AMiner 联推多个数据集与数据竞赛,助力中国 AI 社区蓬勃发展
数据集是诸多人工智能研究的重要支柱,不仅可以提供训练模型的“燃料”,也能起到评价模型的基准作用。作为训练和测试机器学习模型的资源,它们深深融入 AI 从业者的工作实践中。随着 AI 领域的持续发展,越来越多的优质数据集通过各式各样的数据竞赛在AI社区中流通。
在这方面,过去 5 年来,智谱AI 和 AMiner 团队联合组织了 20 次数据竞赛,并发布了一批大规模、高质量的数据集。比赛总共吸引了超过 1 万人次参与,合作会议和机构包括 KDD Cup、IJCAI Cup、WSDM Cup、CCKS 评测、智源算法大赛、中国人工智能学会、中国中文信息学会、中国工程院和微软等。
这些数据竞赛既覆盖了学术前沿,如图数据攻防、异构图网络;也包括了各类应用,如同名消歧、学者画像;更涉及到对社会有意义的各类任务,如新冠知识图谱构建和疫情趋势预测等。
总的来说,所有的比赛可以归纳为 4 条主线:学术大数据和同名消歧(WhoIsWho)、知识图谱和图神经网络,这也符合,智谱AI 打造数据与知识双轮驱动的人工智能框架,让机器像人一样思考的技术愿景。
(点击
https://www.aminer.cn/competition
或【阅读原文】,即可浏览更多详细的比赛信息)
▼智谱AI& AMiner 已举办的数据竞赛一览:
![]()
![]()
![]()
在学术数据大爆炸的今天,学者数量也随之暴涨。例如,AMiner 中已有大约 1.3 亿名论文作者的档案以及 2 亿多篇论文的信息。所以线上学术搜索系统(例 Google Scholar, Dblp 和 AMiner 等)已成为目前学术界重要的学术交流以及论文搜索平台。然而由于论文分配算法的局限性,现有的学术系统内部存在着大量的论文分配错误;此外,每天都有大量新论文进入系统。故如何准确快速地将论文分配到系统中已有的作者档案以及维护作者档案的一致性,是现学术系统亟待解决的难题,也是确保学术系统中的专家知识搜索有效性、数字图书馆的高质量内容管理以及个性化学术服务的重要前提。
为了弥补同名消歧领域中大规模高质量同名消歧数据集及标准评测任务的空白,WhoIsWho 已标注并发布百万级人工标注的同名消歧数据集,且配套举办了四届竞赛,合作机构包括中国工程院、微软、北京智源人工智能研究院和 IJCAI 2021 学术会议,期间吸引了国内外千余名学者和若干机构参与。2021 年 12 月 26 日,WhoIsWho 再次上线,并计划长期开放,成为同名消歧领域的 benchmark。
WhoIsWho 系列包括两个子任务:
I. 论文的冷启动消歧(Name Disambiguation from Scratch)
任务描述:给定一堆拥有同名作者的论文,要求返回一组论文聚类,使得一个聚类内部的论文都是一个人的,不同聚类间的论文不属于一个人。
参考方法:解决这一问题的常用思路就是通过聚类算法,提取论文特征,定义聚类相似度度量,从而将一堆论文聚成的几类论文,使得聚类内部论文尽可能相似,而类间论文有较大不同,最终可以将每一类论文看成属于同一个人的论文。[7] 是一篇经典的使用聚类方法的论文,它使用了原子聚类的思想,大致思路是首先用较强的规则进行聚类,例如:俩篇论文如果有俩个以上的共同作者,那么这俩篇论文属于同一类,这样可以保证聚类内部的准确率,随后用弱规则将先前的聚类合并,从而提高召回率。有些工作考虑了传统特征的局限性,所以利用了低维语义空间的向量表示方法,通过将论文映射成低维空间的向量表示,从而基于向量使用聚类方法。
