卷积神经网络简介

本文为 AI 研习社编译的技术博客,原标题 :
Simple Introduction to Convolutional Neural Networks
作者 | Matthew Stewart, PhD Researcher
翻译 | 微白o、烟波01浩淼、Dylan的琴、Overfitting
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/simple-introduction-to-convolutional-neural-networks-cdf8d3077bac
注:本文的相关链接请访问文末【阅读原文】
在本文中,我将用很多天鹅图片来解释卷积神经网络(CNN)的概念,并将完成CNN在常规多层感知器神经网络上处理图像的案例。
图像分析
假设我们想要创建一个能够识别图像中的天鹅的神经网络模型。天鹅具有某些特征,可用于帮助确定天鹅是否存在,例如长颈,白色等。

天鹅的某些特征可以用于识别
有些图像中,确定天鹅是否存在比较困难,来看下面这张图像:

为天鹅图像分类较为困难
上述图像仍然存在某些特征,但对我们来说提取这些特征已经较为困难了。还有更极端的情况。

天鹅分类的极端情况
至少颜色还没变,对吧?但是……

别忘了还有黑天鹅!
还能再难点吗?当然可以。

最糟糕的情况
好的,天鹅图片的分析到此为止,下面来谈谈神经网络。我们基本上一直以非常幼稚的方式来讨论检测图像中的特征。研究人员构建了多种计算机视觉技术来解决这些问题:SIFT,FAST,SURF,Brief等。
然而,类似的问题又出现了:探测器要么过于笼统,要么设计过渡。人们正在设计这些特征探测器,这使得它们要么太简易,要么难以推广。
如果我们掌握了要检测的特征怎么办?
我们需要一个可以进行表征学习(或特征学习)的系统。
表征学习是一种允许系统自动查找给定任务的相关特征的技术,能代替人工特征工程。有这样几种方法:
无监督的(K-means,PCA,……)
监督的(Sup,Dictionary learning,Neural Networks)
传统神经网络的问题
假设你已经熟悉多层感知器(MLP)的传统神经网络了。如果你不熟悉这些内容,在中间大纲上有很多有关MLP工作方式的介绍,你可以去了学习一下。这些是类比人脑建模的,其中神经元由连接的节点刺激,并且仅在达到特定阈值时才被激活。
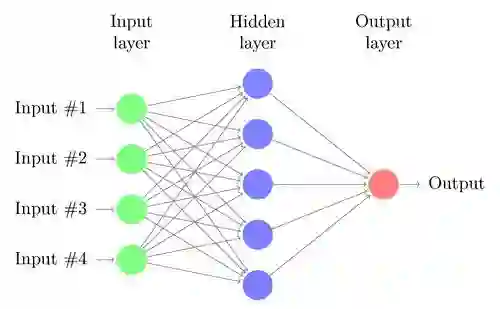
一个标准多层感知器(传统神经网络)
MLP有几个缺点,特别是在图像处理方面。MLP对每个输入使用一个感知器(例如,图像中的像素,在RGB情况下乘以3)。对于大图像,权重数量迅速变得难以处理。对于具有3个颜色通道的224 x 224像素图像,必须训练大约150,000个权重!结果,在训练和过拟合过程中,困难同时出现。
另一个常见问题是MLP对输入(图像)及其移位图像的反应不同——它们不是平移不变的。例如,如果猫的图片出现在一张图片的左上角,且出现在另一张图片的右下角,则MLP会尝试自我纠正并认为猫是一直出现在图像的这一部分中的。
显然,MLP不是用于图像处理的最佳方法。其中一个主要问题是当图像变平为MLP时,空间信息会丢失。靠近的节点很重要,因为它们有助于定义图像的特征。因此,我们需要一种方法来利用图像特征(像素)的空间相关性,这样无论猫出现在何处,我们就可以看到它。在下图中,我们正在学习剩余特征。这种方法并不健全,因为猫可能出现在另一个位置。

使用MLP的猫探测器,随着猫的位置改变而改变
进入卷积神经网络
我希望这个案例可以清楚地说明对于图像处理为什么MLP不好用。现在让我们继续讨论CNN是如何用来解决我们的大多数问题的。

CNN利用近处的像素比远处的相关性更强的事实
我们通过使用称为卷积核的东西来分析附近像素的影响。卷积核正是你认为的过滤器,在上述情况下,我们采用用户指定尺寸的卷积核(经验法则为3x3或5x5),然后将图像从左上角移到右下角。对于图像上的每个点,基于卷积核使用卷积运算,计算结果。
卷积核可能与任何东西有关,对于人类照片,一个卷积核可能与看到的鼻子有关,而我们的鼻子卷积核会让我们看到鼻子在我们的图像中出现的强度、次数和它们出现的位置。与MLP相比,这减少了神经网络必须学习的权重数量,并且还意味着当这些特征的位置发生变化时,它不会脱离神经网络。
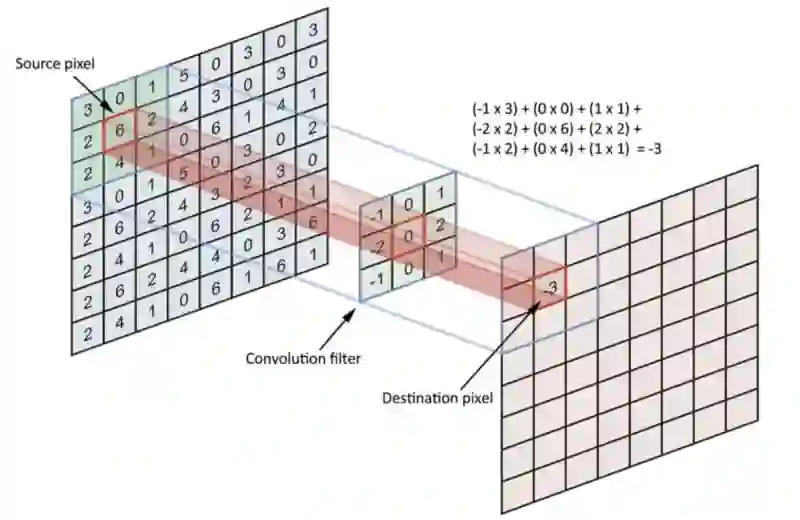
卷积操作
如果您想知道如何通过神经网络学到不同的特征,以及神经网络是否可能学习同样的特征(10个鼻子卷积核将是多余的),这种情况极不可能发生。在构建网络时,我们随机指卷积核的值,然后在神经网络训练时不断更新。除非所选卷积核的数量非常大,否则很可能不会产生两个相同的卷积核。
一些卷积核的例子,或者也可以叫它过滤器,如下:
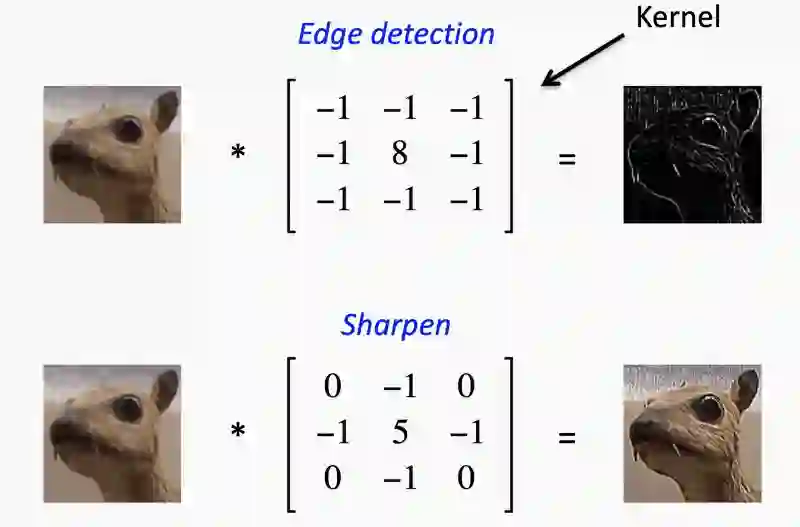
CNN卷积核的例子
在过滤器经过图像之后,为每个过滤器生成特征映射。然后通过激活函数获取这些函数,激活函数决定图像中给定位置是否存在某个特征。然后我们可以做很多事情,例如添加更多过滤层和创建更多特征映射,随着我们创建更深入的CNN,这些映射变得越来越抽象。我们还可以使用池化图层来选择要素图上的最大值,并将它们用作后续图层的输入。理论上,任何类型的操作都可以在池化层中完成,但实际上,只使用最大池,因为我们想要找到异常值 - 这些是我们的网络看到该功能的时候!
