社区分享 | TensorFlow 模型优化:模型量化

本文来自社区投稿与征集,作者张益新,Google Developers Expert,雪湖科技算法副总监,目前主攻 3d 激光雷达深度学习解决方案,车规级,低时延。
1. 模型量化需求
为了满足各种 AI 应用对检测精度的要求,深度神经网络结构的宽度、层数、深度以及各类参数等数量急速上升,导致深度学习模型占用了更大的存储空间,需要更长的推理时延,不利于工业化部署;目前的模型都运行在 CPU,GPU,FPGA,ASIC 等四类芯片上,芯片的算力有限;对于边缘设备上的芯片而言,在存储、内存、功耗及时延性方面有许多限制,推理效率尤其重要。
作为通用的深度学习优化的手段之一,模型量化将深度学习模型量化为更小的定点模型和更快的推理速度,而且几乎不会有精度损失,其适用于绝大多数模型和使用场景。此外,模型量化解锁了定点硬件 (Fixed-point hardware) 和下一代硬件加速器的处理能力,能够实现相同时延的网络模型推理功能,硬件价格只有原来的几十分之一,尤其是 FPGA,用硬件电路去实现网络推理功能,时延是各类芯片中最低的。
-
通过模型量化等方式降低云和边缘设备(例如移动设备和 IoT 设备)的延迟时间和推断成本。将优化后的模型部署到边缘设备,这些设备在处理、内存、耗电量、网络连接和模型存储空间方面存在限制。在现有硬件或新的专用加速器上执行模型并进行优化。 -
根据您的任务选择模型和优化工具: 利用现成模型提高性能在很多情况下,预先优化的模型可以提高应用的效率。
2. 模型量化过程
大家都知道模型是有权重 (w) 和偏置 (b) 组成,其中 w,b 都是以 float32 存储的,float32 在计算机中存储时占 32bit,int8 在计算机中存储时占 8bit;模型量化就是用 int8 等更少位数的数据类型来代替 float32 表示模型的权重 (w) 和偏置 (b) 的过程,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。
模型量化以损失推理精度为代价,将网络中连续取值或离散取值的浮点型参数(权重 w 和输入 x)线性映射为定点近似 (int8/uint8) 的离散值,取代原有的 float32 格式数据,同时保持输入输出为浮点型,从而达到减少模型尺寸大小、减少模型内存消耗及加快模型推理速度等目标。定点量化近似表示卷积和反卷积如下图 所示,左边是原始权重 float32 分布,右边是原始权重 float32 经过量化后又反量化后权重分布。
