网易游戏海外AWS实践分享


4 月 27 日,网易游戏学院受邀 AWS,作为主题演讲分享的重磅嘉宾,参与了中国区 AWS Game Tech Day- AWS 游戏开发者大会深圳站分享,网易游戏资深云解决方案工程师孙国良代表网易团队带来了《网易游戏海外 AWS 实践分享》,技术内容丰富,引起现场热烈讨论,与会人员收获满载。
孙国良,2013 年加入网易游戏,曾负责《天谕》《猎魂觉醒》《楚留香》等游戏项目运维工作,之后负责游戏出海对接公有云的运维架构以及混合云管理平台设计,专注于混合云上业务解决方案和最佳实践的沉淀积累。
孙国良带来的《网易游戏海外 AWS 实践分享》,分享了网易游戏在《阴阳师》《荒野行动》《第五人格》《明日之后》等多款游戏出海运营过程中积累的实践经验,这次分享以全球化的开放视野,与广大游戏热爱者共探云技术的实践运用。
以下为分享实录:
大家好,今天非常高兴能够 分享网易游戏海外在 AWS 云上的实践情况,希望我分享的内容能给大家提供一些线上最佳实践优化的思路,当然也非常欢迎大家对我分享的内容提出建议帮助我们一起改进在云上的业务架构。简单自我介绍一下,我从 2013 年加入网易游戏,早期是做游戏运维的工作,是端游《天谕》、手游《楚留香》等游戏的运维负责人,后来我主要负责了网易游戏出海对接公有云的运维架构,以及国内外混合云解决方案方面的工作。
首先简单介绍一下网易游戏出海的历程,这里主要是指手游。 我们差不多是从 14 年底 15 年初开始做海外发行,比较典型的游戏有《阴阳师》《荒野行动》《终结者》《第五人格》等等, 今年我们也会有更多的游戏出海发行,比如最近发布的《明日之后》《量子特工》等,后续还会有更多的重磅游戏,敬请期待。
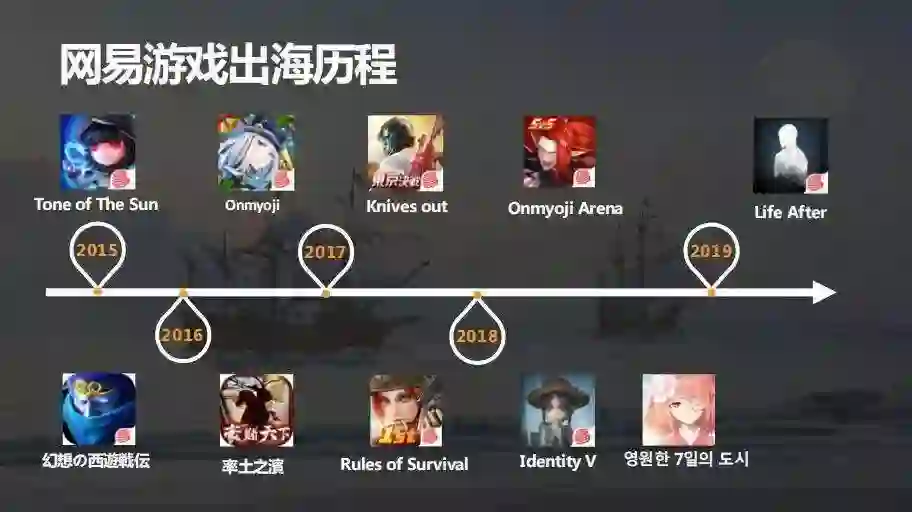
根据第三方统计,去年中国的游戏发行商在海外的收入排行榜中网易取得了第三的成绩,并且中国出海手游收入榜单前 30 中我们有两款游戏上榜——《荒野行动》和《终结者》。根据 Sensor Tower 的统计,《荒野行动》2018 年在全球吸金 4.56 亿美元,其中日本玩家贡献了八成。当然我们也还有其它很多游戏在全球多个地区取得了不错的成绩。
