07/19/saddle-efficiency/
【2018 新智元 AI 技术峰会倒计时 24天】大会早鸟票已经售罄,现正式进入全额票阶段。
2017 年,作为人工智能领域最具影响力的产业服务平台——新智元成功举办了「新智元开源 · 生态技术峰会」和「2017AIWORLD 世界人工智能大会」。凭借超高活动人气及行业影响力,获得 2017 年度活动行 “年度最具影响力主办方” 奖项。
其中「2017AIWORLD 世界人工智能大会」创人工智能领域活动先河,参会人次超 5000;开场视频在腾讯视频点播量超 100 万;新华网图文直播超 1200 万;
2018年的3月29日,新智元再汇AI之力,共筑产业跃迁之路。 在北京举办2018年中国AI开年盛典——2018新智元AI技术峰会,本次峰会以“产业·跃迁”为主题,特邀诺贝尔奖评委\德国人工智能研究中心创始人兼CEO Wolfgang Wahlster 亲临现场与谷歌、微软、亚马逊、BAT、科大讯飞、京东和华为等企业重量级嘉宾,共同研讨技术变革,助力领域融合发展。
新智元诚挚邀请关心人工智能行业发展的各界人士3月29日亲临峰会现场,共同参与这一跨领域的思维碰撞。
关于大会,请关注新智元微信公众号或访问活动行页面:http://www.huodongxing.com/event/8426451122400
【扫一扫或点击阅读原文抢购大会门票】
2018 新智元 AI 技术峰会购票二维码:

加入社群
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_1 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。
此外,新智元 AI 技术 + 产业领域社群 (智能汽车、机器学习、深度学习、神经网络等) 正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群 共享 AI + 开放平台