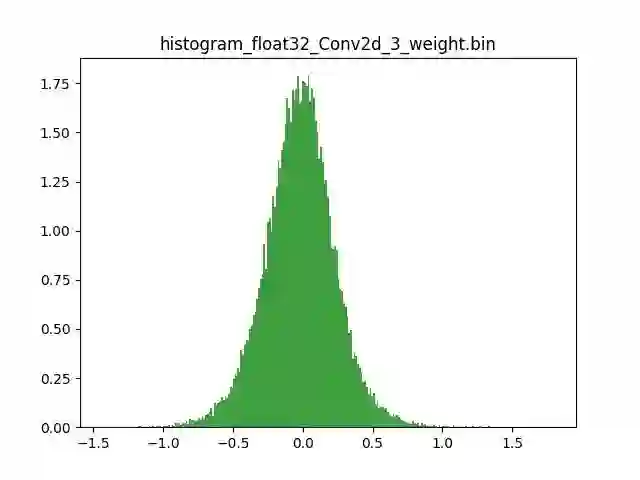
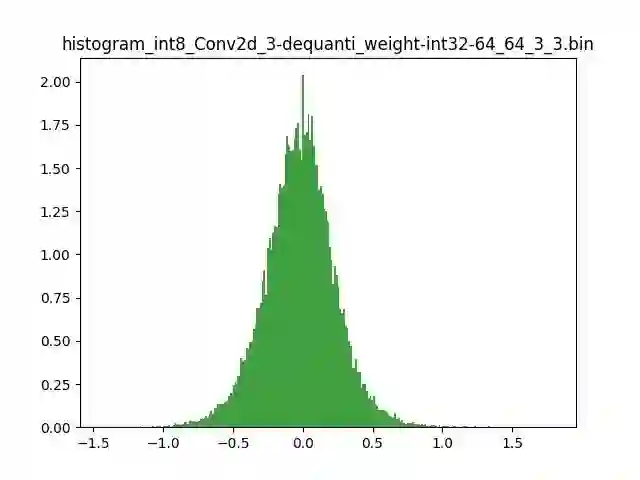
图 2.1 Int8 量化近似表示卷积
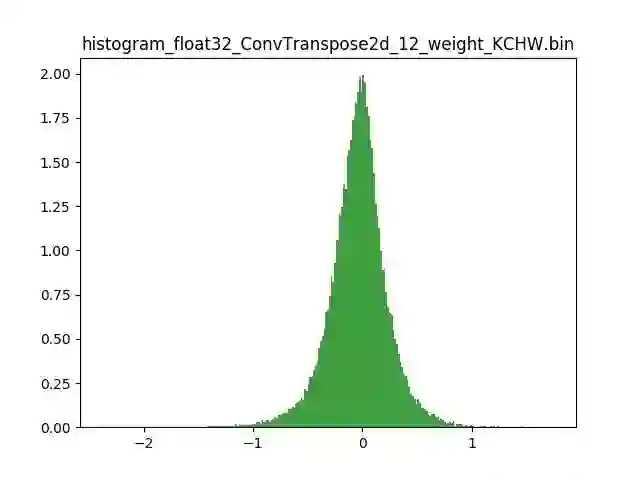
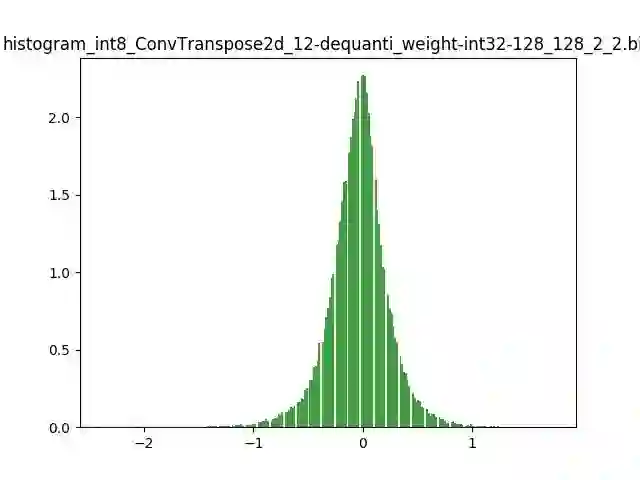
图 2.2 Int8 量化近似表示反卷积
3. 模型量化好处
-
减小模型尺寸,如 8 位整型量化可减少 75% 的模型大小; -
减少存储空间,在边缘侧存储空间不足时更具有意义; -
减少内存耗用,更小的模型大小意味着不需要更多的内存; -
加快推理速度,访问一次 32 位浮点型可以访问四次 int8 整型,整型运算比浮点型运算更快;CPU 用 int8 计算的速度更快 -
减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗; -
支持微处理器,有些微处理器属于 8 位的,低功耗运行浮点运算速度慢,需要进行 8bit 量化。 某些硬件加速器如 DSP/NPU 只支持 int8
4. 模型量化原理
模型前向推理过程中所有的计算都可以简化为 x= w*x +b; x 是输入,也叫作 FeatureMap,w 是权重,b 是偏置;实际过程中 b 对模型的推理结果影响不大,一般丢弃。原本 w,x 是 float32,现在使用 int8 来表示为 qw,qx;模型量化的原理就是定点 (qw qx) 与浮点 (w,x),建立了一种有效的数据映射关系.。不仅仅量化权重 W ,输入 X 也要量化;详解如下:
R 表示真实的浮点值(w 或者 x),𝑸 表示量化后的定点值(qw 或者 qx),Z 表示浮点值定点量化后的量化零点,S 则为浮点值定点量化后的量化尺度。
由浮点到定点的量化公式如下:
𝑸 = R/S + Z
由定点到浮点反量化公式如下:
R = (𝑸 - Z) * S
同时,S 和 Z 的求值公式如下:
S = (Rmax- Rmin)/(𝑸max-𝑸min)
Rmax 表示最大的浮点数 ,Rmin 表示最小的浮点数
𝑸max 表示最大的定点数 ,𝑸min 表示最小的定点数
Z = 𝑸max- Rmax /S = - Rmin /S + 𝑸min
