从上到下|图网络开放数据集


从上到下|图网络开放数据集
很多学者和机构发布了许多与图相关的任务,以测试各种GNN的性能。这些任务一般都会提供数据集。
按照任务分类,可以把数据集分成以下几类:
-
引文网络 -
生化图 -
社交网络 -
知识图谱 -
开源数据集仓库
参考资料:
-
A Comprehensive Survey on Graph Neural Networks -
Introduction to Graph Neural Networks
引文网络
Pubmed/Cora/Citeseer
引文网络,节点为论文、边为论文间的引用关系。这三个数据集通常用于链路预测或节点分类。
这三个数据集均来自于:
《Collective classification in network data》
下载链接可从以下网址找到:
https://linqs.soe.ucsc.edu/data
DBLP
DBLP是大型的计算机类文献索引库。原始的DBLP只是XML格式,清华唐杰教授的一篇论文将其进行处理并获得引文网络数据集。到目前为止已经发展到了第12个版本。
DBLP引用网络论文:
《ArnetMiner: Extraction and Mining of Academic Social Networks》
-
原始数据可以从这里获得:
https://dblp.uni-trier.de/xml/
-
如果是想找处理过的DBLP引文网络数据集,可以从这里获得:
https://www.aminer.cn/citation
| 数据集 | 节点数 | 边数 | 特征 | 标签 |
|---|---|---|---|---|
| Cora | 2,708 | 5,429 | 1,433 | 7 |
| Citeseer | 3,327 | 4,732 | 3,703 | 6 |
| Pubmed | 19,717 | 44,338 | 500 | 3 |
| DBLP_v12 | 4,894,081 | 45,564,149 | - | - |
生化图
PPI
蛋白质-蛋白质相互作用(protein-protein interaction, PPI)是指两个或两个以上的蛋白质分子通过非共价键形成 蛋白质复合体(protein complex)的过程。
PPI数据集中共有24张图,其中训练用20张,验证/测试分别2张。
节点最多可以有121种标签(比如蛋白质的一些性质、所处位置等)。每个节点有50个特征,包含定位基因集合、特征基因集合以及免疫特征。
PPI论文:
《Predicting multicellular function through multi-layer tissue networks》
PPI下载链接:
http://snap.stanford.edu/graphsage/ppi.zip
NCI-1
NCI-1是关于化学分子和化合物的数据集,节点代表原子,边代表化学键。NCI-1包含4100个化合物,任务是判断该化合物是否有阻碍癌细胞增长的性质。
NCI-1论文:
《Comparison of descriptor spaces for chemical compound retrieval and classification》
Graph Kernel Datasets提供下载
MUTAG
MUTAG数据集包含188个硝基化合物,任务是判断化合物是芳香族还是杂芳族。
MUTAG论文:
《Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. correlation with molecular orbital energies and hydrophobicity》
Graph Kernel Datasets提供下载
D&D/PROTEIN
D&D在蛋白质数据库的非冗余子集中抽取了了1178个高分辨率蛋白质,使用简单的特征,如二次结构含量、氨基酸倾向、表面性质和配体;其中节点是氨基酸,如果两个节点之间的距离少于6埃(Angstroms),则用一条边连接。
PROTEIN则是另一个蛋白质网络。任务是判断这类分子是否酶类。
D&D论文:
《Distinguishing enzyme structures from non-enzymes without alignments》
D&D下载链接:
https://github.com/snap-stanford/GraphRNN/tree/master/dataset/DD
PROTEIN论文:
《Protein function prediction via graph kernels》
Graph Kernel Datasets提供下载
PTC
PTC全称是预测毒理学挑战,用来发展先进的SAR技术预测毒理学模型。这个数据集包含了针对啮齿动物的致癌性标记的化合物。
根据实验的啮齿动物种类,一共有4个数据集:
-
PTC_FM(雌性小鼠) -
PTC_FR(雌性大鼠) -
PTC_MM(雄性小鼠) -
PTC_MR(雄性大鼠)
PTC论文:
《Statistical evaluation of the predictive toxicology challenge 2000-2001》
Graph Kernel Datasets提供下载
QM9
这个数据集有133,885个有机分子,包含几何、能量、电子等13个特征,最多有9个非氢原子(重原子)。来自GDB-17数据库。
QM9论文:
《Quantum chemistry structures and properties of 134 kilo molecules》
QM9下载链接:
http://quantum-machine.org/datasets/
Alchemy
Alchemy包含119,487个有机分子,其有12个量子力学特征(quantum mechanical properties),最多14个重原子(heavy atoms),从GDB MedChem数据库中取样。扩展了现有分子数据集多样性和容量。
Alchemy论文:
《Alchemy: A quantum chemistry dataset for benchmarking ai models》
Alchemy下载链接:
https://alchemy.tencent.com/
| 数据集 | 图数 | 节点数 | 边数 | 特征 | 标签 |
|---|---|---|---|---|---|
| PPI | 24 | 56,944 | 818,716 | 50 | 121 |
| NCI-1 | 4110 | 29.87 | 32.30 | 37 | 2 |
| MUTAG | 188 | 17.93 | 19.79 | 7 | 2 |
| D&D | 1178 | 284.31 | 715.65 | 82 | 2 |
| PROTEIN | 1,113 | 39.06 | 72.81 | 4 | 2 |
| PTC_MR | 344 | 14.29 | 14.69 | - | 2 |
| QM9 | 133,885 | - | - | - | - |
| Alchemy | 119,487 | - | - | - | - |
社交网络
Reddit数据集是由来自Reddit论坛的帖子组成,如果两个帖子被同一人评论,那么在构图的时候,就认为这两个帖子是相关联的,标签是每个帖子对应的社区分类。
Reddit论文:
《Inductive representation learning on large graphs》
Reddit下载链接:
https://github.com/linanqiu/reddit-dataset