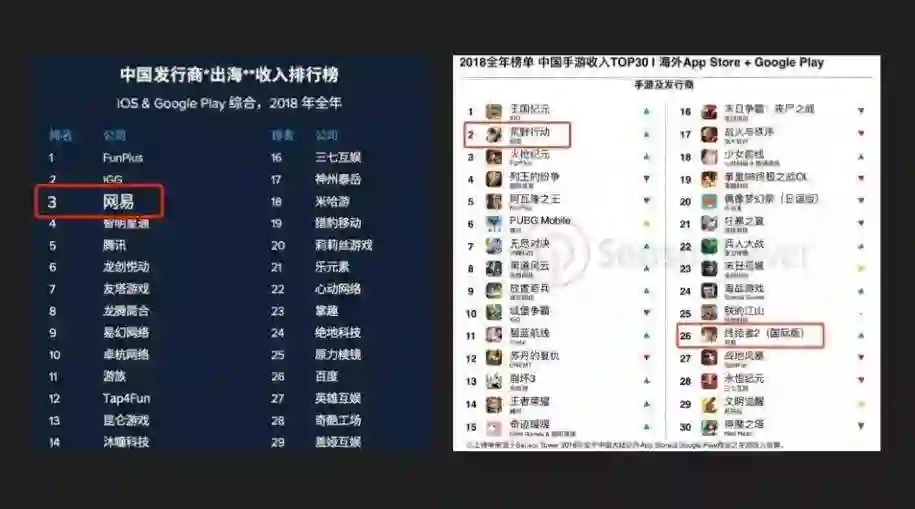
我们回到刚开始出海的时间点,14 年底,从运维和基础架构层面出发,当时我们面临了国内发行和海外发行的一些根本性的差异:
第一点: 网易游戏在国内是有 自建数据中心 的,但是游戏出海我们不可能去每一个发行的地方自建机房,所以会考虑引入 公有云 的基础设施;
第二点:因为要引入公有云,海外使用的资源是 虚拟化的,而我们原来在国内还有比较多的使用 物理资源;
第三点: 云上的资源是 弹性 的,而物理资源是 固定 的;
第四点: 国内发行的游戏 只要覆盖国内网络,但是发行到海外的话我们面临的是 全球范围的网络 情况。
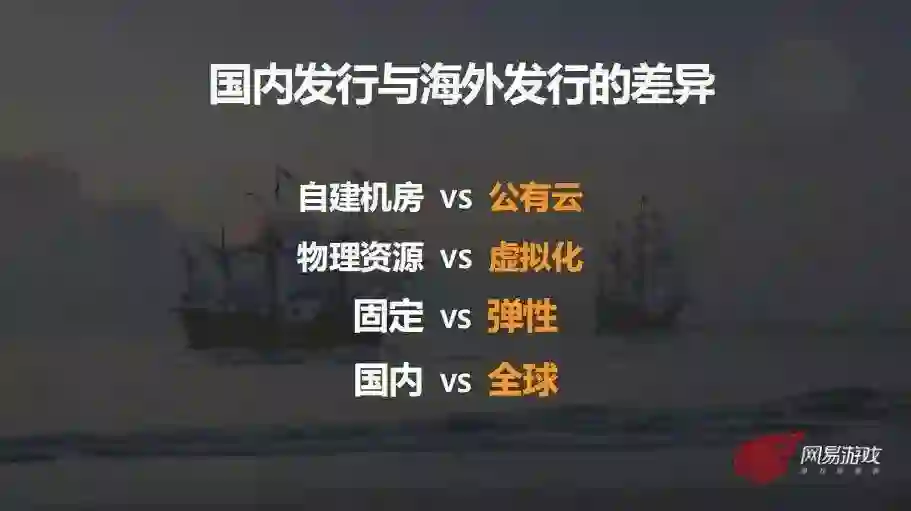
这些差异化给我们带来了新的挑战,总的来说就分为这几点:
第一:性能。 国内可以直接用物理网络设备和服务器承载高性能的业务,如果在海外用公有云的虚拟网络和服务器,这些虚拟化的资源能否满足游戏业务需求,这对我们来说其实是一个未知数。
第二,动态弹性。 因为云资源大都是按时收费的,所以从成本考虑会引入动态伸缩的方案,而动态伸缩对于游戏业务和基础架构来说也是一个全新的内容。
第三,安全性。 国内我们有自建的数据中心,安全性比较容易掌控。在公有云上我们就需要考虑很多安全方面的因素,除了网络安全,还有数据安全等。
第四,全球通服。 游戏海外发行给我们带来一个全新的需求就是全球通服,后面也会介绍我们在全球通服方面的一些实践。

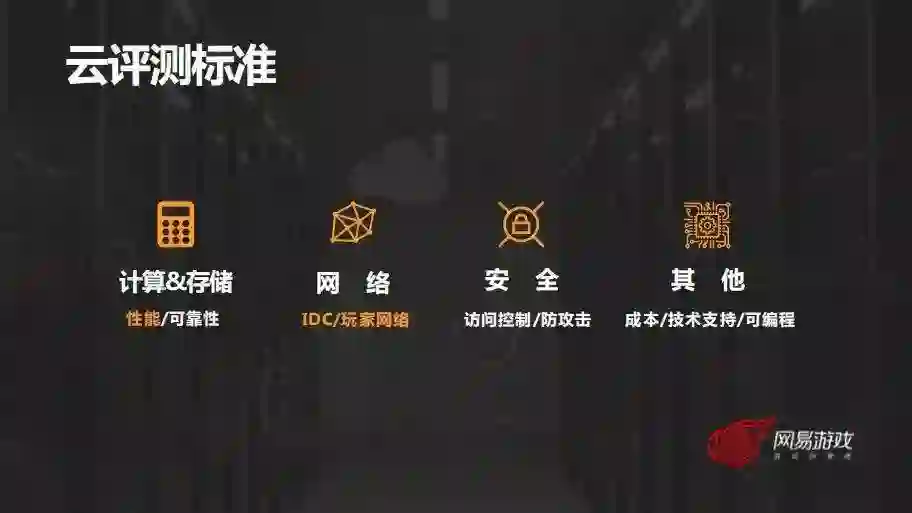
基于这些海外发行和国内发行的差异和挑战,从基础架构层面出发,我们一直在做的一件事情就是建立起一套标准化的云评测体系,来评估一个游戏是否能发行到公有云,以及哪个云能够满足需求标准,并且在实践过程当中根据我们遇到的问题不断迭代这套体系。
我们的评测大概分为这几个方面,第一是基础设施层面,例如对于计算、存储的性能 / 可靠性 / 可用性方面的考量,还有对于网络质量的评估,会分为数据中心网络以及玩家网络两方面。第二个就是安全性,刚才也已经有提过。另外也会有技术支持,成本等多方位的评估,这次分享会集中讲我们在计算性能以及网络延迟方面是怎么做的。
