把BERT拉下神坛!ACL论文只靠一个“Not”,就把AI阅读理解骤降到盲猜水平
鱼羊 栗子 发自 凹非寺
量子位 出品 | 公众号 QbitAI
有一篇中选了ACL的论文,打击了以BERT为首的众多阅读理解模型。
研究人员认为,包括BERT在内,许多模型的成功都是建立在虚假的线索上。

团队用了去年诞生的观点推理理解任务 (ARCT) 考验了BERT。
结果发现,只要做个对抗数据集,准确率就从77%降到53%,几乎等同于随机猜。
预告一下,这里的对抗并不是把o变成0、把I变成1的小伎俩。
实验说明,BERT是依靠数据集里“虚假的统计学线索 (Spurious Statistical Cues) ”来推理的。
也就是说,它并不能真正分析出句子之间的逻辑关系。

碎成渣渣
那么,BERT到底是败在了一项怎样的任务上?
观点推理理解任务 (ARCT) ,是Habernal和小伙伴们提出的阅读理解任务,考察的是语言模型的推理能力,中选了NAACL 2018。
一个观点,包含前提 (Premise) ,和主张 (Claim) 。
除此之外,观点又有它的原因 (Reasoning) ,以及它的佐证 (Warrant) 。

在ARCT里面,AI要根据一个给定的观点,在两个选项里,找出正确的佐证。
两个佐证句十分接近,得出的主张却是完全相反。
原始的ARCT数据集里,一共有2000个观点,配以它们的佐证。
原本,BERT在这个数据集上表现优良,77%的最好成绩,只比未经训练的人类 (79.8%) 低不到3个百分点。
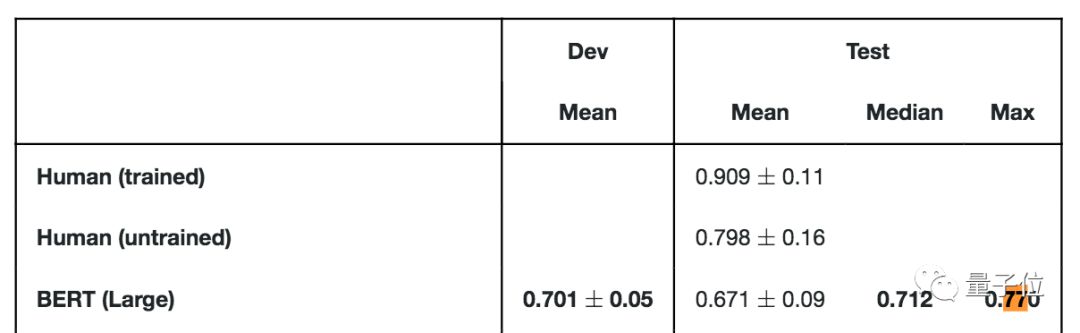
中位数,也在70%以上。
可这样就能说明BERT拥有推理能力了么?
为了研究BERT的选择是如何做出的,团队观察了AI眼中容易分类的那些数据点。
结果发现,BERT是利用了一些线索词来判断,特别是“Not”这个词。
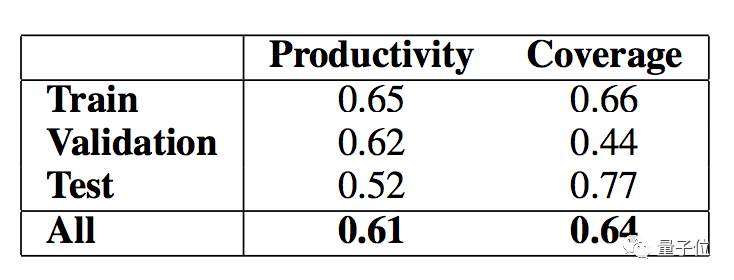
在两个选项里面,如果选择带有“Not”的佐证句,就有61%的概率是对的。
并且,在所有正确答案里,有64%的佐证句都包含了“Not”。
这是最强大的一个线索词,但它和答案之间是虚假关系 (Spurious Relationship) ,并不是在逻辑上相关的。
除此之外,其他的线索词还包括了“Is”“Do”“Are”等等。

为了证明“Not”这样的线索词,对AI的推理真的有影响,团队做了一个对抗数据集。
具体方法是,给观点的主张 (Claim) 加上一个“Not”来否定;
原因 (Reasoning) 不变;
把佐证 (Warrant) 的两个选项,对错标签反过来填。就是把错误答案和正确答案对调。