II. 论文的增量消歧(Incremental Name Disambiguation)
任务描述:给定一批新增论文以及系统已有的作者档案(论文集),最终目的是把新增论文分配到正确的作者档案中或者返回 NIL(NIL 表示无正确的作者)。
(注:NIL 对应于新进研究者,例如学生等,发表第一篇论文的情况。在该情形下,学术系统中不包含他们的档案,故消歧算法不应该把这些论文分配给任意作者。)
参考方法:增量消歧任务与冷启动消歧的任务不同,它是基于有一定作者档案的基础,对新增论文进行分配。所以,容易直接想到的方法就是将已有的作者档案与新增论文进行比较,提取合作者,单位机构或者会议期刊之间相似度的传统特征,随后利用 svm 之类的传统分类器进行分类。还可以利用基于低维空间的向量表示方法,通过将作者与论文表示成低维向量,使用监督学习方法进行特征提取及模型训练。
![]()
清华大学知识工程实验室从 1996 年成立至今已有25年的历史。实验室多年来聚焦于网络环境下的知识工程,在知识获取、融合和挖掘上取得了很多创新成就。2019 年,为了把 AMiner 技术进一步推广,产生应用的生产力,通过技术转化成立了智谱AI,希望用基于知识和大数据挖掘的技术产生更广泛的应用。
![]()
2017 年,知识工程实验室联合中国工程院知识中心、微软等机构,联合组织了开放学术数据挖掘大赛,要求选手在学者画像信息抽取、兴趣标签预测和未来影响力预测等任务上进行探索。
2021 年,AMiner 与 CCKS 联合组织了学者画像知识图谱评测。比赛数据为搜索学者返回的一组搜索引擎返回的网页,其中包括学者本人相关的网页、同名者的网页和其他不相关的网页。参赛选手需要从这组网页中提取关于这名学者的结构化的信息,如学者主页、性别、教育经历等。
2020 年,在新冠疫情肆虐之时,AMiner 与智谱AI 联合发起了新冠知识图谱构建挑战赛。⽐赛聚焦于医疗(特别是和新冠肺炎相关)的知识图谱技术,比赛数据来自新冠肺炎相关的英文学术论⽂数据,并经过标注。
赛道一任务为:
医学论文实体识别,参赛选⼿需要从中抽取出指定类型的实体(例如疾病、症状、病毒、基因、药物等)。
赛道二任务为:
医学论文关系抽取,参赛选手需要判断论文中的实体之间的语义关系(如致病、治疗、副作⽤等)。
![]()
![]()
如果你是数据挖掘领域的研究者或者算法工程师,那么对“异构图(Heterogenous Graph)”或者“异构信息网络(Heterogenous Information Network)”肯定不会陌生。简单地说,与一般的(同构)图不同,异构图中的点和边分为不同类型,甚至带有不同种类的信息。
异构图在工业界的诸多场景有着广泛的应用,随着图神经网络的兴起,许多异构图神经网络也如雨后春笋般涌现出来。然而令人遗憾的是,异构图往往和目标数据高度耦合,许多工作使用了完全不同的数据集,或者在相同数据集上设定不同。就像同构图有 OGB 一样,异构图也需要一个一决高下的舞台,让不同的工作可以得到公平的比较。
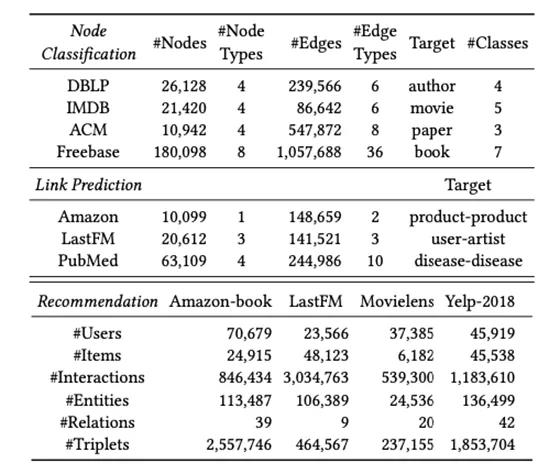