首先是计算性能的评测,对于 CPU 可能很多同学都已经比较熟悉了,常规评估会从硬件架构 / 型号 / 核数 / 主频等指标出发,然后做一些 Benchmark 性能测试,但我今天要讲的重点不是在这些方面。
我想先讲一个案例,在 16 年底当时《阴阳师》有在海外部署两个服,一个是日服,第二个是北美的全球华人服,两个服都跑在 AWS,用了相同的机型,运行相同的操作系统和游戏程序代码,但是很奇怪的一个现象是日服的性能只有美服的十分之一,日服在一开始完全无法支撑当时的发行需求。

从运维的角度,硬件 / 系统 / 软件代码层面都没有什么差异,就先从业务进程这边先入手排查一下。这是当时阴阳师代码压测的情况,上面是日服,可以看到在空跑的状态下 CPU 总体使用率就超过 60%,下面是美服,在空跑状态下它 CPU 总体使用率不到 5%。
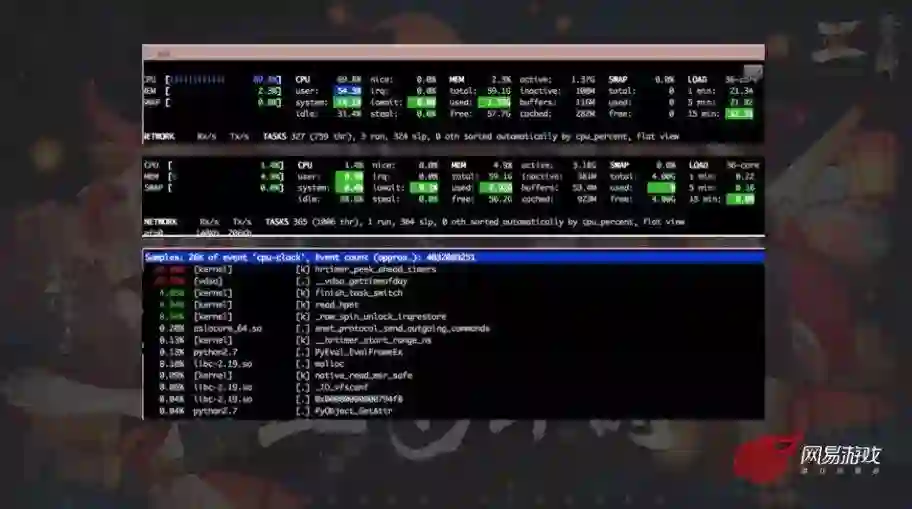
通过 Perf top 或者是 strace 之类的工具去分析进程到底消耗在哪些系统调用,我们发现大部分的调用在 hrtimer,这是获取时钟源的指令,其实对很多游戏引擎来说可能都会依赖这个调用,因为需要加程序插桩用于性能 profile,所以当时我们就怀疑到可能是时钟源设置上的差异,一看果然是。
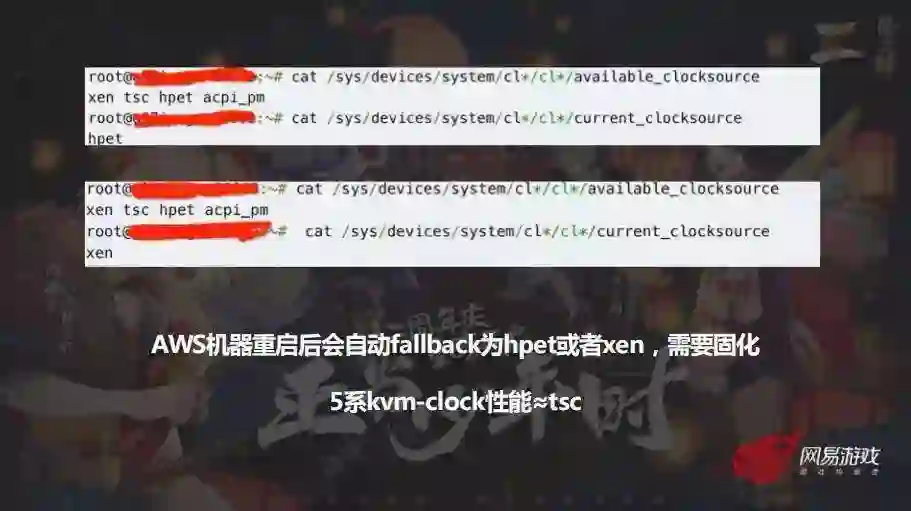
上面是性能有问题的时钟源,设置成了 hpet,下面是正常服的时钟源,它设置的是 xen,但是 Hpet 是读主板的时钟的,而 Tsc 这些是直接读 CPU 寄存器的,两者性能相差悬殊,而两个服支持的时钟源完全一样。
这里其实引伸出另一个问题,网易游戏是有一套服务器初始化的自动化标准流程的,当时我们的流程没有把 AWS 时钟源统一设置为高性能 tsc 的原因是 AWS 的机型少支持某一个 cpu 指令,我们会根据有没有这些指令 flag 去设置时钟源,初始化流程没有去设置就导致它用了 AWS 自动设置的时钟源,而 AWS 会自动随机设置成 hpet/xen/tsc 的任意一种;
