推荐系统之FM与MF傻傻分不清楚

目录
-
前言 -
FM模型简介 -
MF模型简介 -
FM vs MF
前言
之前分享过一篇关于围绕LR周边模型展开的文章,主要前向回顾了它与Linear Regression的关系,后向介绍了它与Softmax Regression以及Linear SVM的关系,同时延伸了它与Factorization Machine的联系以及它与Multiple Layer Perceptron的关联。记得有朋友在底下评论说MF和FM到底有啥区别和联系,希望能够真正把他们搞懂,因此文本的目的就在于此。概括一句话就是:FM是MF的全能版本,MF是FM的一种简单存在形式。
FM模型简介
因子分解机(Factorization Machine, FM)是由Steffen Rendle提出的一种基于矩阵分解思想的机器学习算法,FM的提出是为了解决大规模稀疏数据中的特征组合问题。
1.1 FM模型
最常见的预测任务是估计一个函数: ,将实值特征 映射到目标域 中(其中对回归任务 ,对分类任务 )。在监督模型中,已知训练数据。另外在排序任务中,可以通过成对的训练数据来训练得到打分函数,其中特征元组 , 排名高于 。
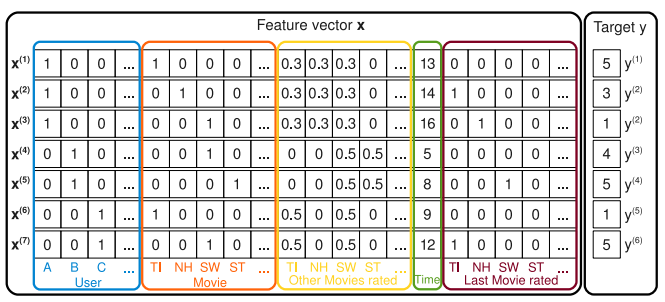
假设我们从电影评论系统中获取了这么一组交互数据(见下图),其中用户集合 ,物品(这里为电影)集合 。根据以上数据构造了如图1所示的实值特征向量,蓝色框框内代表用户的one-hot编码,橙色框框内代表电影的one-hot编码,黄色框框内代表用户评论过的其他物品,并做了归一化,绿色框框内表示评论的时间,紫色框框内表示最近评论过的物品,最后一列Target y表示用户对该物品的一个评分(以 为例,即用户A对电影TI的评分为5)。
1.2 FM模型公式
(1)二阶FM
FM是在逻辑回归(LR)的基础上扩展的,因此在特征线性组合的前提下增加了特征交叉项,公式如下:
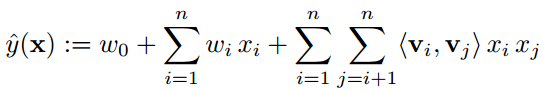
其中 ,内积表达式 。
从上述公式中可以看出时间复杂度为
,但通过化解公式之后可以得到线性的时间复杂度
。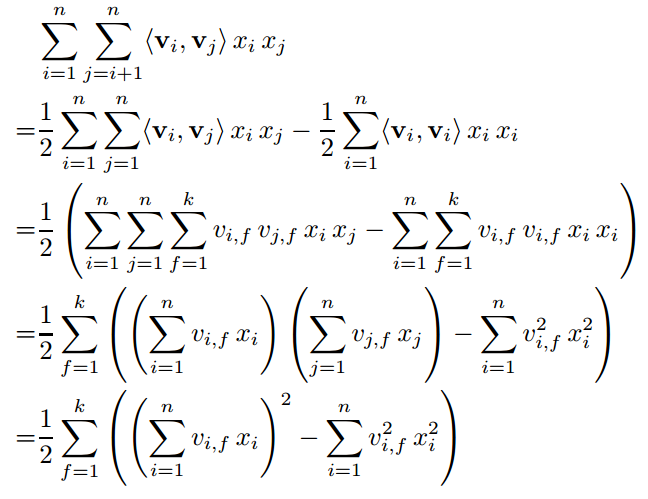
(二)高阶FM
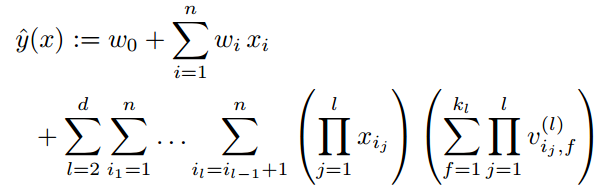
相比二阶FM,高阶FM考虑了更多特征之间的联系。
MF模型简介
推荐系统核心技术是协同过滤技术 其中协同过滤技术中最常用的便是矩阵分解技术,矩阵分解将用户与物品嵌入到一个共享的低维隐空间内。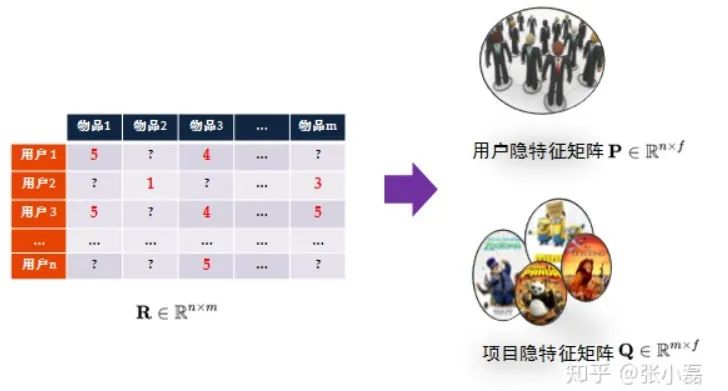
