教程 | 如何通过距离度量学习解决Street-to-Shop问题
选自Medium
作者:Aleksandr Movchan
机器之心编译
参与:Nurhachu Null、黄小天
本文将向你介绍用机器学习解决街道到商店 (street-to-shop) 问题的流程:如何从用户图像中识别衣服,并从网上商店找到它。你可曾有过这样的经历,在大街上看到某个人,然后不禁感叹,「哇哦,多么漂亮的衣服,我在哪里能买到它呢?」本文作者虽然没有过这样的经历,但是对其而言,尝试使用距离度量学习技术是一项很酷的任务。希望你也会觉得这很有趣。
数据集
首先,我们需要数据集。实际上,当我发现 Aliexpress 上有很多用户图像的时候我就有了这个想法。我心里想,「哇,我可以通过使用这种数据来搜索,当然是仅仅为了有趣」。为了简便,我决定重点关注女装。
下面是我所使用的类别:
连衣裙
衬衣&衬衫
卫衣和运动衫
夹克和外套
我使用 requests(https://pypi.python.org/pypi/requests)和 beautifualSoup(https://pypi.python.org/pypi/beautifulsoup4)来爬取图像。卖家的图像可从商品页面上获得,但是为了得到用户图像,我们需要浏览反馈页面。在商品页面上有一个叫做「colors」的属性,指的是另一种不同的颜色或者甚至是另一件商品,所以我们需要将不同颜色的衣服视为不同的商品。

商品页面上的「颜色」
你可以在 github 上找到我用来得到关于一件服饰的所有信息的代码(https://github.com/movchan74/street_to_shop_experiments/blob/master/get_item_info.py)(它爬取到的信息甚至比我们任务中需要的信息还要多)。
我们需要做的就是通过每一个类别取浏览对应的页面,拿到所有商品的 URL,然后使用上面提到的函数取得有关每个商品的信息。
最终,我们得到了每个商品的两个图片集合:来自于卖家的图片(商品页面上每个「colors」对应的元素)以及来自于用户的图片(商品页面上每个「feedbacks」对应的元素)。
对于每个 color,我们只有一张卖家图片,但是可能具有多于一个的用户图像 (然而有时候根本没有用户图像)。
很棒现在我们有数据了。然而得到的数据集有噪声:
用户图像中含有噪声(包裹箱子的照片,商品中一些无关区域的照片,以及刚拆开包装的照片)。

用户数据中的噪声示例
为了减轻这个问题,我们给 5000 张图像打了两种不同类别的标签:好图片和噪声图片。起初,我计划训练一个分类器来清洗数据集。但是后来我决定将数据清洗分类器这项工作留在后面,仅仅将干净的数据用在测试集和验证集中。