量化后的 𝑸 还是反推求得的浮点值 R,若它们超出各自可表示的最大范围,则需进行截断处理。特别说明:一是浮点值 0 在神经网络里有着举足轻重的意义,比如 padding 就是用的 0,因而必须有精确的整型值来对应浮点值 0。二是以往一般使用 uint8 进行定点量化,而目前有提供 float16 和 int8 等定点量化方法,而 int8 定点量化针对不同的数据有不同的范围定义。深度模型的前向推导通过量化实现 8-bit 版本运算符(包括卷积、矩阵乘、激活函数、下采样和拼接)运行;同时,量化对象包含实数与矩阵乘法等类型。则以激活函数 Relu 为例,传统、实数量化、矩阵乘法量化等三种前向推导流程如图 4 所示。
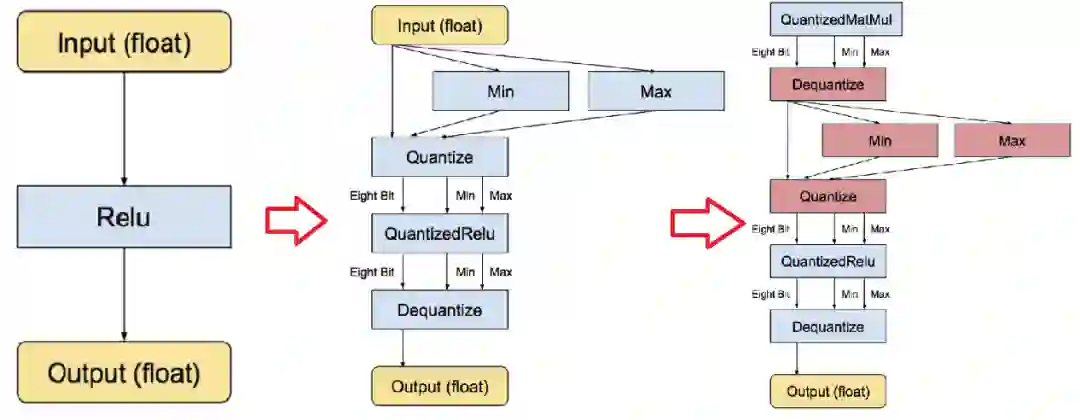
图 4 量化前向推导流程
-
Post-training quantization
https://tensorflow.google.cn/lite/performance/post_training_quantization?hl=zh-cn
Quantization-aware training
https://github.com/tensorflow/tensorflow/tree/r1.13/tensorflow/contrib/quantize
5. TensorFlow 训练后量化
训练后量化,又叫做离线量化,根据量化零点是否为 0;离线量化分为对称量化和非对称量化;根据数据通道顺序 NHWC 上 C 这一维度上区分,离线量化分为逐层量化和逐通道量化;我们看到在 nvidia 的 TensorRT 中使用了逐层量化的方法,每一层采用同一个阈值来进行量化。逐通道量化就是对每一层每个通道都有各自的阈值,对精度可以有一个很好的提升。
对称量化的解释如下:
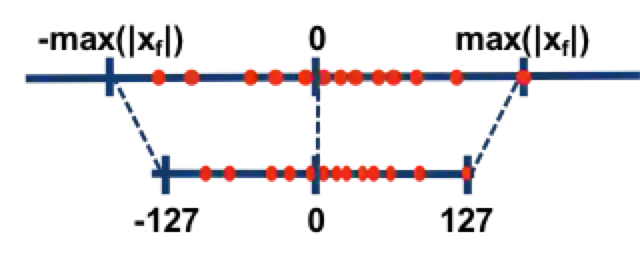
图 5.1 对称量化的解释
简单的将一个 tensor 中的 -max(|X|) 和 max(|X|) FP32 value 映射为 -127 和 127 ,中间值按照线性关系进行映射,称这种映射关系是对称量化。
一般来说,TensorFlow 权重 w 使用对称量化,逐层量化,FeatureMap 也就是 x 使用非对称量化,逐通道量化;这样做的好处是 权重 w 的量化零点为 0 ,可以减少计算次数,起到算法加速的目的,FeatureMap 采用逐通道量化是为了提高精度;量化后模型 int8 表示权重 (w),uint8 表示输入 (FeatureMap, x)。
int8 量化使用以下公式近似表示浮点值:
real_value = (int8_value - zero_point)*scale
-