但是考虑一些额外因素:1、一些用户给分偏高,一些用户给分较低,2、一些物品本就比较受欢迎,一些物品不被大众所喜爱,3、评分系统的固有属性,与用户物品都无关。因此,考虑到这些因素,将用户对物品的预测函数升级为:
其中 为全局偏置, 为用户偏置, 为物品偏置。
FM vs MF
分解机的思想是从线性模型中通过增加二阶交叉项来拟合特征之间的交叉,为了拓展到数据稀疏场景并便于计算,吸收了矩阵分解的思想。这一节中主要简单了解一下FM与MF之间的关系。
MF是FM的特例
本质上,MF模型是FM模型的特例,MF可以被认为是只有User ID 和Item ID这两个特征信息时的FM模型。接下来,举个栗子方便大家理解FM是如何在仅有User ID 和Item ID时退化成MF模型的。假设用户集合为
,物品集合为
,我们以图1中的
为例,在仅包含用户ID和物品ID信息时,特征维度
,则特征向量
,即为用户ID和物品ID的one-hot表示的拼接,由于特征向量
中第一位和第四位为非零元素,因此二阶FM公式便如下所示: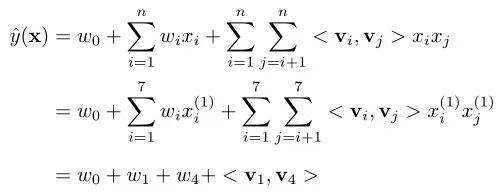
FM与MF的不同
-
「输入数据的形式不同」 一般来说,FM的输入数据是一个实值特征向量(如图1的每一行),相当于是对多个one-hot特征的拼接;MF的输入数据是一个二元组 , 为用户ID, 为物品ID。往往对于FM和MF理解的难点在于此,一个数据形式为one-hot,一个数据形式为标号ID。只不过MF中的数据只有user和item,因此可以通过标号ID直接查询对应的隐向量,而FM则需要通过one-hot的形式与隐向量矩阵做乘得到对应的隐向量。
-
「参数矩阵的不同」 往往我们在FM模型中只初始化一个参数矩阵 ,其中 为特征的数目;MF模型由于只涉及user和item的隐特征,因此可以分别学得一个用户矩阵 和物品矩阵 。如果FM中只有user和item的特征时, 。因此,只不过MF为了方便,把user和item分开进行初始化,其实类似于FM只初始化一个矩阵未尝不可,只不过需要注意user和item的下标不要重复,比如user从1开始,那么item很可能需要从 开始。
-
「融合附加信息的方式不同」 他们输入数据的形式决定了他们融合附加信息的形式不同。直观来讲,FM融合附加信息的方式更直接。比如FM融合边信息直接在列的维度拼接特征即可,比如增加性别、年龄等信息;而MF融合边信息不能直接在输入数据上拼接,而是需要通过增加正则项约束,或者在预测函数上做文章。更具体的融合方式可参考之前的博文推荐系统之矩阵分解家族,可见MF也可以方便快捷的融合各种附加信息。
推荐阅读




