被热议的DataOps ,究竟要解决什么问题

2008 年我在我的第一份工作(Ask.com)中开始使用 Hadoop。当时是因为昂贵的 Oracle 集群无法处理不断增加的分析工作量,公司不得不切换到 Hadoop。随后在 Twitter 担任数据工程师的第二份工作中,我在第一线参与并推动了如何使用数据给几乎所有 Twitter 的产品赋能(与其称之为“大数据”,我更愿意简单称之为“数据”)。自 2008 年以来,我亲眼目睹了数据的力量,以及见证了它如何改变世界。如果你阅读过有关剑桥分析公司如何影响 2016 年美国大选的文章,那么你会感受到这种改变所带来的非凡意义。
然而,自流行词“大数据”出现 10 多年后,大数据似乎只对少数公司有用。在硅谷,几乎所有的独角兽企业都广泛使用大数据来推动他们的成功。在中国,像 BAT 这样的公司已经掌握了大数据的艺术,同时我们也有像字节跳动这样主要以大数据技术为基础的超级独角兽公司,但是仍然有很多关于大数据是如何难以使用的笑话。并且令人遗憾的事实是,对于大多数公司来说,大数据要么仍然是流行词,要么的确是难以实现。幸运的是,一门新学科正在崛起,是解开普通公司数据能力的关键,它就是 DataOps。
与 DevOps 明显相似的名称,以及与 DevOps 类似的软件开发角色,是数据工程师希望简化数据的使用并真正实现以数据来驱动企业成功的方法。今天,我们将简要介绍 DataOps 以及为什么它对每个想要从数据中获取真正价值的公司都很重要。
在维基百科上,DataOps 的定义是:
DataOps 是一种面向流程的自动化方法,由分析和数据团队使用,旨在提高质量并缩短数据分析的周期时间。
维基百科上的 DataOps 页面在 2017 年 2 月创建,其中详细介绍了这一新学科。DataOps 的定义肯定会随着时间的推移而发展,但其关键目标非常明确:提高数据分析的质量并缩短数据分析的周期。
在 2018 年的 Gartner 数据管理软件技术成熟度曲线中,DataOps 第一次出现在“Innovation Trigger”初始阶段。在 2021 年的曲线中,DataOps 已经快速发展到“Peak of Inflated Expectation”边缘了。同时,硅谷已经出现了一批以 DataOps 理念为核心打造数据产品的创业公司并得到了风险投资的大力支持,比如以集成开发为核心的 FiveTran 和 AirBytes,以 SQL 开发管理为核心的 DBT, 以调度为核心的 Astronomer 等等。
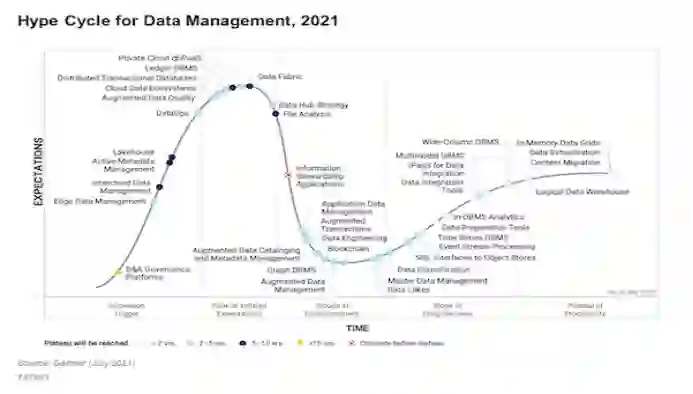
DataOps 可以降低数据分析的门槛,但是它并不会使数据分析变成一项简单的工作。实施成功的数据项目仍然需要大量工作,例如深入了解数据和业务的关系,良好的数据使用规范以及一个公司的数据驱动的文化培养。不过,DataOps 将极大地提高人们使用数据的效率并降低使用数据的门槛,公司可以更快、更早、更好地开始使用数据,并且成本和风险更低。
大数据的大多数应用可以分类为 AI(人工智能)或 BI(商业智能)。此处的 AI 是指广义的人工智能功能,包括机器学习、数据挖掘以及其他从数据中获取以前未知知识的技术。BI 则是更多地使用统计方法将大量数据汇总到更简单的报告,供人们理解。简而言之,AI 使用各种数据算法来计算新的东西,BI 则是统计人们可以理解的数字。