解决方案是很简单的,我们在初始化流程里去定制 AWS 的机器要把它设置成我们想要的时钟源。 在经过这个问题之后我们就把 CPU 所支持的指令集以及时钟源作为一个关键的评测指标,如果说新的平台需要改用新的时钟源,比如 5 系实例是一个新的 nitro 平台,它引入了全新的时钟源叫做 kvm-clock。那么针对这个时钟源我们就需要做游戏引擎的压测,确认这个时钟源的性能能够满足业务的需求。

接下来再看另外一个案例,在 2018 年初 Intel 的两个漏洞 Spectre&Meltdown 全面爆发,所有云商都跟进修复这个漏洞,当然 AWS 也很快修复了这个漏洞,修复这个漏洞需要底层打上几个补丁,当时我们发现漏洞修复后 3 系,4 系的实例都出现不同程度的 CPU 性能损失,尤其是对于网络密集型的业务,最多会出现 50% 的下降。
而《荒野行动》的游戏服恰好是网络密集型的业务,并且 18 年初正好是《荒野行动》在春节期间人数一直上升的阶段,所以这个性能下降导致了当时玩家承载量上不去,需要排队。
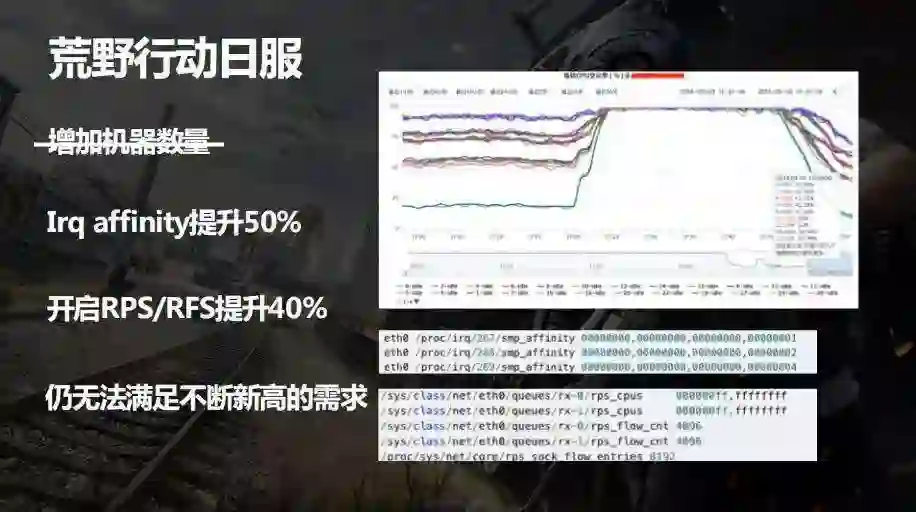
这里截取了游戏压测的 CPU 负载情况,最下面的那条线就是某一个 CPU 的 SI 的软中段已经到达瓶颈,pps 已经撑不住了会开始丢包,玩家的体验没办法保证,但整体的 CPU 性能并没有达到瓶颈,大概是百分之四、五十还没有被充分利用,但就是因为某一个 CPU 的 si 吃满导致了网络软中段的性能瓶颈。
这里第一个想到的方案可能就是堆机器,是不是增加机器就可以提升承载量?这个方案不是很可行,或者是它的效果不佳。因为我一旦增加机器的话整个集群内部的通信反而会增加,而且瓶颈仍然会在那个 CPU 核上。增加机器是一种提升效率不佳,而且成本又很高的方式。
接着我们就尝试从系统层面去优化,当时我们专门跟 AWS 的架构师进行探讨,4 系的实例是支持多少个网卡队列?结论是应该有两个队列,然而我们在系统里面看到只有一个队列,我们怀疑可能是因为用的网卡的驱动版本太老了,然后就把它做了升级,确实就有两个队列,并且开启了 Irq,Irq 是从 linux 2.6.22 内核开始引入的一个新特型,它可以把硬件多个网卡队列的数据包处理分散到多个 CPU 核上去,这样一来两个队列可以分散到两个 CPU 核上,这个优化可以提升约 50% PPS 承载量。