第二个问题是,一些商品有好几个卖家。这些卖家有时候甚至用的是相同图像(经过轻微编辑)。那么如何处理这个问题呢?最简单的方法就是对数据不做任何处理,使用一个鲁棒的距离度量学习算法。但是这会影响到验证,因为在这种情况下,我们在验证数据和训练数据中有相同的商品。因此这就造成了数据泄露。另一种方式就是使用某种方法来寻找相似的(甚至完全相同的)商品,并将其合并。我们可以使用感知哈希来寻找相同的图像(例如 phash 和 whash)。或者我们可以在噪声数据集上训练一个模型来寻找相似的图像。我选择了后者,因为这种方法可以合并经过轻微编辑的图像。
距离度量学习
最常用的距离度量算法之一就是 triplet loss:
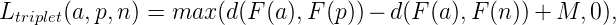
其中,max(x, 0) 是 hinge 函数,d(x, y) 是 x 和 y 之间的距离函数。F(x) 是一个深度神经网络,M 是边际,a 是 anchor,p 是正例点,n 是反例点。
F(a), F(p), F(n) 都是由深度神经网络产生的高维空间中的向量。值得提及的是,为了让模型应对对照变化的时候更加鲁棒以及训练过程中具有更好的稳定性,这些向量需进行正则化处理,以拥有相同的长度,例如||x|| = 1。anchor 和正例样本属于同一类别,反例点属于其他类别。
所以 triplet loss 的主要思想就是使用一个距离边际 M 来区分正例对(anchor 和 positive)的向量。
但是如何选择元组 (a, p, n) 呢?我们可以随机选择一个 triplet,但是这样会导致以下问题。首先,存在 N³种可能的 triplet。这意味着我们需要花费很多时间来遍历所有可能的 triplet。但是实际上我们没必要这么做,因为经过少数几次的训练迭代之后,很多元 triplet 已经符合 triplet 限制(例如 0 损失)。这意味着这些 triplet 在训练中是没用的。
最常用的 triplet 选择的方式就是 hard negative mining:
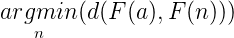
实际上,选择最严格的负样本会在训练早期导致糟糕的局部最小值。尤其是,它能够导致一个收缩的模型(例如 F(x) = 0)),为了缓解这个问题,我们使用 semi-hard negative mining(半严格负样本最小化)。
半严格负样本要比 anchor 离正样本更加远,但是它们仍然是严格的(违背了 triplet 限制),因为它们在边际 M 内部。
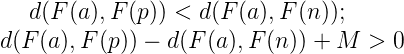
半严格负样本的 triplet 的限制条件
下面是生成半严格和严格负样本的两种方式:在线和离线。
在线方式意味着我们从数据集中随机地选择样本作为一个 mini-batch,并从这个 Mini-batch 中选择 triplet。然而,在线方法需要一个较大的 mini-batch。在我的情况中是不可能的,因为我只有一块具有 8GB 显存的 GTX 1070。
在离线方式中,我们需要在一段时间之后停止训练,为一定数量的样本预测向量,从中选择 triplet 并为这些 triplet 训练模型。这意味着我们要进行两次,然而这就是离线方法的代价。
