下一只阿尔法狗,已经会认路了
准备好向人工智能投降吧!人类。

在2014年上映的电影《她》(Her)中,男主角西奥多带着搭载有 AI 操作系统“萨曼莎”的手机,走在拥挤的游乐场里。他突然心血来潮,决定闭上眼睛,让萨曼莎来指挥他的路线。西奥多伸直手举着手机,萨曼莎完美的指引着他避开迎面而来的人群,绕过立在广场的柱子,抵达他的目的地——一家披萨店。

放在电影的背景下这个场景很温馨,单独拿出来看,这个画面很诡异。但无论如何,这样的功能正在离我们越来越近。
想要实现 AI 的实时指路,背后需要拥有两个关键技术。首先,AI 需要能够用最高效的方式识别周围的空间,其次,它还要能够像人一样,基于视线所及的图像来“脑补”出整个空间的布局。
而最近, AI 在这两个能力上刚刚取得了巨大进展,带头的又是 Google 旗下的 AI 明星公司 DeepMind。
在周四出版的《科学》(Science)杂志上,DeepMind 发表了一篇论文,向世界介绍了一个名叫 GQN 的新 AI 系统。
GQN的全称为“ Generative Query Network”,直译为“生成式查询网络”,它改进了现有的机器视觉研究方式:目前的机器视觉在训练时,更多还是依赖“吃进”人为标记好标签的图像数据来进行训练,大部分属于监督式学习,而 GQN 的方法则是让机器进行自我训练,属于无监督机器学习。
这是一种更接近人类行为模式的系统:当我们走进一个空间时,我们可以根据自己双眼看到的简单画面,快速对所处空间有一个整体的感知。比如,眼睛看到的可能只是一个衣柜的正面,但在我们的脑海中,这个衣柜的全貌、它在房间所处的位置、它在阳光下的阴影的样子,其实都已同步生成并存在于脑海中。

这对人类来说很简单,但没人能说清人类大脑是如何处理这些信息的。当 AI 尝试复刻这些流程时,若依然采取输入规则、监督式的学习方式,显然十分困难。GQN 选择了神经网络的方法,决定让机器自己学习,就像它们在围棋、翻译等领域做的那样。
具体来看,GQN 由两个模型构成,一个叫做表征网络(representation network),另一个叫做生成网络(generation network)。前者其实可以看作是在模仿人类的眼睛,后者则尝试复制人类大脑对空间信息的处理方式。
表征网络通过图像传感器观察世界,把它在一个空间中看到的二维图像,以数据形式输入到系统中,之后生成网络会基于这些数据进行学习,然后尝试对某一个陌生视角下、这个空间的样子做一个预测,将其渲染并以三维形式呈现出来。
简单说就是,表征网络看见了一个桌子的正面,包括它的构造、颜色、高低等,然后生成网络要据此“猜出”桌子侧面、底面等等其他角度的样子。就像人类无时无刻不再做的那样。
由于采用了无监督的学习模式,表征网络在“看”东西时并不知道生成网络最后需要从哪个视角进行预测,为了更好地帮助后者完成任务,它就需要在不断的训练中,提升自己的观察和记录能力,最终保证自己对系统提供的输入是最高效的。
过程中它慢慢积累了经验,对整个空间中各个物体之间的透视规律、阳光阴影关系等都有了感知(事先并没有任何人为的干预来告诉机器什么是“颜色”、“位置”、“大小”等等这些概念,全靠机器自己“开悟”),并且最终用一种计算机能理解的、最浓缩最高效的数据形式完成对系统的输入。
而生成网络在一次次训练中,将这些输入的数据再次转换成图像。而且,这个图像不再是二维的,它需要给出一个立体的空间画面,里面物体的尺寸、定位、光影关系、透视关系都需要准确呈现。在这个过程中,生成网络逐渐学习成了一个有渲染能力的图像神经网络。
经过一段时间的自主学习后,DeepMind 对 GQN 在虚拟环境中进行了测试。测试结果惊人。
下图是第一种测试,在一个类似小广场的简单的虚拟3维空间中,GQN 的表征网络从一个视角输入一组二维图像,而生成网络实现了清晰精确的三维“还原”——包括二维图片以外的空间。

接下来,DeepMind 又做了第二种测试。这有点类似我们中学时都做过的空间感觉的测试。表征网络对一个多个立方体组成的“积木”进行观察输入,而生成网络需要回答这个物体由几个立方体组成。GQN 也完成了测试。