BlogCatalog
BlogCatalog数据集是一个社会关系网络,图是由博主及其社会关系(比如好友)组成,标签是博主的兴趣爱好。
BlogCatalog论文:
《Relational learning via latent social dimensions》
BlogCatalog下载链接:
http://socialcomputing.asu.edu/datasets/BlogCatalog
| 数据集 | 节点数 | 边数 | 特征 | 标签 |
|---|---|---|---|---|
| 232965 | 11606919 | 602 | 41 | |
| BlogCatalog | 10312 | 333983 | - | 39 |
知识图谱
FB13/FB15K/FB15K237
这三个数据集是Freebase的子集。其中:
-
FB13:包含13种关系、75043个实体。 -
FB15K:包含1345种关系、14951个实体 -
FB15K237:包含237种关系、14951个实体
如果希望找到entity id对应的实体数据,可以通过以下渠道(并不是所有的实体都能找到):
-
https://developers.google.com/freebase/#freebase-wikidata-mappings -
http://sameas.org/
WN11/WN18/WN18RR
这三个是WordNet的子集:
-
WN11:包含11种关系、38696个实体 -
WN18:包含18种关系、40943个实体 -
WN18RR:包含11种关系、40943个实体
为了避免在评估模型时出现inverse relation test leakage,建议使用FB15K237/WN18RR 来替代FB15K/WN18。更多建议阅读《Convolutional 2D Knowledge Graph Embeddings》
FB15K/WN8论文:
《Translating Embeddings for Modeling Multi-relational Data》
FB13/WN11论文:
《Reasoning With Neural Tensor Networks for Knowledge Base Completion》
WN18RR论文:
《Convolutional 2D Knowledge Graph Embeddings》
以上6个知识图谱数据集均可从这里下载:
https://github.com/thunlp/OpenKE/tree/master/benchmarks