好了,现在我们可以开始用 triplet loss 和离线半严格负样本最小化来训练模型了。但是,为了成功地解决 street-to-shop 问题,我们还需要一个技巧。我们面临的任务是找到与用户照片最相似的卖家图像。然而,通常卖家的图像具有更高的质量,所以我们有两个域:卖家图像和用户图像。为了得到更有效的模型,我们需要减小这两个域之间的差距。这个问题就叫做域适应。

左边是用户的图像;右边是卖家的图像
我想出了一个非常简单的方法来减少这种域差距:我们在卖家图像中选择 anchor,从用户图像中选择正例样本和负例样本。这个方法简单有效。
实现
为了实现我的想法并快速实验,我使用了基于 TensorFlow 的 Keras 库。
我选择 inception V3 作为模型的基本卷积网络。像往常一样我使用 ImageNet 权重初始化卷积神经网络。我在使用 L2 正则化的全局池化之后又加了两个全连接层,向量的维度是 128。
def get_model():
no_top_model = InceptionV3(include_top=False, weights='imagenet', pooling='avg')
x = no_top_model.output
x = Dense(512, activation='elu', name='fc1')(x)
x = Dense(128, name='fc2')(x)
x = Lambda(lambda x: K.l2_normalize(x, axis=1), name='l2_norm')(x)
return Model(no_top_model.inputs, x)
我们还需要实现 triple 损失函数。我们传递一个 anchor,正样本和负样本作为一个 mini-batch,在损失函数中将其分为三个张量。距离函数就是欧氏距离的平方。
def margin_triplet_loss(y_true, y_pred, margin, batch_size):
out_a = tf.gather(y_pred, tf.range(0, batch_size, 3))
out_p = tf.gather(y_pred, tf.range(1, batch_size, 3))
out_n = tf.gather(y_pred, tf.range(2, batch_size, 3))
loss = K.maximum(margin
+ K.sum(K.square(out_a-out_p), axis=1)
- K.sum(K.square(out_a-out_n), axis=1),
0.0)
return K.mean(loss)
并优化模型:
#utility function to freeze some portion of a function's arguments
from functools import partial, update_wrapper
def wrapped_partial(func, *args, **kwargs):