但是光靠这个还不够,还没有达到漏洞修复前的性能,我们继续寻找其它的优化方式,考虑引入 RPS 跟 RFS, 它是从 linux 2.6.35 开始进入 linux 内核的,通过软件模拟的方式实现更多多队列的功能,把软中断负载分散到多个 CPU 核上去。但是默认情况下我们不会去开 RPS,因为它会造成额外 CPU 的开销,这个分散本身就会消耗一定的 CPU。基于两个队列确实已经不够,那我们就选择开启,开了之后大概能提升 40% 左右的 PP。
这里也再提一下 RFS,虽然说我们把网卡分散到了多个 CPU,但是有可能出现这样的情况,即给该数据流分发的 CPU 核和执行处理该数据流的应用程序的 CPU 核不是同一个,这样对于 CPU CACHE 的性能影响较大,RFS 就是保证应用程序处理的 cpu 跟软中断处理的 cpu 是同一个,从而保证 CPU CACHE,当然这两个特性一般来说都是结合一起开的。
做了这两个提升之后系统的网络包处理性能差不多已经达到了之前说的因漏洞修复以前的状态,但是这个状态仍然没办法满足需求,因为当时《荒野行动》在日本的人数一直新高,数据流的量级其实已经超出了我们所用的 4 系实例的极限,我们开始思考当前的 4 系列虚拟化体系的性能可能已经无法满足现在的业务需求。
这时候刚好离 AWS 推出 5 系 Nitro 新平台不久,这个平台本身它有很多重大升级,包括硬件底层,hypervisor 层等都是全新的,尤其需要注意的一个是网络性能优化从 SRIOV 改成了 ENA,第二个是磁盘驱动改成了 NVMe。这两个改变理论上来说是能够本质的提升网络处理性能,所以我们开展了测试:

可以看到上面是 4 系,下面是 5 系。5 系最多有 8 个网卡队列,它的网卡软中断负载可以更均衡的分散到多个核上去,所以能更加均衡的承载业务网络数据,整体的实例性能也是可以继续往下压榨的,可以去到 70-80% 的总利用率。