编写 AI / BI 程序并不难。你可以在几个小时内设置一个 TensorFlow 的人脸识别程序。或者使用 Matlab 绘制一些数据,甚至使用 Excel 也并不难实现这个目的。问题在于,要实际使用生产结果来支持面向用户的产品或根据这些神奇的数字来决定公司的命运,你需要的不仅仅是手动工作。
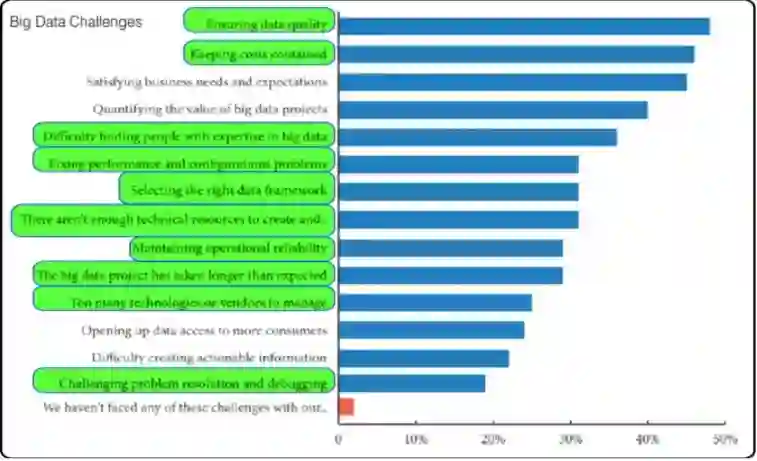
Dimensional Research 的一项调查(如上图所示)发现,对于想要实施大数据应用的公司来说,以下问题最为困难:
确保数据质量 ;
控制成本 ;
满足业务需求和期望 ;
量化大数据项目的价值 ;
很难找到具有大数据专业知识的人 ;
修复性能和配置问题 ;
选择正确的数据框架 ;
技术资源不足 ;
保持运行可靠性 ;
大数据项目花费的时间比预期的要长 ;
要管理的技术或供应商太多 ;
开放对更多消费者的数据访问 ;
难以创建可操作的信息 ;
复杂问题解决和调试。
谷歌数据分析师的另一项研究发现,对于大多数机器学习项目,只有 5%的时间花在编写 ML 代码上,另外 95%的时间用于设置运行 ML 代码所需的基础设施。
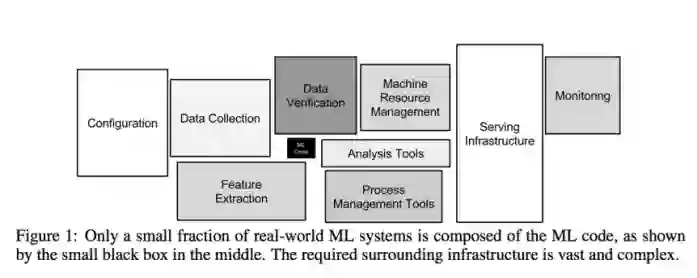
在这两项研究中,我们可以很容易地看到许多艰苦的工作实际上并不是在编写代码。整个基础设施的准备工作以及高效运行生产级别的代码是非常费时费力的,而且经常伴随着各种风险。
在谷歌的研究中,他们引用了我的前同事 Jimmy Lin 和 Dmitry Ryaboy(来自 Twitter Analytics 团队)的话:我们的大部分工作可以被描述为“数据管道工”。实际上,DataOps 使管道工的工作更简单和高效。
DataOps 旨在减少整个分析周期时间。因此,从搭建基础架构到使用数据应用的结果,通常需要实现以下功能:
部署:包括基础架构和应用程序。无论底层硬件基础设施如何,配置新系统环境都应该快速而简单。部署新应用程序应该花费几秒而不是几小时或几天 ;
运维:系统和应用程序的可扩展性,可用性,监视,恢复和可靠性。用户不必担心运维,可以专注于业务逻辑 ;
治理:数据的安全性,质量和完整性,包括审计和访问控制。所有数据都在一个支持多租户的安全环境中以连贯和受控的方式进行管理。
可用:用户应该能够选择他们想要用于数据的工具,并根据需要轻松运行它们和开发应用。应将对不同分析 / ML / AI 框架的支持整合到系统中:
生产:通过调度和数据监控,可以轻松地将分析程序转换为生产应用,构建从数据抽取到数据分析的生产级数据流水线,并且数据的使用应该很容易并由系统管理。
简而言之,它类似于 DevOps 方法:从编写代码到生产部署的路径,包括调度和监视,应由同一个人完成,并遵循系统管理的标准。与提供许多标准 CI、部署、监控工具以实现快速交付的 DevOps 类似,通过标准化大量大数据组件,新手可以快速建立生产级的大数据平台并充分利用数据的价值。
DataOps 的主要方法论仍处于快速发展阶段。像 Facebook 和 Twitter 这样的公司通常会有一个专门的数据平台团队(Data Platform Team)处理数据运营并实现数据项目。但是,他们的实现方式大多与公司现有的 Ops 基础设施集成,因此通常不适用于其他人。我们可以从他们的成功中学习经验,并建立一个可以由每家公司轻松实施的通用大数据平台。
要构建 DataOps 所需的通用平台,我们认为需要以下技术:
云架构:我们必须使用基于云的基础架构来支持资源管理,可扩展性和运营效率 ;