partial_func = partial(func, *args, **kwargs)
update_wrapper(partial_func, func)
return partial_func
opt = keras.optimizers.Adam(lr=0.0001)
model.compile(loss=wrapped_partial(margin_triplet_loss, margin=margin, batch_size=batch_size), optimizer=opt)
实验结果
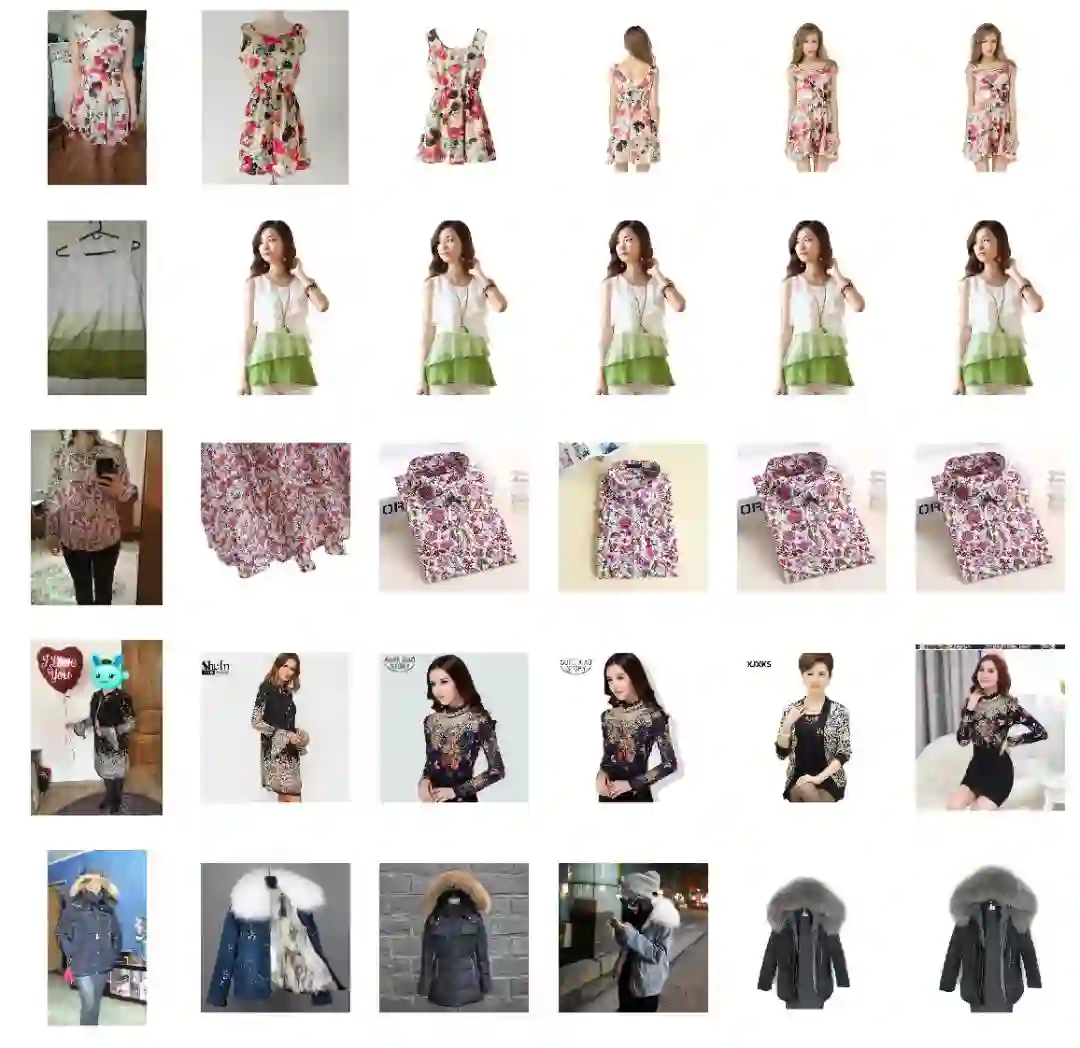
结果:第一列-查询(用户图像),后五列-最相似的卖家图像。
性能衡量指标是 R@K。
我们来看一下 R@K 是如何计算的。验证集里面的每张用户图像作为一次查询,我们需要找到对应的卖家图像。我们不仅使用了验证集中的卖家图像,还使用了训练集中的图像,因为这样可以使我们增加干扰数量,使得我们的任务更加具有挑战性。
所以我们就有一张查询图像,以及一些很相似的卖家图像。如果在 K 个最相似的图像中有对应的卖家数据,我们就返回 1,否则就返回 0。现在我们需要为验证集中的每一次查询返回这么一个结果,然后找到每次查询的平均得分。这就是 R@K。
正如我之前讲到的,我从噪声图像中清洗了一部分用户图像。所以我在两个验证集上衡量了一下模型的质量:完整的验证集只包含干净数据的子验证集。
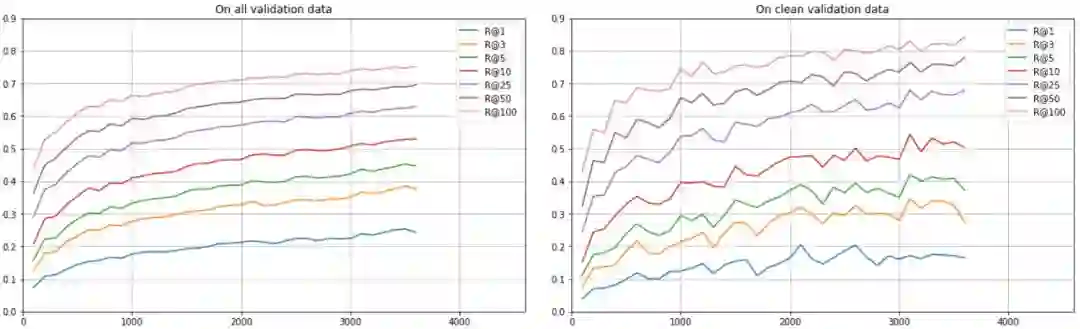
验证数据中的 R@K
结果距离理想情况还很远,还有很多需要做:
从噪声数据中清洗用户图像。我在第一步中已经做了一部分。
更加准确地合并相似的图像(至少在验证集中)。
降低域差距。假设可以通过特定域增强的方法(例如亮度增强)以及其他特定的方法完成(例如这篇论文中的方法 https://arxiv.org/abs/1409.7495)。
应用其他的距离指标学习技术。我试了这篇论文中的方法(https://arxiv.org/abs/1703.07464),但是比我所用的方法性能要差一些。
当然,要收集更多的数据。
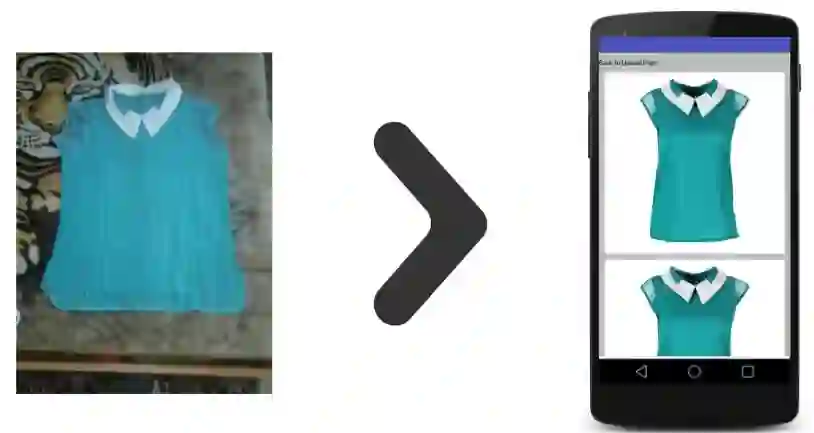
DEMO,代码和训练好的模型
我做了一个 demo。你可以在这里看到 vps389544.ovh.net:5555。你可以上传你自己的图像或者随便使用验证集中的图像来搜索。
代码和训练好的模型在这里:https://github.com/movchan74/street_to_shop_experiments。

原文链接:https://medium.com/@movchan74/how-to-apply-distance-metric-learning-for-street-to-shop-problem-d21247723d2a
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