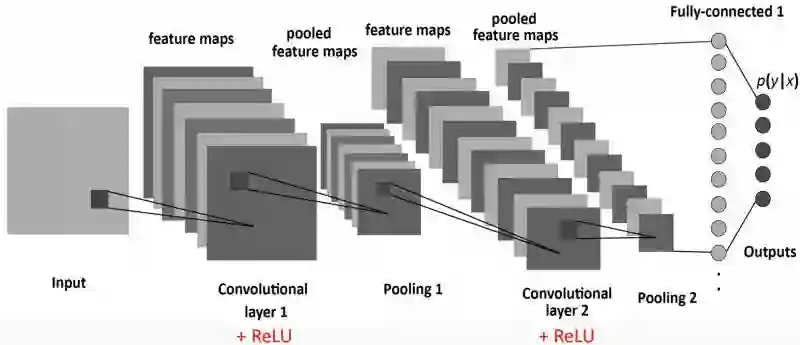
示例CNN具有两个卷积层,两个合并层和一个完全连接的层,它将图像的最终分类决定为几个类别之一。
只是重申我们迄今为止所发现的内容。我们知道MLP:
不适合图像缩放
忽略像素位置和与邻居相关的信息
无法处理翻译
CNN的一般思想是智能地适应图像的属性:
像素位置和邻域具有语义含义
感兴趣的元素可以出现在图像中的任何位置
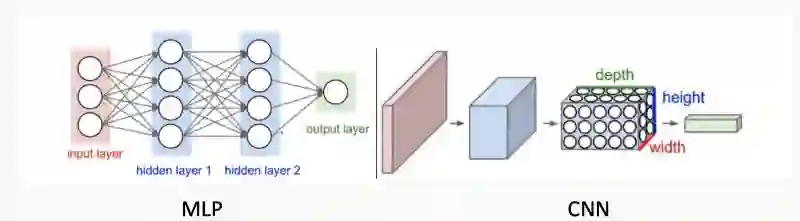
MLP和CNN的体系结构比较。
CNN也由层组成,但这些层没有完全连接:它们具有滤镜,在整个图像中应用的立方体形状的权重集。过滤器的每个2D切片称为内核。这些过滤器引入了平移不变性和参数共享。它们是如何应用的?卷积!
