【CMU博士论文】信息检索中的神经匹配和重要性学习,163页pdf
本篇推荐来自CMU-LTI的小姐姐Zhuyun Dai博士论文《Neural Matching and Importance Learning in Information Retrieval》,是信息检索领域值得关注的最新工作。

作者介绍:

Zhuyun Dai
卡内基梅隆大学语言技术学院(LTI)的博士生。研究方向是提升当今信息检索系统的语言理解能力,构建下一代信息助理系统,帮助人们无缝地获取世界上的知识。
http://www.cs.cmu.edu/~zhuyund/index.html
信息检索中的神经匹配与重要性学习

地址:https://www.cs.cmu.edu/~zhuyund/zhuyundai_defense.pdf
在50-60年的时间里,信息检索(IR)系统依赖于词汇袋方法。尽管词包检索有一些长期存在的限制,但解决这些问题的尝试大多是不成功的。最近,神经网络为自然语言建模提供了一种新的范式。这篇论文的目的是结合IR的观点和神经网络的关键优势,以带来更深入的语言理解IR。
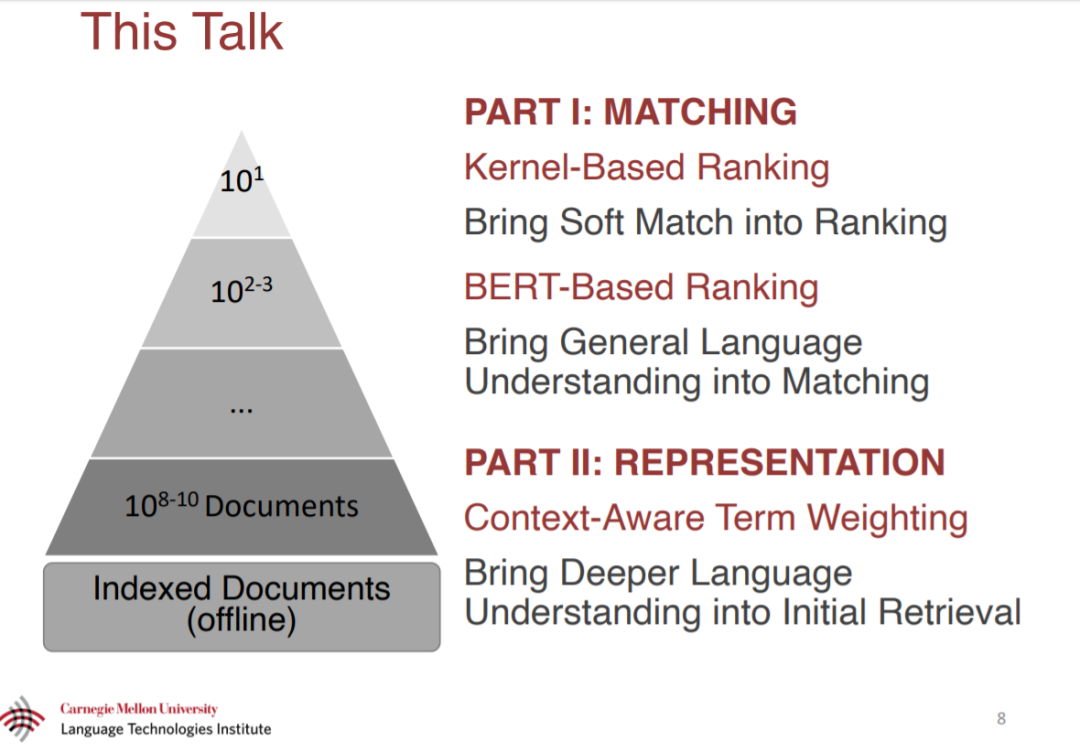
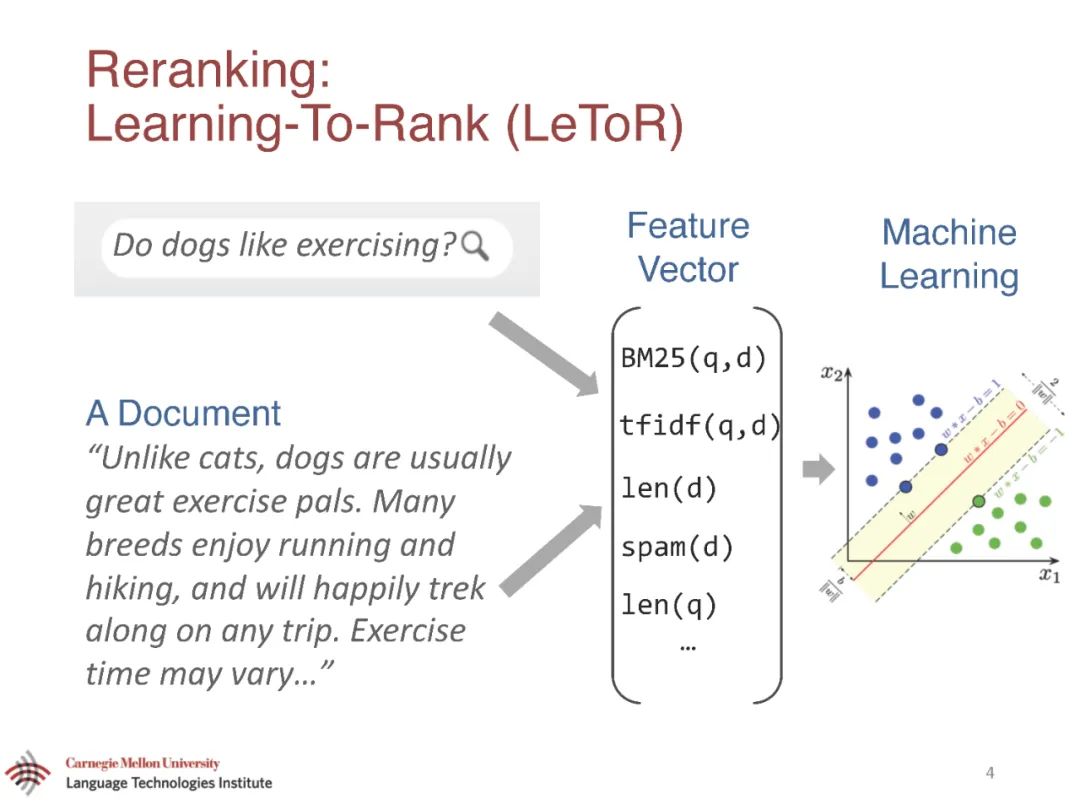
本论文的第一部分主要研究如何匹配查询和文档。最先进的排序器以前依赖于精确的词汇匹配,这导致了众所周知的词汇不匹配问题。本文开发了将软匹配引入相关性排序的神经模型。利用分布式文本表示,我们的模型可以对每个查询词和每个文档词进行软匹配。由于软匹配信号有噪声,本文提出了一种新的核池技术,该技术根据软匹配对相关性的贡献对软匹配进行分组。本文还研究了预训练好的模型参数是否可以改善低资源域,以及模型架构在非文本检索任务中是否可重用。我们的方法比以前最先进的排名系统有很大的优势。
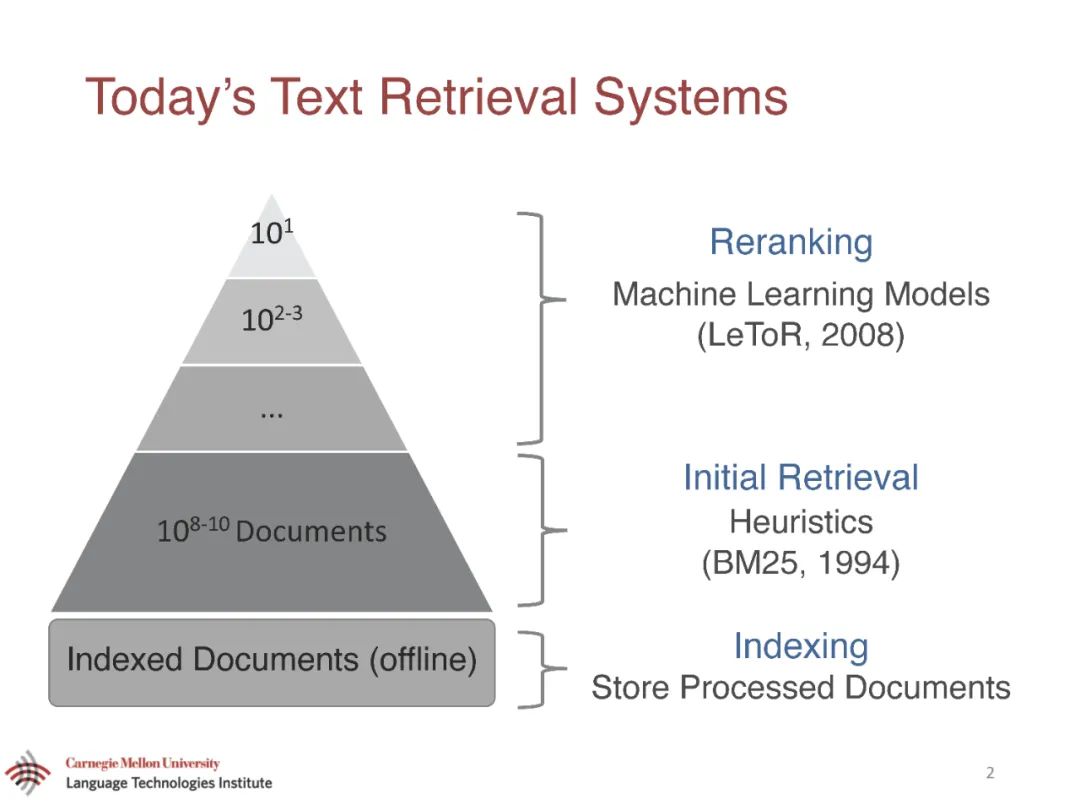
本论文的第二部分主要研究如何表示查询和文档。一个典型的搜索引擎使用频率统计来确定单词的权重,但是频繁的单词对文本的意义不一定是必要的。本论文开发的神经网络,以估计词的重要性,基于如何相互作用的语言语境。开发了一种弱监督方法,允许在没有任何人工注释的情况下训练我们的模型。我们的模型可以离线运行,在不影响效率的前提下显著提高了第一阶段的检索。
总之,本文提出了一种新的神经检索范式,克服了传统检索模型在匹配和重要性加权方面的局限性。在神经相关性排序、深度检索模型和深度文档理解等方面提出了一些有前景的方法。




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NMIL” 可以获取《CMU博士论文-信息检索中的神经匹配和重要性学习,163页pdf》专知下载链接索引