权重 w 由 int8 的二进制补码值表示的每轴(即每通道)或张量权重,范围为 [-127, 127],量化零点等于 0。 输入 x(FeatureMap) 由 int8 的二进制补码值表示的每个张量激活/输入,范围在 [-128, 127] 中,量化零点在 [-128, 127] 范围内。
TensorFlow 训练后量化是针对已训练好的模型来说的,针对大部分我们已训练未做任何处理的模型来说均可用此方法进行模型量化,而 TensorFlow 提供了一整套完整的模型量化工具,如 TensorFlow Model Optimization Toolkit 以及 TensorFlow Lite converter 等实现了其中的几种方式,加速性能见下表:
| 技术 | 好处 | 硬件 |
|---|---|---|
| 动态范围量化 | 缩小 4 倍,加速 2 倍至 3 倍 | 中央处理器 |
| 全整数量化 | 缩小 4 倍,加速 3 倍以上 | CPU,Edge TPU,微控制器 |
| Float16 量化 | 小 2 倍,GPU 加速 | CPU,GPU |
选择何种方式,需要结合业务场景及所拥有的硬件资源,目的是以最小损失达到最大化模型量化效果,官方提供了一棵决策树用于选择不同的训练后量化方式,实作中可进行参考。训练后量化方式的选择方式如下:
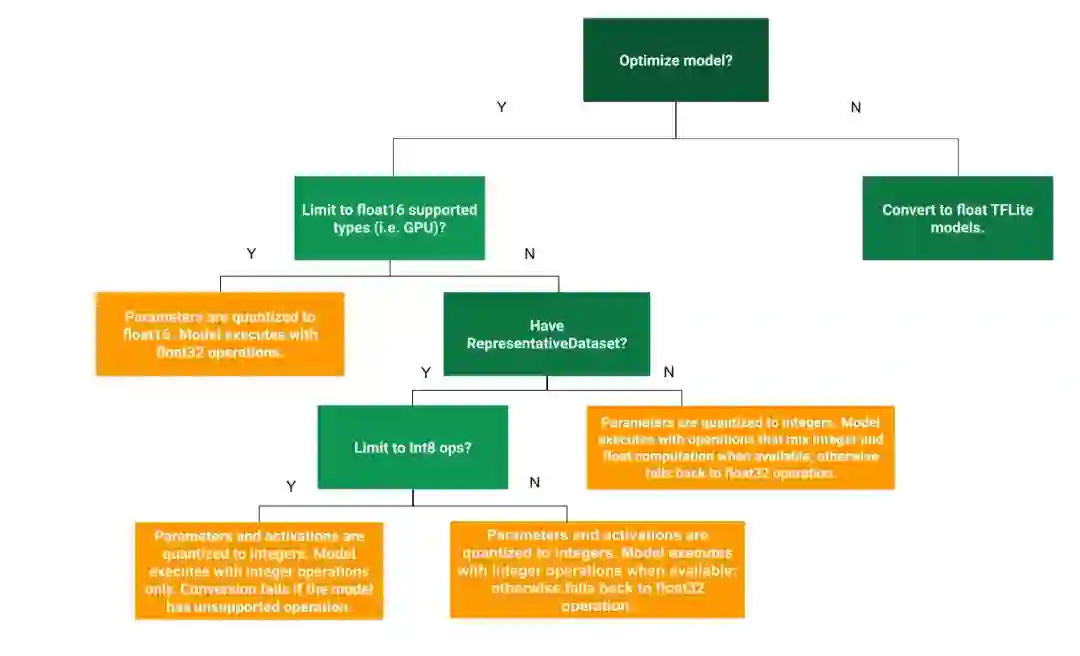
图 5.2 训练后量化方式的选择方式
6. TensorFlow 训练时量化
训练时量化 (Quantization-aware Training),又叫做在线量化,其中包括四个步骤:
-
用常规方法训练一个 TensorFlow 浮点模型。 -
用 tf.contrib.quantize 重写网络以插入Fake-Quant 节点并训练 min/max。 -
用 TensorFlow Lite 工具量化网络,该工具读取步骤 2 训练的 min/max。 用 TensorFlow Lite 部署量化的网络。
-
使用 tf.keras 训练一个浮点模型; -
使用新的 quantization aware training API 在第一步训练的模型上迁移训练; -
使用 tf.lite.TFLiteConverter.from_keras_model 将第二步的模型导出为量化的模型; -
用 TensorFlow Lite 部署量化的模型
quantization aware training API
https://tensorflow.google.cn/model_optimization/guide/quantization/training