我们还对比了他们的成本,4 系到 5 系实例的替换比例接近 2:1,可以节省不少成本。于是我们就进行了升级操作,包括操作系统、驱动、软件依赖包等都做了升级,然而升级并没有那么的顺利,我们在 1 个月内就遭遇了 8 次各种类的故障,其中有硬件底层的,有 hypervisor 层的,也有上层应用兼容性的问题。
所以这里也想提一点,对于一个新技术或者新平台,我们还是需要用敬畏的心态面对它, 而不是说好像觉得很厉害很牛,就去用它。其中有一个疑难问题我们也通过 AWS 的 enterprise support 跟 EC2 产品团队直接进行了沟通。
我们定制了一个调试用的 linux 内核,并且 EC2 团队为我们定制了一个调试用的 hypervisor,加了很多的 debug 设置,然后在 dedicated host 上绑定这个 hypervisor 去跑应用来定位到底这个问题是什么,虽然最后还是没有能定位到精确的问题,不过好在我们找到了一个 workaround,线上暂时来说可以有解决办法,当然我们也仍然在寻找更优雅的解决方案。
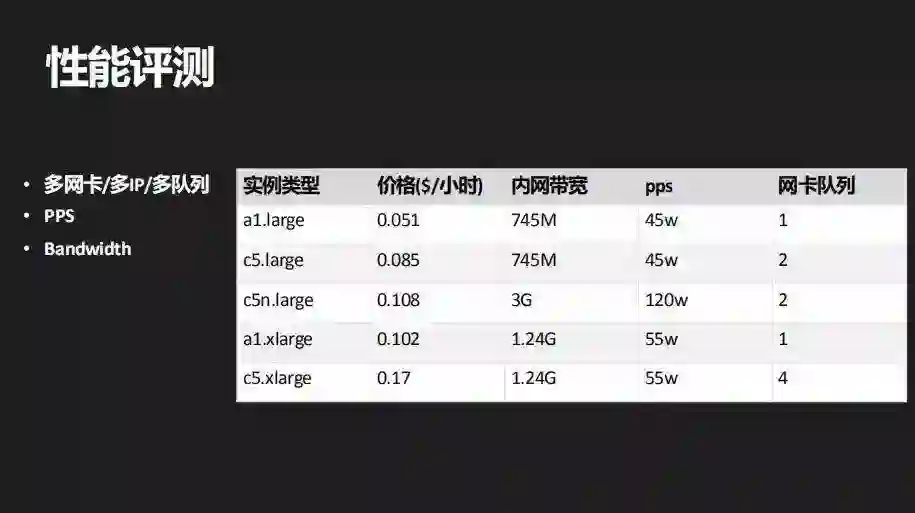
经过这次实践之后我们就实例支持的队列数 / 网卡数,包括支持的 IP 数都把它加到了我们的评测体系里面,以及它的带宽和 PPS 指标,其中多网卡,多 IP 是有一些其他的应用场景需要的。

第二方面是存储,主要就是可用性,IOPS,吞吐量等方面的评测。
这里要说一点的就是我们会更加追求性价比, 举一个例子,假设有一个数据库的应用它的需求是需要一个 600G 大小的快存储,IOPS 要求是 10000,吞吐量要求是 200MB/s。因为这是一个高 IOPS 的应用,我们第一个想到的方案可能就是用 IO1 EBS,因为 IOE 是一个可以制定 IOPS 的高性能方案。
但其实还有一个方案是用一个很大的 GP2 的磁盘,GP2 是一种 IOPS 随容量增大的 EBS,比如这里写的 3.3T 这么大的磁盘,它的 IOPS 也能够达到 10000,但是它的价格不到 IO1 的一半,这时候我们可能就倾向于用 GP2 去承载存储密集型的业务。
接下来是网络评测,这一块分为两方面:一个是 IDC 网络,一个是玩家网络。