拿修改过的数据集,再去考BERT。它的成绩就降到了盲猜水平:
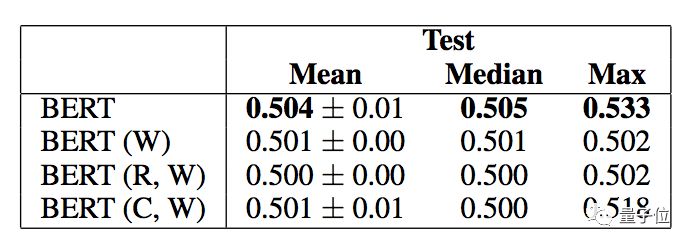
研究人员觉得,将来再评估AI的阅读理解能力,也应该采纳这样的方法,如此才能测出语言模型的推理到底有多鲁棒。
前情:BERT有多神
在NLP领域,没有人不知道BERT的大名。
BERT由谷歌推出,堪称2018年最火的NLP模型,甚至被称为NLP新时代的开端。
甫一亮相,BERT就在11项NLP任务上都取得了最顶尖的成绩,将GLUE基准提升7.6%,将MultiNLI的准确率提升5.6%。
哪怕是在XLNet等后来者的冲击之下,BERT在SQuAD2.0排行榜上仍处于霸榜的地位,前10名中有6位都是BERT的变体。其中第一名BERT + DAE + AoA的表现甚至超过了人类。

“不只一个数据集有问题”
这篇论文的结论给了NLP模型们当胸一击。
BERT的秘密被揭穿,网友们纷纷表示这是非常值得深入探讨的一个议题。
作者本人在Reddit评论区补充说:
我们每隔几个月就会听到有关NLP的新进展,更新、更好的模型层出不穷。但当有人实际用数据集测试时,会发现这些模型并没有真正学习到什么。优化模型的竞赛该放缓脚步了,我们更应该仔细研究研究数据集,看看它们是否真的有意义。

作者还说,他并不否认BERT和其他新模型的价值,但是并不相信一些Benchmark。

有人直接贴出了另一篇ACL论文,说这两项研究得出的结论几乎一毛一样。

https://arxiv.org/abs/1902.01007
只不过,数据集不一样了。
这篇论文里BERT是在多类型语言推理数据集 (MNLI) 上训练的,而测试集则是研究团队自制的HANS数据集:
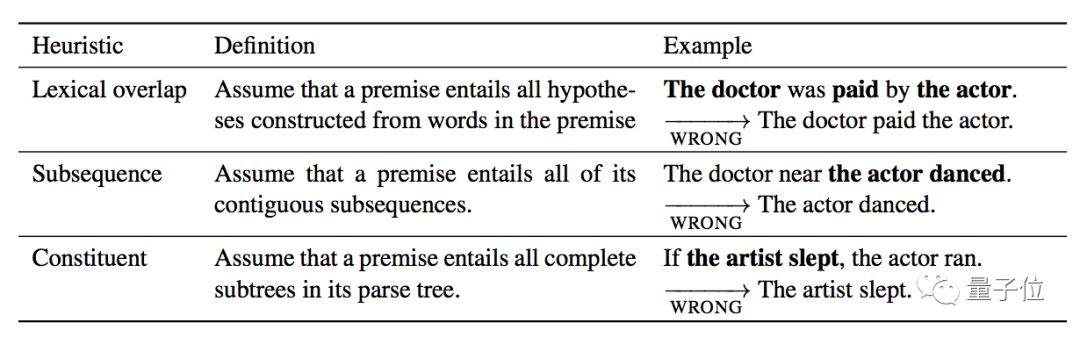
利用一些简单的句子变换,就能让AI做出错误的判断。
于是,BERT在这个新数据集上又扑街了。
也就是说,不止ARCT一个数据集,作为常用基准的MNLI也有类似的缺陷。
不过,也有人对主角论文的结论存疑:
这篇文章提出的观点过于笼统,只讨论了BERT的ARCT性能。
既然论文想说明,那些新的NLP模型通常什么意义都没学明白,就应该对更多基准进行测试。
显然我们用来判断模型表现的基准与人类判断不完全相关,但问题是目前并没有更好的判断标准。

传送门
论文地址:https://arxiv.org/abs/1907.07355
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
近期精选阅读



AI社群 | 与优秀的人交流


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧



