陈丹琦新作:关系抽取新SOTA,用pipeline方式挫败joint模型
转载机器之心
端到端关系抽取涉及两个子任务:命名实体识别和关系抽取。近期研究多采用 joint 方式建模两个子任务,而陈丹琦等人新研究提出一种简单高效的 pipeline 方法,在多个基准上获得了新的 SOTA 结果。

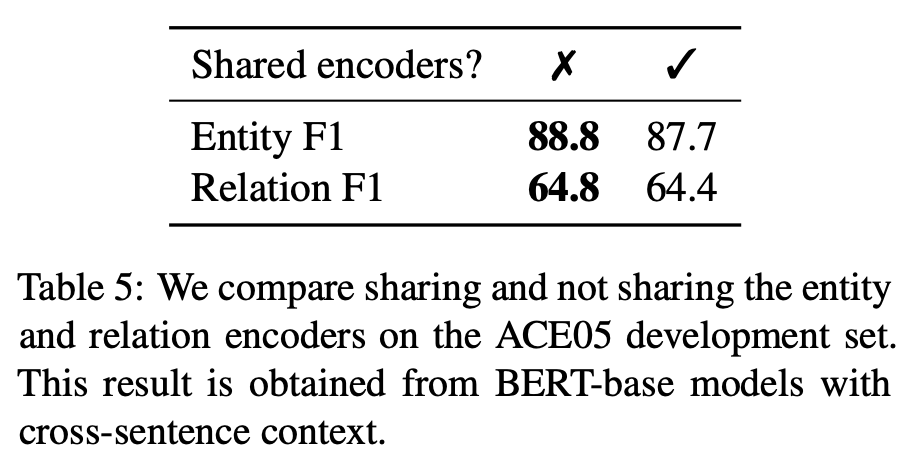
实体模型和关系模型的语境表示本质上捕获了不同的信息,因此共享其表示会损害性能;
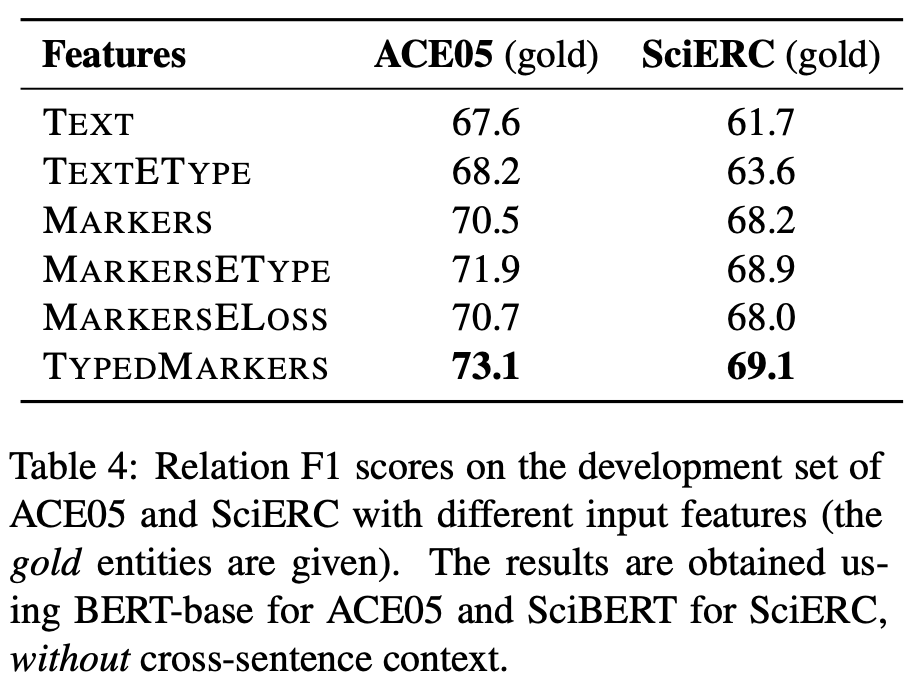
在关系模型的输入层融合实体信息(边界和类型)至关重要;
在两个子任务中利用跨句(cross-sentence)信息是有效的;