| 数据集 | 关系 | 实体数 |
|---|---|---|
| FB13 | 13 | 75043 |
| FB15K | 1345 | 14951 |
| FB15K237 | 237 | 14951 |
| WN11 | 11 | 38696 |
| WN18 | 18 | 40943 |
| WN18RR | 11 | 40943 |
开源的数据仓库
Network Repository
具有交互式可视化和挖掘工具的图数据仓库。具有以下特点:
-
用表格的形式展示每一个图数据集的节点数、遍数、平均度数、最大度数等。 -
可视化对比图数据集之间的参数。 -
在线GraphVis,可视化图结构和详细参数。
链接:
http://networkrepository.com
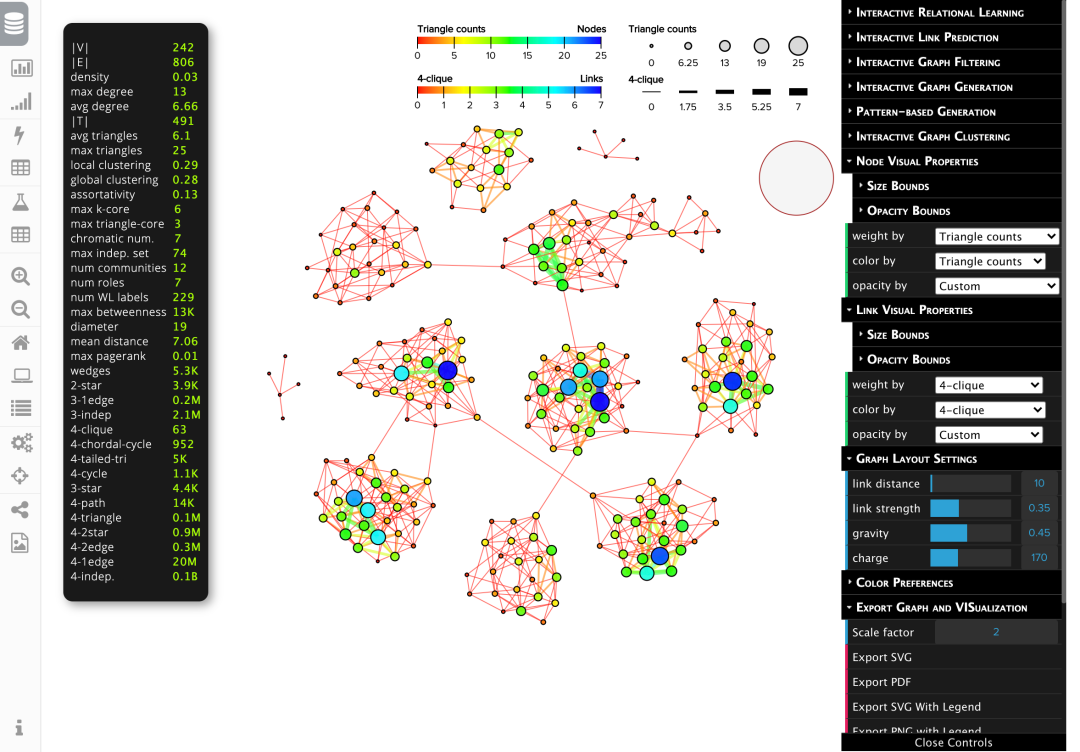
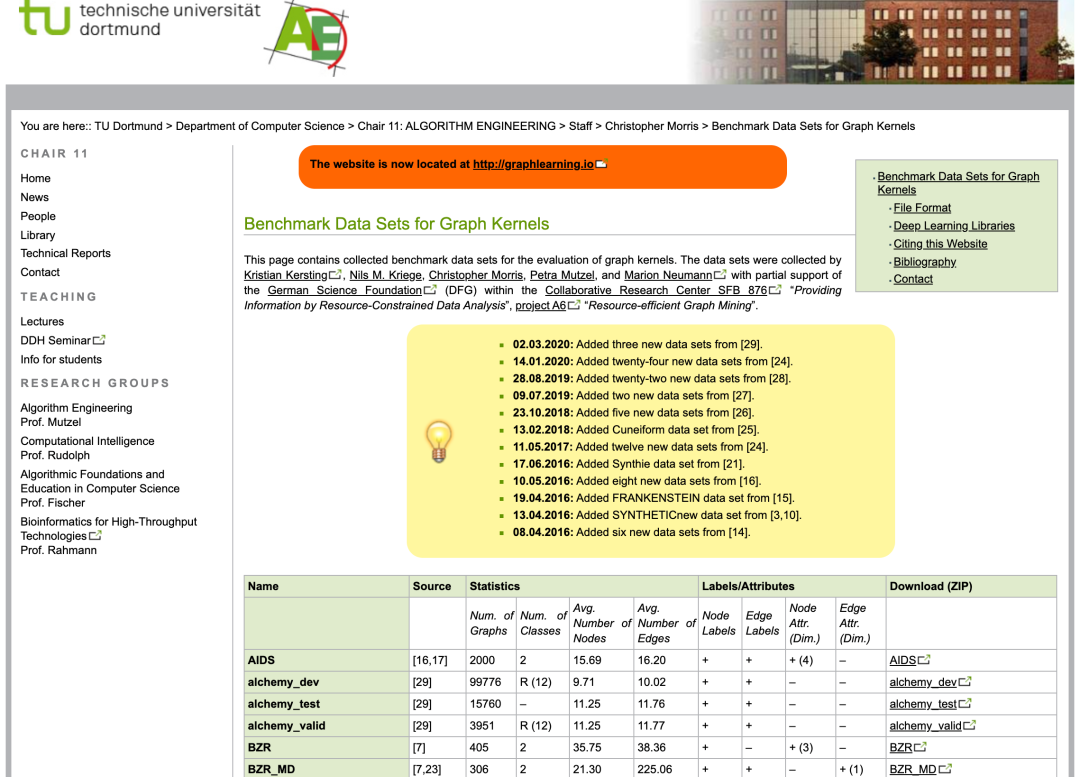
Graph Kernel Datasets
图核的基准数据集。提供了一个表格,可以快速得到每个数据集的节点数量、类别数量、是否有节点/边标签、节点/边特征。
链接:
https://ls11-www.cs.tu-dortmund.de/staff/morris/graphkerneldatasets
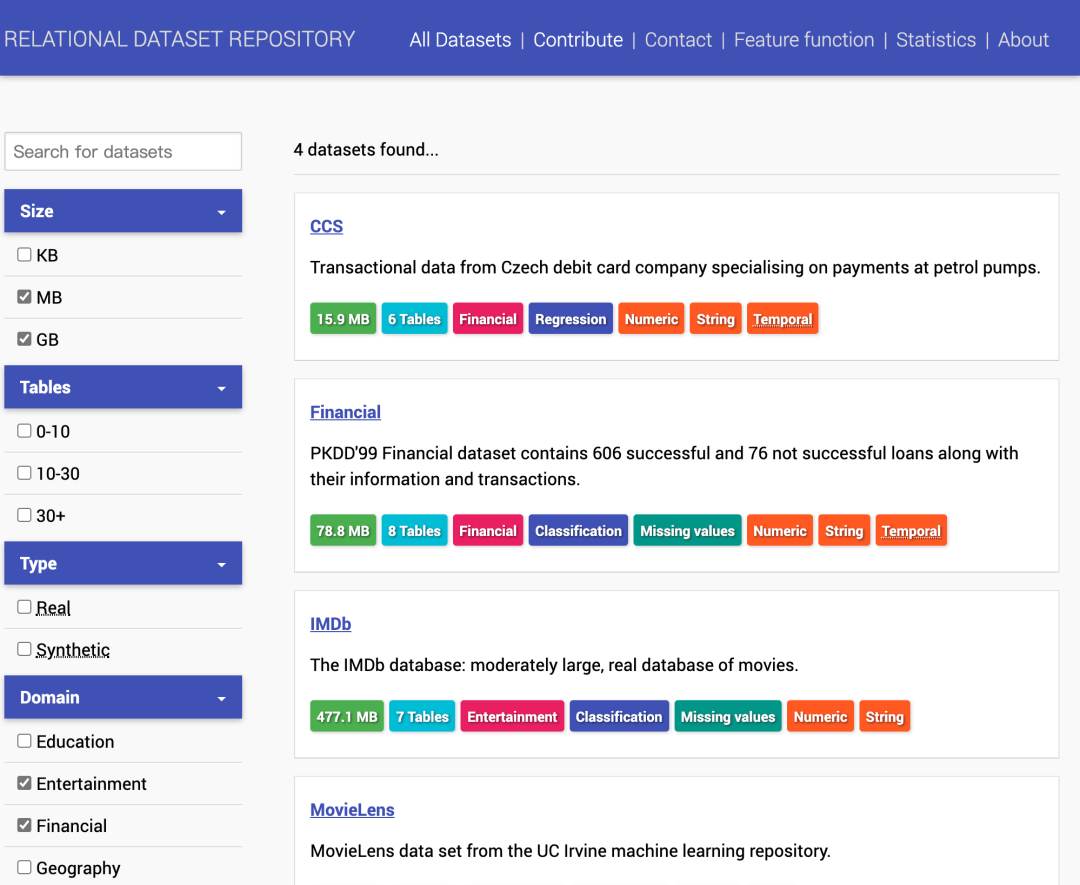
Relational Dataset Repository
关系机器学习的数据集集合。能够以数据集大小、领域、数据类型等条件来检索数据集。
链接:
https://relational.fit.cvut.cz
Stanford Large Network Dataset Collection
SNAP库包含了一个大型图网络数据集集合,拥有大型社交、信息网络。包括:图分类数据库、社交网络、引用网络、亚马逊网络等等,非常丰富。
链接:
https://snap.stanford.edu/data/

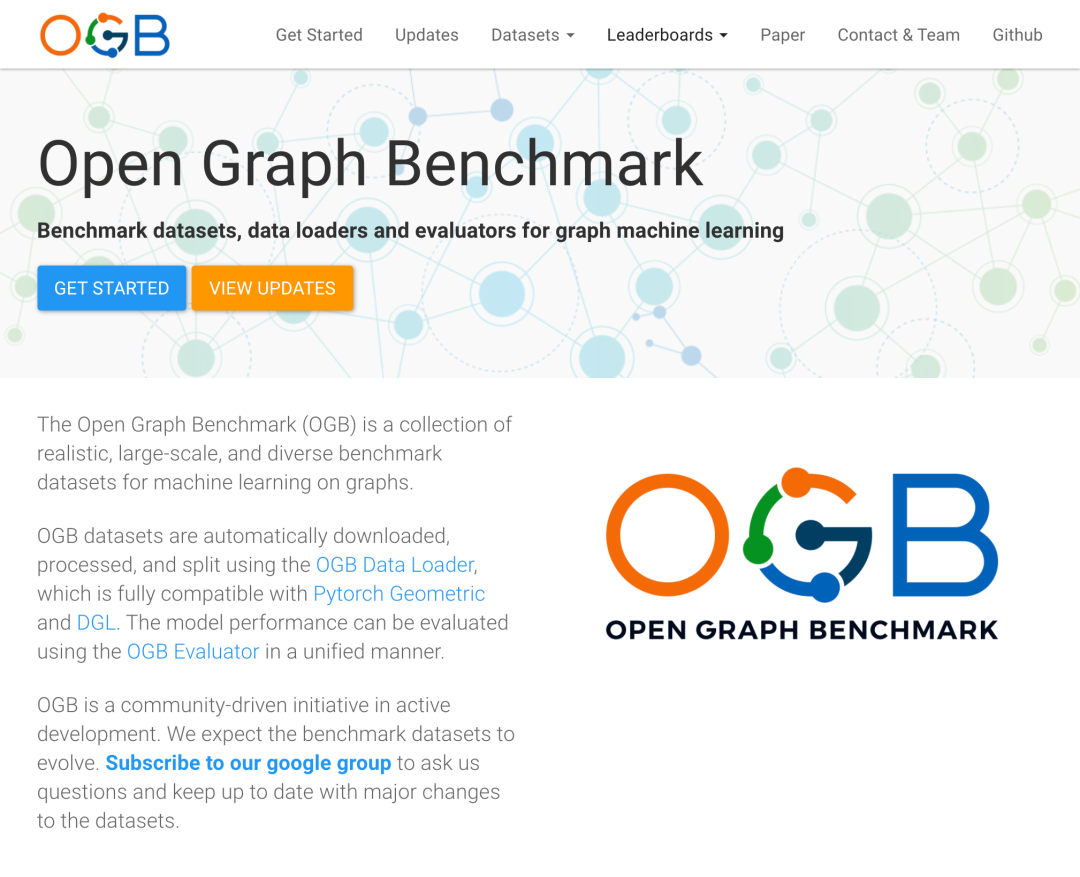
Open Graph Benchmark
OGB是真实基准数据集的集合,同时提供数据加载器和评估器(PyTorch)。可以自动下载、处理和切割;完全兼容PyG和DGL。
链接:
https://ogb.stanford.edu/
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