此外我们还可以在 Quantization-aware Training 过程中引入乘法变移位法 (Turning Multiplications Into Bit Shifts) 的量化方式,直接将权重 w 量化成二进制位的形式,把所有的权重 w 全部变为 2 的 n 次方或者 2 的负 n 次方,把乘法变成移位运算,加速计算过程,减少资源占用。
训练时量化 (Quantization-aware Training),其中网络的前向 (Forward) 模拟 INT8 计算,反向 (Backward) 仍然是 FP32 。下图左半部分是量化网络,它接收 INT8 输入和权重并生成 INT8 输出。下图右半部分是步骤 2 重写的网络,其中 wt quant/act quant 节点在训练期间将 FP32 张量量化为 INT8,进行截断,产生损失,接下来反量化为FP32,进行反向传播。
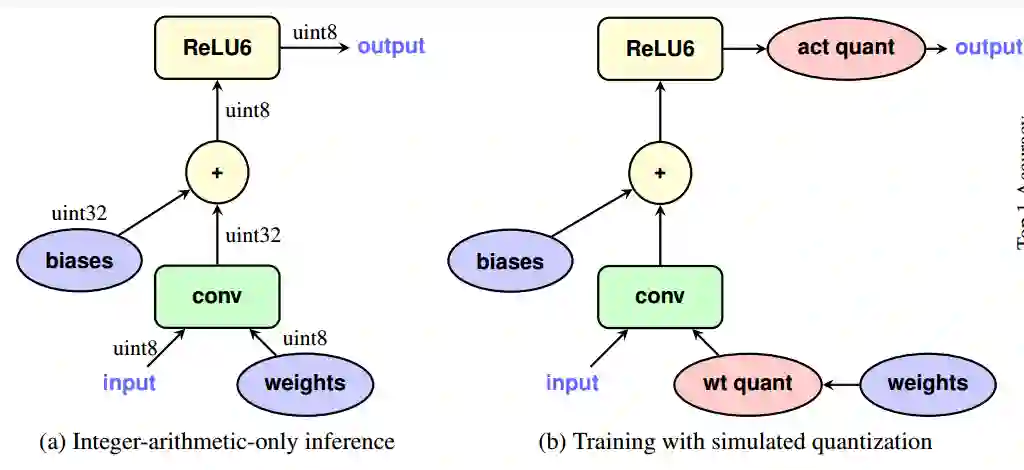
图 6 训练时量化训练原理
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference 揭示了训练时量化的诸多细节。
7. 模型量化实战经验
由于量化是牺牲了部分精度来压缩和加速网络,因此不适合精度非常敏感的任务。量化目前最适合的数据集是图片和激光雷达点云数据,基于图片的 2d 目标检测、分类,可以做到掉点 1% 以内,基于激光点云的 3d 目标检测甚至几乎不掉点;
模型量化过程中一定会出现精度上掉点,第一种方法,可以尝试把 FeatureMap 的量化位宽从 int8 变为 fp16 等提高量化位宽,第二种方法是寻找 FeatureMap(输入,X)的最佳值域,通常有 kl 散度等方法,第三种方法是模型问题,权重分布上存在离群点,可以直接人为去除,或者重新训练模型,第四种方法是跳过某些重要的层不量化,例如注意力机制,尝试量化后面的层而不是前面的层等。
模型量化只是深度神经网络压缩和加速的一种方法,还有包括知识蒸馏、矩阵秩分解、网络剪枝、自动模型搜索技术等多种方法。但是量化是一种已经获得了工业界认可和使用的方法,在训练 (Training) 中使用 FP32,在推理 (Inference) 期间使用 INT8 这套量化体系已经被包括 TensorFlow,TensorRT,PyTorch,MxNet 等众多深度学习框架启用。
—参考文献—



如果您想在 TensorFlow 社区分享经验与用例,点击 “阅读原文” 填写相关信息,我们会尽快与您联系。