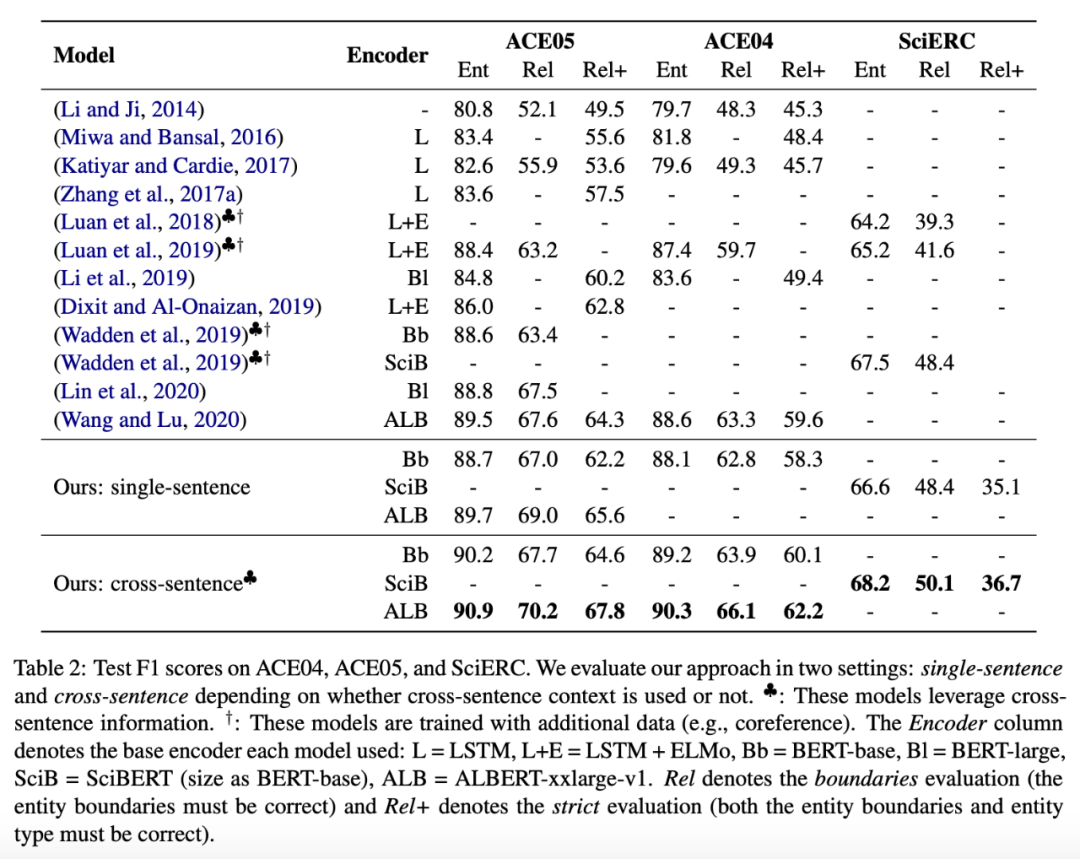
更强大的预训练语言模型能够带来更多的性能收益。
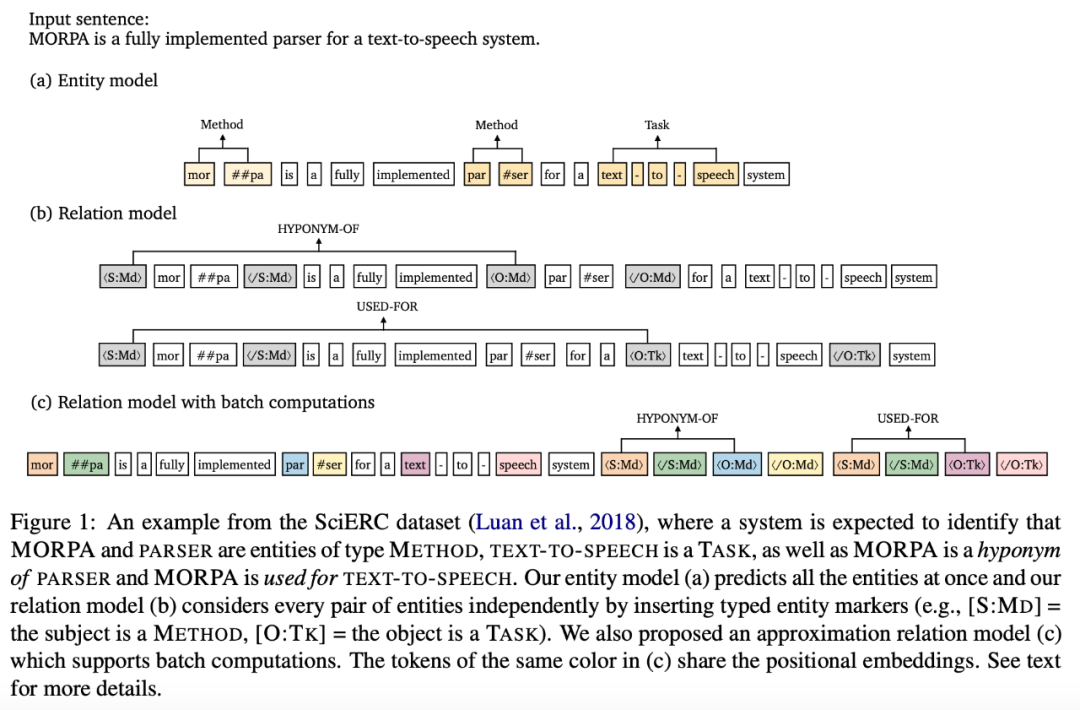
提出了一种非常简单有效的端到端关系抽取方法,该方法学习两个独立编码器,分别用于实体识别和关系抽取的。该模型在三个标准基准上达到了新 SOTA,并在使用相同的预训练模型的时,性能超越了此前所有 joint 模型。
该研究经过分析得出结论:对于实体和关系而言,相比于联合学习,学习不同的语境表示更加有效。
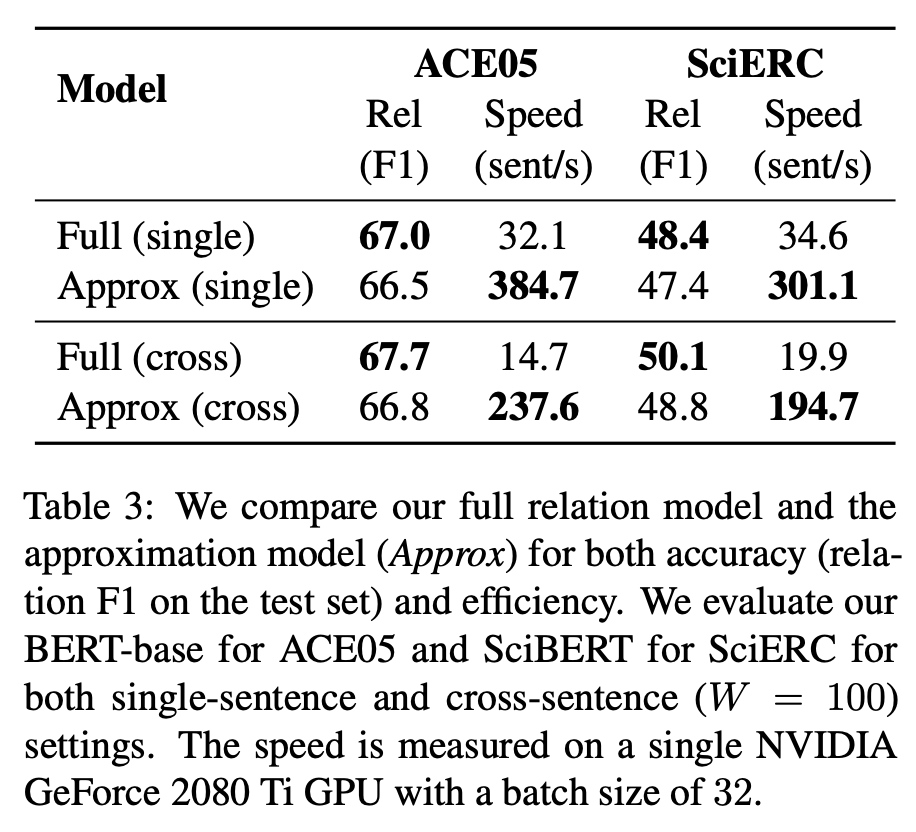
为了加快模型推断速度,该研究提出了一种新颖而有效的近似方法,该方法可实现 8-16 倍的推断加速,而准确率只有很小的降低。
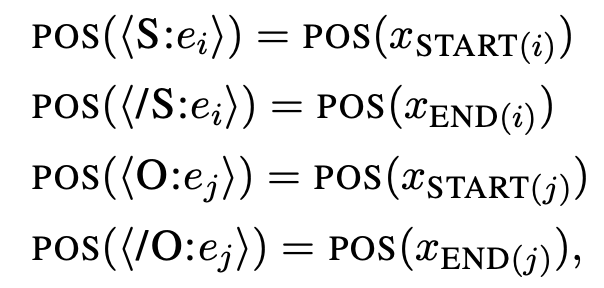
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“REP” 可以获取《陈丹琦新作:关系抽取新SOTA,用pipeline方式挫败joint模型》专知下载链接索引



登录查看更多
相关内容

Arxiv
16+阅读 · 2019年4月3日
Arxiv
10+阅读 · 2018年1月30日
Arxiv
16+阅读 · 2017年11月20日




相关VIP内容
相关资讯
相关论文
Arxiv
16+阅读 · 2019年4月3日
Arxiv
10+阅读 · 2018年1月30日
Arxiv
16+阅读 · 2017年11月20日