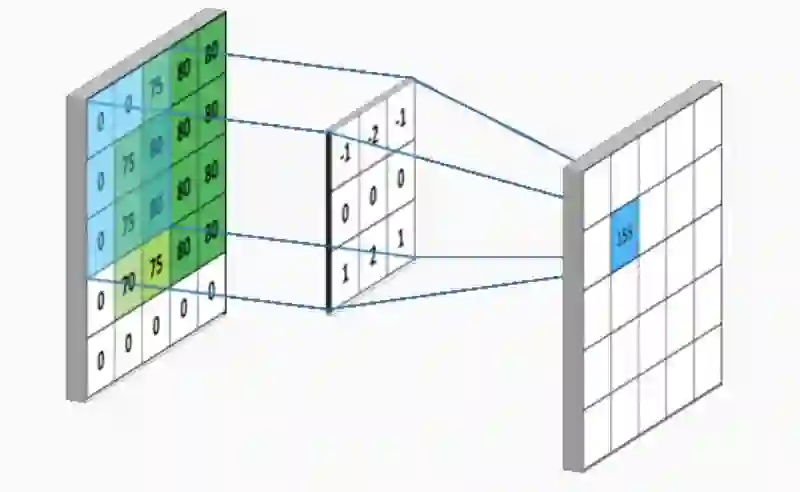
使用内核过滤器如何将卷积应用于图像的示例。
现在一个好问题是图像边缘会发生什么?如果我们在正常图像上应用卷积,则结果将根据滤波器的大小进行下采样。如果我们不希望这种情况发生,我们该怎么办?我们可以使用填充。
填充
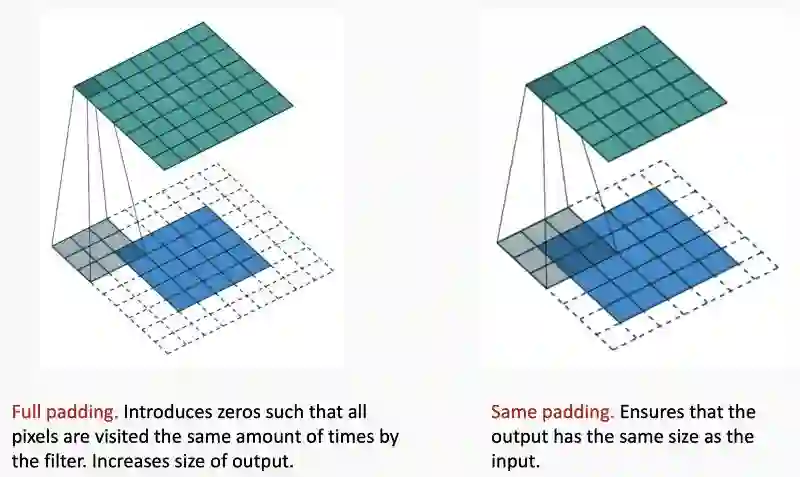
Full padding.填充0确保全部的像素都被过滤器卷积。增加输出的大小。
Same padding.确保输出和输入有相同的大小。
图片示例如何在卷积神经网络中使用full padding和same padding
填充本质上是使得卷积核产生的特征映射与原始图像的大小相同。这对于深度CNN非常有用,因为我们不希望减少输出,因此我们仅仅在网络的边缘留下一个2x2的区域来预测我们的结果。
我们如何将过滤器连接在一起?
如果我们有许多的特称映射,那么在我们网络中如何将这些映射结合起来帮助我们获得最终结果?