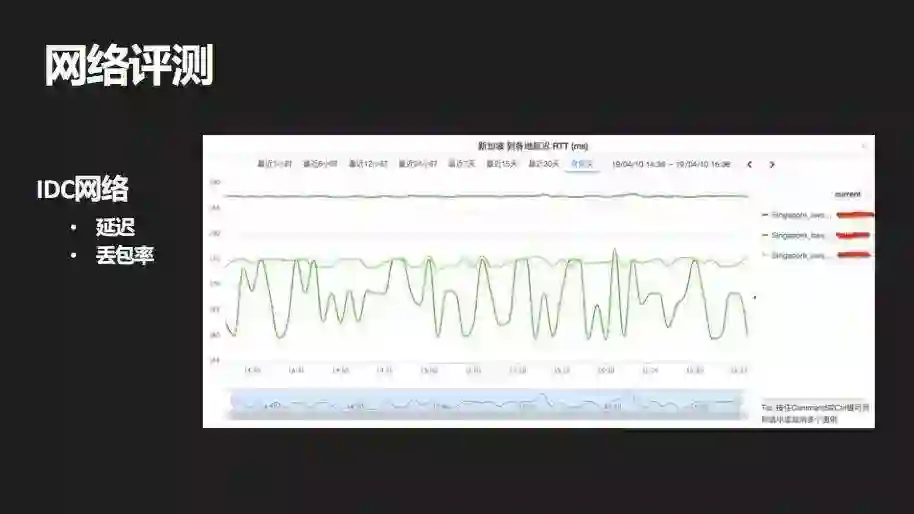
IDC 网络就会比较直观了,比如说要在新加坡部署一个服,那新加坡的服跟日本的服互相之间可能需要交互,例如跨服战斗。那这时候就需要评估新加坡到日本这些地方的数据中心的网络延迟能否满足游戏需求?
通常来说不同的游戏可能会有不一样的需求,这个游戏是 100 毫秒,那个游戏可能是 200 毫秒,所以就需要我们有这样的评测数据作为决策支撑。图里是举例在 AWS 上面的一个评测案例,我们评测了 AWS 新加坡到日本和韩国 AWS 节点之间的网络情况;当然实际的评测会更加复杂和庞大一些。
对于玩家网络评测,这个也很直白,比如说还是在新加坡部署一个服,但是面向的玩家可能是东南亚地区,越南,泰国,马来,印尼,菲律宾等。
那这些地方的玩家到数据中心的网络是否能够满足到我们游戏需要的延迟 / 丢包的要求,这就需要我们做一个全面的评测。通过我们在各地玩家客户端 SDK 中加入探针去探测这些地区的玩家到数据中心网络的延迟和丢包情况,一般的会测游戏本身流量基于的协议,比如说 TCP 或者是 UDP 或者是其它自研协议,图中就是一个玩家网络评测样例。
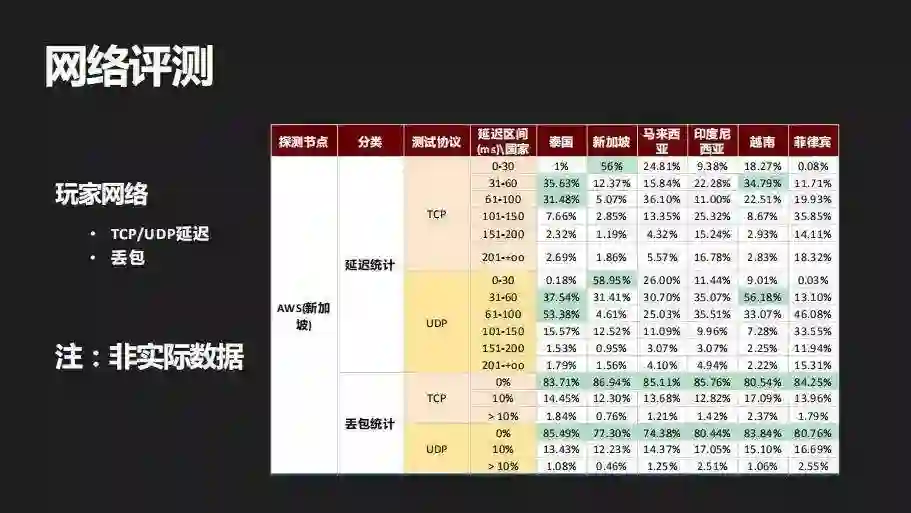
数据为伪数据,仅作示例,请勿参考
其它我们也会有很多方面的标准化评测,包括刚才提到的安全性是一个非常重要的方面,因为我们多款游戏在 DDOS 上吃过很多亏,也做了一些优化方案,其他的还有例如基础设施可编程,因为我们有数十上百款游戏,光在 AWS 上面可能就有成千上万台服务器,我们需要用到云的 API 或者是 SDK 来开发我们的自动化管理工具。
还有技术支持方面,除了售前的架构咨询,还有就是售后的 7*24 故障响应等等。另外成本也会做一个综合的评估,包括收费模式,费用对比等;网易游戏对云的标准化评测大概就是这一些方面。

经过评测之后 AWS 是一个符合业务需求的选择,因为 AWS 有广泛的全球基础设施,在计算存储网络等方面都有高性能的方案,所以很自然 AWS 成为我们海外发行比较重要的选择之一。
最后我想分享一下经过这几年海外上云实践的心得总结:
第一点:实践永远是检验技术的唯一标准,一项新的技术是否值得引入需要评估测试,经过线上实践验证,能明确它能够对我们业务产生价值我们才会认为它是一项很好的技术。
第二点:我们会在满足业务需求的前提下不断寻求成本优化的解决方案。
第三点:不管是云还是游戏,每天都在快速发展,这就需要我们不断学习,寻找业务的切入点, 切实满足业务需求或优化线上服务,我觉得这是我们做云架构或云解决方案的核心价值。
希望能对大家有所启发。
中国区首次举办的 AWS Game Tech Day- AWS 游戏开发者大会深圳站已与 2019 年 4 月 27 日完满落幕,作为目前为止规模最大的 AWS 游戏行业会议, 内容丰富更胜以往。对于行业未来发展,网易游戏学院与 AWS 拥有同样的愿景,希望游戏能够在运行流畅之余不断创新,也希望借助这个平台,与全球游戏热爱者自由交流,碰撞出思想和技术的火花,携手探索出更多的可能性。
(附活动照片如下)




如大家想获悉更多网易分享内容,了解更多网易资讯,那么机会来了!
2019 AWS Game Tech Day
上海站即将拉开帷幕

“中国智造”的游戏也大有风靡世界的潜力
各位游戏行业大佬们,欢迎来这里交流嬉戏 :)
在 AWS Game Tech Day 上,我们特别为客户精选了游戏行业云端议程,内容将涵盖多个重点主题:
•云上的游戏数据湖及机器学习在游戏开发中的应用;
• 深入探讨游戏全球同服架构构建部署;
• DDOS 防护方法实践;
• ……
我们还将与全球的游戏行业客户一起,分享和探讨这些宝贵的经验以及最新的技术,除此之外,还将特别企划一场 “Amazon GameLift 动手实战训练营”,为学员提供真实的 GameLift 服务管理与操作环境,从实验中学习,辅以讲师要点精讲,快速上手 GameLift 服务!
现在扫码,即刻报名!

会议时间:2019 年 5 月 28 日(星期二), 08:30-17:30
会议地点:上海虹桥雅高美爵酒店(上海市长宁区仙霞路 369 号)
现在就加入 AWS 中国游戏开发者大会
2019 AWS Game Tech Day
和众多大咖专家来一场游戏风暴!