容器:容器在 DevOps 的实现中至关重要,它在资源隔离和提供一致的 dev / test / ops 环境中的作用对于实现数据平台仍然至关重要 ;
实时和流处理:实时和流处理现在在数据驱动平台中变得越来越重要,它们应该是现代数据平台的一等公民 ;
多分析引擎:MapReduce 是传统的分布式处理框架,但 Spark 和 TensorFlow 等框架日常使用越来越广泛,应该进行集成 ;
集成的应用程序和数据管理:应用程序和数据管理,包括生命周期管理,调度,监视,日志记录支持,对于生产数据平台至关重要。DevOps 的常规实践可以应用于应用程序管理,但是数据管理以及应用程序和数据之间的交互需要很多额外的工作 ;
多租户和安全性:数据安全性几乎是数据项目中最重要的问题:如果数据无法保护,则根本无法使用。该平台应为每个人提供一个安全的环境,以便每个人都可以使用这些数据并对每个操作进行授权,验证和审核。
Dev 和 Ops 工具:该平台应为数据科学家提供有效的工具,以分析数据并生成分析程序,为数据工程师提供大数据流水线的工具,并为其他人提供消费数据和结果的方法。
云原生场景中,企业对大数据系统的核心诉求是,需要快速高效在统一环境中实现多元异构的数据应用,敏捷应对支持业务需求,并管理整个数据应用生命周期。
对于中小客户来说,希望可以直接在公有云使用 DPaaS(Data Platform as a Service),开箱即用,无需运维,按需付费。同时,有大量的数据应用可供参考和直接使用,产生的数据应用可以支持企业生产决策。如果需要私有发布,企业可以实现快速迁移。
对于大中型企业来说,在公有 / 私有云上建设云原生大数据平台,希望可以通过标准化组件降低运维复杂度及成本,通过 DataOps 工具加快数据应用的开发速度,通过资源混排以及更细粒度的资源调度提高资源使用效率
对于大型集团型企业来说,在私有 / 混合云上建设私有 Data Platform as a Service,允许业务部门以多租户方式共享数据平台能力,避免重复建设。同时,统一数据开发流程及标准,避免数据孤岛,提升数据共享能力,便于内部各部门间应用隔离、资源计费、提升数据 ROI。
可以使用云原生 DataOps 构建的典型数据应用场景包括:
云原生 DataOps 后台支持及管理体系应该涵盖全局数据门户、数据质量检测与管理、数据应用调度以及多租户资源计费。
目前的大数据技术是强大的,但它们对于普通人来说仍然太难使用。部署一个适合生产环境的数据平台仍然是一项艰巨的任务。对于已经开始这一过程的公司来说,他们的数据平台团队大部分时间仍在做相似的事情,就像重新造轮子。
有些公司已经意识到这些问题,并开始采用不同的方法来解决这个问题,越来越多的企业开始使用基于容器的解决方案,而传统的基于 Hadoop 为中心的平台逐渐在往云原生体系迁移。
但对于企业用户来说,更加容易践行云原生 DataOps 的方法是找到一款正确、合适的工具来帮助他们实践 DataOps 方法论。
作者介绍:
彭锋,智领云联合创始人 &CEO,拥有 20 余年软件开发、大数据及云计算经验,曾担任 Twitter 大数据架构师及技术带头人,ask.com 工程总监,硅谷天使投资人,毕业于美国马里兰大学计算机博士,武汉大学计算机系本科及硕士。
80 岁 Unix 大神还在修复 AWK 代码;华为全线收缩和关闭边缘业务;小鹏汽车回应苹果汽车前工程师窃密认罪案|Q 资讯