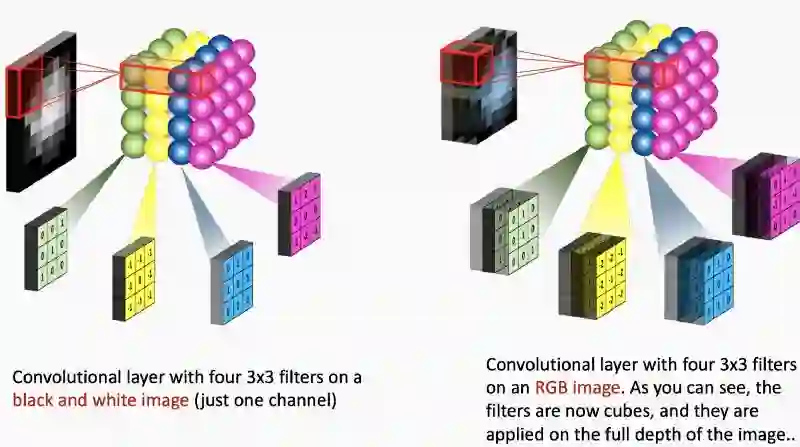
左图:在黑白图像上使用4个3x3卷积层(仅一个通道)
右图:在RGB图像上使用4个3x3卷积层。如你所见,过滤器是立方体,它们应用于图像的完整深度。
需要明确的是,每一个过滤器都与整个输入3D立方体进行卷积,但是只生成一个2D特征映射。
因为我们有许多过滤器,所以我们最终得到一个3D输出:每一个过滤器对应一个2D特征映射。
特征映射维度可以从一个卷积层急剧地变化到下一个:我们可以输入一个32x32x16的层,如果该层有128个过滤器,然后输出一个32x32x128的结果。
使用过滤层对图像进行卷积会生成特征映射,该特征映射突出显示图像中给定要素的存在。
在卷积层中,我们一般地在图像上应用多个过滤器来提取不同的特征。但更重要的是,我们正在学习这些过滤器!我们缺少一样东西:非线性。
介绍ReLU
对CNN来说,最成功的非线性函数是修正线性单元(ReLU), 它克服了在sigmoid函数中出现的梯度消失问题。ReLU更容易计算并生成稀疏性(但这并不总是有益的)。
不同层次比较
卷积神经网络中有三种层:卷积层,池化层和全连接层。每层都有不同的参数,可以对这些参数进行优化,并对输入层执行不同的任务。
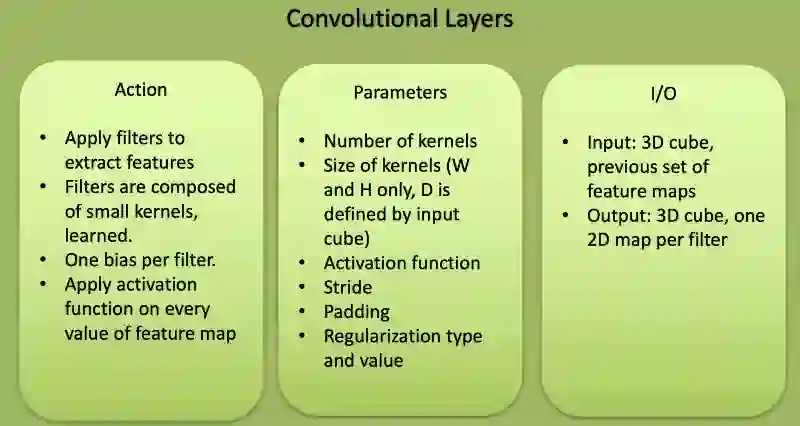
卷积层的特征
卷积层是对原始图像或深度CNN中的其他特征图应用过滤器的层。这一层包含了整个神经网络中大多数由用户指定的参数。最重要的参数是核的数量和核的大小
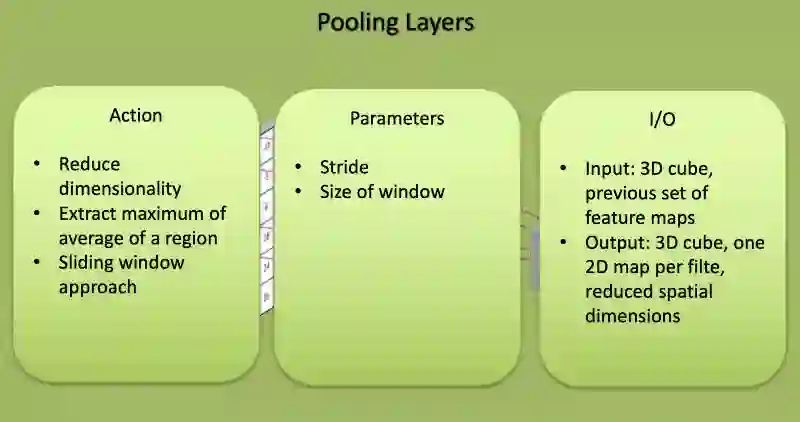
池化层的特征