因此,2021 年的清华大学知识工程实验室发表在 KDD 上的论文"Are we really making much progress? Revisiting, benchmarking and refining the Heterogeneous Graph Neural Networks"推出了横跨三大任务 11 个数据集的异构图领域的基准 Heterogenous Graph Benchmark(HGB)和强基线方法 Simple-HGN。
HGB 收集了在 3 个任务上共收集了 11 个中等规模异构图数据集,三个任务分别是节点分类、链接预测、基于知识图谱的推荐,相关数据集的统计信息如图所示:
![]()
为了真正凸显图神经网络结构的影响,排除其他的因素的干扰,HGB 的测评流程中将模型训练分为三个部分:特征预处理、图神经网络、下游任务的解码器和损失函数。文章发现合适的预处理方法或者下游任务解码器对最终结果的影响甚至大于结构的改进本身,因此预设了多种不同的处理方法,研究人员可以在验证集上选取与自己的模型配合最好的预处理和解码器。
![]()
图神经网络相关的技术已经获得了巨大的成功。不过,和其他深度学习技术一样,图神经网络模型也非常容易受到攻击。一个非常类似原数据的对抗样本,可以极大地拉低分类器的性能。2018 年的 KDD 最佳论文就发现极其轻微的扰动就能让节点分类器的准确率大幅下降。在论文引用网络中,可能存在多种类型的对抗攻击。例如,预打印论文网站(如 arxiv)中的论文因为无需同行评议,所以存在很多低质量的引用。另一种是虚假引用(coercive citation)。2019 年,《自然》杂志报道了著名出版商爱思唯尔调查发现数百名研究人员通过操纵同行评议流程,增加自己的论文引用数。
这些对引文网络的攻击不仅会降低公众对科技行业的信任,也会损害对学术数据进行定量分析的努力。因此,智谱AI、AMiner 和数据竞赛平台 biendata 于 2020 年联合 KDD Cup,组织了图数据攻防大赛,希望可以研究如何攻击和防御学术图数据。
比赛数据来自 AMiner 发布的 dblp 引文数据集。已有的图包括 593,486 个节点,每个节点都有一个 100 维的特征。其中 543,486 个节点是训练数据,50,000 个节点是测试数据。参赛队伍需要对组织者提供的图数据进行攻击,并拉低比赛组织者准备的节点分类器的准确率。参赛选手可以添加不超过 500 个新的节点,达到干扰图数据的结果。每个新的节点最多只能有 100 条边。包含了新节点的图将会干扰分类器,降低分类器的性能。如果降低的幅度越大,干扰的效果就越好。
![]()
![]()
科学研究已经成为现代社会创新的主要动力。大量科研数据的积累也让我们可以理解和预测科研发展,并能用来指导未来的研究。论文是人类最前沿知识的媒介,因此如果可以理解论文中的数据,可以极大地扩充计算机理解知识的能力和范围。 在论文中,作者经常会引用其他论文,并对被引论文做出对应描述。如果我们可以自动地理解、识别描述对应的被引论文,不仅可以加深对科研脉络的理解,还能在科研知识图谱、科研自动问答系统和自动摘要系统等领域有所进步。
2020 年,智谱AI 联合 biendata 与 WSDM Cup,共同组织了 DiggScience 比赛,要求选手构建可以理解论文语义的模型,匹配论文和对论文的描述。
![]()
2020 年初,新冠疫情开始蔓延。为了结合基于病原生物学、生物信息学和机器学习的交叉学科对传染病走向预测的研究,测试各类不同技术的最新成果,智谱AI组织了新冠流行趋势预测比赛。
在比赛期间,参赛团队每天都需要提交一份对未来七天中国新增确诊人数和新增治愈人数的预测。排行榜每天都会刷新。