而第三种测试,DeepMind 把 GQN 从开放的小广场赶到了一个更加复杂的“迷宫”里,这里,视野会受到限制,但 GQN 可以来回走动,找到它认为最好的视角进行观测,从而帮助生成网络更好还原整个空间。
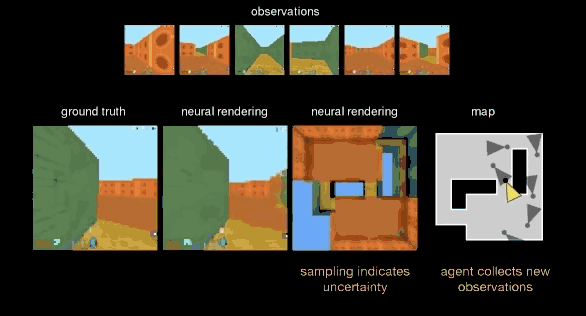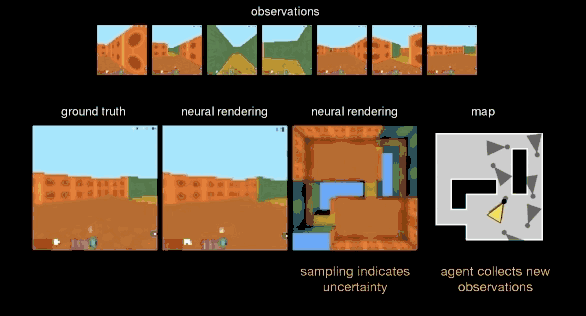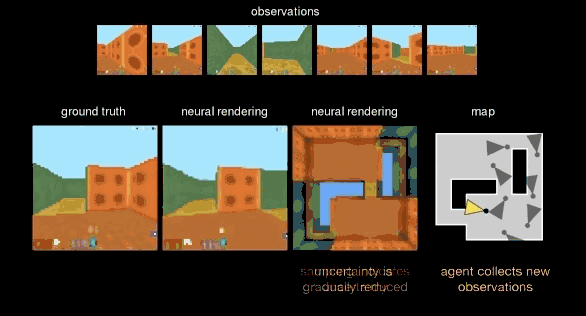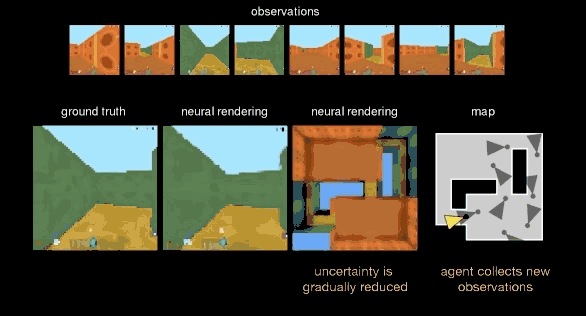
可以看到,GQN 就像做拼图一样,随着表征网络观察角度的增多,而逐渐完美“脑补”出整个空间的全貌。
这已经和人类非常接近。近的有点吓人。
DeepMind 的联合创始人、CEO 德米斯·哈萨比斯(Demis Hassabis)说:“GQN 已经可以从任何角度想象和呈现场景。”
其实,如果拉长时间来看,可以发现,这次 GQN 的突破,其实是最近 DeepMind 在 AI 识别空间方面的一系列尝试中的一环。
就在上个月,DeepMind 就曾在《自然》上发文,表示他们在 AI 身上实现了类似哺乳动物“抄近路”似的导航行为。
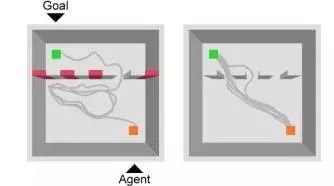
它们在 AI 身上以计算机科学的方式复刻了类似人类大脑中实现认路功能的最神秘的“网格细胞”。研究指出,网格细胞(grid cell)在大脑里给人类提供了一种感知矢量空间的框架,让人们可以给自己导航。这个可能是人类上千年进化出来的细胞,被 AI 轻松复刻。
而今年4月,DeepMind 还在 ArXiv 上发表论文,宣布他们使用深度学习和神经网络代替了地图指引,让 AI 可以仅依靠街景图就对整个城市的布局有所了解,然后找到通往目的地的路。
DeepMind 的这些对 AI 在空间和视觉方面技能的研究,最终也很可能集合成一个类似阿尔法狗的集中体。到时候的应用场景肯定不只是走走迷宫这么简单。
DeepMind 就像是一个制造机器人的拼图师傅,一点点拼着一个理想中的“超级人工智能”,然后等着人工智能在智慧上超过人类的奇点时刻的到来。
准备好向人工智能投降吧,人类。
转载声明:本文转载自「硅星人」,搜索「guixingren123」即可关注。作者:玄宁(王兆洋)

每天都看到这里?
👇快加入 PingWest 品玩吧👇
最热门的岗位都在这里
近期职位空缺如下:
记者/主笔、微信运营
要闻(快讯)编辑
新媒体文案/创意策划
商务经理、平面设计师
以及,人力资源经理...
简历投递邮箱:recruiting@pingwest.com

