BAT机器学习面试题101~105(文末有福利)

101.深度学习(CNN RNN Attention)解决大规模文本分类问题
https://zhuanlan.zhihu.com/p/25928551
102.如何解决RNN梯度爆炸和弥散的问题的?
本题解析来源:http://blog.csdn.net/han_xiaoyang/article/details/51932536
为了解决梯度爆炸问题,Thomas Mikolov首先提出了一个简单的启发性的解决方案,就是当梯度大于一定阈值的的时候,将它截断为一个较小的数。具体如算法1所述:
算法:当梯度爆炸时截断梯度(伪代码)
g^←∂E∂W
if
下图可视化了梯度截断的效果。它展示了一个小的rnn(其中W为权值矩阵,b为bias项)的决策面。这个模型是一个一小段时间的rnn单元组成;实心箭头表明每步梯度下降的训练过程。当梯度下降过程中,模型的目标函数取得了较高的误差时,梯度将被送到远离决策面的位置。截断模型产生了一个虚线,它将误差梯度拉回到离原始梯度接近的位置。
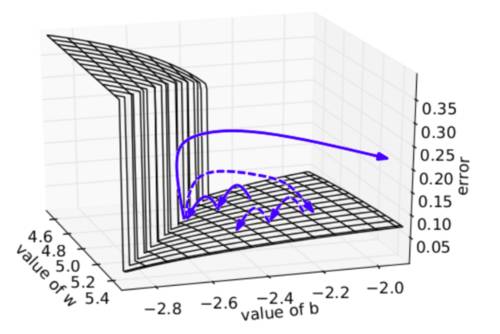
为了解决梯度弥散的问题,我们介绍了两种方法。第一种方法是将随机初始化
103.如何提高深度学习的性能
http://blog.csdn.net/han_xiaoyang/article/details/52654879
104.RNN、LSTM、GRU区别
@我愛大泡泡,本题解析来源:http://blog.csdn.net/woaidapaopao/article/details/77806273
RNN引入了循环的概念,但是在实际过程中却出现了初始信息随时间消失的问题,即长期依赖(Long-Term Dependencies)问题,所以引入了LSTM。
LSTM:因为LSTM有进有出且当前的cell informaton是通过input gate控制之后叠加的,RNN是叠乘,因此LSTM可以防止梯度消失或者爆炸的变化是关键,下图非常明确适合记忆:
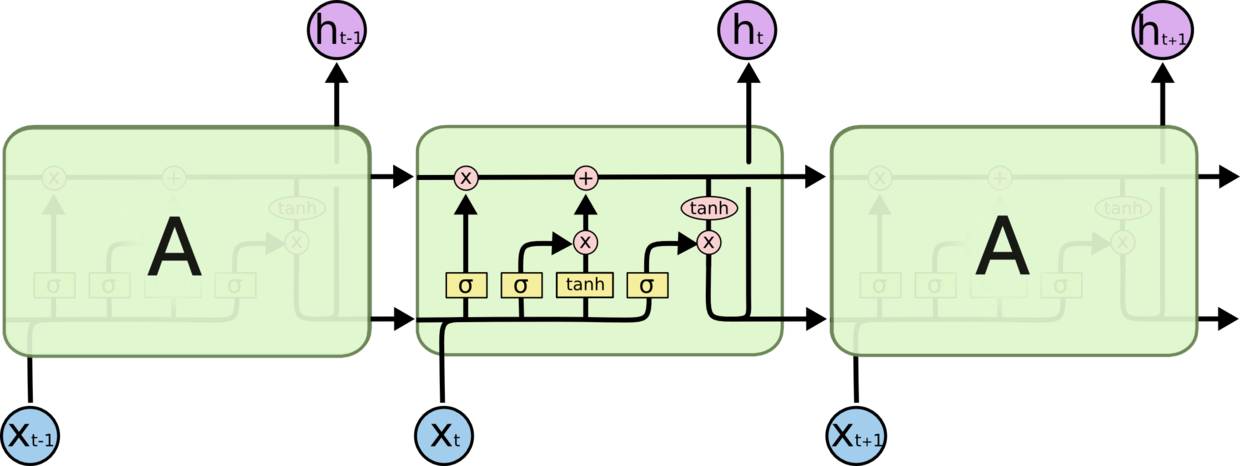
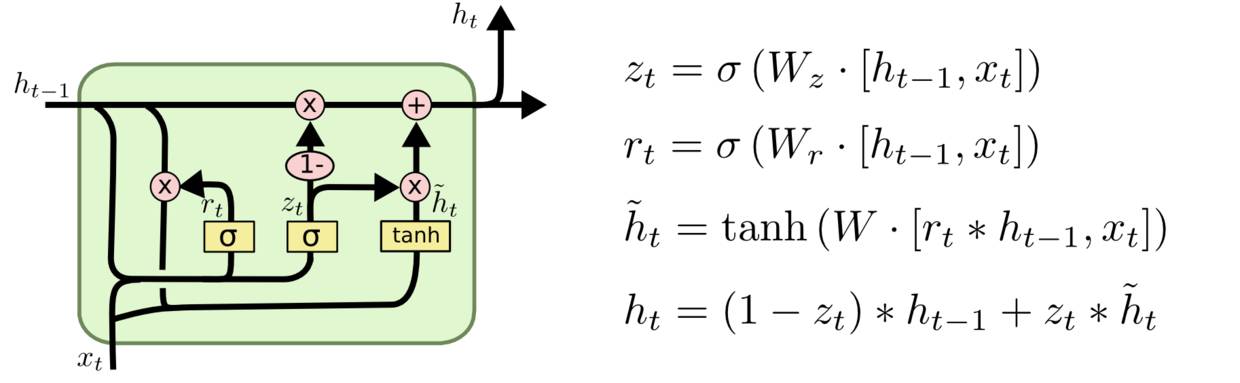
本期思考题:
105.当机器学习性能遭遇瓶颈时,你会如何优化的?
在评论区留言,一起交流探讨,让更多小伙伴受益。
参考答案在明天公众号上公布,敬请关注!
往期题目:


课程咨询|微信:julyedukefu
七月热线:010-82712840