池化层与卷积层很相似,但池化层执行特定的功能,如max池化(在某个过滤器区域取最大值),或average池化(在某个过滤器区域取平均值)。这些通常被用来降低网络的维度。
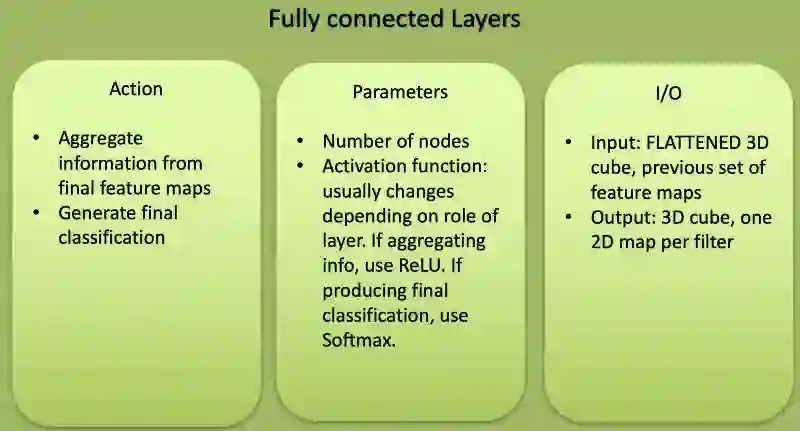
全连接层的特征
在CNN分类结果输出前放置全连接层,并在分类前对结果进行扁平化处理。这类似于MLP的输出层。
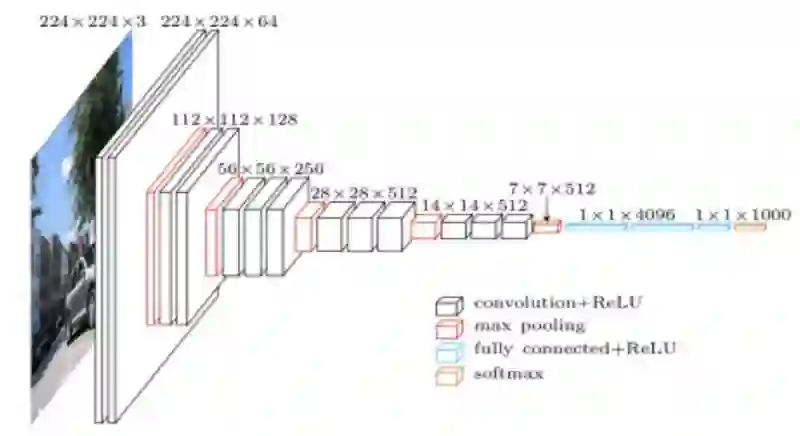
标准CNN的架构
CNN图层学了什么?
每个CNN层都学习增加复杂度的过滤器。
第一层学习基本的特征检测过滤器:边、角等
中间层学习检测对象部分的过滤器。对于人脸,他们可能学会对眼睛、鼻子等做出反应
最后一层具有更高的表示:它们学会识别不同形状和位置的完整对象。

CNN训练的识别特定物体及其生成的特征图的例子。
要查看CNN实际工作的3D示例,请查看下面的链接。
http://scs.ryerson.ca/~aharley/vis/conv/
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1565
AI求职百题斩 · 每日一题

AI研习社IJCAI小组组长本周将采访大咖教授:Victor R. Lesser
大家有什么问题想要问Victor R. Lesser的,都可以在IJCAI小组里面进行提问!
扫码即刻参与提问,带话题#提问 IJCAI 大咖#,提问采纳者有机会获得礼品一份,小组研值累积排行前三者,更有机会获得 AI 研习社赞助的「直达顶会」的机票+酒店等参会费用,让你亲临大会现场,和大咖面对面~。




